Click the card below to follow the “CVer” WeChat public account
AI/CV heavy-duty content delivered to you first
Author: Amusi | Source: CVer
Introduction
There are not many abbreviations left for the combination of Transformer + U-Net…
Previously, I reviewed the currently published 5 papers on Transformer + medical image segmentation at MICCAI 2021, see: Transformer Kicks into Medical Image Segmentation! A Look at 5 MICCAI 2021 Papers
I didn’t expect everyone to like this article so much,the number of collections is terrifying…
So this article will review the papers on the combination of Transformer + U-Net, where Transformer is a hot tool for paper writing, and U-Net is the king of medical image segmentation. The collision of the two has become a hot topic in the field of medical image segmentation research.
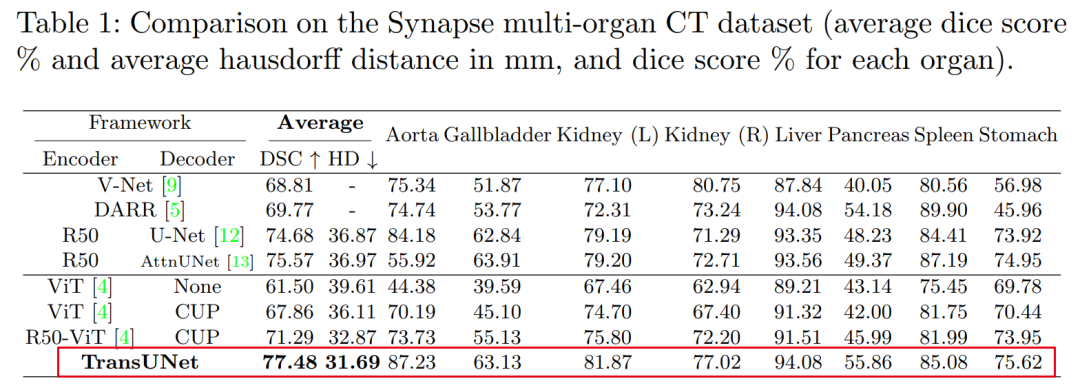
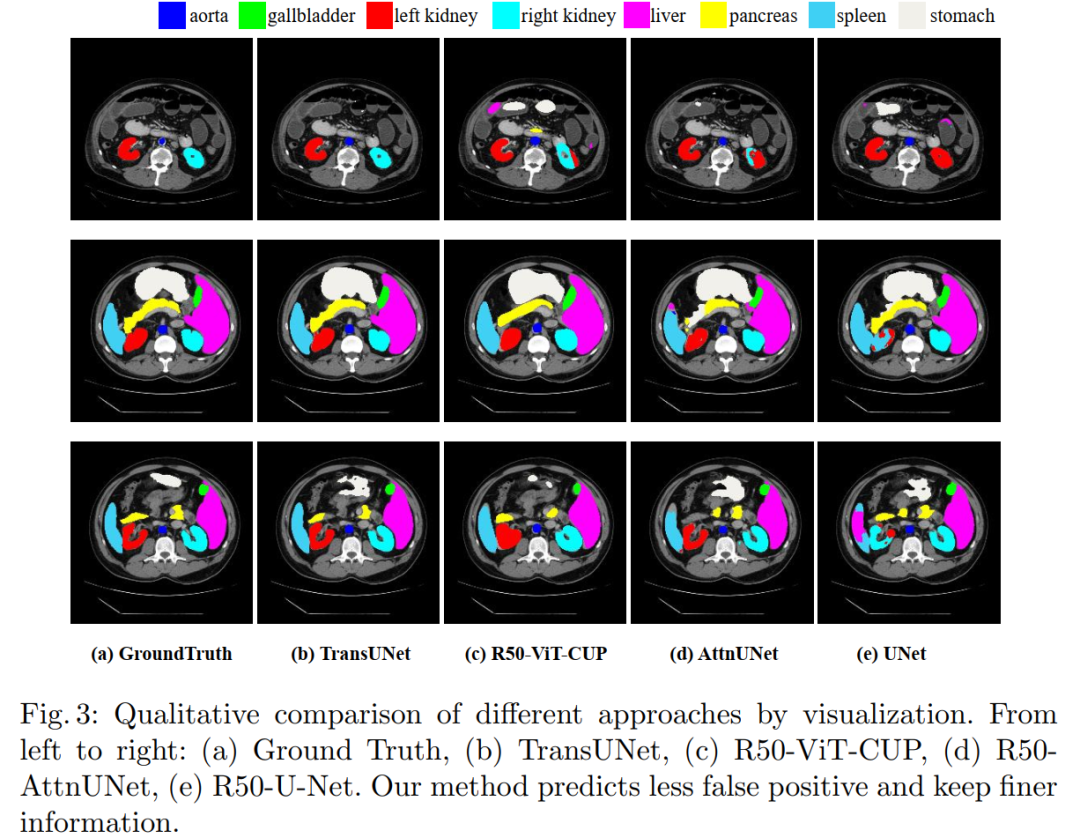
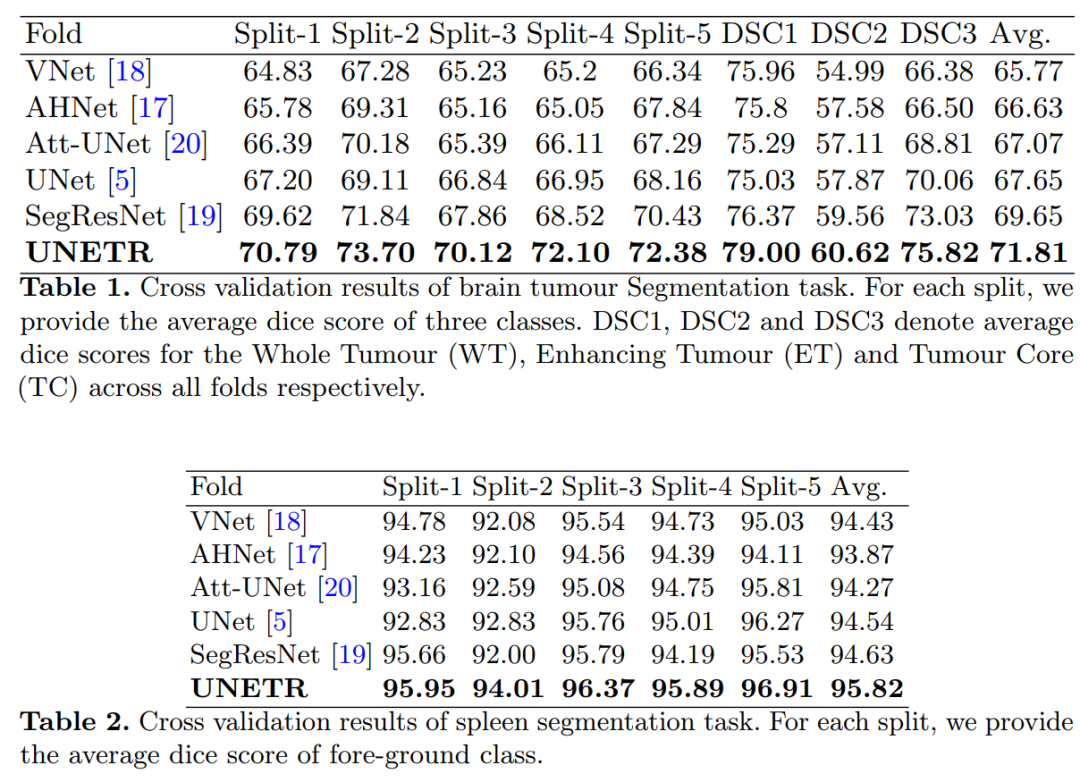
1. TransUNet: A Powerful Encoder for Medical Image Segmentation Using Transformers
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation

Affiliations: JHU, University of Electronic Science and Technology of China, Stanford University, etc.
Code: https://github.com/Beckschen/TransUNet
Paper: https://arxiv.org/abs/2102.04306
Summary in One Sentence: Combines the advantages of Transformers and U-Net, achieving SOTA! Performance exceeds AttnUNet, V-Net, and other networks, code just open-sourced!
Medical image segmentation is a prerequisite for developing healthcare systems (especially for disease diagnosis and treatment planning). Among various medical image segmentation tasks, the U-shaped architecture (also known as U-Net) has become the de facto standard and has achieved great success. However, due to the inherent locality of convolution operations, U-Net often shows limitations in explicitly modeling long-range dependencies. Transformers, designed for sequence-to-sequence predictions, have become an alternative architecture with an innate global self-attention mechanism, but may lack the ability to capture low-level details, which can limit localization capabilities.
In this paper, we propose TransUNet, which combines the advantages of Transformers and U-Net, serving as a powerful alternative for medical image segmentation.
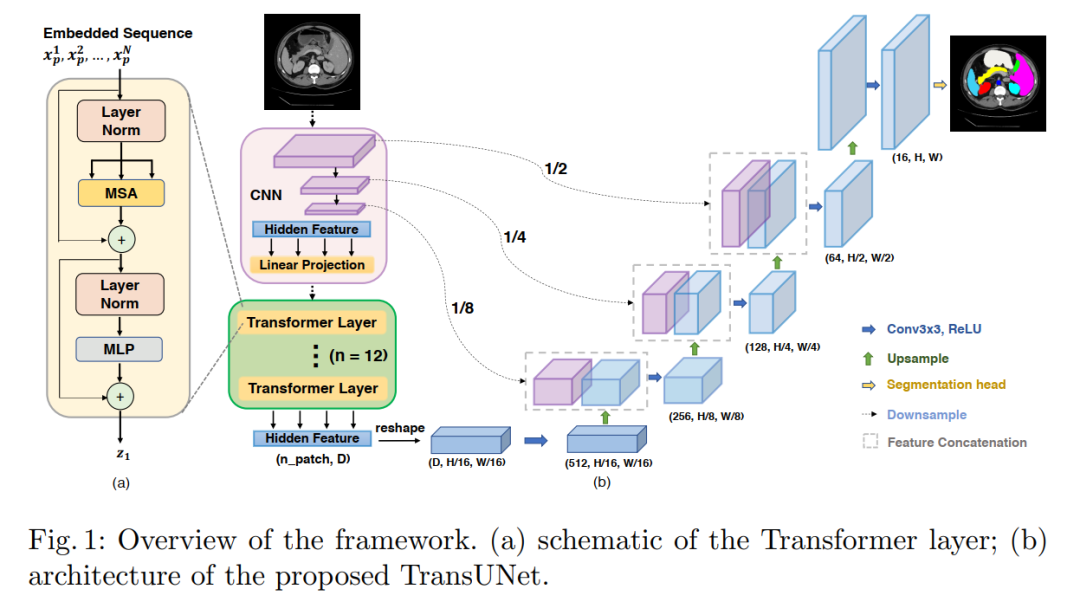
On one hand, the Transformer encodes tokenized image patches from convolutional neural network (CNN) feature maps into an input sequence to extract global context. On the other hand, the decoder upsamples the encoded features and combines them with high-resolution CNN feature maps for precise localization.
We believe that by restoring localized spatial information through the combination with U-Net, Transformers can serve as powerful encoders for medical image segmentation tasks. TransUNet outperforms various competing methods across various medical applications (including multi-organ segmentation and cardiac segmentation).
2. MedT: A Transformer for Medical Image Segmentation
Medical Transformer: Gated Axial-Attention for Medical Image Segmentation

Code (open-sourced):
https://github.com/jeya-maria-jose/Medical-Transformer
Paper: https://arxiv.org/abs/2102.10662
Summary in One Sentence: Achieves SOTA! Introduces a local-global training strategy (LoGo) to further enhance performance, outperforming Res-UNet, U-Net++, and other networks, code just open-sourced! Author affiliations: JHU, Rutgers University
Over the past decade, deep convolutional neural networks have been widely used for medical image segmentation and have shown sufficient performance. However, due to the inherent inductive biases in convolutional architectures, they lack understanding of long-range dependencies in images. Recently proposed transformer-based architectures utilizing self-attention mechanisms encode long-range dependencies and learn highly expressive representations.
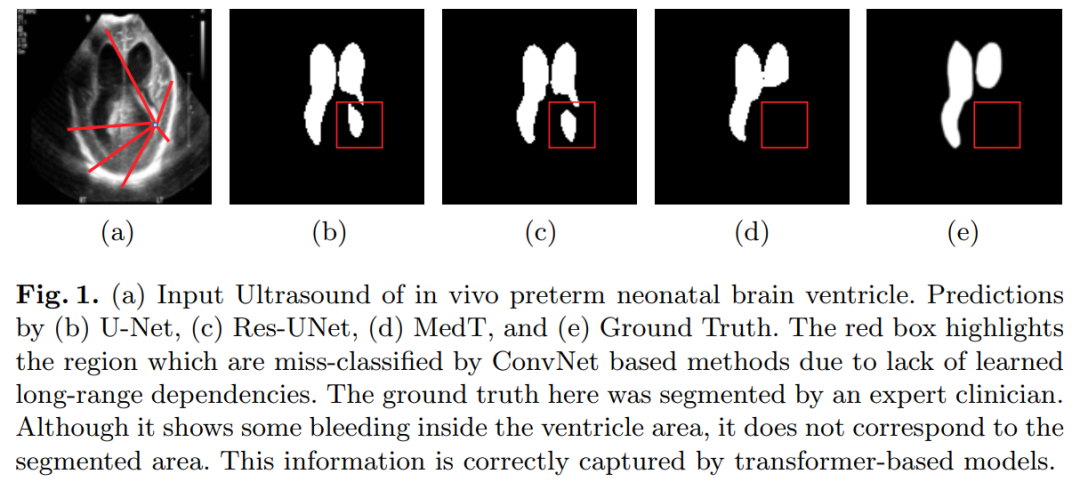
This prompted us to explore transformer-based solutions and investigate the feasibility of using transformer-based network architectures for medical image segmentation tasks. Most existing transformer-based network architectures proposed for visual applications require large-scale datasets to be trained properly. However, the number of data samples for medical imaging is relatively small compared to datasets used for visual applications, making it difficult to effectively train transformers for medical applications.
To address this, we propose the Gated Axial-Attention model, which extends existing architectures by introducing additional control mechanisms in the self-attention module.
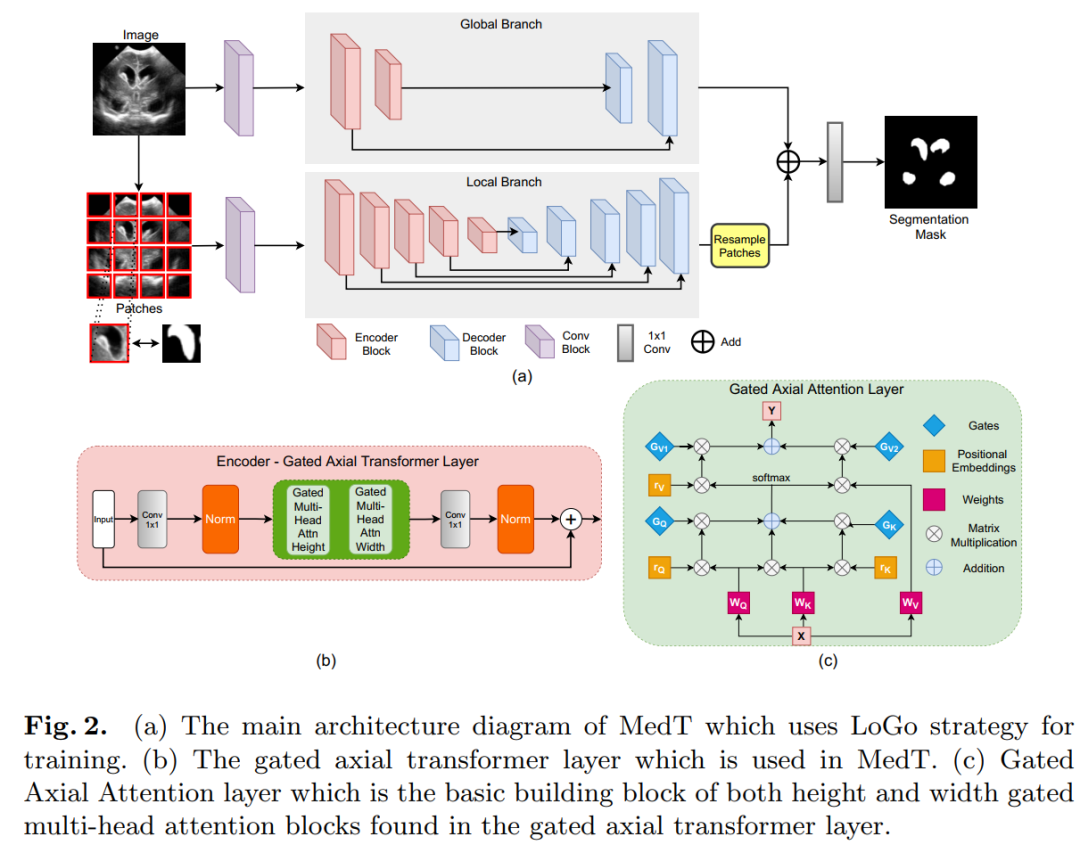
Additionally, to effectively train models on medical images, we propose a local-global training strategy (LoGo), which can further enhance performance.
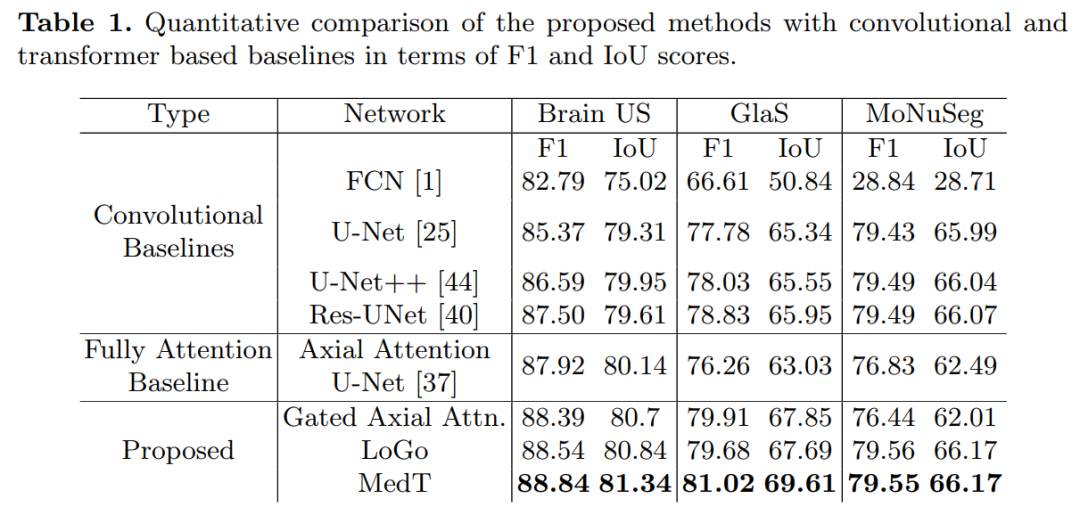
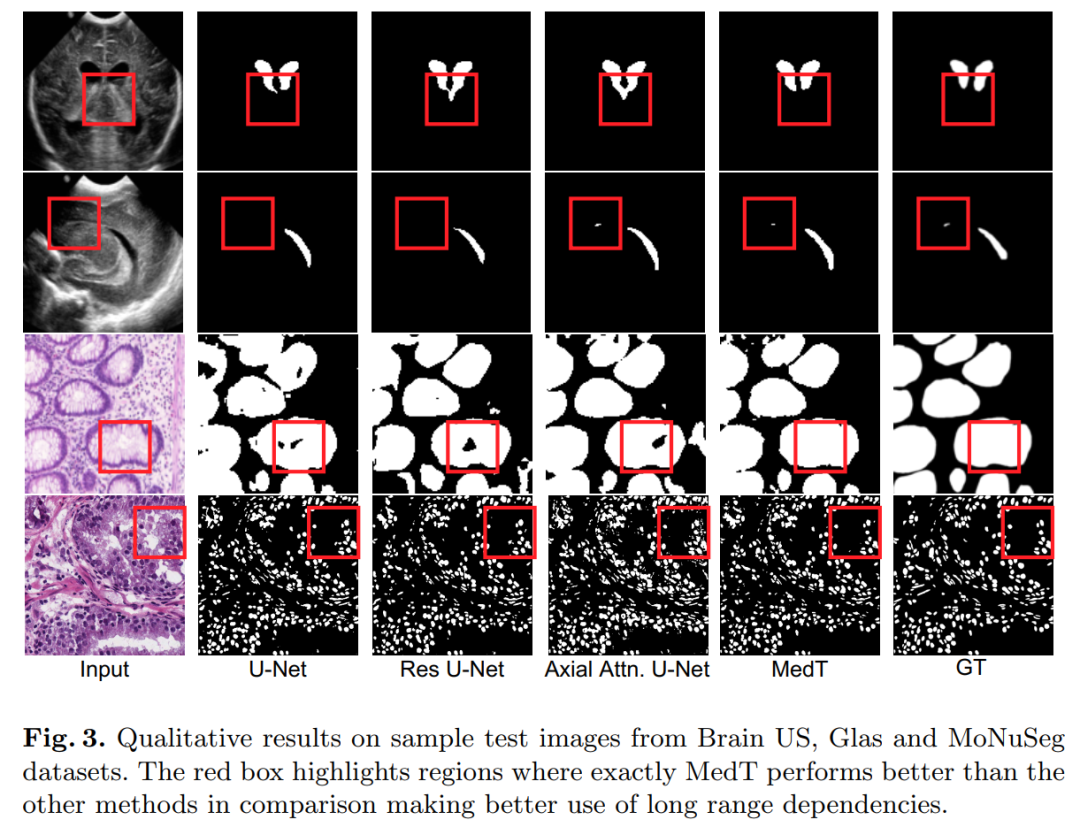
Specifically, we operate on both the entire image and patches to learn global and local features, respectively. The proposed Medical Transformer (MedT) was evaluated on three different medical image segmentation datasets, and the results show better performance compared to convolution-based and other transformer-based architectures.
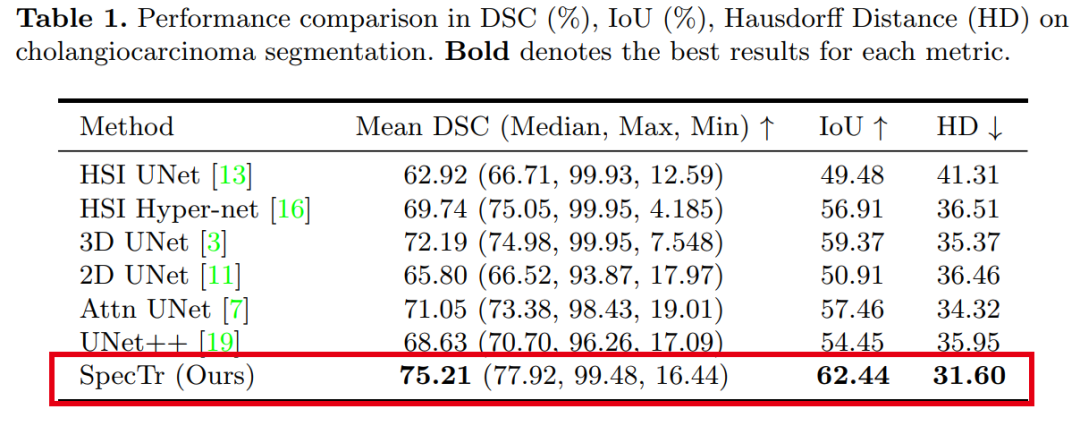
3. SpecTr: Spectral Transformer for Hyperspectral Pathology Image Segmentation
SpecTr: Spectral Transformer for Hyperspectral Pathology Image Segmentation

Affiliations: East China Normal University, JHU, Shanghai Jiao Tong University
Code: https://github.com/hfut-xc-yun/SpecTr
Paper: https://arxiv.org/abs/2103.03604
Summary in One Sentence: Achieves SOTA! Performance exceeds UNet++, Attn UNet, and other networks, code will be open-sourced soon!
Hyperspectral imaging (HSI) has released great potential for various applications relying on high-precision pathology image segmentation (e.g., computational pathology and precision medicine). Since hyperspectral pathology images can benefit from rich and detailed spectral information even from the visible spectrum, achieving high-precision hyperspectral pathology image segmentation is crucial for modeling the background across hyperspectral bands.
Inspired by the powerful contextual modeling capability of Transformers, we formulate the learning of cross-spectral contextual features for hyperspectral pathology image segmentation as a sequential prediction process of transformers for the first time.
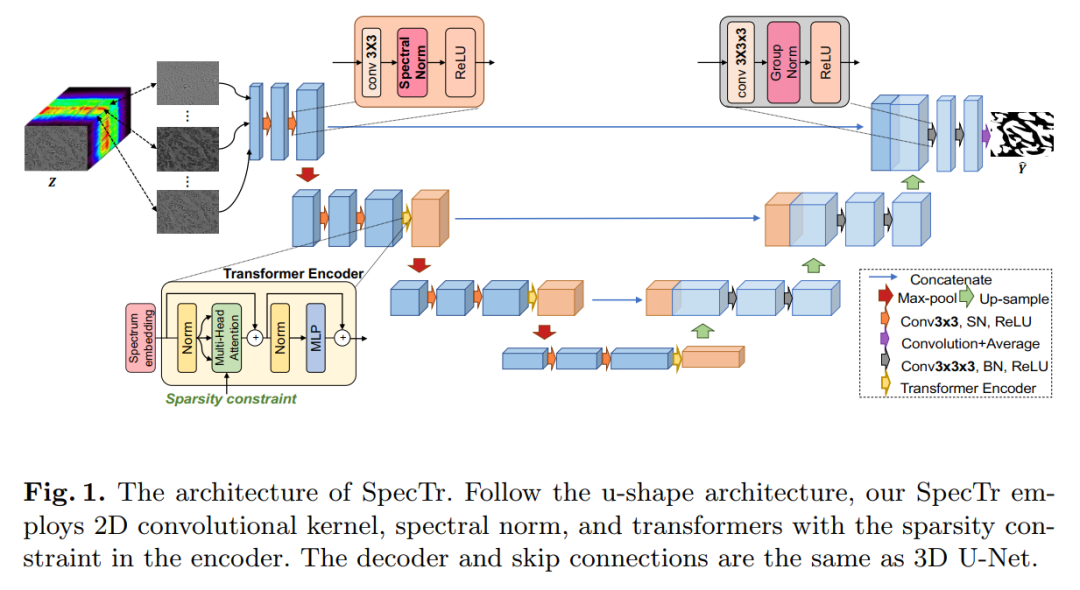
To assist the spectral context learning process, we introduce two important strategies:
(1) A sparse scheme makes the learned contextual relationships sparse, eliminating interference from redundant spectral bands;
(2) Spectral normalization, i.e., individual group normalization for each spectral band, alleviates troubles caused by the uneven underlying distribution of spectral bands.
We name our method the Spectral Transformer (SpecTr), which has two benefits:
(1) A strong ability to model long-range dependencies between spectral bands,
(2) It jointly explores spatial-spectral features of HSI.
Experiments show that SpecTr outperforms other competitive methods in hyperspectral pathology image segmentation benchmarks without requiring pre-training.
4. TransBTS: Multimodal Brain Tumor Segmentation Using Transformer
TransBTS: Multimodal Brain Tumor Segmentation Using Transformer

Affiliations: University of Science and Technology Beijing, North Carolina, etc.
Code: https://github.com/Wenxuan-1119/TransBTS
Paper: https://arxiv.org/abs/2103.04430
Summary in One Sentence: Our first attempt to utilize Transformers for 3D MRI brain tumor segmentation in 3D CNN: TransBTS, unlike TransUNet, this network is based on 3D CNN and can process image slices at once, achieving SOTA! Outperforms Attention U-Net, V-Net, etc., code just open-sourced!
Transformers, which benefit from using self-attention mechanisms for global (long-range) information modeling, have recently achieved success in natural language processing and 2D image classification. However, local and global features are crucial for dense prediction tasks, especially for 3D medical image segmentation.
In this paper, we utilize Transformers for MRI brain tumor segmentation in 3D CNN for the first time and propose a novel network structure called TransBTS based on an encoder-decoder architecture.
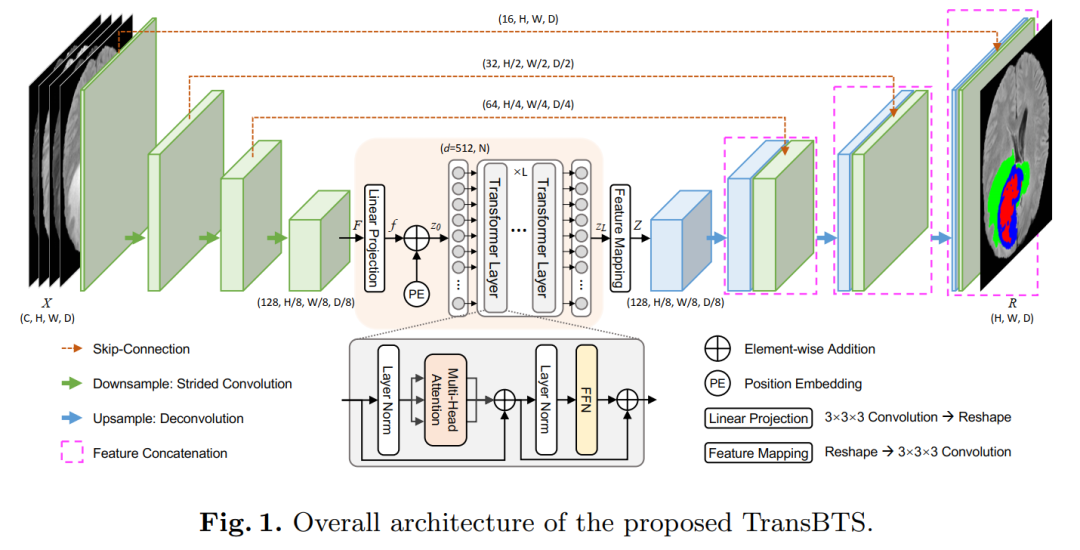
To capture local 3D contextual information, the encoder first extracts volumetric spatial feature maps using 3D CNN. Meanwhile, the feature maps used for mapping tokens are carefully improved, and these tokens are fed into the Transformer for global feature modeling. The decoder leverages the capabilities of Transformer embeddings and performs progressive upsampling to predict detailed segmentation maps.
Experimental results on the BraTS 2019 dataset show that TransBTS outperforms state-of-the-art methods for brain tumor segmentation in 3D MRI scans.
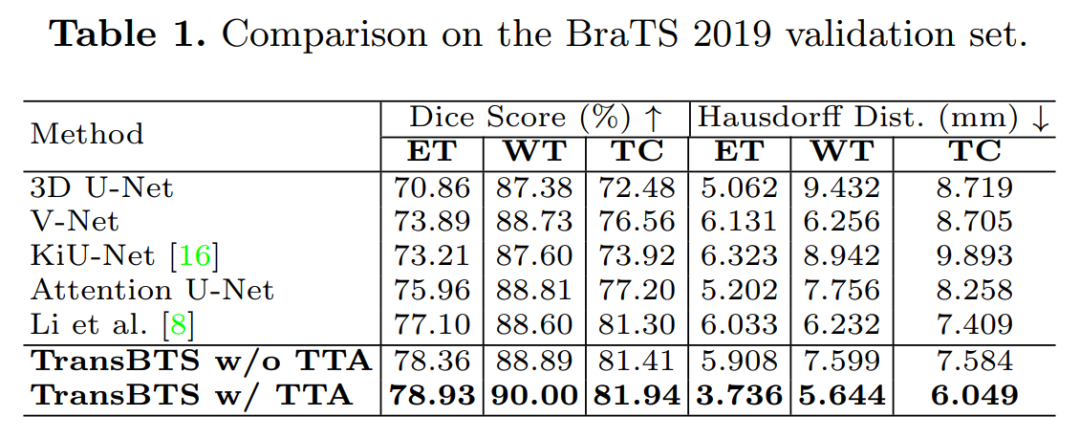
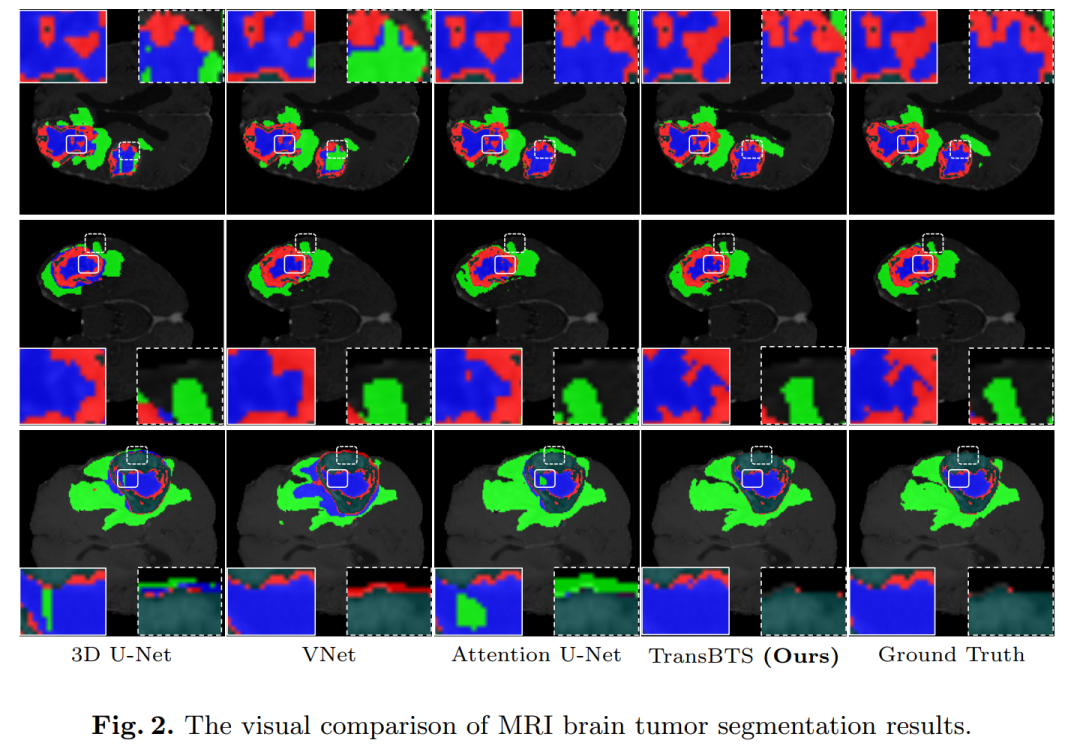
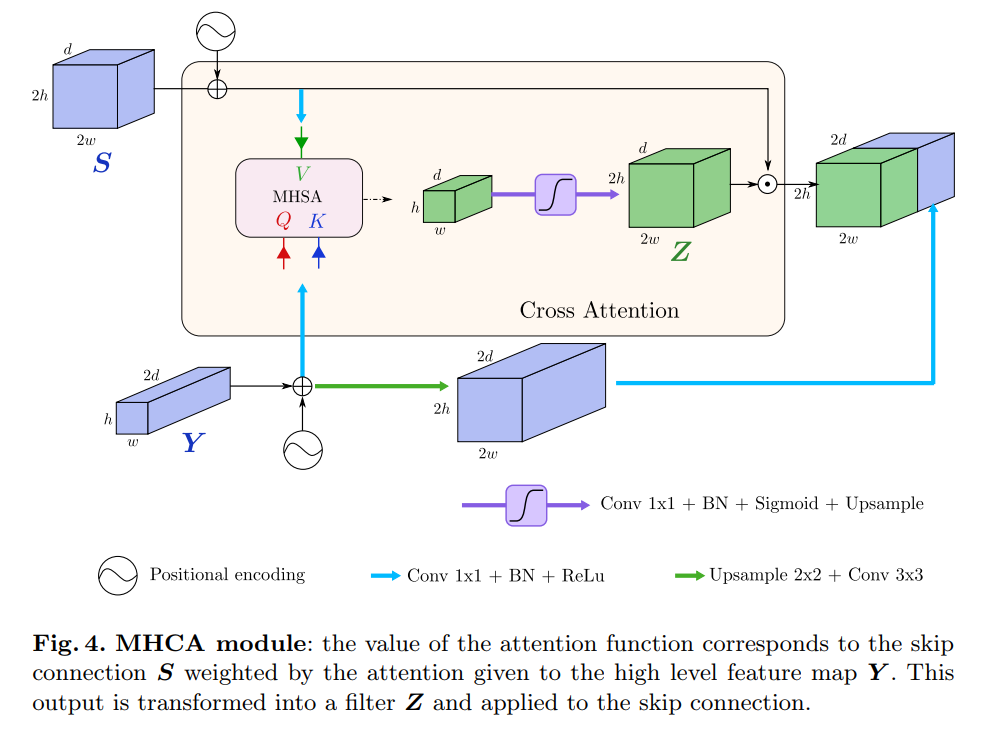
5. U-Net Transformer: Self and Cross Attention for Medical Image Segmentation
U-Net Transformer: Self and Cross Attention for Medical Image Segmentation

Affiliations: National Institute of Applied Sciences, France, etc.
Paper: https://arxiv.org/abs/2103.06104
Summary in One Sentence: U-Transformer works! It uses self-attention and cross-attention modules to model long-range interactions and spatial dependencies, outperforming Attn U-Net and other networks.
Medical image segmentation remains particularly challenging for complex and low-contrast anatomical structures. In this paper, we introduce the U-Transformer network, which combines the U-shaped structure with self-attention and cross-attention from Transformers for image segmentation.
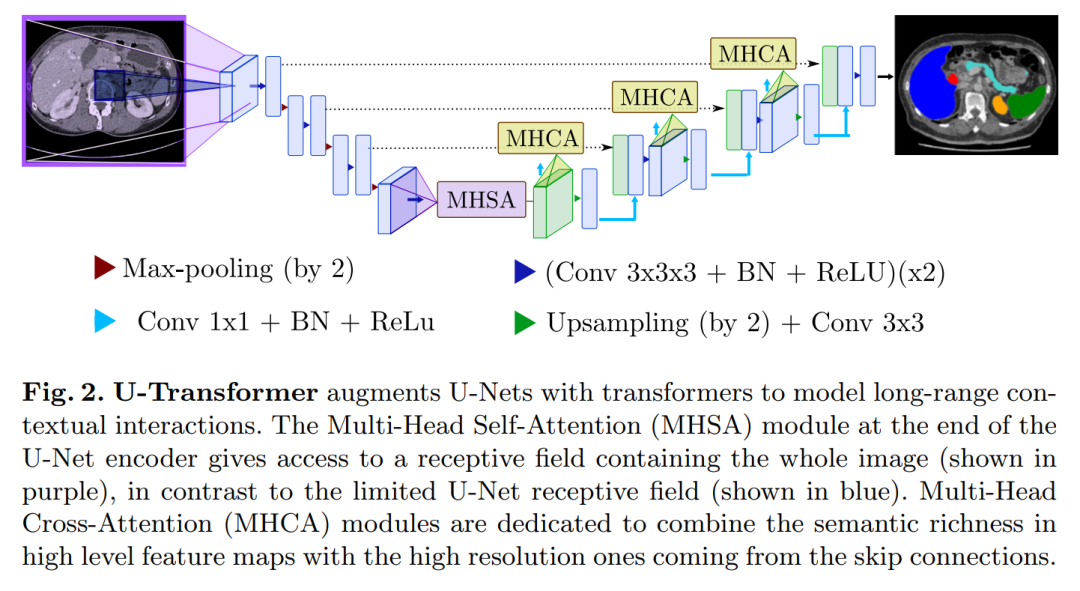
The U-Transformer overcomes the inability of U-Net to model long-range contextual interactions and spatial dependencies, which are crucial for precise segmentation in challenging contexts. To this end, attention mechanisms are merged at two main levels: the self-attention module utilizes global interactions between encoder features, while the cross-attention in the skip connections achieves fine spatial recovery features in the U-Net decoder by filtering out non-semantic information.
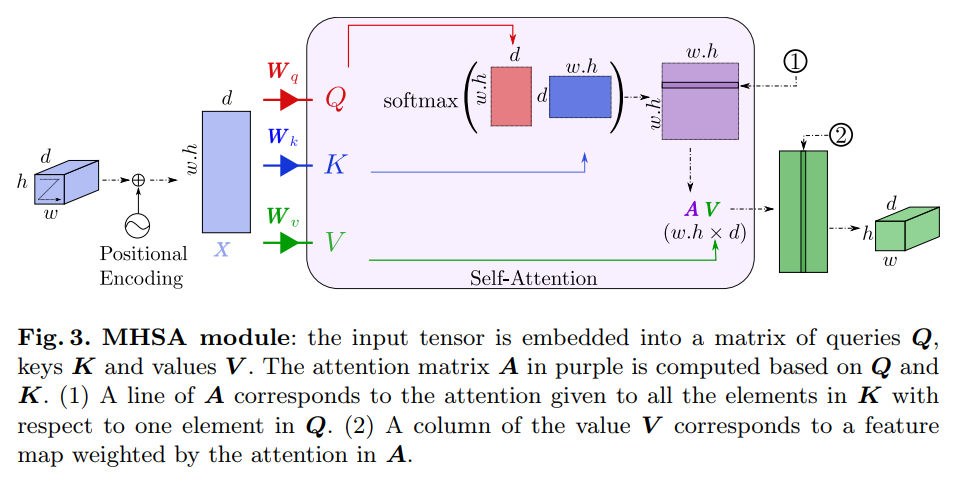
6. UNETR: Transformers for 3D Medical Image Segmentation
UNETR: Transformers for 3D Medical Image Segmentation

Affiliations: NVIDIA
Paper: https://arxiv.org/abs/2103.10504
Summary in One Sentence: Redesigns the 3D medical image segmentation task as a 1D sequence-to-sequence prediction problem, achieving SOTA! Performance exceeds SegResNet, Att-UNet, etc.
In recent years, fully convolutional neural networks (FCNN) with a contracting path and an expanding path (e.g., encoder and decoder) have shown a prominent position in various medical image segmentation applications. In these architectures, the encoder plays an indispensable role by learning global contextual representations, which will be further used by the decoder for semantic output predictions. Despite the success, the limitations of convolutional layers, which are the main building blocks of FCNNs, restrict the ability to learn long-range spatial correlations in such networks.
Inspired by the recent success of the NLP Transformer in long-range sequence learning, we redesign the task of volumetric (3D) medical image segmentation as a sequence-to-sequence prediction problem. Specifically, we introduce a novel architecture called UNETR (UNET Transformers), which uses pure Transformers as encoders to learn sequential representations of inputs and effectively capture global multi-scale information.
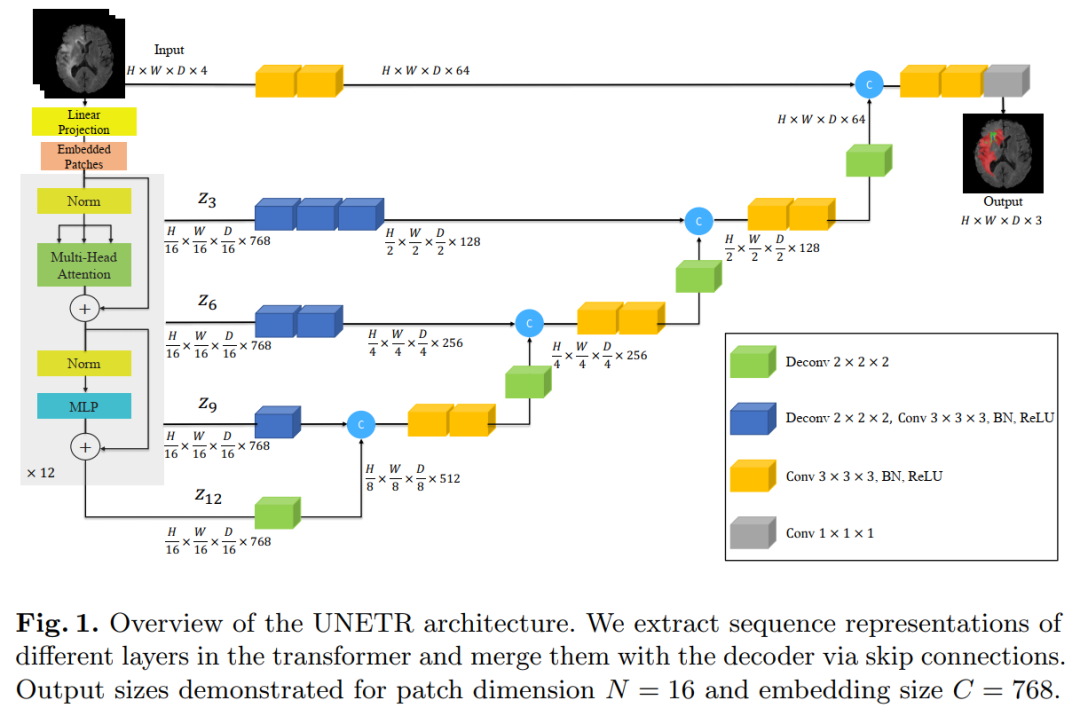
The transformer encoder is directly connected to the decoder through skip connections of different resolutions to compute the final semantic segmentation output.
We have extensively validated our proposed model’s performance on the medical segmentation MSD dataset for volumetric brain tumor and spleen segmentation tasks across different imaging modalities (i.e., MR and CT), and our results consistently demonstrate good benchmarks.
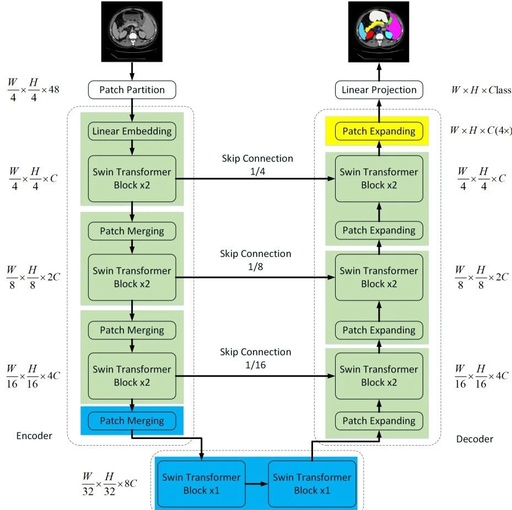
7. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation

Affiliations: Technical University of Munich, Fudan University, Huawei (Tian Qi et al.)
Code: https://github.com/HuCaoFighting/Swin-Unet
Paper: https://arxiv.org/abs/2105.05537
Summary in One Sentence: The first U-Net-like medical image segmentation network based on pure Transformers, utilizing Swin Transformer to construct encoders, bottleneck, and decoders, achieving SOTA! Performance exceeds TransUnet, Att-UNet, etc., code will be open-sourced soon!
In recent years, convolutional neural networks (CNNs) have achieved milestone progress in medical image analysis. In particular, deep neural networks based on U-shaped architectures and skip connections have been widely applied in various medical image tasks. However, despite the excellent performance of CNNs, due to the limitations of convolution operations, they cannot well learn global and long-range semantic information interactions.
In this paper, we propose Swin-Unet, which is a Unet-like pure Transformer for medical image segmentation.
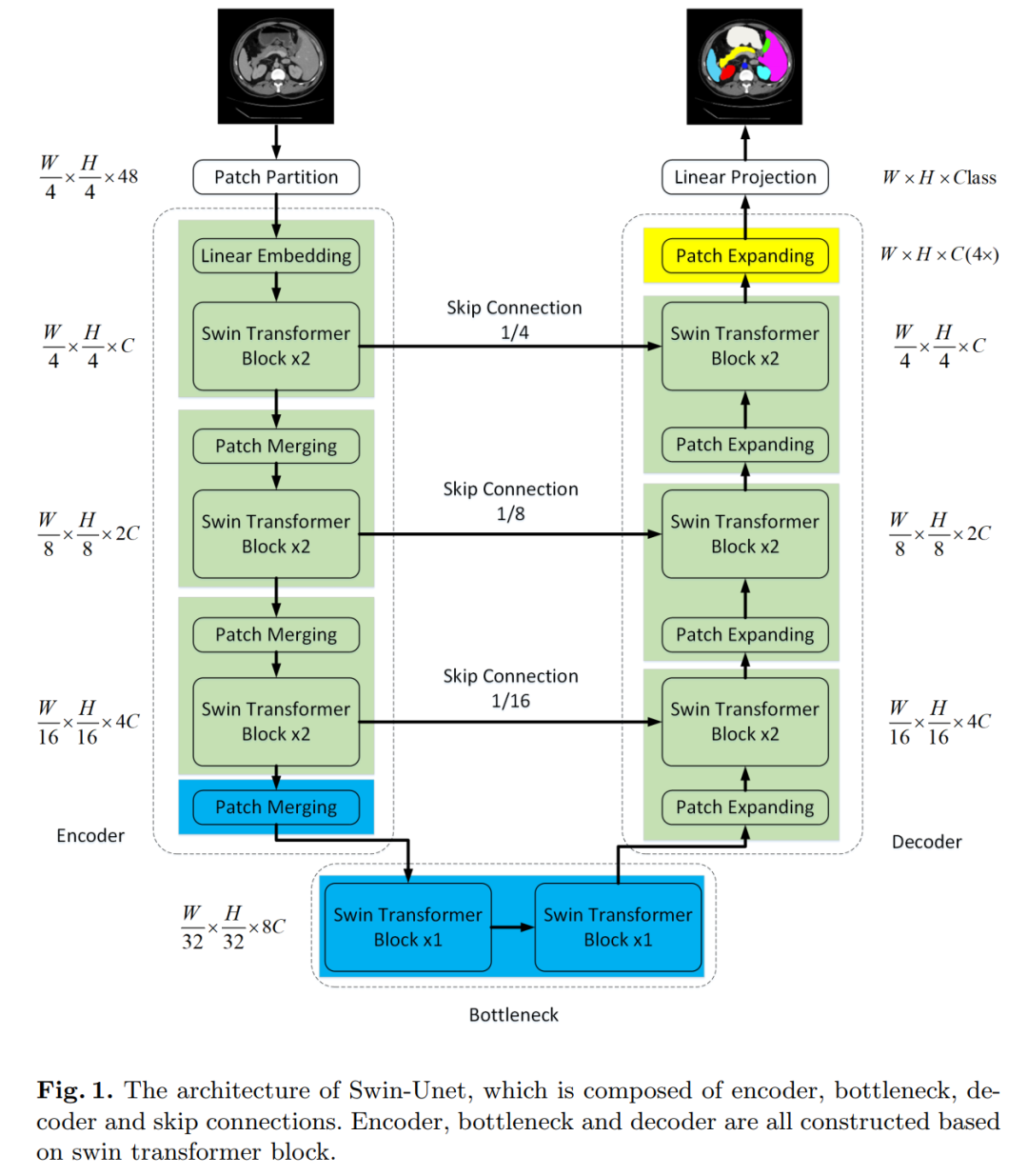
Tokenized image patches are fed into the Transformer-based U-shaped En-Decoder architecture through skip connections for local-global semantic feature learning. Specifically, we use a hierarchical Swin Transformer with shifted windows as the encoder to extract contextual features.
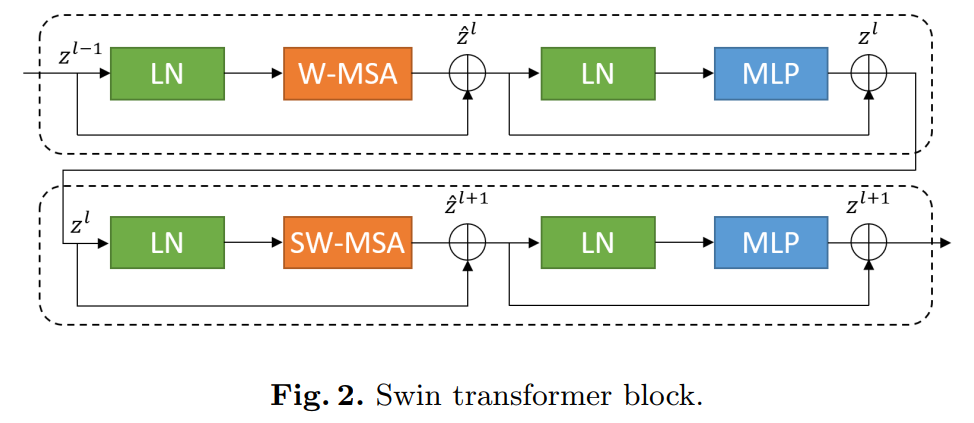
And designed a decoder based on symmetric Swin Transformer with patch expansion layers to perform upsampling operations to restore the spatial resolution of feature maps. Experiments on multi-organ and cardiac segmentation tasks, with direct downsampling and upsampling of 4 times for inputs and outputs, show that the pure Transformer-based U-shaped encoder/decoder network outperforms those based on fully convolutional or combinations of transformers and convolutions.
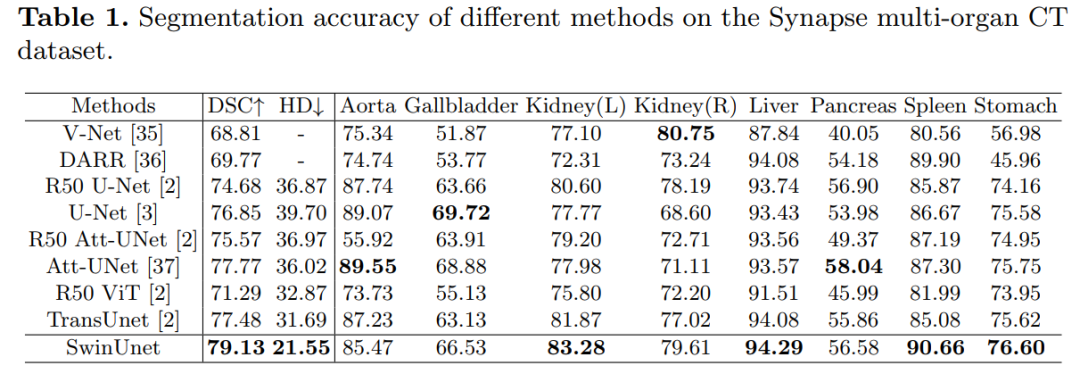
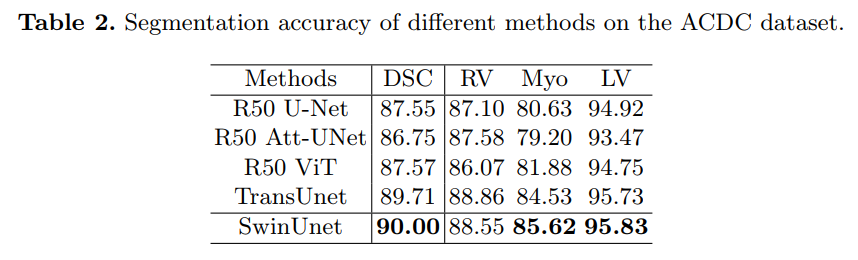
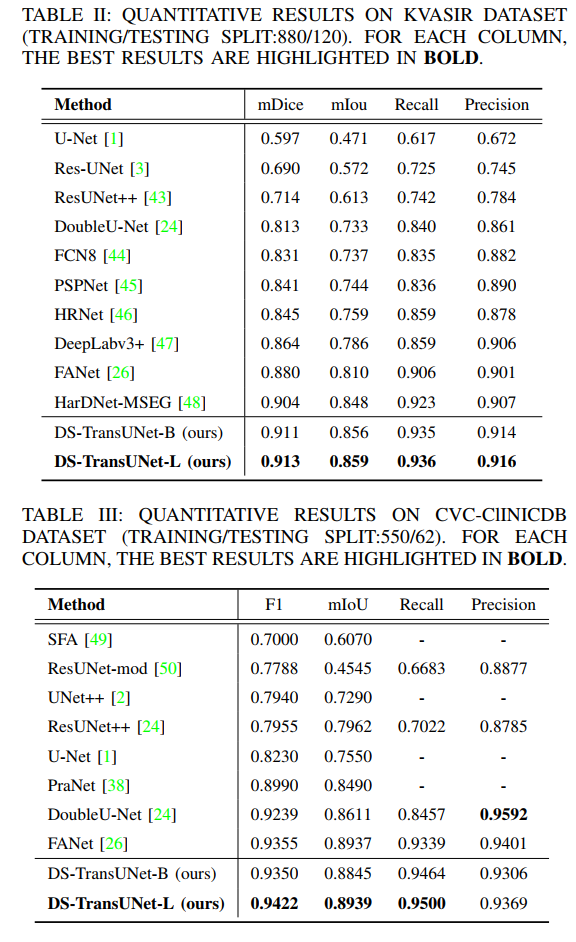
8. DS-TransUNet: Dual Swin Transformer U-Net for Medical Image Segmentation
DS-TransUNet: Dual Swin Transformer U-Net for Medical Image Segmentation

Affiliations: Harbin Institute of Technology (Shenzhen)
Paper: https://arxiv.org/abs/2106.06716
Summary in One Sentence: Uses Swin Transformer as encoder and decoder, introduces U-shaped design structure, achieving SOTA! Performance exceeds TransFuse, PraNet, FANet, etc.
Thanks to the development of deep learning, automatic medical image segmentation has made significant progress. However, most existing methods are based on convolutional neural networks (CNNs), which cannot establish long-range dependencies and global contextual connections due to the limitations of receptive fields in convolution operations. Inspired by the success of Transformers in modeling long-range contextual information, several researchers have made considerable efforts to design powerful variants of U-Net based on Transformers. Additionally, the patch division used in visual Transformers often ignores the pixel-level intrinsic structural features within each patch.
To alleviate these issues, we propose a novel deep medical image segmentation framework called Dual Swin Transformer U-Net (DS-TransUNet), which may be the first attempt to incorporate the advantages of hierarchical Swin Transformers into standard encoder-decoder U-shaped architectures to improve the semantic segmentation quality of various medical images.
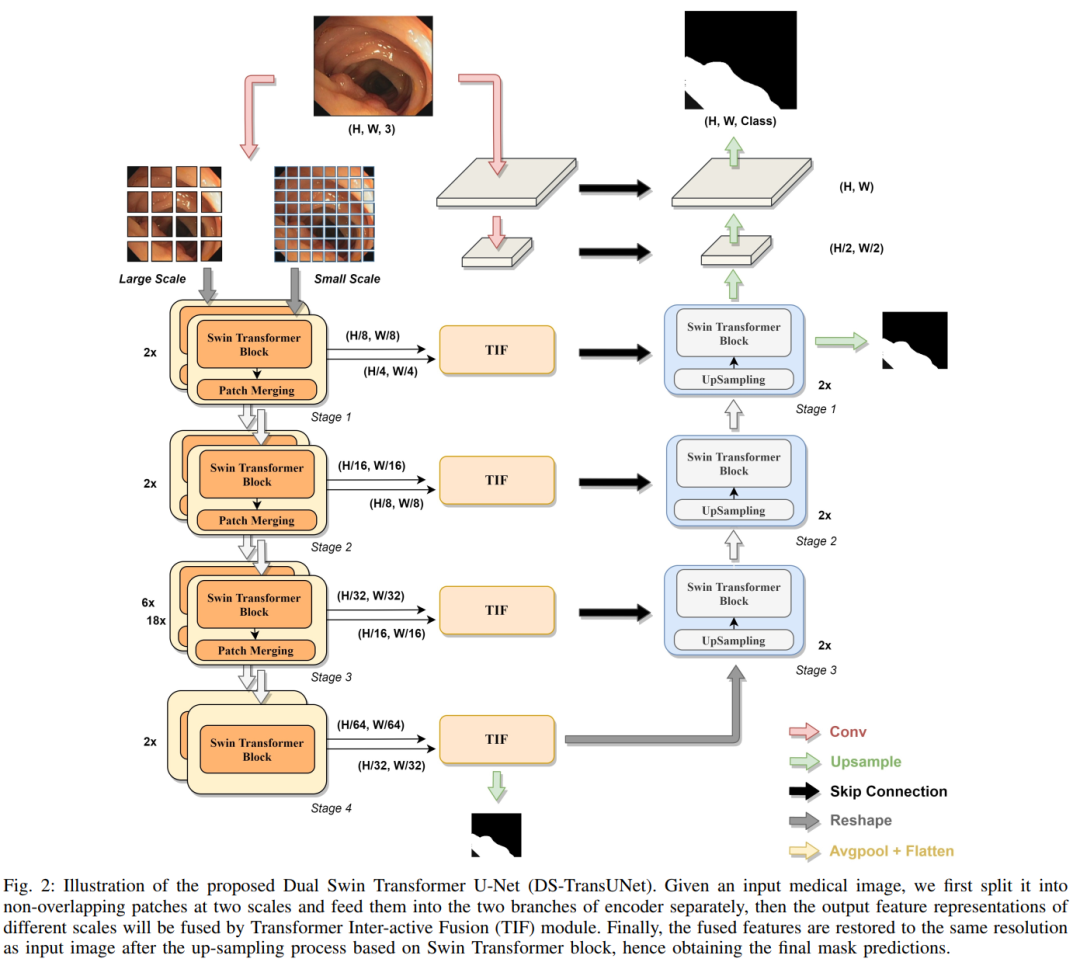
Unlike many previous transformer-based solutions, the proposed DS-TransUNet first adopts a dual-scale encoder subnet based on Swin Transformer to extract coarse and fine-grained feature representations of different scales. As the core component of our DS-TransUNet, we propose a carefully designed Transformer Interactive Fusion (TIF) module, which effectively establishes global dependencies between features of different scales through self-attention mechanisms.
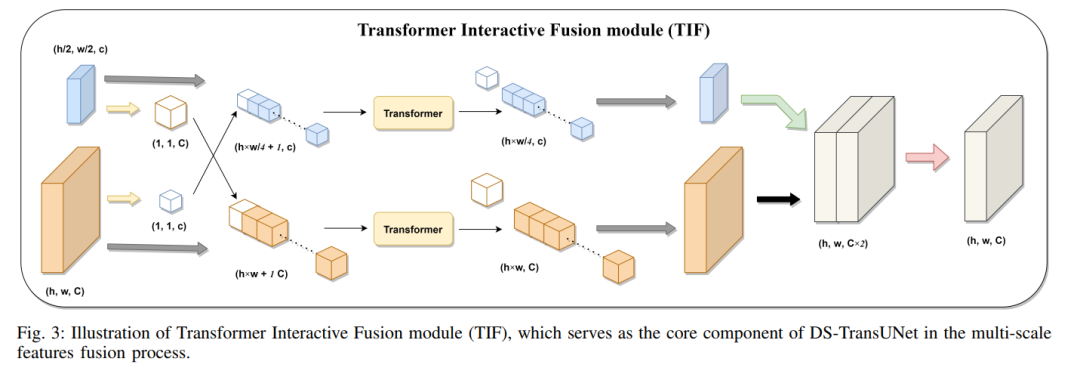
Additionally, we also introduce Swin Transformer blocks into the decoder to further explore long-range contextual information during the upsampling process. Extensive experiments across four typical medical image segmentation tasks demonstrate the effectiveness of DS-TransUNet and show that our approach significantly outperforms state-of-the-art methods.
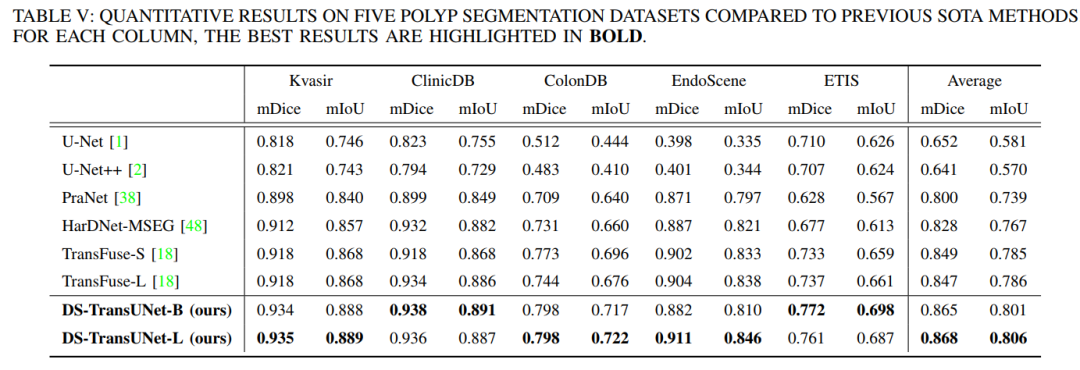
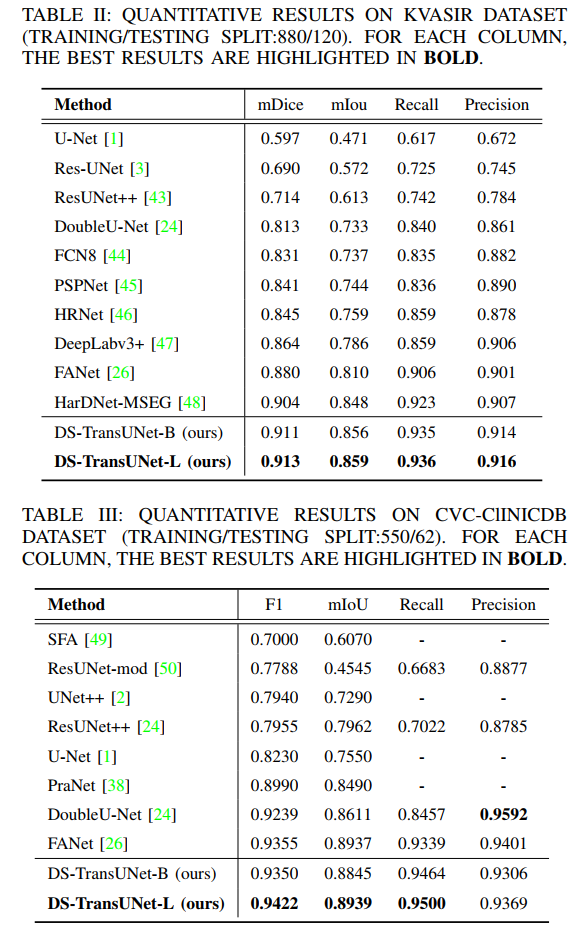
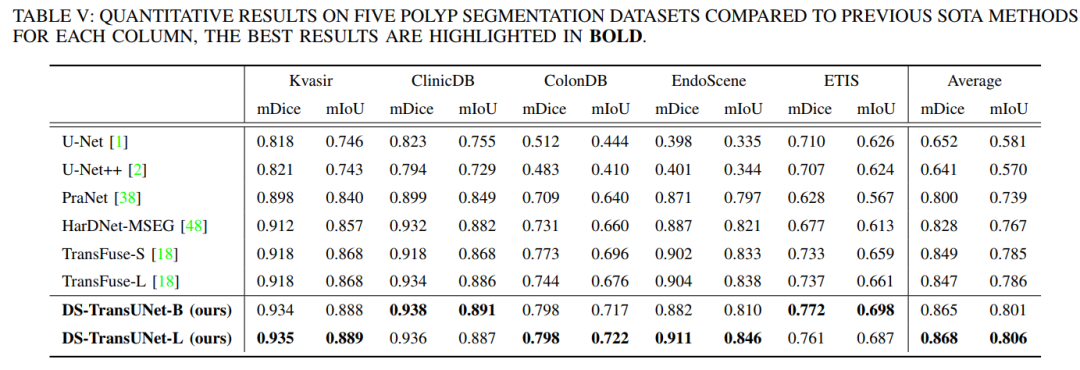
9. UTNet: A Hybrid Transformer Architecture for Medical Image Segmentation
UTNet: A Hybrid Transformer Architecture for Medical Image Segmentation

Affiliations: Rutgers University, etc.
Paper: https://arxiv.org/abs/2107.00781
Summary in One Sentence: Achieves SOTA! Performance exceeds ResUNet and other networks.
Transformer architectures have achieved success in many natural language processing tasks. However, their application in medical vision remains largely unexplored.
In this study, we propose UTNet, a simple yet powerful hybrid transformer architecture that integrates self-attention into convolutional neural networks to enhance medical image segmentation.
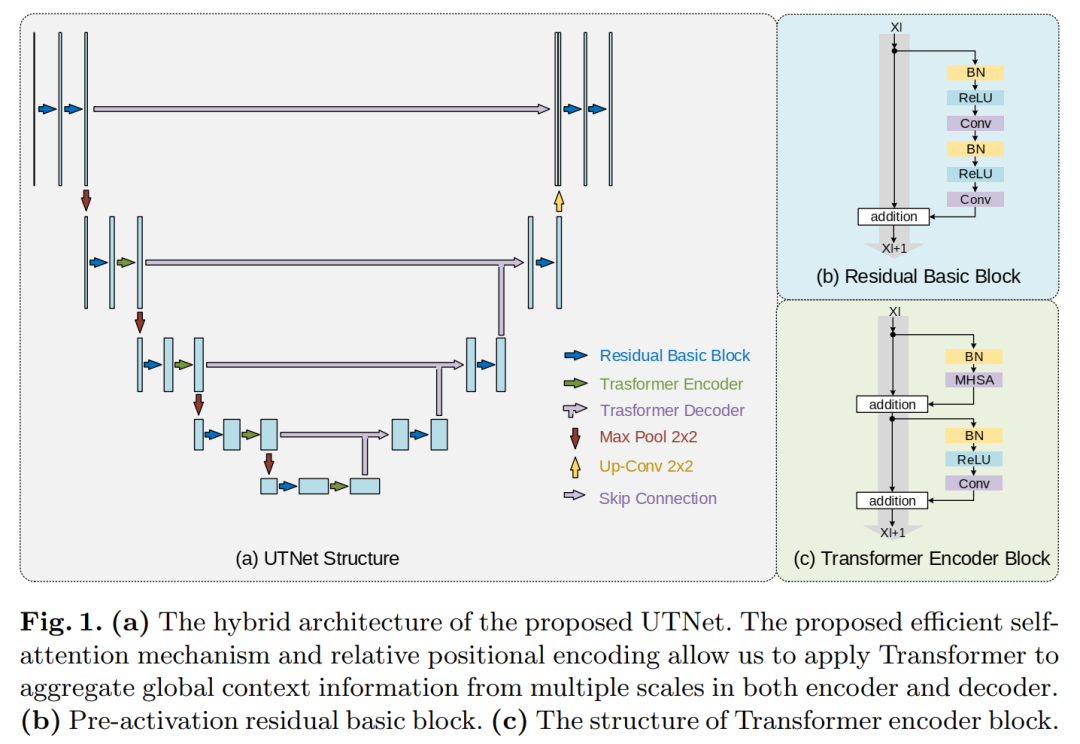
UTNet applies self-attention modules in the encoder and decoder to capture long-range dependencies of different scales with minimal overhead. To this end, we propose an efficient self-attention mechanism and relative position encoding that significantly reduces the complexity of self-attention operations from O(n2) to approximately O(n). A new self-attention decoder is also proposed to recover fine-grained details from skip connections from the encoder.
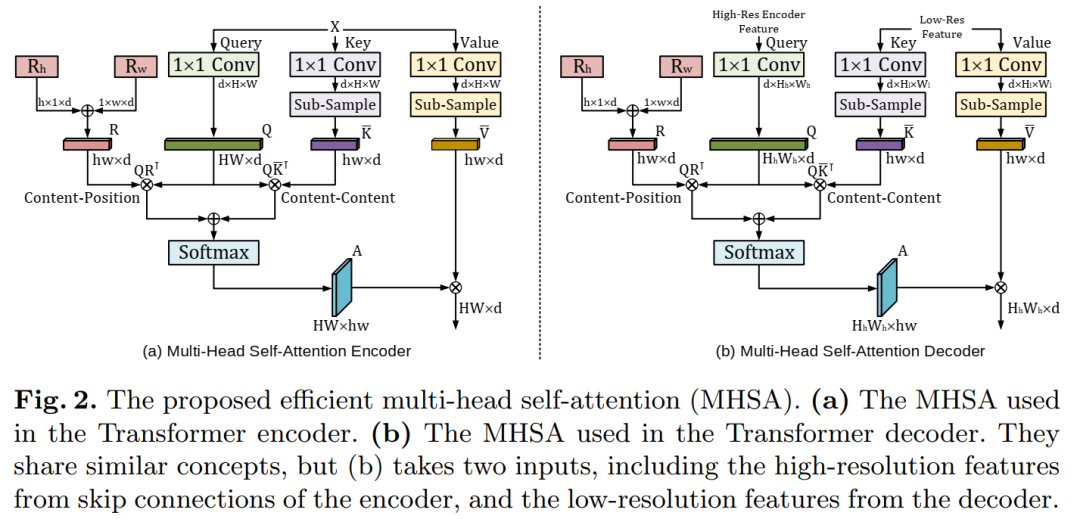
Our method addresses the dilemma that transformers require large amounts of data to learn visual inductive biases. Our hybrid layer design allows transformers to be initialized as convolutional networks without the need for pre-training. We have evaluated UTNet on a multi-label, multi-vendor cardiac MRI queue. UTNet demonstrates superior segmentation performance and robustness over state-of-the-art methods, showing promise for good generalization in other medical image segmentation tasks.
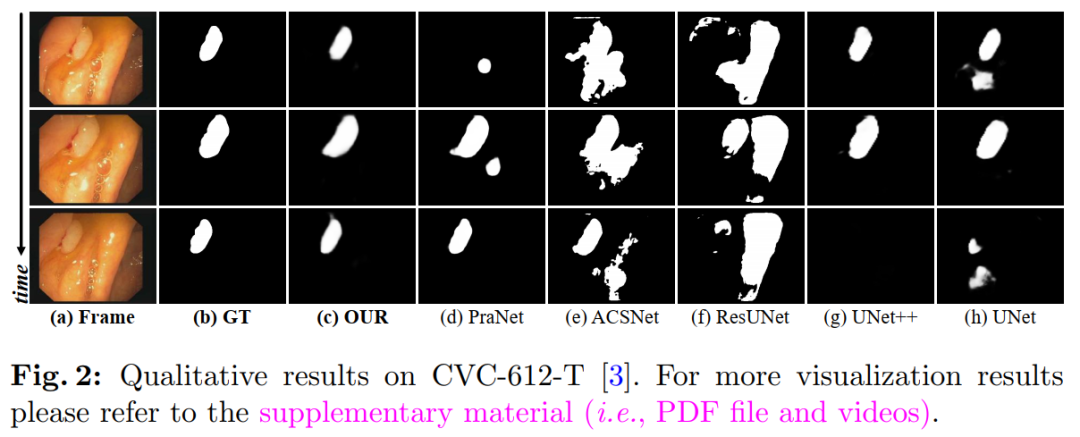
10. PNS-Net: Progressively Normalized Self-Attention Network for Video Polyp Segmentation
PNS-Net: Progressively Normalized Self-Attention Network for Video Polyp Segmentation

Affiliations: IIAI, Wuhan University, SimulaMet
Paper: https://arxiv.org/abs/2105.08468
Code: https://github.com/GewelsJI/PNS-Net
Summary in One Sentence: Achieves SOTA! Performance exceeds PraNet, ResUNet, and other networks.
Existing video polyp segmentation (VPS) models typically use convolutional neural networks (CNNs) to extract features. However, due to their limited receptive fields, CNNs cannot fully utilize global temporal and spatial information in consecutive video frames, leading to false positive segmentation results.
In this paper, we propose a novel PNS-Net (Progressively Normalized Self-Attention Network), which can effectively learn representations from polyp videos at real-time speeds (~140fps) on a single RTX 2080 GPU without post-processing.
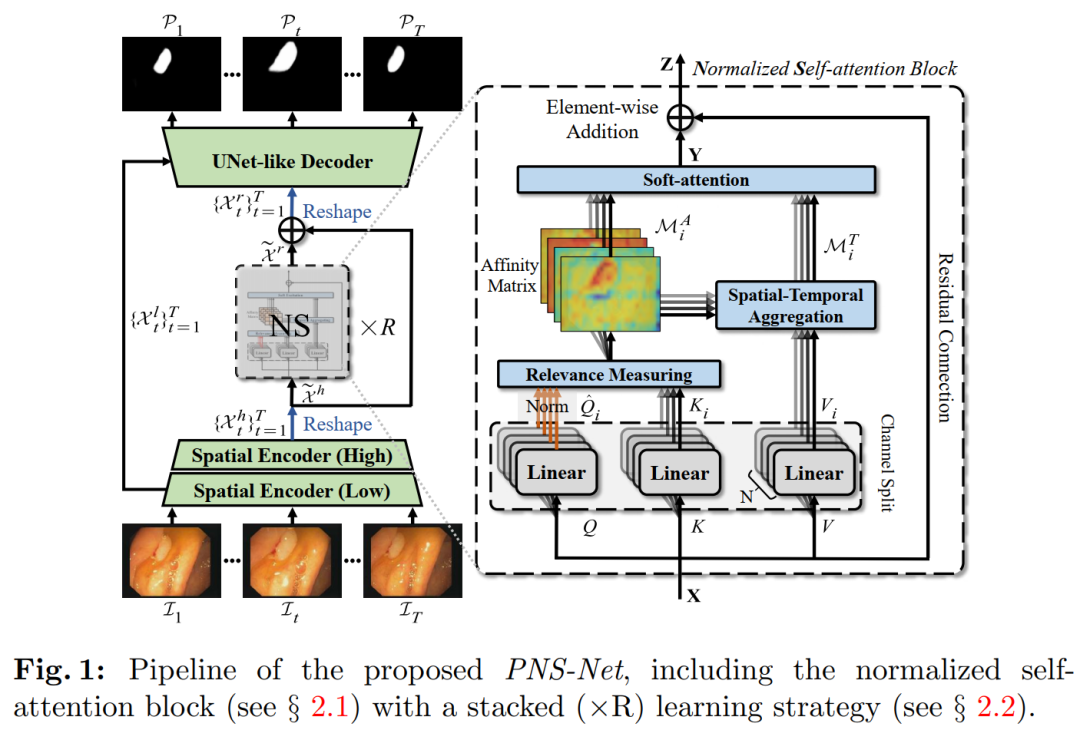
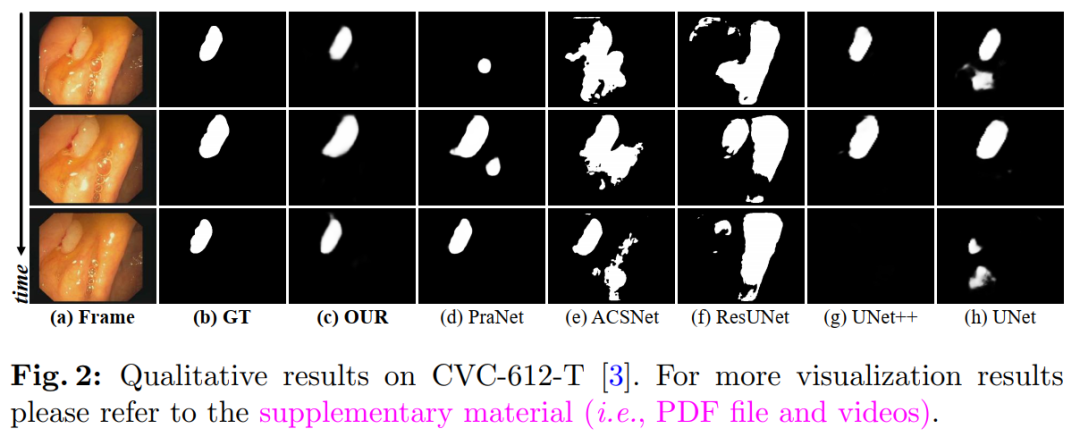
Our PNS-Net is entirely based on fundamental normalized self-attention blocks, fully equipped with recursion and CNN. Experiments conducted on challenging VPS datasets show that the proposed PNS-Net achieves state-of-the-art performance. We also conducted extensive experiments to investigate the effectiveness of channel splitting, soft attention, and progressive learning strategies. We found that our PNS-Net performs well under various settings, making it a promising solution for VPS tasks.

The above 10 papers on medical image segmentation can be downloaded
Reply in the background: Medical image segmentation to download the above paper PDFs
CVPR and Transformer materials can be downloaded
Reply in the background: CVPR2021 to download the collection of CVPR 2021 papers and open-source papers
Reply in the background: Transformer reviews to download the latest two Transformer review PDFs
CVer-Transformer group chat established
Scan to add the CVer assistant, and apply to join the CVer-Transformer WeChat group chat, covering directions: object detection, image segmentation, object tracking, face detection & recognition, OCR, pose estimation, super-resolution, SLAM, medical imaging, Re-ID, GAN, NAS, depth estimation, autonomous driving, lane line detection, model pruning & compression, denoising, dehazing, deraining, style transfer, remote sensing images, behavior recognition, video understanding, image fusion, image retrieval, paper submission & communication, PyTorch and TensorFlow, etc.
Be sure to note: research direction + location + school/company + nickname (e.g., Transformer + Shanghai + SJTU + Kaka). According to the format note, you can be approved and invited to join the group faster.
▲ Long press to add the assistant WeChat to join the group chat
▲ Click the card above to follow the CVer official account
Sorting is not easy, please like and look at