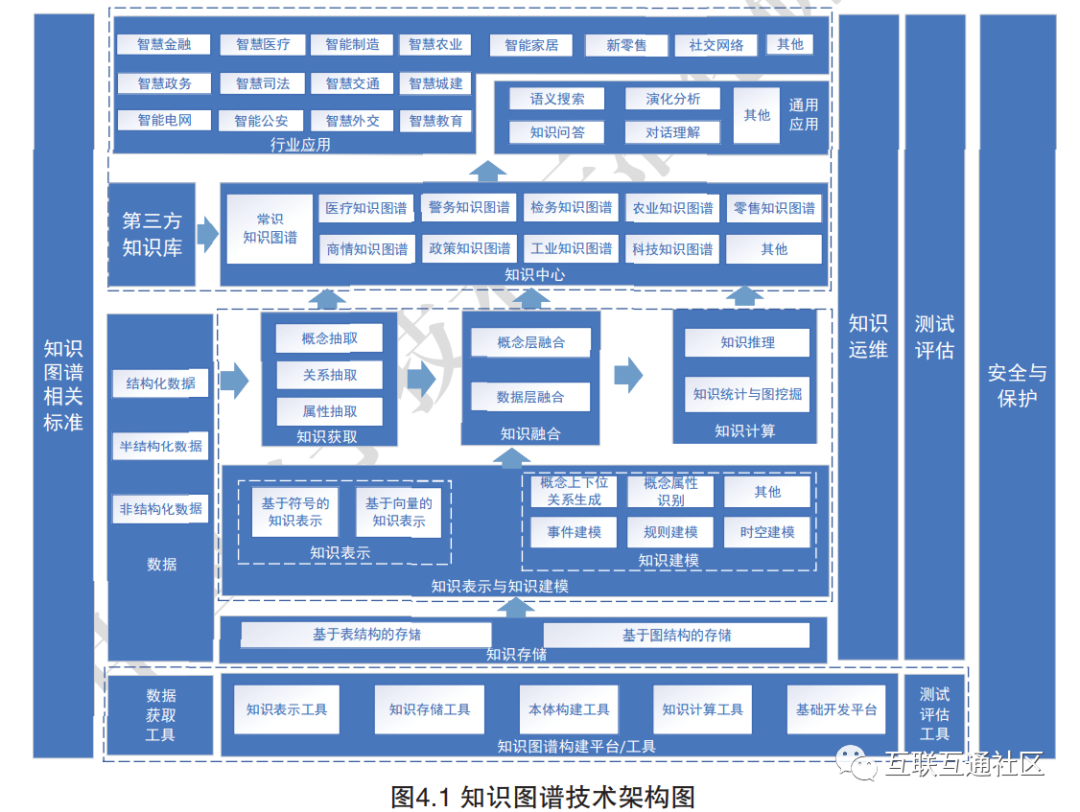
The main technologies of knowledge graphs include knowledge acquisition, knowledge representation, knowledge storage, knowledge modeling, knowledge fusion, knowledge understanding, and knowledge maintenance. These seven aspects support the construction of knowledge graphs from structured, semi-structured, and unstructured data for applications in various fields, as shown in the technical architecture in Figure 4.1.
1. Knowledge Acquisition
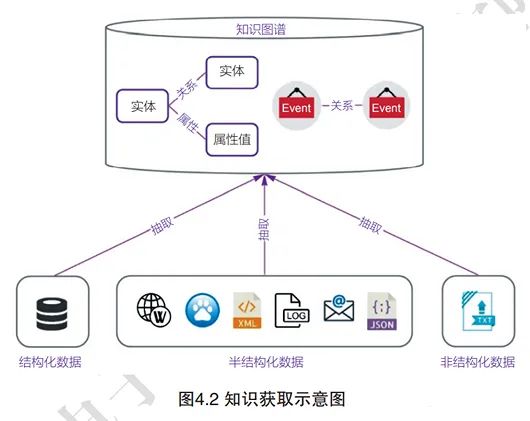
The knowledge in a knowledge graph comes from structured, semi-structured, and unstructured information resources, as shown in Figure 4.2. Knowledge extraction techniques are used to extract structured data that is understandable and computable by computers from these different structures and types of data for further analysis and utilization. Knowledge acquisition is the process of extracting knowledge from various sources and structures, forming structured knowledge to be stored in the knowledge graph. Currently, knowledge acquisition mainly targets text data, and the extraction issues that need to be addressed include entity extraction, relationship extraction, attribute extraction, and event extraction.
As the first step in building a knowledge graph, knowledge acquisition typically has the following four methods:Crowdsourcing, Web Crawling, Machine Learning, Expert Method.
Crowdsourcing:Allows anyone to create, modify, and query a knowledge base, known as the crowdsourcing model. Examples include Baidu Encyclopedia and Wikipedia. In such scenarios, the knowledge base stores not a large amount of disorganized text, but machine-readable data formats with a certain structure (for example, a specific entry in Baidu). Modern knowledge graphs established through crowdsourcing, like those of Google and Baidu, already contain hundreds of billions of triples, and Alibaba’s knowledge graph, released in August 2017, which only includes core product data, has also reached tens of billions.
Web Crawling:Web developers mark entities, entity attributes, and relationships appearing on web pages according to certain rules, allowing search engines like Google and Baidu to obtain this data through web crawling, thus accumulating knowledge graph data. There are many web crawling frameworks in different languages, such as Scrapy for Python and WebMagic for Java, which can complete the definition of crawling rules, crawling, cleaning, deduplication, and storage through simple configuration.
Machine Learning:Transforms data into understandable knowledge through machine learning. For example, by using machine learning models such as text classification and topic modeling, text features can be obtained, and these features can be understood as knowledge.
Expert Method:The expert method is usually used in engineering practices in vertical fields, where knowledge is formed from the experience of experts through induction and summarization. For example, event graphs in knowledge graphs are typically formed from expert experience.
2. Knowledge Representation
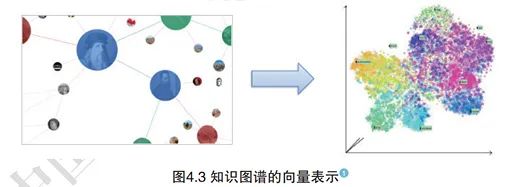
Knowledge is a collection of objective facts, concepts, theorems, and axioms summarized by humans in the process of understanding and transforming the objective world. Knowledge can be classified in different ways; for example, according to the scope of knowledge, it can be divided into common knowledge and domain-specific knowledge. Knowledge representation is the process of converting knowledge that exists in the real world into content that can be recognized and processed by computers. It is a data structure that describes knowledge and is used to describe or stipulate knowledge. Knowledge representation plays a key role in the construction of artificial intelligence. By representing knowledge in an appropriate way, a comprehensive knowledge expression can be formed, allowing machines to exhibit human-like behavior by learning this knowledge. Knowledge representation is an important research topic in knowledge engineering and is the foundation for knowledge acquisition, fusion, modeling, computation, and application in knowledge graph research, as shown in Figure 4.3.
 Knowledge representation methods are mainly divided into symbol-based knowledge representation methods and representation learning-based knowledge representation methods.
1. Symbol-Based Knowledge Representation MethodsThese methods are divided into early knowledge representation methods and semantic web knowledge representation methods. Early knowledge representation methods include first-order predicate logic representation, production rule representation, frame representation, and semantic network representation.
(1) First-Order Predicate Logic Representation
This knowledge representation method based on predicate logic describes objects, properties, states, and relationships using predicate formulas composed of propositions, logical connectives, individuals, predicates, and quantifiers. First-order predicate logic representation is based on mathematical logic, providing accurate results and natural expressions that are close to human natural language. However, it also has the drawback of poor representational capacity, being able to express only deterministic knowledge, and having limited expression for procedural and non-deterministic knowledge.
(2) Production Rule Representation
In the 1940s, logician Post proposed the production rule representation. Based on the logical causal relationships among knowledge, it formed the “IF-THEN” knowledge representation form, which was one of the common knowledge representation methods used in early expert systems. This representation method is similar to human causal judgment, being intuitive, natural, and easy to reason. Moreover, the range of knowledge expression in production rule representation is broad, including deterministic knowledge, uncertainty knowledge with confidence levels, heuristic knowledge, and procedural knowledge. However, due to its unified representation format, production rule representation has low reasoning efficiency when the knowledge scale is large, easily leading to the combinatorial explosion problem.
In the early 1970s, American AI expert M. Minsky proposed a “frame theory” for knowledge representation. This theory stems from the idea that people’s understanding of various objects in the objective world is stored in memory in a framework-like structure, leading to frame representation. A frame is a general data structure used to store accumulated information and experience. In frame structures, concepts from past experiences can be used to analyze and explain new information. When expressing knowledge, a frame can represent categories, individuals, attributes, and relationships of objects. A frame structure generally consists of four parts: “frame name-slot name-side value,” where a frame is composed of several slots, with each slot describing a certain aspect of the object’s attributes; a slot consists of several sides, used to describe an aspect of the corresponding attribute, each side having several values. Frames have advantages such as inheritance, structuring, and naturalness, but complex frame construction has high costs and requires high quality for the knowledge base, while their expression is not flexible enough, making it difficult to use in conjunction with other datasets.
(4) Semantic Network Representation
In 1960, cognitive scientist Allan M. Collins proposed the knowledge representation method of semantic networks. A semantic network is a directed graph that expresses knowledge through entities and the semantic relationships between them. In the graph, nodes represent objects, attributes, concepts, states, events, situations, actions, etc., while the arcs between nodes represent the semantic relationships between the two connected nodes. Depending on the knowledge situation being represented, the arc’s labels need to be defined, which are generally predicates in predicate logic, with common labels including instance relationships, classification relationships, membership relationships, attribute relationships, inclusion relationships, temporal relationships, spatial relationships, etc. A semantic network consists of semantic primitives, which can be described using triples (node1, arc, node2), and is composed of several semantic primitives and their semantic relationships. Semantic network representation has a wide range of representation and strong representational capabilities, with a simple and direct representation form that is easy to understand and conforms to natural language. However, semantic networks have issues such as the lack of standards for node and edge values, which are entirely defined by users, making knowledge sharing difficult, and the inability to distinguish between knowledge descriptions and knowledge instances.
2. Representation Learning-Based Knowledge Representation Methods
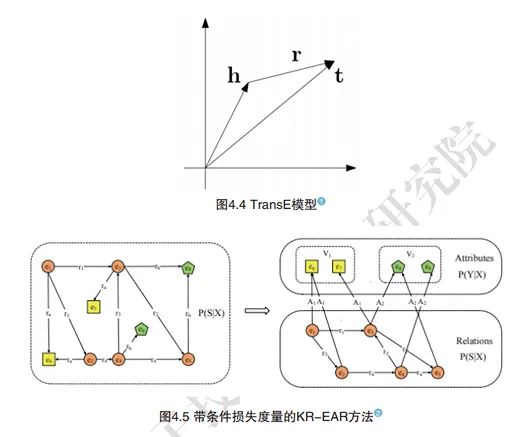
Early knowledge representation methods and semantic web knowledge representation methods explicitly represent concepts and their relationships through symbols. In fact, many knowledge features are difficult to symbolize and are implicit; thus, knowledge that is only explicitly represented cannot obtain comprehensive knowledge characteristics. Furthermore, semantic computation is an important goal of knowledge representation, and symbol-based knowledge representation methods cannot effectively calculate the semantic relationships between entities, as shown in Figures 4.4 and 4.5.
Knowledge representation methods are mainly divided into symbol-based knowledge representation methods and representation learning-based knowledge representation methods.
1. Symbol-Based Knowledge Representation MethodsThese methods are divided into early knowledge representation methods and semantic web knowledge representation methods. Early knowledge representation methods include first-order predicate logic representation, production rule representation, frame representation, and semantic network representation.
(1) First-Order Predicate Logic Representation
This knowledge representation method based on predicate logic describes objects, properties, states, and relationships using predicate formulas composed of propositions, logical connectives, individuals, predicates, and quantifiers. First-order predicate logic representation is based on mathematical logic, providing accurate results and natural expressions that are close to human natural language. However, it also has the drawback of poor representational capacity, being able to express only deterministic knowledge, and having limited expression for procedural and non-deterministic knowledge.
(2) Production Rule Representation
In the 1940s, logician Post proposed the production rule representation. Based on the logical causal relationships among knowledge, it formed the “IF-THEN” knowledge representation form, which was one of the common knowledge representation methods used in early expert systems. This representation method is similar to human causal judgment, being intuitive, natural, and easy to reason. Moreover, the range of knowledge expression in production rule representation is broad, including deterministic knowledge, uncertainty knowledge with confidence levels, heuristic knowledge, and procedural knowledge. However, due to its unified representation format, production rule representation has low reasoning efficiency when the knowledge scale is large, easily leading to the combinatorial explosion problem.
In the early 1970s, American AI expert M. Minsky proposed a “frame theory” for knowledge representation. This theory stems from the idea that people’s understanding of various objects in the objective world is stored in memory in a framework-like structure, leading to frame representation. A frame is a general data structure used to store accumulated information and experience. In frame structures, concepts from past experiences can be used to analyze and explain new information. When expressing knowledge, a frame can represent categories, individuals, attributes, and relationships of objects. A frame structure generally consists of four parts: “frame name-slot name-side value,” where a frame is composed of several slots, with each slot describing a certain aspect of the object’s attributes; a slot consists of several sides, used to describe an aspect of the corresponding attribute, each side having several values. Frames have advantages such as inheritance, structuring, and naturalness, but complex frame construction has high costs and requires high quality for the knowledge base, while their expression is not flexible enough, making it difficult to use in conjunction with other datasets.
(4) Semantic Network Representation
In 1960, cognitive scientist Allan M. Collins proposed the knowledge representation method of semantic networks. A semantic network is a directed graph that expresses knowledge through entities and the semantic relationships between them. In the graph, nodes represent objects, attributes, concepts, states, events, situations, actions, etc., while the arcs between nodes represent the semantic relationships between the two connected nodes. Depending on the knowledge situation being represented, the arc’s labels need to be defined, which are generally predicates in predicate logic, with common labels including instance relationships, classification relationships, membership relationships, attribute relationships, inclusion relationships, temporal relationships, spatial relationships, etc. A semantic network consists of semantic primitives, which can be described using triples (node1, arc, node2), and is composed of several semantic primitives and their semantic relationships. Semantic network representation has a wide range of representation and strong representational capabilities, with a simple and direct representation form that is easy to understand and conforms to natural language. However, semantic networks have issues such as the lack of standards for node and edge values, which are entirely defined by users, making knowledge sharing difficult, and the inability to distinguish between knowledge descriptions and knowledge instances.
2. Representation Learning-Based Knowledge Representation Methods
Early knowledge representation methods and semantic web knowledge representation methods explicitly represent concepts and their relationships through symbols. In fact, many knowledge features are difficult to symbolize and are implicit; thus, knowledge that is only explicitly represented cannot obtain comprehensive knowledge characteristics. Furthermore, semantic computation is an important goal of knowledge representation, and symbol-based knowledge representation methods cannot effectively calculate the semantic relationships between entities, as shown in Figures 4.4 and 4.5.
3. Knowledge Storage
Knowledge storage refers to the design of underlying storage methods for the representations of knowledge in knowledge graphs, completing the storage of various types of knowledge to support effective management and computation of large-scale graph data. The objects of knowledge storage include basic attribute knowledge, relational knowledge, event knowledge, temporal knowledge, and resource knowledge. The quality of knowledge storage methods directly affects the efficiency of knowledge querying, knowledge computation, and knowledge updating in the knowledge graph.
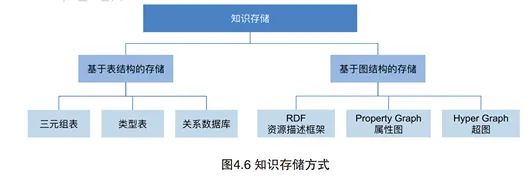
From the perspective of storage structure, knowledge storage is divided into table-structured storage and graph-structured storage, as shown in Figure 4.6.
4. Knowledge Fusion
The concept of knowledge fusion first appeared in literature published in 1983 [HOLSAPPLEC, et al., 1983] and gained widespread attention from researchers in the 1990s. Another definition of knowledge fusion refers to the process of merging information from multiple sources with different concepts, contexts, and expressions [Wikipedia]. [A. Smirnov, et al., 2002] believes that the goal of knowledge fusion is to generate new knowledge by integrating knowledge from loosely coupled sources to form a synthetic resource that complements incomplete knowledge and acquires new knowledge. [Tang Xiaobo, Wei Wei, et al., 2015] summarized many concepts of knowledge fusion and concluded that knowledge fusion is an interdisciplinary field of knowledge organization and information fusion, focusing on demand and innovation, processing knowledge acquisition, matching, integration, and mining from numerous scattered and heterogeneous resources to obtain hidden or valuable new knowledge, while optimizing the structure and connotation of knowledge and providing knowledge services.
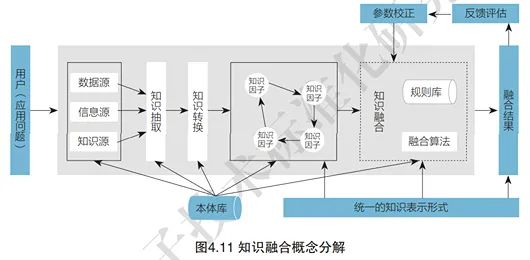
Knowledge fusion is a concept that continues to evolve. Although researchers’ specific expressions, perspectives, and emphases differ, there are many commonalities in their findings that reflect the inherent characteristics of knowledge fusion, allowing it to be distinguished from other similar or related concepts. Knowledge fusion is aimed at knowledge services and decision-making problems, based on multi-source heterogeneous data, and supported by ontology and rule repositories, through knowledge extraction and transformation to obtain hidden knowledge factors and their relationships in data resources, and then semantically combine, reason, and create new knowledge. This process needs to be dynamically adjusted in real-time according to changes in data sources and user feedback. The process of knowledge fusion can be decomposed from a flow perspective, as shown in Figure 4.11.
5. Knowledge Modeling
Knowledge modeling refers to establishing a data model for the knowledge graph, that is, determining how to express knowledge and construct an ontology model to describe knowledge. The ontology model needs to construct concepts, attributes, and relationships between concepts. The knowledge modeling process is the foundation for building a knowledge graph. A high-quality data model can avoid unnecessary and redundant knowledge acquisition work, effectively improve the efficiency of knowledge graph construction, and reduce the cost of domain data fusion. Different fields of knowledge have different data characteristics, allowing for the construction of different ontology models.
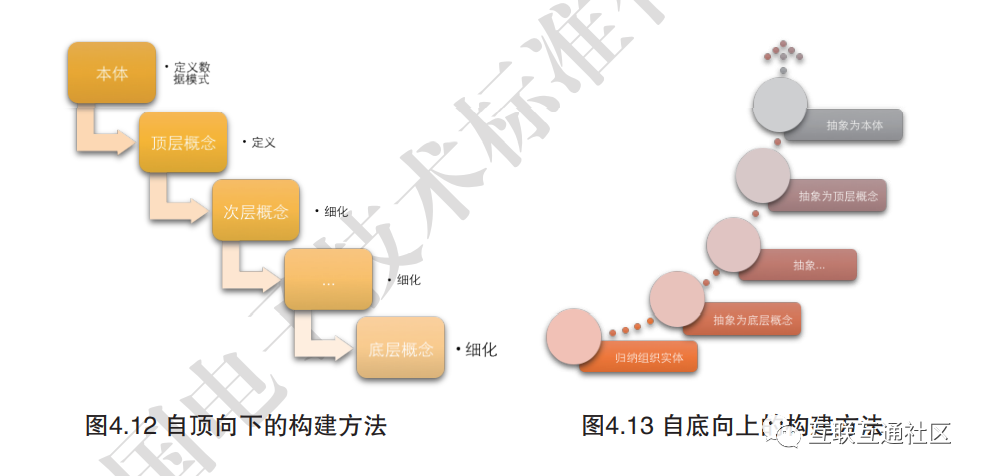
Knowledge modeling generally has two approaches: 1. Top-down approach (as shown in Figure 4.12) refers to defining the data schema, that is, the ontology, at the beginning of knowledge graph construction, usually compiled by domain experts. Starting from the top-level concepts, definitions are gradually refined, forming a well-structured classification hierarchy. 2. Bottom-up approach is the opposite (as shown in Figure 4.13), where existing entities are first organized inductively to form bottom-level concepts, which are then abstracted upwards to form higher-level concepts. The bottom-up approach is often used for constructing ontologies of open-domain knowledge graphs because the open world is too complex for the top-down approach to consider comprehensively, and as the world changes, the corresponding concepts continue to grow, making the bottom-up approach suitable for meeting the need for constantly growing concepts.
 The practical operation process of knowledge modeling can be divided into manual modeling and semi-automatic modeling. Manual modeling is suitable for small-scale knowledge modeling with high quality requirements, but cannot meet the needs of large-scale knowledge construction; it is a time-consuming, costly task requiring expertise. The hybrid method combines natural language processing with manual methods, suitable for large-scale and semantically complex graphs.
The practical operation process of knowledge modeling can be divided into manual modeling and semi-automatic modeling. Manual modeling is suitable for small-scale knowledge modeling with high quality requirements, but cannot meet the needs of large-scale knowledge construction; it is a time-consuming, costly task requiring expertise. The hybrid method combines natural language processing with manual methods, suitable for large-scale and semantically complex graphs.
6. Knowledge Computation
With the continuous development of knowledge graph technology and applications, the quality of graphs and the completeness of knowledge have become two major challenges affecting the application of knowledge graphs. Knowledge computation, focusing on graph quality improvement, potential relationship mining and completion, knowledge statistics, and knowledge reasoning, has become an important research direction in knowledge graph applications. Knowledge computation is the process of capability output based on the constructed knowledge graph, serving as the main way of capability output for knowledge graphs. The connotation of knowledge computation is illustrated in Figure 4.16, mainly including knowledge statistics and graph mining, and knowledge reasoning. Knowledge statistics and graph mining focus on knowledge querying, indicator statistics, and graph mining; knowledge reasoning focuses on logical reasoning algorithms based on graphs, including symbolic reasoning and statistical reasoning.
 Several key issues are clarified within the concept of knowledge computation:
(1) Knowledge computation addresses the issues of incompleteness and existing erroneous information in constructed knowledge graphs. On this basis, it combines methods such as knowledge statistics and graph mining, knowledge reasoning with traditional applications for capability output, thereby improving knowledge completeness and expanding knowledge coverage.
(2) Two representative capabilities in knowledge computation: knowledge statistics and graph mining, and knowledge reasoning. Knowledge statistics and graph mining methods are based on graph feature algorithms for community computing, similar subgraph computation, link prediction, inconsistency detection, etc.; the goal of knowledge reasoning is to derive new entities, relationships, and attributes from the given knowledge graph. Through these two capabilities, knowledge completion, correction, updating, and linking functions for existing graphs can be realized. Based on this, the capability output of knowledge computation can be applied to user profiling, decision data, assisted decision-making opinions, intelligent Q&A/search, and other aspects.
Several key issues are clarified within the concept of knowledge computation:
(1) Knowledge computation addresses the issues of incompleteness and existing erroneous information in constructed knowledge graphs. On this basis, it combines methods such as knowledge statistics and graph mining, knowledge reasoning with traditional applications for capability output, thereby improving knowledge completeness and expanding knowledge coverage.
(2) Two representative capabilities in knowledge computation: knowledge statistics and graph mining, and knowledge reasoning. Knowledge statistics and graph mining methods are based on graph feature algorithms for community computing, similar subgraph computation, link prediction, inconsistency detection, etc.; the goal of knowledge reasoning is to derive new entities, relationships, and attributes from the given knowledge graph. Through these two capabilities, knowledge completion, correction, updating, and linking functions for existing graphs can be realized. Based on this, the capability output of knowledge computation can be applied to user profiling, decision data, assisted decision-making opinions, intelligent Q&A/search, and other aspects.
7. Knowledge Maintenance
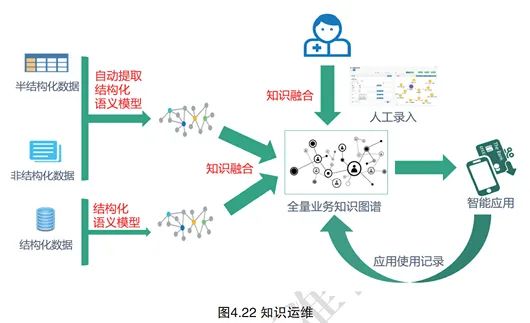
Due to the high cost of constructing a complete industry knowledge graph, the actual implementation process generally follows the principle of small steps and rapid iteration for knowledge graph construction and gradual evolution. Knowledge maintenance refers to the process of evolving and improving the complete industry knowledge graph after its initial construction, based on user feedback, newly emerging similar knowledge, and the addition of new knowledge sources. During maintenance, it is necessary to ensure that the quality of the knowledge graph is controllable and gradually enriched. The knowledge graph maintenance process is an engineering system that covers the entire lifecycle of knowledge graphs from knowledge acquisition to knowledge computation.
Knowledge maintenance includes two focal points: one is monitoring the construction process of the knowledge graph based on incremental data from the data source, and the other is identifying knowledge errors and new business needs discovered through the application layer of the knowledge graph. For example, issues such as incorrect entity attribute values, missing relationships between entities, unrecognized entities, and duplicate entities. These maintenance-exposed issues will be corrected in terms of the knowledge graph construction process, algorithm combinations, algorithm adjustments, and prioritization of newly added business knowledge, thereby improving knowledge quality and enriching knowledge content. Knowledge graph maintenance requires a combination of user feedback and expert manual issue discovery and correction, automated operation monitoring, and updates after algorithm adjustments, making it a human-machine collaborative process where experts and algorithms work together. The entire process of knowledge maintenance is illustrated in Figure 4.22: