

Google BERT
1. the essence of BERT
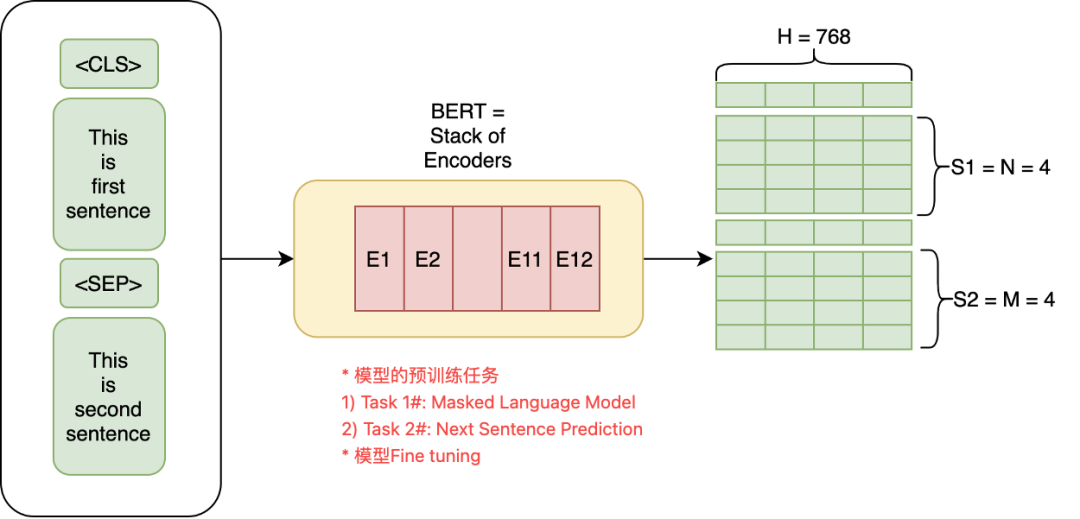
BERT Architecture: A pre-trained language model based on a multi-layer Transformer encoder that captures the bidirectional context of text through Tokenization, various Embeddings, and task-specific output layers, demonstrating excellent performance in various natural language processing tasks.
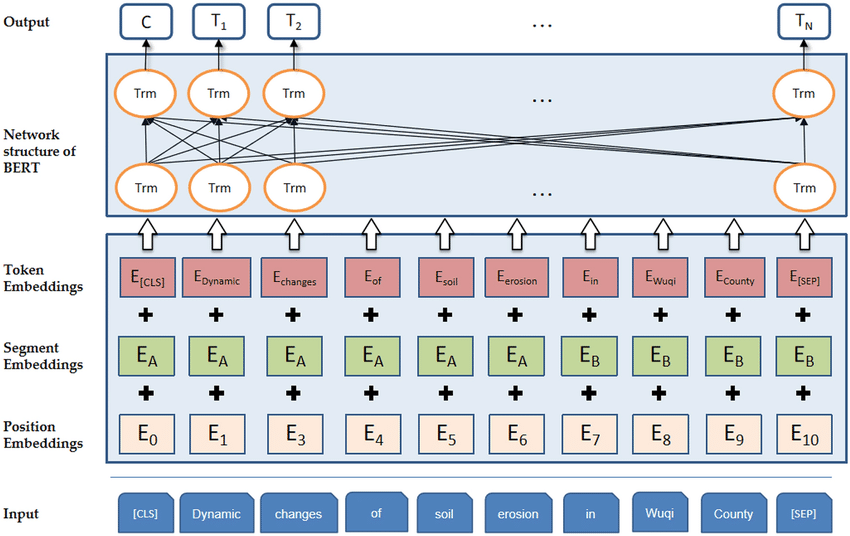
BERT Architecture
-
Input Layer
The input to BERT is a raw text sequence, which can be a single sentence or two sentences (for example, a question and answer in a QA task). Before inputting into the model, these texts need to undergo specific preprocessing steps.
-
Tokenization and Embeddings
Tokenization: The input text is first split into tokens using a tokenizer. This step usually includes converting the text to lowercase, removing punctuation, and tokenizing. BERT uses the WordPiece tokenization method to further break down words into subwords, optimizing the vocabulary size and model generalization.
Token Embeddings: The tokenized tokens are mapped to a high-dimensional space, forming token embeddings. This is achieved by looking up a pre-trained embedding matrix that provides a fixed-size vector representation for each token.
Segment Embeddings: Since BERT can handle two sentences as input (for example, in sentence pair classification tasks), a method is needed to distinguish between the two sentences. Segment embeddings are used for this purpose, adding an extra embedding to each token to indicate which sentence it belongs to (usually “A” or “B”).
Position Embeddings: Since the Transformer model itself does not have the ability to process token position information in the sequence, position embeddings are needed to provide this information. Each position has a unique embedding vector, which is learned during training.
The final input embedding for each token is obtained by adding Token Embeddings, Segment Embeddings, and Position Embeddings together.
-
Network Structure of BERT
The core of BERT consists of multiple stacked Transformer encoder layers. Each encoder layer contains self-attention mechanisms and feedforward neural networks, allowing the model to capture complex dependencies in the input sequence.
-
Self-attention Mechanism: Allows the model to focus on tokens at different positions while processing the sequence and calculate attention weights between tokens, capturing dependencies in the input sequence.
-
Feedforward Neural Network: Further transforms the output of the self-attention mechanism to extract higher-level features.
-
Residual Connections and Layer Normalization: Used to improve the stability and effectiveness of model training, helping to alleviate the gradient vanishing and exploding problems.
-
Output Layer
The output of BERT depends on the specific task. During the pre-training phase, BERT employs two tasks: Masked Language Model (MLM) and Next Sentence Prediction (NSP).
-
MLM: In this task, BERT predicts the tokens that are randomly masked in the input sequence. The model’s output is a probability distribution for each masked token, obtained through the Softmax layer.
-
NSP: This task requires BERT to predict whether two sentences are consecutive. The model’s output is a probability distribution for a binary classification problem.
By combining Token Embeddings, Segment Embeddings, and Position Embeddings, models like BERT can comprehensively capture the semantics and contextual information of text, providing a robust foundational representation capability for various natural language processing tasks.
-
Token Embeddings:
-
In BERT, the input text is first divided into a sequence of tokens (words, subwords, etc.), and each token is mapped to a high-dimensional vector space, forming token embeddings. These embeddings capture the semantic information of the tokens and are fundamental for the model’s understanding of text.
-
Token embeddings are obtained through unsupervised pre-training on large-scale corpora, enabling BERT to understand and process various complex language phenomena and semantic relationships.
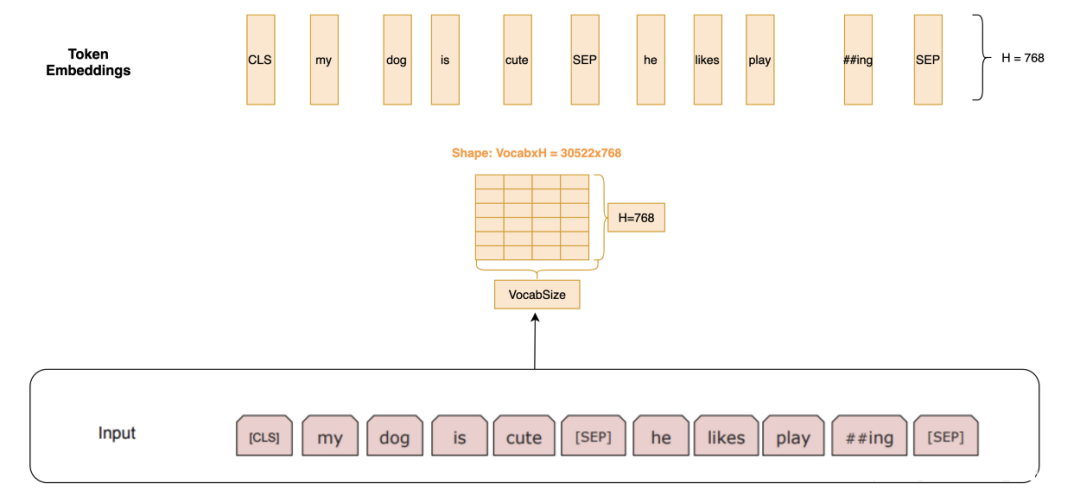 Token Embeddings
Token Embeddings
-
Segment Embeddings:
-
To handle tasks like QA, BERT introduces segment embeddings to distinguish between two different but related sentences (e.g., question and answer). These embeddings help the model understand the relationship and boundaries between sentences.
-
In text classification tasks, the role of segment embeddings may not be as apparent since the input is usually a continuous paragraph. However, they can still be used to distinguish different parts of the text, especially when dealing with long documents or multiple sentences.
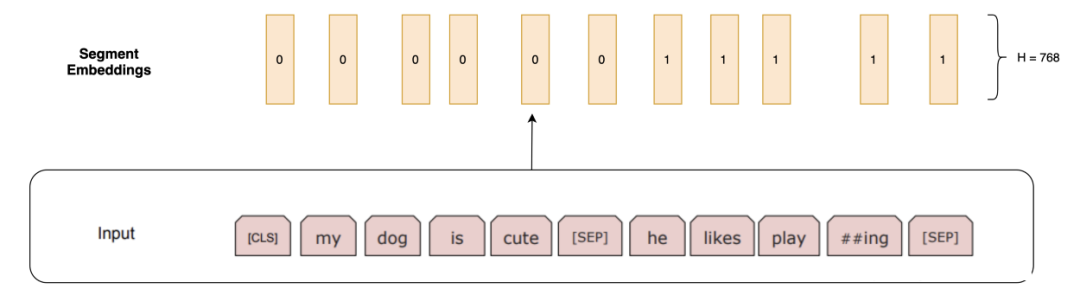 Segment Embeddings
Segment Embeddings
-
Position Embeddings:
-
Since the Transformer structure itself does not have the ability to handle the order of sequences, BERT introduces position embeddings to capture the positional information of tokens in the text.
-
These embeddings ensure that the model can distinguish the same tokens at different positions, such as differentiating “hello, world” and “world, hello” within the phrases.
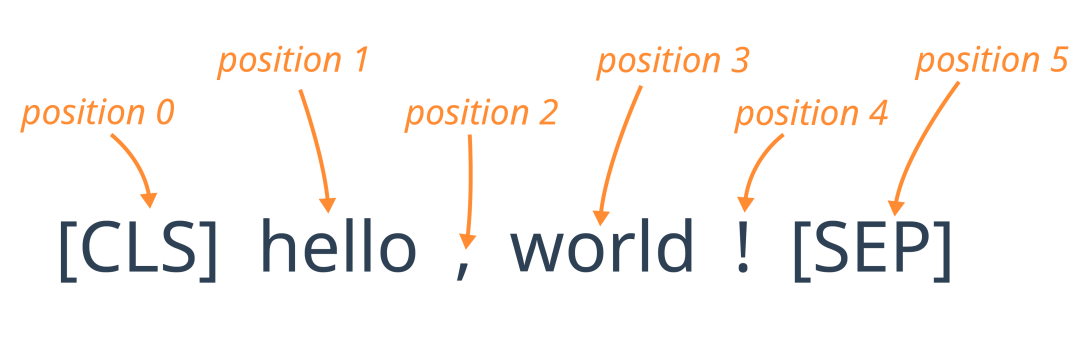 Position Embeddings
Position Embeddings
Position Embeddings, when added to Token Embeddings and Segment Embeddings, form the final input embeddings that are subsequently fed into the Transformer encoders for processing.
2. the principles of BERT
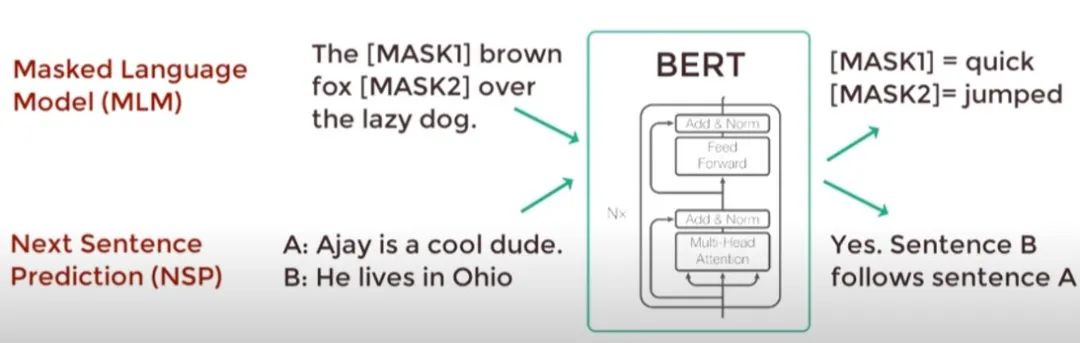
The working principle of BERT is to perform pre-training tasks (such as the Masked Language Model to capture the bidirectional context of words in the text and Next Sentence Prediction to understand the logical relationships between sentences) on a large amount of unlabelled data, and then fine-tune the pre-trained model for specific tasks, achieving high performance in various natural language processing tasks.
Pre-training tasks of the model
:In the process of self-learning on a large amount of unlabelled data, the model can learn the inherent laws and patterns of language through these tasks, providing strong support for its subsequent specific tasks (such as text classification, QA, etc.). Here are two core pre-training tasks:
Unsupervised Pre-training
-
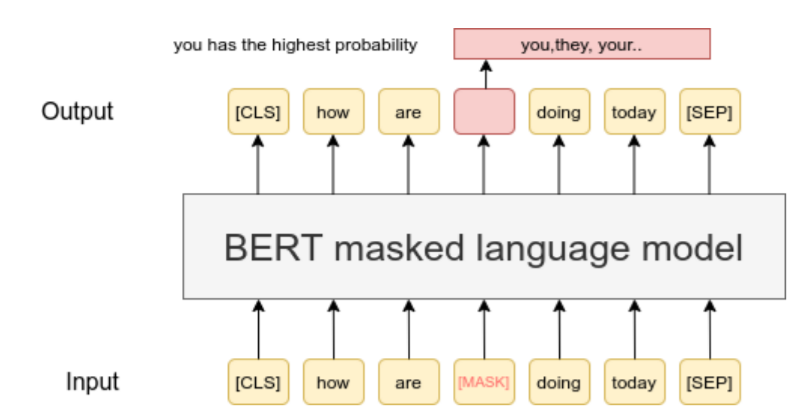
Masked Language Model (MLM)
-
Task Description: Randomly mask or replace a portion of the vocabulary in the input text and require the model to predict the original content of the masked or replaced vocabulary.
-
Purpose: Enable the model to use bidirectional context information to predict the masked vocabulary, thereby learning deeper semantic representations.
-
Implementation: During the pre-training phase, BERT randomly selects 15% of the tokens in the text to mask, with 80% of the time replacing them with the [MASK] token, 10% of the time replacing them with random vocabulary, and the remaining 10% staying unchanged. This masking strategy is called dynamic masking, as it randomly changes the masking positions and vocabulary each time the input is provided.
Masked Language Model (MLM)
-
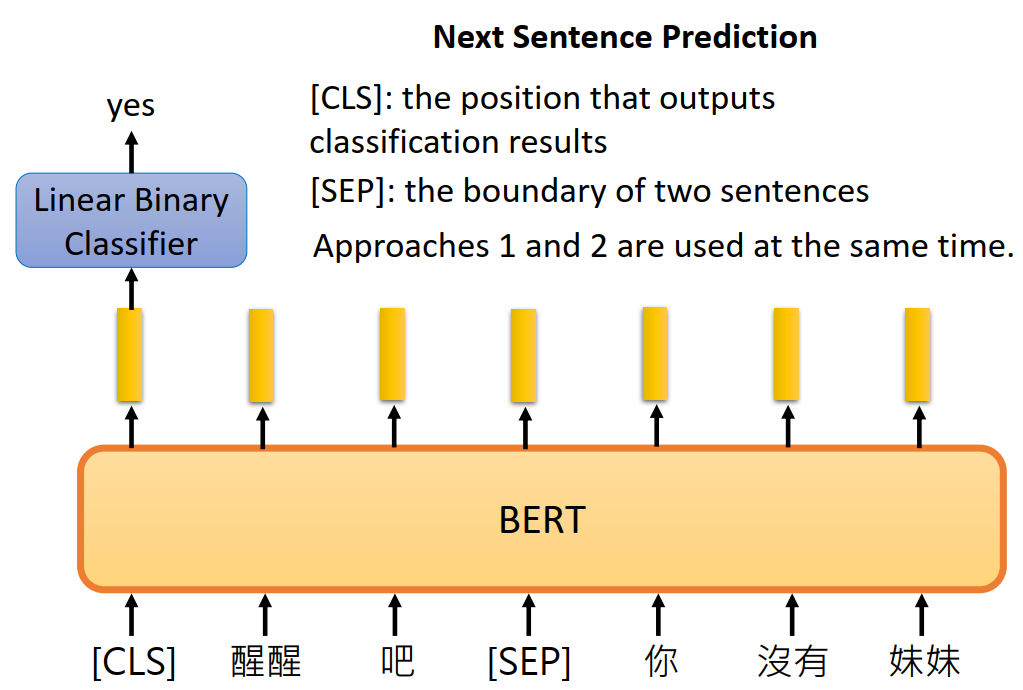
Next Sentence Prediction (NSP)
-
Task Description: Given a pair of sentences, determine whether the second sentence is the subsequent sentence of the first sentence.
-
Purpose: Enable the model to understand the logical relationships between sentences, such as coherence and causality, thereby improving its ability to handle long documents or complex texts.
-
Implementation: During the pre-training phase, BERT constructs a binary classification task, where 50% of the time B is the true subsequent sentence of A (labeled as “IsNext”), and the other 50% of the time B is a randomly selected sentence from the corpus (labeled as “NotNext”). The model predicts using the embedding of the [CLS] token output from the last layer of the Transformer.
Next Sentence Prediction (NSP)
Model Fine-tuning:BERT’s fine-tuning process adjusts the pre-trained model for specific tasks, allowing it to better adapt to and solve specific tasks. Depending on the type of task, modifications to the BERT model may vary, but these modifications are usually relatively simple, often requiring only the addition of one or more layers of neural networks to the output section of the model.
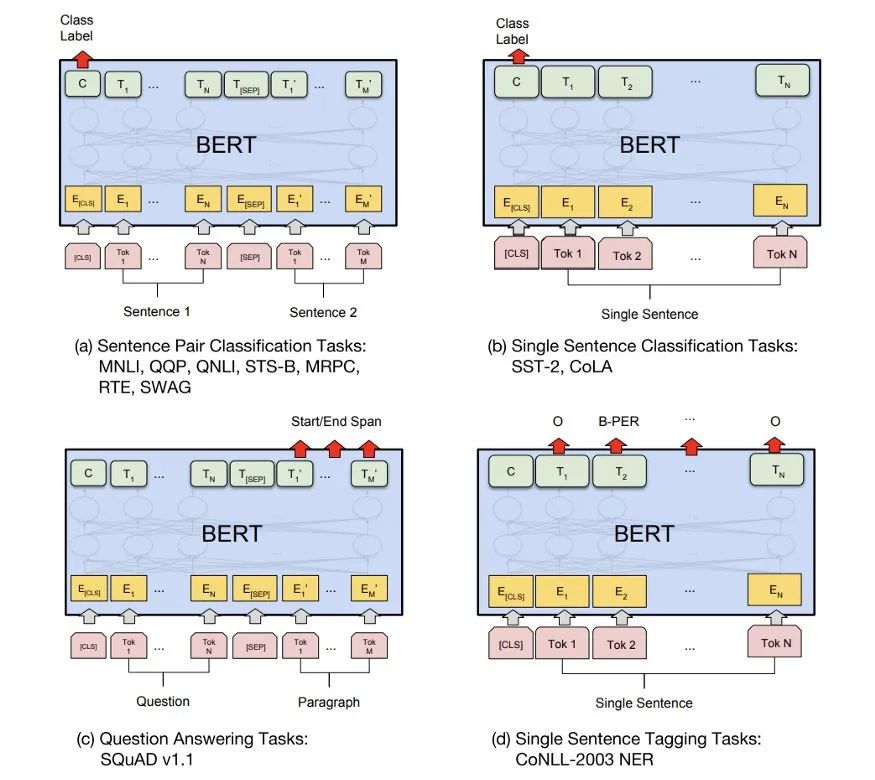
Model Fine-tuning
-
Task Types: Depending on the specific task, BERT’s fine-tuning can be categorized into the following types:
-
Sentence Pair Classification Task: This task requires determining the relationship between two sentences, such as text entailment and QA matching. During fine-tuning, both sentences are input to the model, and the output representation of the first token ([CLS]) is taken as the representation of the entire sentence pair, which is then input to an additional softmax layer for classification.
-
Single Sentence Classification Task: This task requires classifying a single sentence, such as sentiment analysis and text classification. During fine-tuning, a single sentence is input to the model, and the output representation of the first token ([CLS]) is also used for classification.
-
Question Answering Task: This task requires the model to find the answer to a question from the given text. During fine-tuning, both the question and answer are input to the model, and the starting and ending positions of the answer in the model output are used as the prediction of the answer.
-
Sequence Tagging Task (e.g., Named Entity Recognition): This task requires classifying each token in the input sequence, such as identifying entities in the text or part-of-speech tagging. During fine-tuning, all tokens’ outputs from the last layer of the Transformer are taken and input to an additional softmax layer for token-wise classification.
-
Model Modifications: During fine-tuning, modifications to the BERT model typically include the following aspects:
-
Input Processing: Depending on the type of task, the input data undergoes corresponding processing, such as concatenating sentence pairs and adding special tokens.
-
Output Layer: An additional layer or layers of neural networks are added to the output section of the BERT model to convert the model’s output into the required format for the task. For classification tasks, a softmax layer is usually added to compute the probability distribution; for sequence tagging tasks, token-wise classification is performed.
-
Loss Function: Select an appropriate loss function based on the task type, such as cross-entropy loss for classification tasks and mean squared error loss for regression tasks.
3. the applications of BERT
Question Answer (QA) System:BERT’s application in QA systems typically involves two stages: retrieval and answer judgment.

Question Answer (QA) System
-
1. Retrieval Stage
-
Document Processing:
-
Segmentation: Cut long documents into shorter paragraphs or sentences (Passages), which are easier to process and index.
-
Indexing: Use inverted indexing techniques to establish an index for each segmented passage for quick querying.
-
Retrieval Model:
-
BM25 Model: Use BM25 or similar retrieval functions (e.g., BM25+RM3) to calculate the relevance score between the question and each candidate passage or sentence.
-
Candidate Selection: Select the Top K most relevant candidate passages or sentences based on the scores.
-
2. Answer Judgment Stage
-
Model Preparation:
-
Fine-tuning Data: Select appropriate QA datasets (e.g., SQuAD) or task data for fine-tuning the BERT model.
-
Model Structure: Add necessary output layers to the BERT model to fit the QA task, such as classification layers or start/end position prediction layers.
-
Answer Processing:
-
Input Construction: Combine the user’s question with each candidate passage or sentence into the input format for the BERT model.
-
Model Prediction: Use the fine-tuned BERT model to predict for each input, determining whether the candidate passage or sentence contains the correct answer or predicting the precise location of the answer.
-
Answer Selection:
-
Scoring Mechanism: Based on the predictions from the BERT model, assign scores to each candidate passage or sentence.
-
Final Answer: Select the candidate passage or sentence with the highest score as the final answer.
Chatbot:BERT’s application in chatbots mainly involves two aspects: user intent classification and slot filling (for single-turn dialogues), as well as utilizing contextual information in multi-turn dialogues.
Chatbot
-
1. Application of BERT in Single-turn Dialogue
-
User Intent Classification:
-
Input: Use the user’s utterance as input to the BERT model.
-
Model Structure: Add a classification layer on top of the BERT model to classify the user intent into different service types.
-
Training: Fine-tune using a dataset of user utterances with intent labels to enable the model to accurately recognize user intent.
-
Task Description: Parse the user’s utterance to extract the user’s intent, such as ordering food, playing a song, etc.
-
BERT Application:
-
Slot Filling:
-
Input: Use the user’s utterance and predefined slots as input to the BERT model.
-
Model Structure: Use a sequence labeling approach to predict slot labels for each input token.
-
Training: Fine-tune using a dataset of user utterances with slot labels to enable the model to accurately fill in slot information.
-
Task Description: Extract key elements based on user intent, such as departure and destination when booking a flight.
-
BERT Application:
-
2. Application of BERT in Multi-turn Dialogue
-
Utilization of Contextual Information:
-
Input: Use the current user utterance along with historical dialogue content as input to the BERT model.
-
Model Structure: Various strategies can be employed to incorporate historical information, such as concatenating historical dialogue with the current user utterance or using embeddings of historical dialogue.
-
Training: Fine-tune using a multi-turn dialogue dataset to enable the model to accurately understand and utilize contextual information to generate responses.
-
Task Description: In multi-turn dialogues, leverage historical interaction information to improve the model’s responses.
-
BERT Application:
-
Model Improvement:
-
Increase Model Capacity: Capture more contextual information by increasing the number of layers or hidden units in the BERT model.
-
Introduce Attention Mechanism: Use attention mechanisms to weight the importance of historical information, allowing the model to focus on the parts most relevant to the current response.
-
Memory Networks: Combine memory networks to store and retrieve historical information for the model to generate responses when needed.
-
Key Questions: How to effectively incorporate more historical information and correctly use this information in context.
-
Improvement Strategies: