
Source: DeepHub IMBA
This article is about 3200 words long, and it is recommended to read for 6 minutes.
This article explores the new integration of LlamaIndex for fine-tuning OpenAI's GPT-3.5 Turbo.
OpenAI announced on August 22, 2023, that fine-tuning of GPT-3.5 Turbo is now possible. This means we can customize our own models. Subsequently, LlamaIndex released version 0.8.7, which includes the ability to fine-tune OpenAI’s GPT-3.5 Turbo.
In other words, we can now use GPT-4 to generate training data, and then fine-tune with a cheaper API (GPT-3.5 Turbo) to achieve a more accurate model at a lower cost. In this article, we will use NVIDIA’s 2022 SEC 10-K file to closely examine this new feature in LlamaIndex and compare the performance of GPT-3.5 Turbo with other models.
RAG vs Fine-tuning
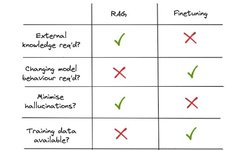
What exactly is fine-tuning? How is it different from RAG? When should RAG and fine-tuning be used? The following two summary images:
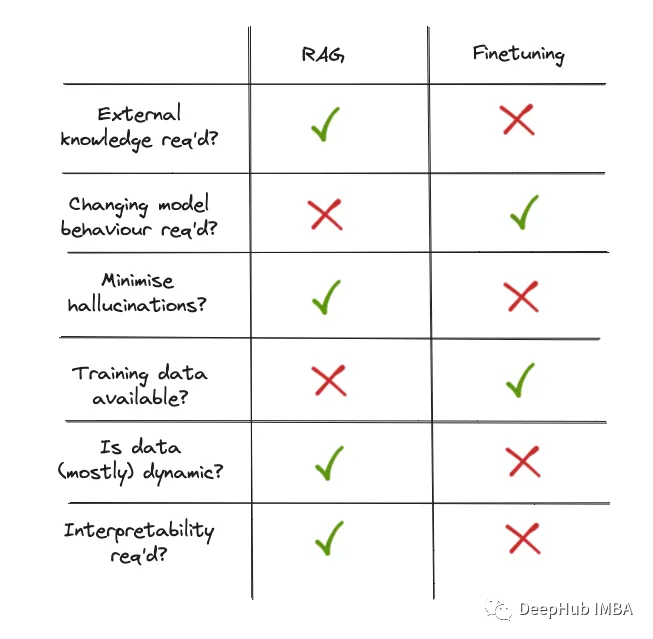
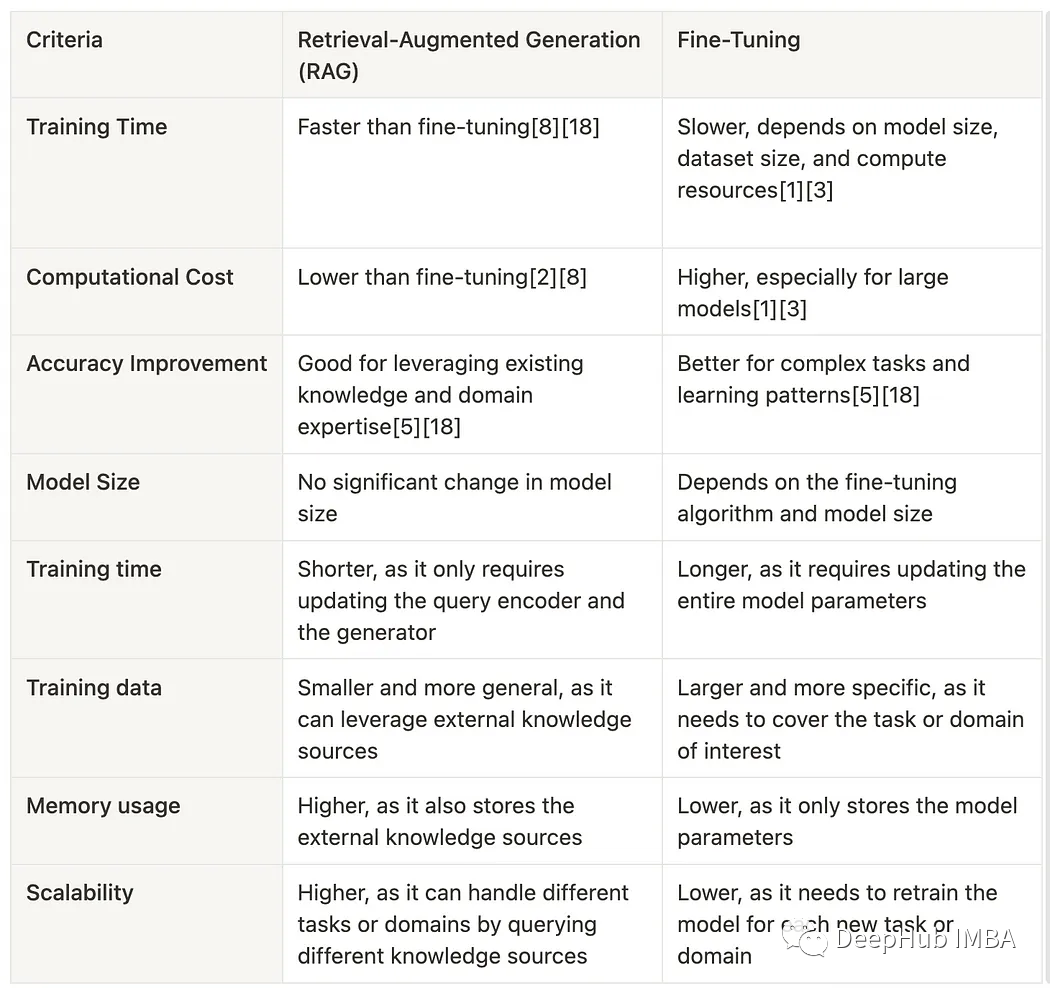
These two images summarize their basic differences and provide good guidance for choosing the right tool.
However, RAG and fine-tuning are not mutually exclusive. Applying both in a hybrid manner to the same application is entirely feasible.
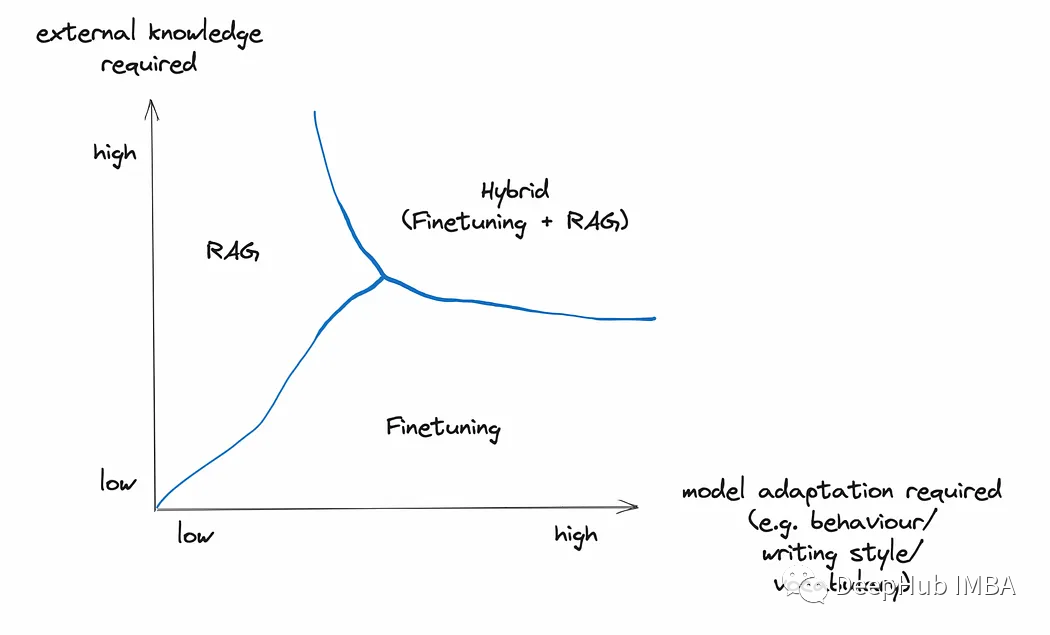
RAG/Fine-tuning Hybrid Approach
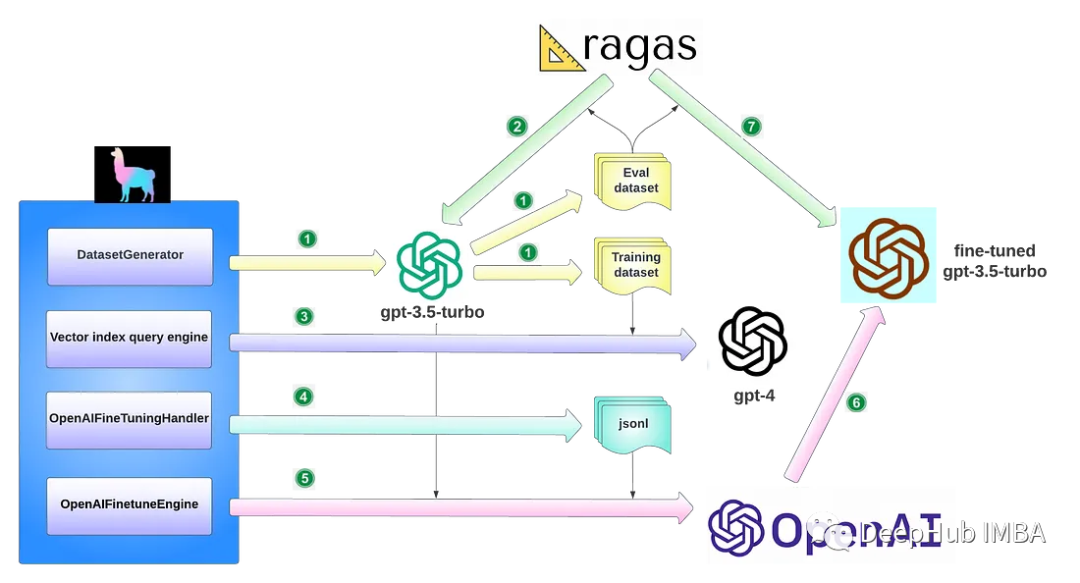
LlamaIndex provides a detailed guide for fine-tuning OpenAI’s GPT-3.5 Turbo in the RAG pipeline. At a high level, fine-tuning can achieve the key tasks described in the following diagram:
-
Use DatasetGenerator to automate the generation of evaluation and training datasets.
-
Before fine-tuning, evaluate the base model GPT-3.5 Turbo using the Eval dataset generated in step 1.
-
Build a vector index query engine and call GPT-4 to generate new training data based on the training dataset.
-
The callback handler OpenAIFineTuningHandler collects all messages sent to GPT-4 and their responses, saving these messages in .jsonl (jsonline) format, which the OpenAI API endpoint can use for fine-tuning.
-
OpenAIFinetuneEngine is constructed by passing in GPT-3.5 Turbo and the json file generated in step 4, which sends a fine-tuning call to OpenAI, initiating a fine-tuning job request.
-
OpenAI creates a fine-tuned GPT-3.5 Turbo model based on your request.
-
Fine-tune the model using the Eval dataset generated from step 1.
In summary, this integration allows GPT-3.5 Turbo to be fine-tuned on data trained by GPT-4, resulting in better responses.
Steps 2 and 7 are optional, as they merely evaluate the performance of the base model against the fine-tuned model.
We will demonstrate this process using NVIDIA’s 2022 SEC 10-K file.
Main Features
1. OpenAIFineTuningHandler
This is the callback handler for OpenAI fine-tuning, used to collect all training data sent to GPT-4 and their responses. These messages are saved in .jsonl (jsonline) format, which the OpenAI API endpoint can use for fine-tuning.
2. OpenAIFinetuneEngine
The core of the fine-tuning integration is OpenAIFinetuneEngine, which is responsible for initiating fine-tuning jobs and obtaining a fine-tuned model that can be directly plugged into the rest of the LlamaIndex workflow.
Using OpenAIFinetuneEngine, LlamaIndex abstracts all implementation details of using the OpenAI API for fine-tuning, including:
-
Preparing fine-tuning data and converting it to json format.
-
Using OpenAI’s file upload for fine-tuning data. Creating endpoints and obtaining file IDs from the response.
-
Creating a new fine-tuning job by calling OpenAI’s FineTuningJob. Creating endpoints.
-
Waiting for the creation of the new fine-tuned model, and then using the new fine-tuned model.
We can use OpenAIFinetuneEngine’s GPT-4 and OpenAIFineTuningHandler to collect the data we want to train on, meaning we use GPT-4’s output to train our custom GPT-3.5 Turbo model.
from llama_index import ServiceContext from llama_index.llms import OpenAI from llama_index.callbacks import OpenAIFineTuningHandler from llama_index.callbacks import CallbackManager
# use GPT-4 and the OpenAIFineTuningHandler to collect data that we want to train on. finetuning_handler = OpenAIFineTuningHandler() callback_manager = CallbackManager([finetuning_handler])
gpt_4_context = ServiceContext.from_defaults( llm=OpenAI(model="gpt-4", temperature=0.3), context_window=2048, # limit the context window artificially to test refine process callback_manager=callback_manager, )
# load the training questions, auto generated by DatasetGenerator questions = [] with open("train_questions.txt", "r") as f: for line in f: questions.append(line.strip())
from llama_index import VectorStoreIndex
# create index, query engine, and run query for all questions index = VectorStoreIndex.from_documents(documents, service_context=gpt_4_context) query_engine = index.as_query_engine(similarity_top_k=2)
for question in questions: response = query_engine.query(question)
# save fine-tuning events to jsonl file finetuning_handler.save_finetuning_events("finetuning_events.jsonl")
from llama_index.finetuning import OpenAIFinetuneEngine
# construct OpenAIFinetuneEngine finetune_engine = OpenAIFinetuneEngine( "gpt-3.5-turbo", "finetuning_events.jsonl" )
# call finetune, which calls OpenAI API to fine-tune gpt-3.5-turbo based on training data in jsonl file. finetune_engine.finetune()
# check current job status finetune_engine.get_current_job()
# get fine-tuned model ft_llm = finetune_engine.get_finetuned_model(temperature=0.3)It is important to note that the fine-tuning function takes time. For the 169-page PDF document I tested, it took about 10 minutes from starting the fine-tune on the finetune_engine to receiving an email notification from OpenAI that the new fine-tuning job was completed. The email is as follows.
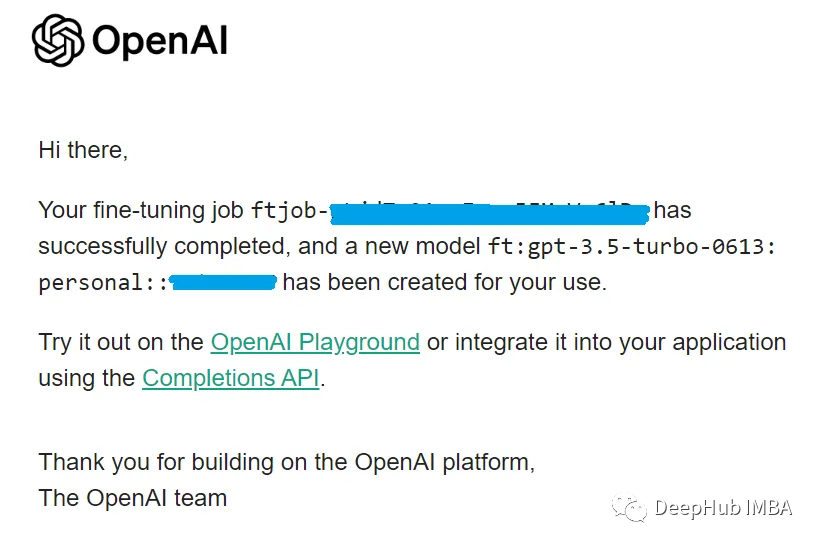
Before receiving this email, if you run get_finetuned_model on finetune_engine, you will get an error indicating that the fine-tuning job is not yet ready.
3. ragas Framework
ragas stands for RAG Assessment, which provides tools based on the latest research, allowing us to gain insights into the RAG pipeline.
ragas measures the performance of the pipeline according to different dimensions: fidelity, answer relevance, context relevance, context recall, etc. For this demonstration application, we will focus on measuring fidelity and answer relevance.
Fidelity: Measures the consistency of information in the generated answer given the context. Any claims in the answer that cannot be inferred from the context will be penalized.
Answer relevance: Refers to the extent to which the answer directly addresses the given question or context. This does not consider the truthfulness of the answer but penalizes providing redundant information or incomplete answers to the question.
The detailed steps for applying ragas in the RAG pipeline are as follows:
-
Collect a set of eval questions (at least 20, in our case 40) to form our test dataset.
-
Run the pipeline using the test dataset before and after fine-tuning. Record prompts each time using context and generated outputs.
-
Run ragas evaluation on each of them to generate evaluation scores.
-
Comparing the scores will show how much the fine-tuning affects performance.
The code is as follows:
contexts = [] answers = []
# loop through the questions, run query for each question for question in questions: response = query_engine.query(question) contexts.append([x.node.get_content() for x in response.source_nodes]) answers.append(str(response))
from datasets import Dataset from ragas import evaluate from ragas.metrics import answer_relevancy, faithfulness
ds = Dataset.from_dict( { "question": questions, "answer": answers, "contexts": contexts, } )
# call ragas evaluate by passing in dataset, and eval categories result = evaluate(ds, [answer_relevancy, faithfulness]) print(result)
import pandas as pd
# print result in pandas dataframe so we can examine the question, answer, context, and ragas metrics pd.set_option('display.max_colwidth', 200) result.to_pandas()Evaluation Results
Finally, we can compare the eval results before and after fine-tuning.
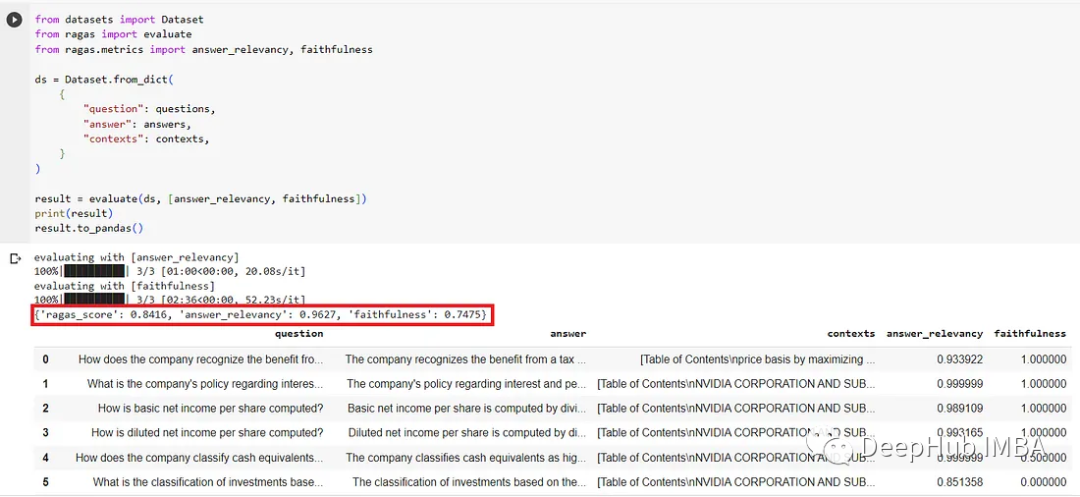
For the basic GPT-3.5 Turbo evaluation, please see the screenshot below. The answer relevance score is good, but fidelity is a bit low.
After fine-tuning, the model’s performance improved slightly in answer relevance, increasing from 0.7475 to 0.7846, an improvement of 4.96%.
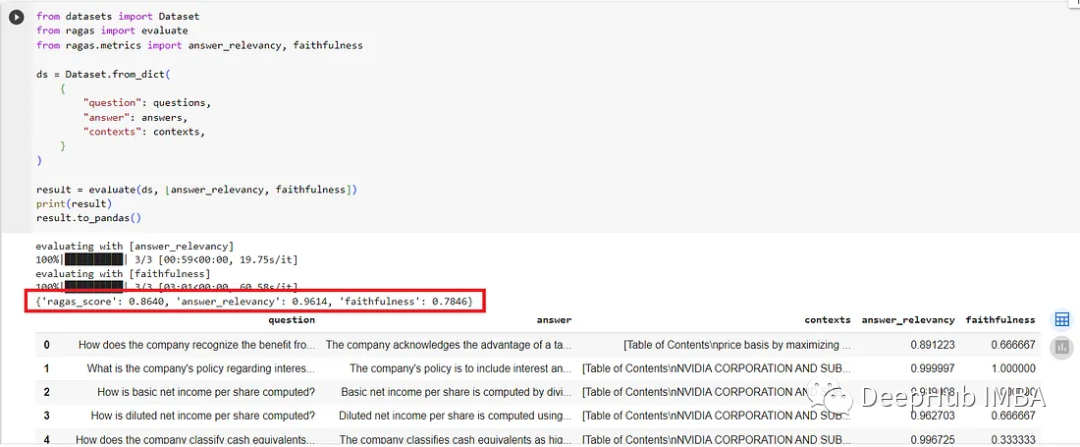
Fine-tuning GPT-3.5 Turbo with training data generated by GPT-4 indeed showed improvement.
Some Interesting Findings
1. Fine-tuning with small documents can lead to performance degradation
Initially, I experimented with a small 10-page PDF file and found that the eval results showed a performance decline compared to the base model. I then continued testing for two rounds, with the results as follows:
First round base model: Ragas_score: 0.9122, answer_relevance: 0.9601, faithfulness: 0.8688
First round fine-tuned model: Ragas_score: 0.8611, answer_relevance: 0.9380, faithfulness: 0.7958
Second round base model: Ragas_score: 0.9170, answer_relevance: 0.9614, faithfulness: 0.8765
Second round fine-tuned model: Ragas_score: 0.8891, answer_relevance: 0.9557, faithfulness: 0.8313
Thus, using small documents may be the reason the fine-tuned model performs worse than the base model. Therefore, I used NVIDIA’s 169-page SEC 10-K file. This provided a good experiment for the above results—after fine-tuning, the model performed better, with fidelity increasing by 4.96%.
2. Inconsistent results of fine-tuned models
The reason may be the size of the data and the quality of the evaluation questions.
Although the fine-tuned model from the 169-page document achieved the expected evaluation results, I ran a second round of tests with the same evaluation questions and the same document, yielding the following results:
Second round base model: Ragas_score: 0.8874, answer_relevance: 0.9623, faithfulness: 0.8233
Second round fine-tuned model: Ragas_score: 0.8218, answer_relevance: 0.9498, faithfulness: 0.7242
What caused the inconsistency in eval results?
The size of the data is likely one of the fundamental reasons for the inconsistent fine-tuning computation results. “At least 1000 samples of fine-tuning datasets are needed.” This demonstration application clearly does not have that many fine-tuning datasets.
Another fundamental reason may lie in the quality of the data, specifically the quality of the evaluation questions. I printed the eval results into a dataframe, listing each question’s question, answer, context, answer relevance, and fidelity.
Upon visual inspection, four questions scored 0 in fidelity. These answers did not have context provided in the document.
These four questions had poor quality, so I removed them from eval_questions.txt, reran the evaluation, and obtained better results:
Base model eval: Ragas_score: 0.8947, answer_relevance: 0.9627, fidelity: 0.8356.
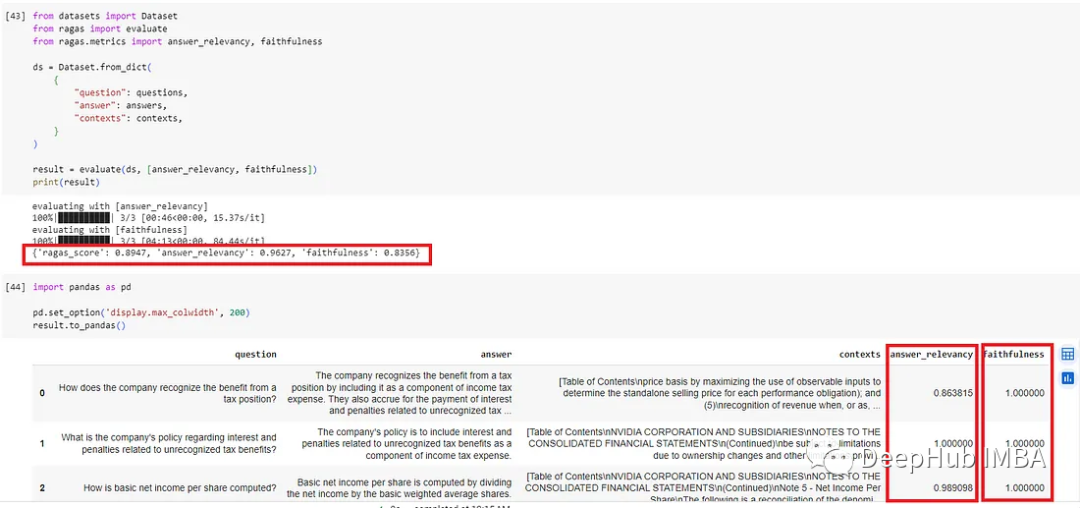
Fine-tuned model eval: Ragas_score: 0.9207, answer_relevance: 0.9596, fidelity: 0.8847.
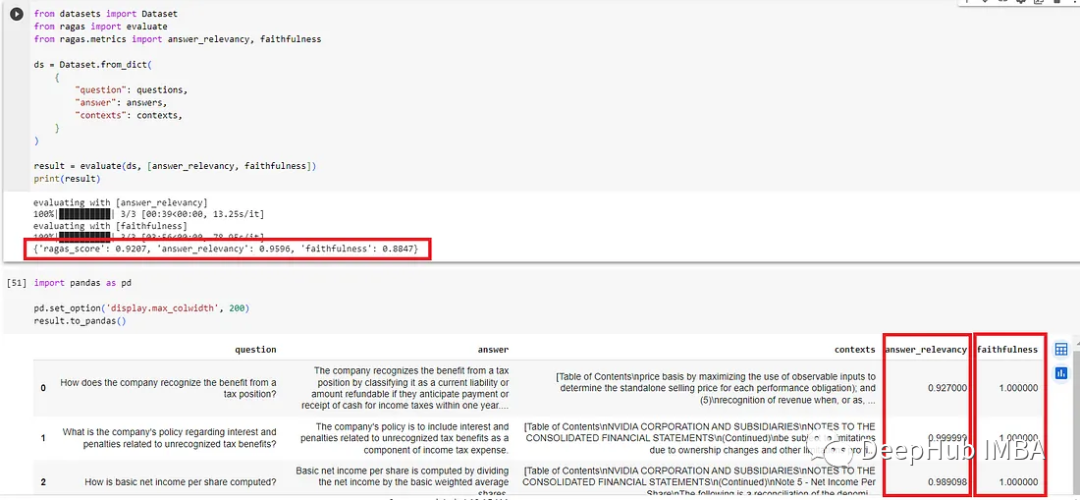
As we can see, after addressing these four quality issues, the fine-tuned version improved by 5.9%. Therefore, the evaluation questions and training data need more adjustments to ensure good data quality. This is indeed a very interesting area of exploration.
3. The cost of fine-tuning
The cost of the fine-tuned GPT-3.5 Turbo is higher than that of the base model. Let’s take a look at the cost differences between the basic model, fine-tuned model, and GPT-4:
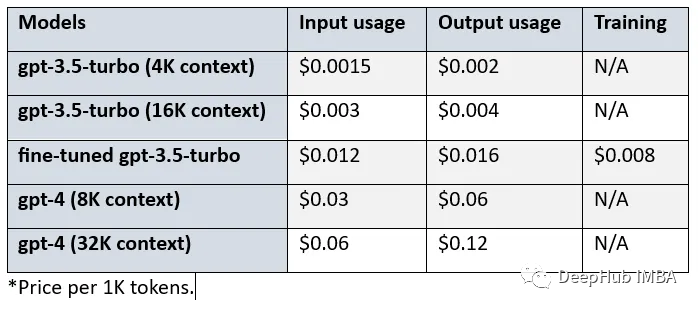
Comparing GPT-3.5 Turbo (4K environment), fine-tuned GPT-3.5 Turbo, and GPT-4 (8K environment), we can see:
-
The fine-tuned GPT-3.5 Turbo costs 8 times more for input and output usage than the base model.
-
For input usage, the cost of GPT-4 is 2.5 times that of the fine-tuned model, and for output usage, it is 3.75 times.
-
For input usage, the cost of GPT-4 is 20 times that of the base model, and for output usage, it is 30 times.
-
Additionally, using the fine-tuned model incurs an extra cost of $0.008/1K tokens.
Conclusion
This article explored the new integration of LlamaIndex for fine-tuning OpenAI’s GPT-3.5 Turbo. We tested the performance of the base model through the RAG pipeline analysis of NVIDIA’s SEC 10-K archive, then collected training data using GPT-4, created the OpenAIFinetuneEngine, established a new fine-tuned model, tested its performance, and compared it with the base model.
It can be seen that due to the significant cost difference between GPT-4 and GPT-3.5 Turbo (20 times), we can achieve similar results after fine-tuning while saving considerable costs (2.5 times).
