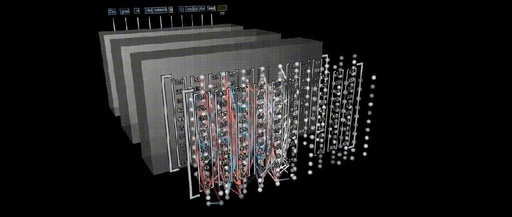
Introduction
The Transformer was proposed in the paper“Attention is All You Need”, and is now the recommended reference model for Google Cloud TPU. By introducing self-attention mechanisms and positional encoding layers, it effectively captures long-distance dependencies in input sequences and performs excellently when handling long sequences. Additionally, the parallel computing capabilities of the Transformer model also accelerate training speed, driving significant breakthroughs in deep learning in the field of natural language processing, such as the BERT (Bidirectional Encoder Representations from Transformers) model in machine translation tasks.

This article is based on arthurchiao【 translated from the original link】 Chapter 5 of the 2024 Deep Learning series But what is a GPT? Visual intro to transformers learning video. The original video is highly recommended. The author has also compiled a full translated PDF material (27-minute video, the translated manuscript is about 8,000 words), feel free to message for collaborative learning.

This translation uses a “text + animated image” visualization method, which is easy to understand, to roughly outline and introduce the working principle of the Transformer and the internal actual flow of data changes that occur.


The Transformer predicts the next word. MLP is also known as feed-forward.
Translation organized for reference
-
Translator’s Preface
-
1 Visualizing GPT
-
1.1 Generative: Generative
-
1.2 Pre-trained: Pre-trained
-
1.3 Transformer: A type of neural network architecture
-
1.4 Summary
1 Visualizing Generative Pre-trained Transformer (GPT)
GPT is the abbreviation for Generative Pre-trained Transformer, literally translated as “generative pre-trained transformer”. The first word is straightforward; they are robots used to generate new text. “Pre-trained” (pre-trained) refers to the model having learned from a large amount of data, suggesting that the model can undergo further training and fine-tuning for specific tasks. However, the last word is the most important part. The Transformer is a specific type of neural network, a machine learning model that is the core innovation driving the rapid development of AI today.
1.1 Generative: Generative
“Generative” (Generative) means very straightforwardly, given a segment of input (for example, the most common text input), the model can continue writing (“compose”) further.
1.1.1 Visualization
Here is an example, given “The most effective way to learn computer science is” as input, the model starts to continue writing the subsequent content.

“Generative”: the ability to generate (continue writing) text.
1.1.2 Generative vs. Discriminative (Translator’s Note)
This generative model of text continuation is different from the discriminative models like BERT (used for classification, fill-in-the-blank, etc.),
-
BERT: Pre-trained deep bidirectional Transformers for language understanding (Google, 2019)
1.2 Pre-trained: Pre-trained
“Pre-trained” (pre-trained) refers to the model having learned from a large amount of data, suggesting that the model can undergo further training and fine-tuning for specific tasks.
1.2.1 Visualization
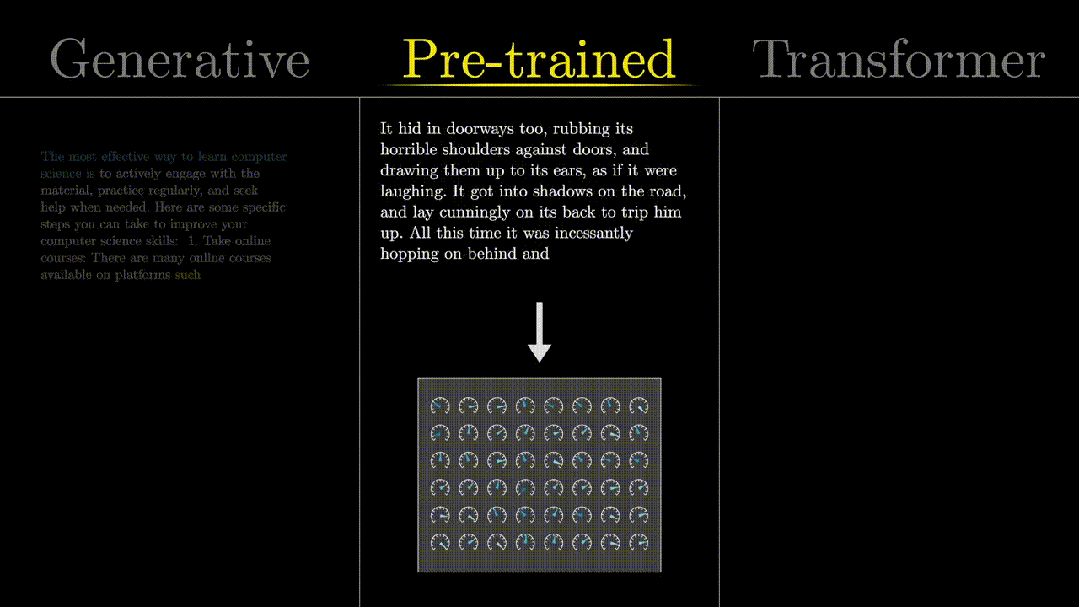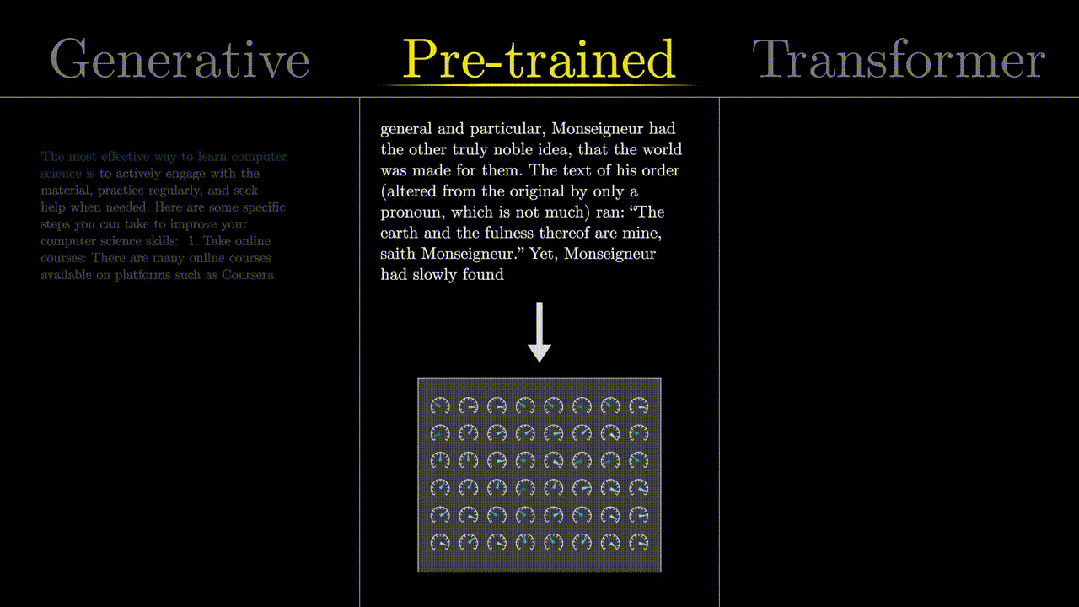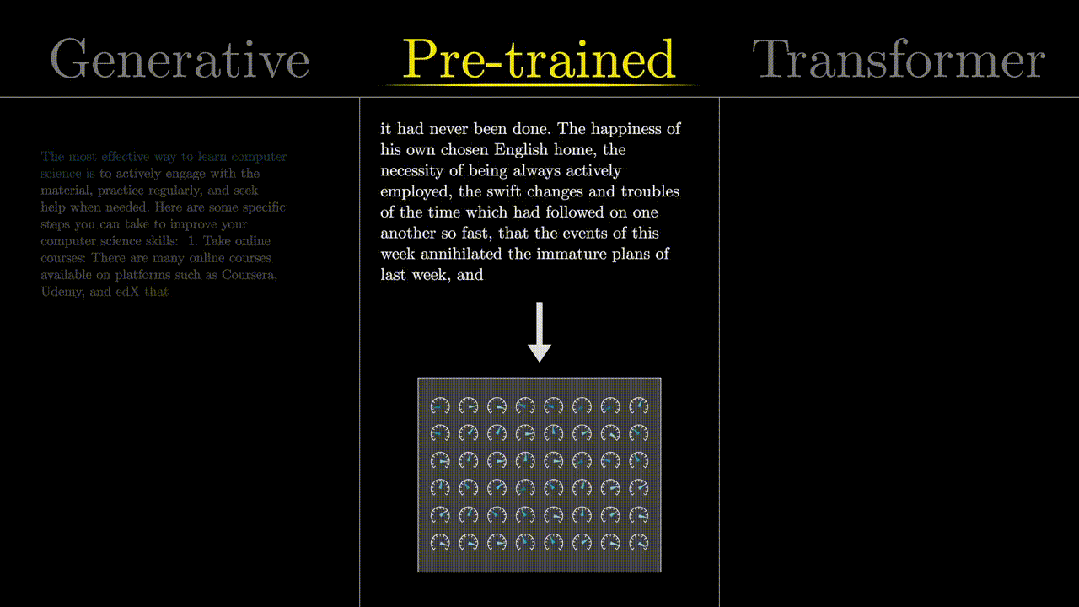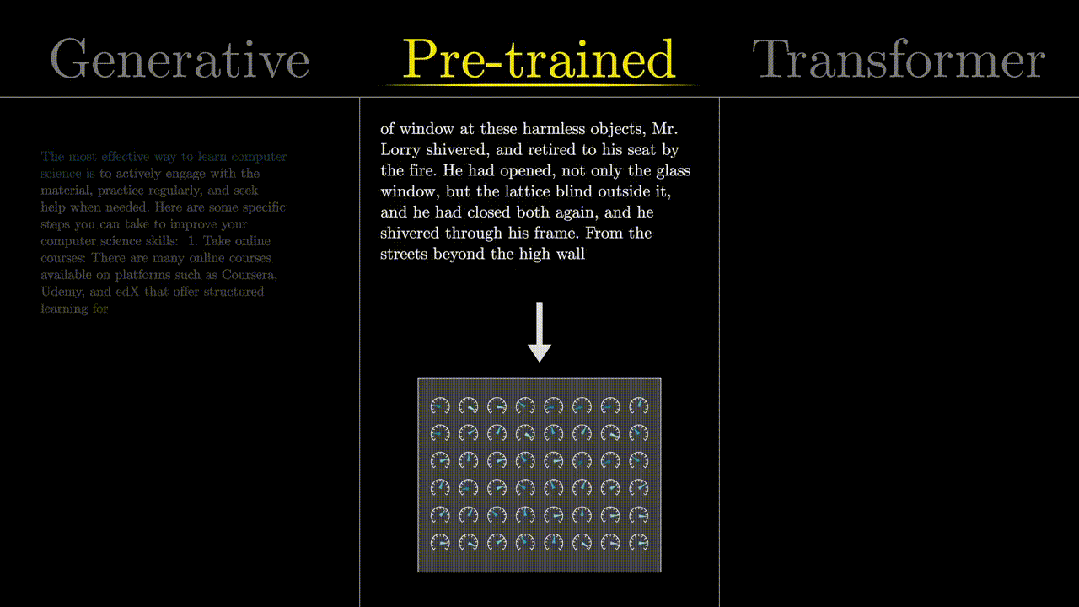
“Pre-trained”: trained with a large amount of data.
A large number of knobs/dials are what we call“model parameters”, and the training process is about continuously optimizing these parameters, which will be detailed later.
1.2.2 Pre-trained vs. Incremental Training (Fine-tuning)
“Pre-” also suggests that the model has the possibility of further training in specific tasks — which we often refer to as “fine-tuning”.
How to fine-tune a pre-trained model: InstructGPT: Training language models to follow instructions based on human feedback (OpenAI, 2022). Translator’s note.
1.3 Transformer: A Type of Neural Network Architecture
Among the three words in “GPT,” the last word, Transformer, is actually the most important. The Transformer is a type of neural network/machine learning model that has become a core innovation in the AI field, driving rapid development in recent years.
Various types of models can be built using the Transformer. Some models take audio input and generate text. This sentence comes from a reverse-working model that can generate artificial speech from text input.
The Transformer is literally translated as “converter” or “transformer”, continuously transforming/converting input data through mathematical operations. Additionally, transformers and transformers (the toy) are also terms related to this word. Translator’s note.

Transformer: A collective term for a type of neural network architecture.

The final output layer of the Transformer. More details will be provided later.
1.4 Summary
Today, many different types of models can be built based on the Transformer, not limited to text, for example,
-
Speech to Text
-
Text to Speech
-
Text to Image: Tools like DALL-E and MidJourney that became popular worldwide in 2022 can transform text descriptions into images, all based on Transformers.
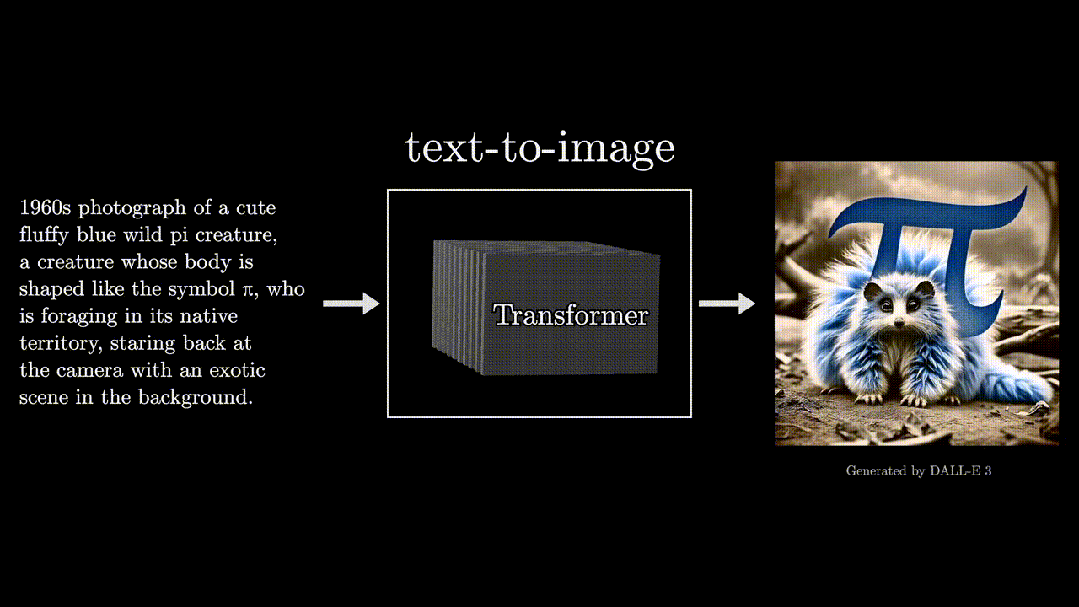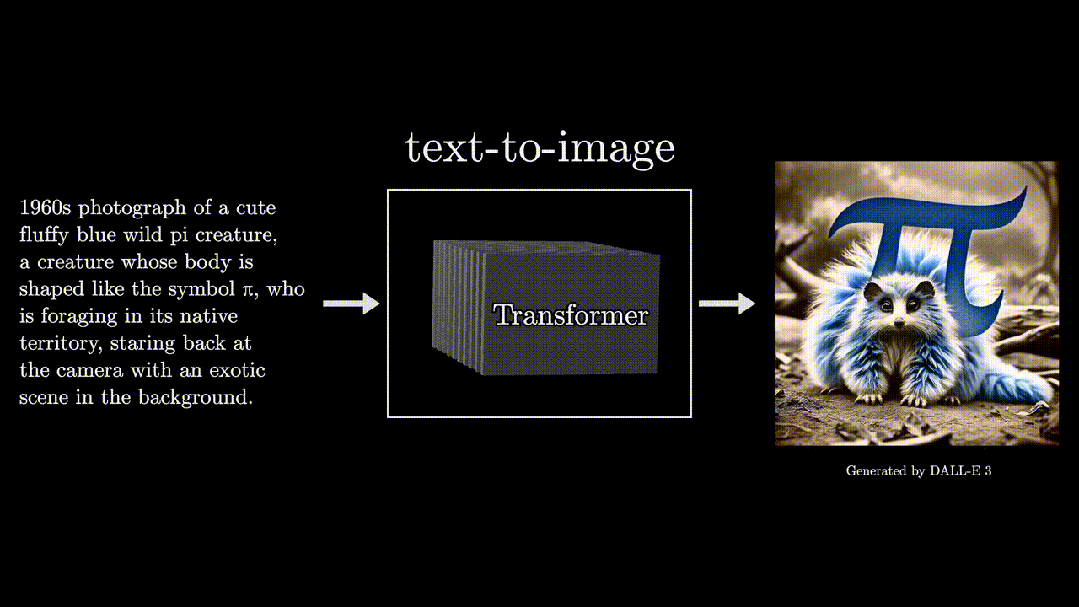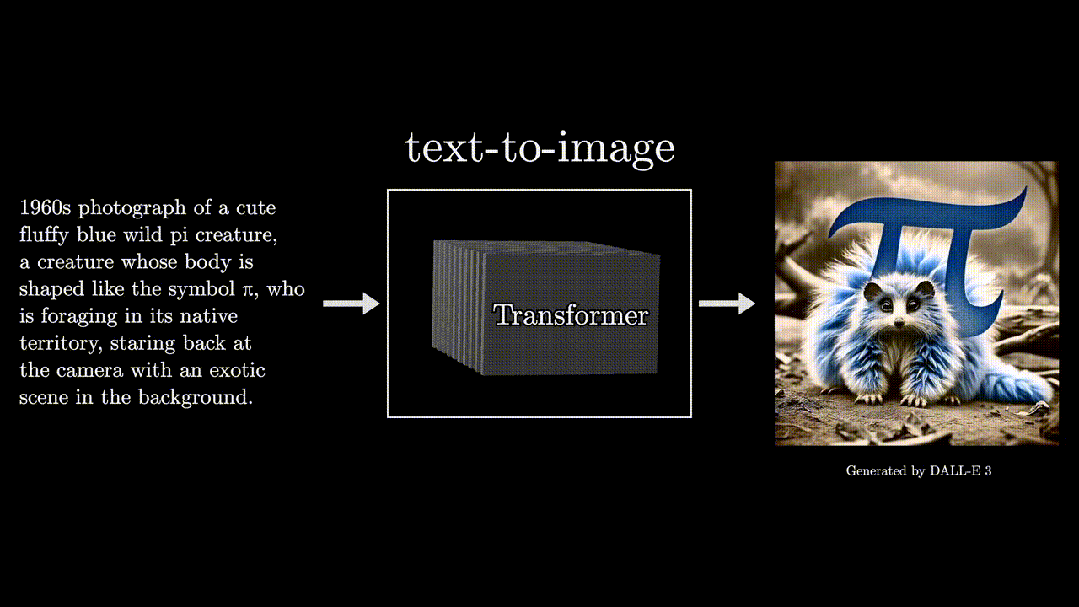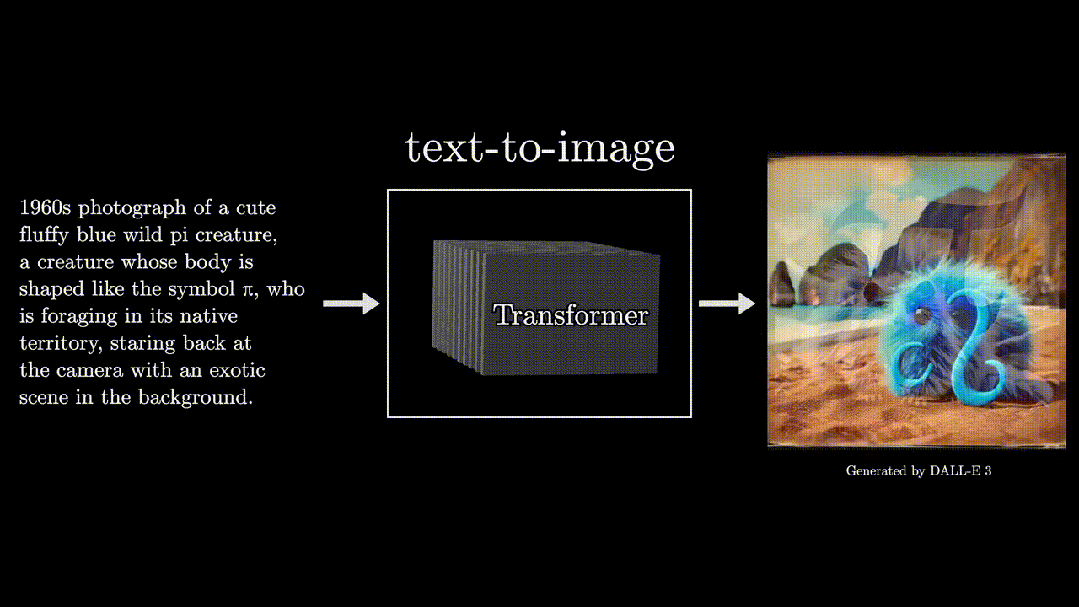
“π Bio”
Even if we cannot fully understand what “π Bio” is, we are still surprised that such things could happen.
This article uses a “text + animated image” visualization method, providing an easy-to-understand way to explain the internal workings of the Transformer and the actual processes that occur internally. We will gradually explore the data flowing through it. For more detailed information, please refer to the original video and text content.
https://www.youtube.com/watch?v=wjZofJX0v4Mhttps://arthurchiao.art/blog/visual-intro-to-transformers-zh/