
1. What is XLNet
-
Learn bidirectional contextual information by maximizing the log-likelihood of all possible factorization orders;
-
Overcome the shortcomings of BERT using the characteristics of autoregression;
-
Additionally, XLNet integrates ideas from the current optimal autoregressive model, Transformer-XL.
2. Autoregressive Language Models
3. Autoencoding Language Models
4. The XLNet Model
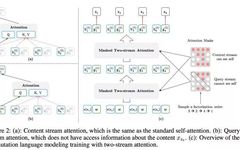
4.1 Permutation Language Modeling
-
The first pre-training phase introduces the [Mask] token to mask out certain words, while during the fine-tuning phase, this forcibly added mask token is not visible, leading to inconsistencies in usage patterns between the two phases, which may cause performance loss;
-
Another issue is that in the first pre-training phase, if multiple words in a sentence are masked, these masked words are assumed to be conditionally independent, whereas sometimes there are relationships between these words.

-
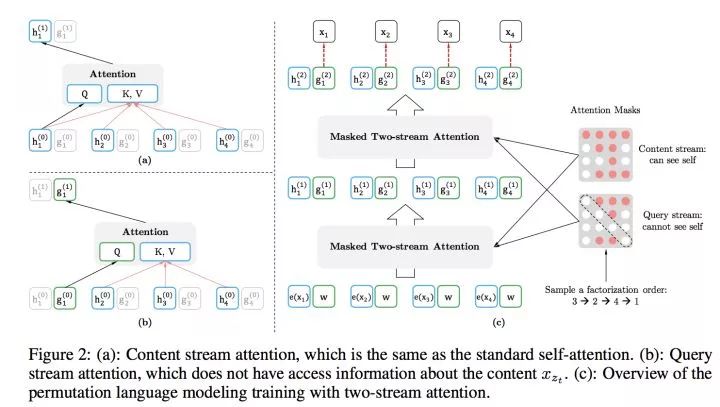
First, it absorbs BERT’s bidirectional language model through the PLM (Permutation Language Model) pre-training objective;
-
Then, the core of GPT2.0 is actually more and higher quality pre-training data, which is clearly absorbed into XLNet;
-
Furthermore, the main idea of Transformer XL is also absorbed, aimed at solving the issue of the Transformer being less friendly for long document NLP applications.
4.2 Transformer XL
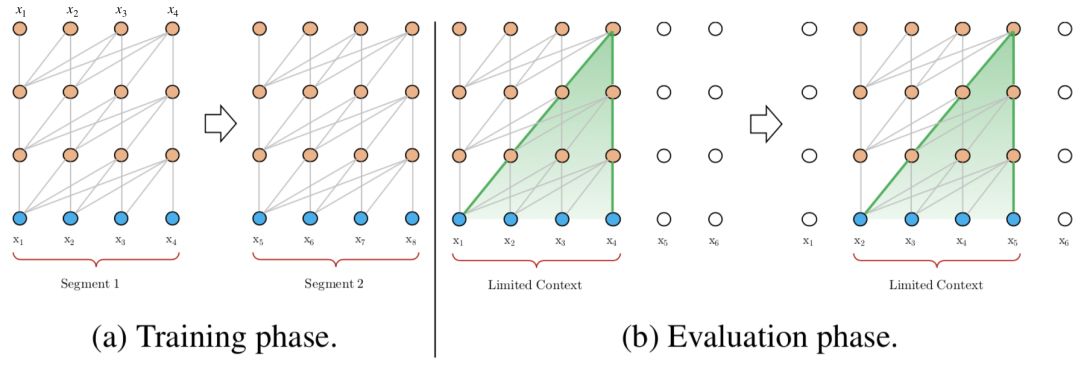
-
Limited Context Length: The maximum dependency distance between characters is limited by the input length, meaning the model cannot see words that appeared several sentences earlier.
-
Fragmented Context: For texts longer than 512 characters, each is trained separately from scratch. The lack of contextual dependencies between segments leads to inefficient training and affects model performance.
-
Slow Inference Speed: During the testing phase, for each prediction of the next word, the context needs to be reconstructed, and calculations begin from scratch, resulting in very slow computation speed.
4.2.2 Transformer XL
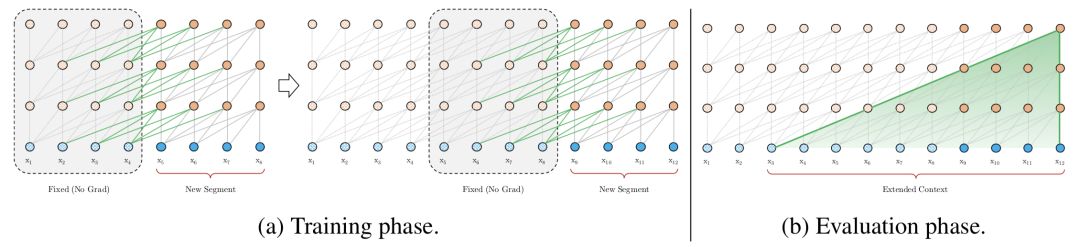
-
The output from the preceding hidden layer of the current segment, similar to the vanilla Transformer (the gray line in the figure above).
-
The output from the preceding segment’s hidden layer (the green line in the figure above), which allows the model to create long-term dependencies.
-
Content-based “addressing”, which is the original score without adding the original position encoding.
-
Content-based positional bias, which is the relative position deviation from the current content.
-
Global content bias, which measures the importance of the key.
-
Global positional bias, which adjusts importance based on the distance between query and key.
5. Comparison of XLNet and BERT
Despite seeming that XLNet’s introduction of the Permutation Language Model as a new pre-training objective is quite different from BERT’s method of using mask tokens, if you think deeply about it, you will find that the essence of both is similar.
The main differences are:
-
BERT directly introduces mask tokens on the input side, hiding a portion of the words to prevent them from contributing during prediction, requiring the use of other words in the context to predict a masked word;
-
In contrast, XLNet discards the mask token on the input side, using an attention mask mechanism to randomly mask out a portion of words within the Transformer (the proportion of masked words is related to the position of the current word in the sentence; the closer to the front, the higher the proportion masked, and vice versa), preventing these masked words from influencing the prediction of a specific word.
Therefore, essentially, there is not much difference between the two; it is just the position of the mask. BERT is more superficial, while XLNet hides this process within the Transformer. This allows XLNet to discard the superficial [Mask] token, addressing the inconsistency issue between pre-training and fine-tuning caused by the presence of the [Mask] token. As for XLNet’s claim regarding the mutual independence of masked words in BERT, it means that when predicting a masked word, other masked words do not have an effect. However, if you think deeply about it, this issue is not significant, because during XLNet’s internal attention masking, a certain proportion of contextual words will also be masked. As long as a portion of the masked words is there, it essentially faces this problem. Moreover, if the training data is large enough, it can rely on other examples to compensate for the direct interdependence issues of masked words, as there will always be other examples that can learn these words’ interdependencies.
Of course, XLNet’s transformation maintains the superficial left-to-right pattern of autoregressive language models, which BERT cannot achieve. This has clear advantages for generative tasks, allowing the model to implicitly contain contextual information while maintaining a superficial left-to-right generation process. Thus, it appears that XLNet should have a significant advantage over BERT for generative NLP tasks. Additionally, because XLNet incorporates the Transformer XL mechanism, it should also have a significant advantage for long document input types in NLP tasks compared to BERT.
6. Code Implementation
XLNet: Operating Mechanism and Comparison with BERT (https://zhuanlan.zhihu.com/p/70257427)
Interpretation of Transformer-XL (Paper + PyTorch Source Code, https://blog.csdn.net/magical_bubble/article/details/89060213)
Cover image source: https://www.maxpixel.net/photo-3704026
Recommended Reading:
Notes on Learning Sentence Representation
Common Normalization Methods: BN, LN, IN, GN
PaddlePaddle Practical NLP Classic Model BiGRU + CRF Detailed Explanation
