Due to the current lack of automatic scoring for subjective questions in multilingual education, this paper proposes an automatic scoring system for subjective questions based on a Siamese network and the BERT model. The problem text and answer text of subjective questions are processed through natural language preprocessing using the BERT model to obtain sentence vectors. The BERT model has been trained on a large-scale multilingual corpus, and the resulting text vectors contain rich contextual semantic information and can handle multiple language information. Then, the sentence vectors of the problem text and answer text are used to compute semantic similarity through a deep network Siamese network, and finally connected to a logistic regression classifier to complete the automatic scoring of subjective questions. The dataset used in the experiments consists of an English dataset provided by the Hewlett Foundation and a translated Chinese dataset, with the quadratic weighted Kappa coefficient as the evaluation metric for the model. Experimental results show that compared to other benchmark models, the automatic scoring system based on the Siamese network and BERT model achieves the best results across various data subsets.

Scan the QR code to read the full article
The automatic scoring system for subjective questions based on the Siamese network and BERT model proposed in this article can transform the problem text and students’ answer texts in multiple languages (mainly Chinese and English) into a natural language processing text matching problem, using the pre-trained language model BERT, which has learned general semantic representation from large corpora, applying the learned prior knowledge directly to specific tasks to improve the performance of the target task. Utilizing the advantages of the BERT model and the Siamese network structure, the similarity calculation between the problem text and the students’ answer texts is completed, designing the automatic scoring system for subjective questions.
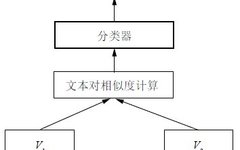
The structure of the automatic scoring model is shown in Figure 1. The entire model follows the Siamese network structure, mainly consisting of two layers of neural networks, namely the encoding layer and the output layer. The encoding layer processes using the same pre-trained model BERT, initialized directly with BERT’s original weights, fine-tuned on specific datasets. This training method can better capture the relationships between sentences, generating higher quality sentence vectors. In the pre-trained BERT model, dynamic vectors for the two text pairs are generated, followed by a pooling layer to obtain a vector that contains the meaning of the entire text. In the output layer, the obtained sentence vectors are used to compute the similarity between text pairs, and finally connected to a logistic regression classifier to obtain the students’ scores.
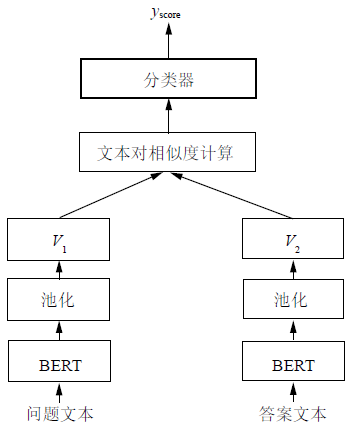
The BERT model is a model trained on a large-scale unannotated corpus, obtaining text representation vectors that contain rich semantic representations, directly applying these text representations and model parameters to downstream target tasks. This article utilizes the trained model as text vectors embedded in other task models. The structure diagram of the BERT model is shown in Figure 2.
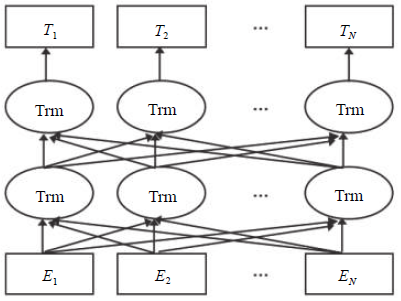
Figure 2 Structure of BERT
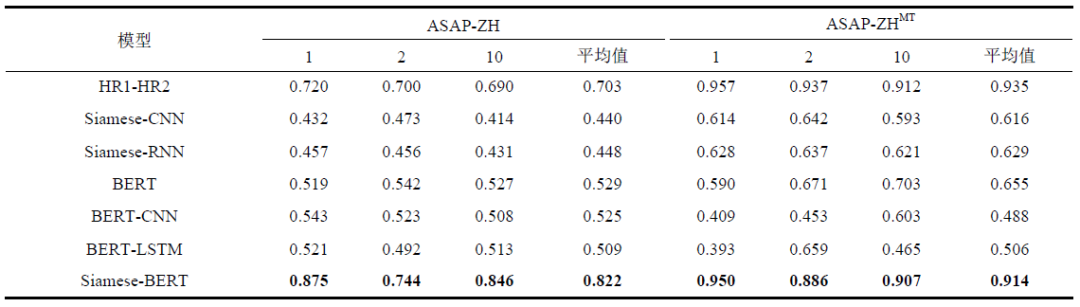
Table 1 shows the experimental results of the English dataset ASAP, with bold font indicating the best experimental results. The Siamese-BERT model studied in this paper achieves the best results on various data subsets compared to other deep neural network models. Table 2 shows the experimental results of the Chinese datasets ASAP-ZH and ASAP-ZHMT, using the quadratic weighted Kappa (QWK) to evaluate the experimental results across all models, with bold font indicating the best experimental results. The experimental results are similar to those of the English dataset, with the Siamese-BERT model achieving the best results. However, on the ASAP-ZHMT dataset, the results of the Siamese-BERT model differ from the human scoring HR1-HR2 results, possibly due to subsequent manual corrections made to this dataset.
Table 1 Experimental Results of Different Models Based on the ASAP Dataset
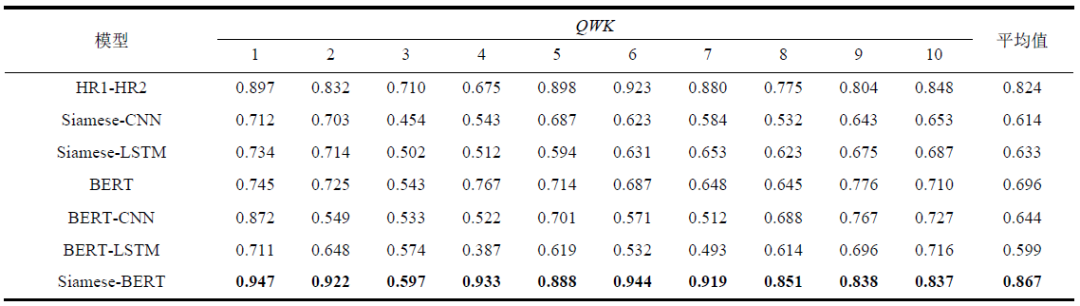
Table 2 Experimental Results of Different Models Based on the Chinese Dataset
The Siamese-BERT model for automatic scoring of subjective questions enhances performance significantly by using the Siamese network and the pre-trained model BERT compared to merely using the Siamese network and the BERT model. Experimental results also indicate that compared to other benchmark models, the Siamese-BERT model achieves the best scoring results on both Chinese and English datasets. Future research will focus on the automatic correction of student answers to complete the development of the entire intelligent education system.