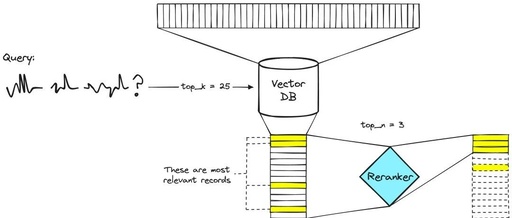
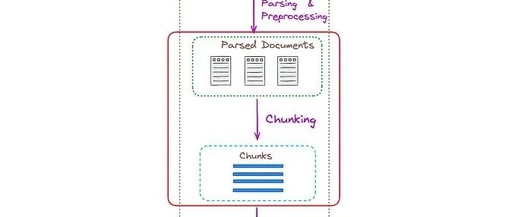
Integrating LlamaIndex and LangChain to Build an Advanced Query Processing System

Source: DeepHub IMBA This article is approximately 1800 words and is suggested to be read in 6 minutes. This article will introduce how to integrate and create a scalable and customizable agent RAG. Building large language model applications can be quite challenging, especially when we have to choose between different frameworks like LangChain and LlamaIndex. … Read more