

Introduction
The pursuit of adaptability and domain-specific understanding in the field of artificial intelligence and language models has been relentless. The emergence of large language models (LLMs) has ushered in a new era in natural language processing, achieving significant advancements across various domains. However, the challenge lies in how to leverage the potential of these models to accomplish specialized tasks and domains. This is where techniques like Retrieval-Augmented Fine-Tuning (RAFT) come into play, providing a pathway to cultivate domain-specific knowledge and reasoning capabilities for LLMs.
Trained on vast amounts of textual data, large language models (LLMs) have revolutionized natural language understanding tasks. From answering questions to generating text, these models exhibit unprecedented capabilities. However, as applications diversify into specialized fields such as law, medicine, or technology, the need to adapt LLMs becomes imperative. This adaptation involves integrating domain-specific knowledge into the model’s framework, enhancing its performance in context-rich environments.

Definitions:
LLM: Large Language Models, such as GPT-3, are deep learning models trained on vast amounts of textual data to understand and generate human-like text.
RAG (Retrieval-Augmented Generation): A technique that allows language models to access external documents or sources to generate responses.
RAFT (Retrieval-Augmented Fine-Tuning): A training approach designed to enhance LLMs’ ability to answer questions in domain-specific contexts by incorporating retrieved documents during fine-tuning.
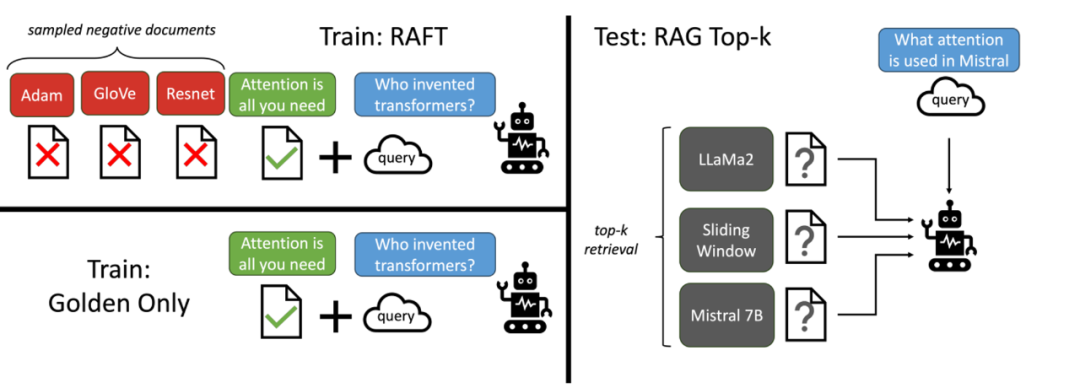
Benefits of Integration:
The integration of RAFT with LlamaIndex offers numerous benefits:
-
Enhanced Adaptability: By fine-tuning LLMs with domain-specific documents using RAFT, we deepen their understanding of specialized topics, thereby enhancing their adaptability in context-rich environments.
-
Improved Reasoning: RAFT helps train LLMs to discern relevant information from retrieved documents, enabling them to generate more accurate and contextually appropriate responses.
-
Robustness Against Inaccurate Retrievals: RAFT trains LLMs to understand the dynamics between questions, retrieved documents, and answers, ensuring robustness against inaccuracies during retrieval.
-
Efficient Knowledge Integration: By simulating real-world scenarios where LLMs must leverage external information sources, RAFT streamlines the integration of domain-specific knowledge into the model framework, achieving more efficient knowledge utilization.
Code Implementation
Implementing RAFT with LlamaIndex involves several key steps to effectively fine-tune large language models (LLMs) for domain-specific tasks.
Step 1: Install Libraries and Download Data
!pip install llama-index
!pip install llama-index-packs-raft-dataset
# Download Data
!wget --user-agent "Mozilla" "<https: data="" docs="" examples="" llama_index="" main="" paul_graham="" paul_graham_essay.txt="" raw.githubusercontent.com="" run-llama="">" -O './paul_graham_essay.txt'</https:>Step 2: Download RAFT Package
import os
from llama_index.packs.raft_dataset import RAFTDatasetPack
os.environ["OPENAI_API_KEY"] = "<your api="" key="" openai="">"
raft_dataset = RAFTDatasetPack("./paul_graham_essay.txt")
dataset = raft_dataset.run()</your>-
RAFT-repo: https://github.com/ShishirPatil/gorilla/tree/main/raft -
Llamapack-RAFT: https://github.com/run-llama/llama_index/blob/main/llama-index-packs/llama-index-packs-raft-dataset/examples/raft_dataset.ipynb