▼Recently, there have been a lot of live broadcasts,make an appointment to ensure you gain something.

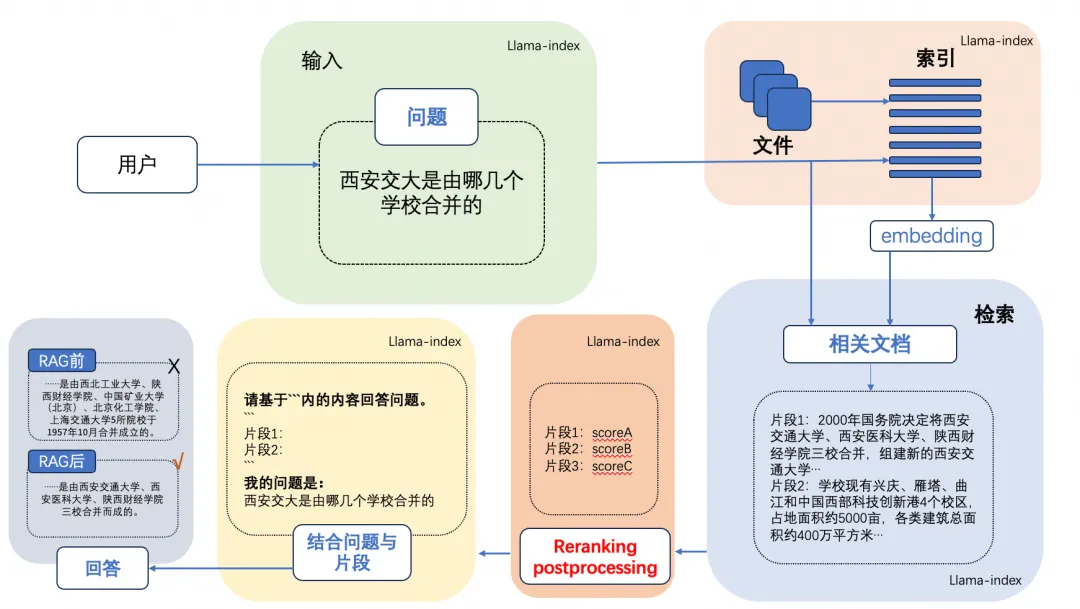
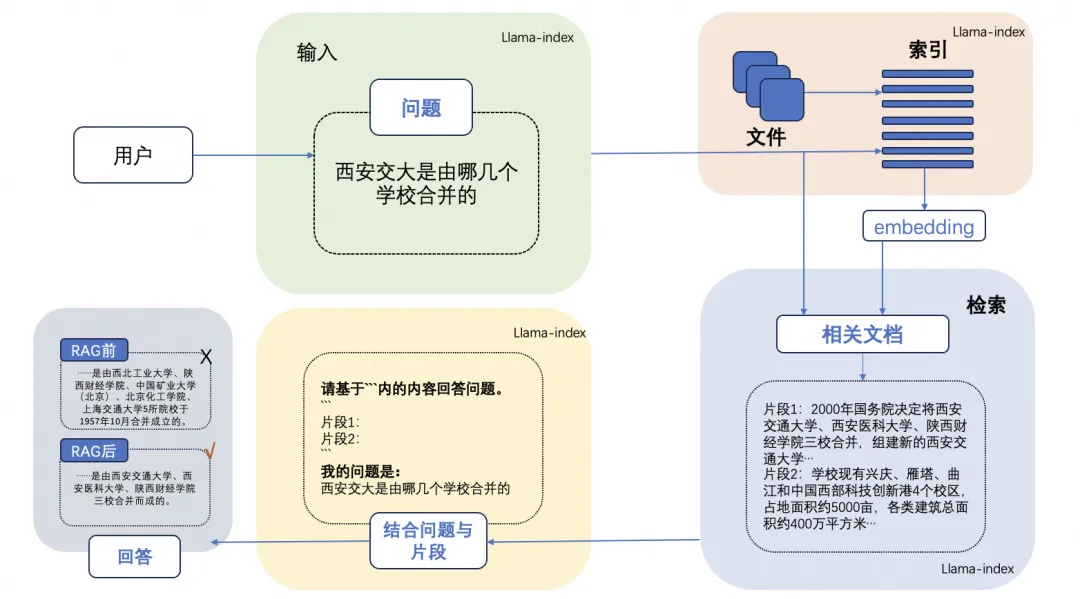
The RAG (Retrieval-Augmented Generation) technology is detailed in the article “Understanding RAG: A Comprehensive Guide to Retrieval-Augmented Generation,” with a typical RAG case shown in the image below, which includes three steps:
-
Indexing: Split the document library into shorter chunks and construct a vector index using an embedding encoder.
-
Retrieval: Retrieve relevant document segments based on the similarity between the prompt question and the chunks.
-
Generation: Generate answers to the prompt question using the retrieved context as enhancement.
Today, let’s discuss how to further enhance the effectiveness of RAG applications by introducing Rerank Technology.
—1—
Enhancing RAG Implementation with Rerank
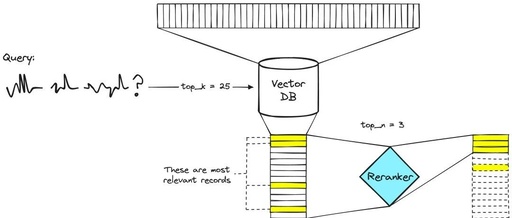
Rerank is a reordering technology that, by introducing Rerank, can accelerate the query of large models without sacrificing accuracy (and may actually improve accuracy). Rerank achieves this by removing irrelevant nodes from the context and reordering relevant nodes, as shown in the image below:
Next, we will analyze Rerank + RAG technology in detail, which effectively alleviates hallucination issues, speeds up knowledge updates, and enhances the traceability of content generation, making large language models more practical and trustworthy in real applications.
First, Rerank Model Technology and Selection
Unlike embedding models, Rerank uses questions and documents as input and directly outputs similarity scores instead of embedding vectors. Relevance scores are obtained by inputting queries and paragraphs into the Rerank module. Rerank is often optimized based on cross-entropy loss, so relevance scores are not limited to a specific range. bge-reranker-v2-m3 is suitable for bilingual Rerank scenarios in Chinese and English.
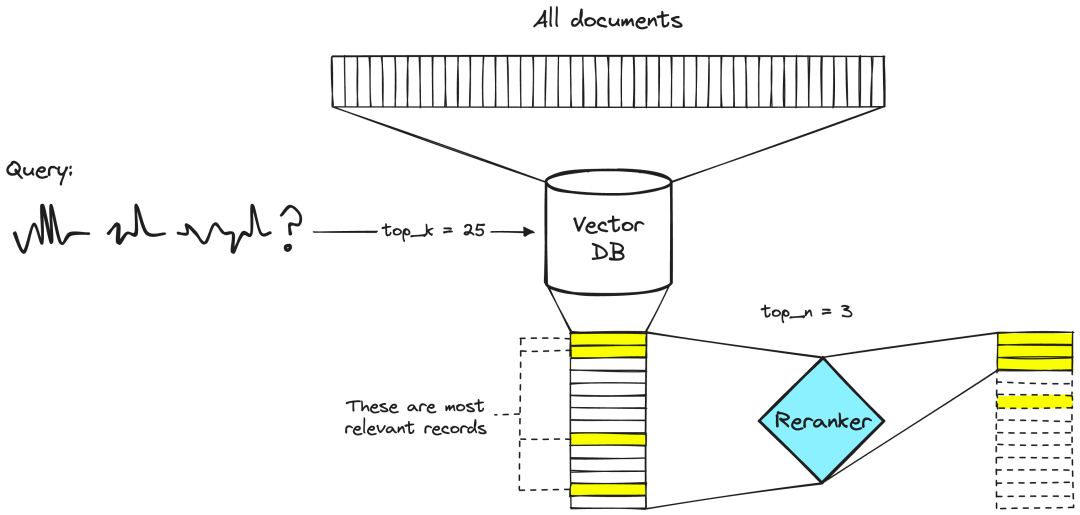
Rerank’s function (as shown in the image below) acts like a smart filter. When RAG retrieves multiple documents from a collection, these documents may have varying degrees of relevance to your question. Some documents may be very pertinent, while others may be only slightly related or even irrelevant. At this point, the task of Rerank is to evaluate the relevance of these documents and then reorder them. It will prioritize those documents that are most likely to provide accurate and relevant answers. Thus, when the large model begins generating answers, it will prioritize these top-ranked, more relevant documents, thereby improving the accuracy and quality of the generated answers. In simple terms, Rerank is like helping you pick out the most relevant books from a library when searching for answers, making the process more efficient and precise.
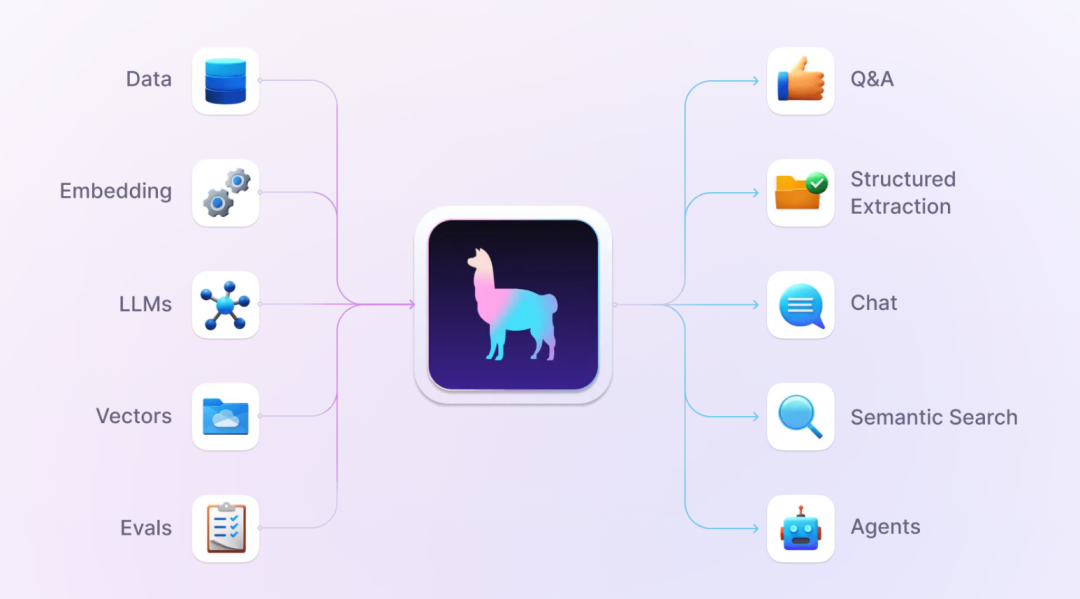
Second, RAG Framework: LlamaIndex
LlamaIndex is a data framework based on large language model applications, designed to enhance the capabilities of large language models. This large language model-based application is referred to as RAG application, which is comparable to fine-tuning technology. LlamaIndex provides the necessary abstractions to more easily acquire, index, store, and access enterprise-level data that is private or domain-specific, allowing this data to be securely and reliably injected into large language models for more accurate knowledge generation.
Third, LLM Large Language Model Selection
When enhancing knowledge, the capabilities required from large language models vary depending on the task. For example: use 3B parameters for classification tasks, 7B parameters for translation tasks, 13B parameters for intent recognition, and 70B parameters for Action function calling.
Based on the above practical principles, for closed-source large models, consider: OpenAI ChatGPT series and Baidu Wenxin Yiyan series. For open-source large models, consider: Alibaba Qwen 1.5, Zhipu ChatGLM3, Baichuan3, Llama 2, and xAI’s latest release with 314B parameters Grok 1.5 and Databricks’ open-source 132B parameters DBRX.

Fourth, RAG + Rerank Environment Configuration and Installation
-
-
Pytorch 1.12 and above, recommended 2.0 and above
-
It is recommended to use CUDA 11.4 and above
-
To help students thoroughly grasp the application development, deployment, and productionization of large models, I will hold a live broadcast tonight at 20:00 to deeply analyze with students. Please click the followingappointment button for free booking.
—2—
!Giveaway! Live Course on AI Large Model Development
The technical system of large models is very complex. Even with a knowledge graph and learning route, it is not easy to master quickly. We have created a series of live courses on large model application technology, including: General Large Model Technical Architecture Principles, Large Model Agent Application Development, Private Large Model Development, Vector Databases, Large Model Application Governance, Large Model Application Industry Case Studies and other six core skills to help students quickly master AI large model skills.
Scan the code now, to book for free now!
Enter the live broadcast, where experts will be online to answer questions!
Limited spots available this time
Height starts from speed(Be quick!!)
—3—
!!Another Giveaway!! “AI Large Model Technology Knowledge Graph“
Recently, many students have left messages in the background: “Xuan Jie, is there a knowledge graph for AI large model technology?”, “Does AI large model technology have a learning route?”
We have carefully compiled a knowledge graph for AI large model technology, come and get it!
This industry-first knowledge graph and learning route is today free for everyone!
Just follow these three steps to get it for free:
Step 1: Press and hold to scan the following video number: Xuan Jie Talks AGI

Step 2: After scanning, click the follow button to follow me.
Step 3: Click the “Customer Service” button and reply “Knowledge Graph” to receive it.