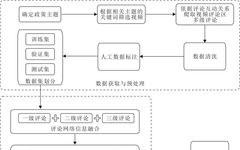
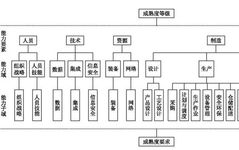
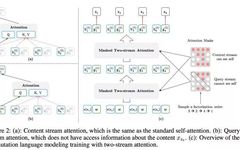
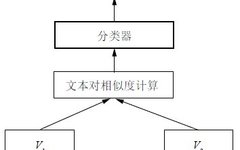
Understanding the Working Principle of GPT’s Transformer Technology
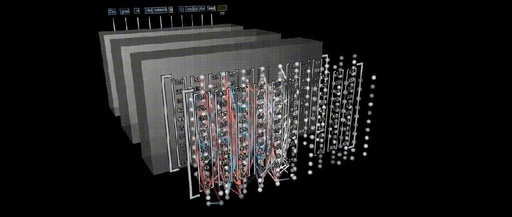
Introduction The Transformer was proposed in the paper“Attention is All You Need”, and is now the recommended reference model for Google Cloud TPU. By introducing self-attention mechanisms and positional encoding layers, it effectively captures long-distance dependencies in input sequences and performs excellently when handling long sequences. Additionally, the parallel computing capabilities of the Transformer model … Read more