

Source: DeepHub IMBA
This article is approximately 3300 words long and is recommended for a 5-minute read.
In this article, I will use two frameworks to complete some basic tasks in parallel.
When using large models locally, especially when building RAG applications, there are generally two mature frameworks available:
-
LangChain: A general framework for developing LLMs. -
LlamaIndex: A framework specifically designed for building RAG systems.

Choosing a framework is very important for the subsequent development of the project because changing frameworks later can be very difficult. Therefore, we will make a simple comparison of these two frameworks to give you an initial impression for your choice.
First, let’s take a look at their performance on GitHub and some public information:
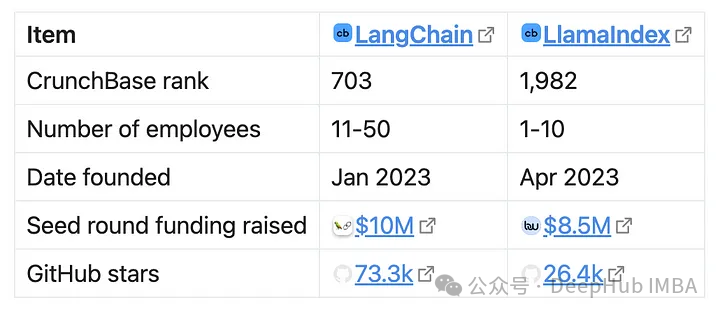
From a financial perspective, LlamaIndex’s funding scale is close to that of LangChain, although their target market is much smaller. This may indicate that LlamaIndex has a greater chance of survival due to more abundant funding. However, LangChain offers more enterprise-oriented products that can generate revenue (LangServe, LangSmith), so LangChain may have higher revenue, which makes it seem better.
The above is our random analysis of enterprise funding, for reference only. Now let’s get to the point. In this article, I will use both frameworks to complete some basic tasks in parallel. By comparing these code snippets, I hope it helps you make a choice.
1. Create a Chatbot with Local LLM
The first task is to create a chatbot using a local LLM.
Although it is local, we run the LLM on a separate inference server to avoid redundancy, allowing both frameworks to use the same service directly. While there are various modes for LLM inference APIs, we choose the mode compatible with OpenAI so that if we switch to OpenAI’s model, we do not need to modify the code.
Here is the method for LlamaIndex:
from llama_index.llms import ChatMessage, OpenAILike
llm = OpenAILike(
api_base="http://localhost:1234/v1",
timeout=600, # secs
api_key="loremIpsum",
is_chat_model=True,
context_window=32768,
)
chat_history = [
ChatMessage(role="system", content="You are a bartender."),
ChatMessage(role="user", content="What do I enjoy drinking?"),
]
output = llm.chat(chat_history)
print(output)
This is LangChain:
from langchain.schema import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_base="http://localhost:1234/v1",
request_timeout=600, # secs, I guess.
openai_api_key="loremIpsum",
max_tokens=32768,
)
chat_history = [
SystemMessage(content="You are a bartender."),
HumanMessage(content="What do I enjoy drinking?"),
]
print(llm(chat_history))
As you can see, the code is very similar.
LangChain distinguishes between chat llm (ChatOpenAI) and llm (OpenAI), while LlamaIndex uses the is_chat_model parameter in the constructor to distinguish.
LlamaIndex distinguishes between the official OpenAI endpoint and the OpenAILike endpoint, while LangChain decides where to send requests through the openai_api_base parameter.
LlamaIndex uses the role parameter to tag chat messages, while LangChain uses separate classes.
The two frameworks are basically indistinguishable, let’s continue.
2. Build RAG System for Local Files
We will build a simple RAG system that reads text from a local text file folder.
Here is the code using LlamaIndex documentation:
from llama_index import ServiceContext, SimpleDirectoryReader, VectorStoreIndex
service_context = ServiceContext.from_defaults(
embed_model="local",
llm=llm, # This should be the LLM initialized in the task above.
)
documents = SimpleDirectoryReader(
input_dir="mock_notebook/",
).load_data()
index = VectorStoreIndex.from_documents(
documents=documents,
service_context=service_context,
)
engine = index.as_query_engine(
service_context=service_context,
)
output = engine.query("What do I like to drink?")
print(output)
Using LangChain, the code gets much longer:
from langchain_community.document_loaders import DirectoryLoader
# pip install "unstructured[md]"
loader = DirectoryLoader("mock_notebook/", glob="*.md")
docs = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits, embedding=FastEmbedEmbeddings())
retriever = vectorstore.as_retriever()
from langchain import hub
# pip install langchainhub
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm # This should be the LLM initialized in the task above.
)
print(rag_chain.invoke("What do I like to drink?"))
These code snippets clearly illustrate the different abstraction levels of the two frameworks. LlamaIndex encapsulates the RAG pipeline with a method called “query engines,” while LangChain requires more internal components: including connectors for retrieving documents, prompt templates that represent “answer Y based on X,” and what it calls “chains” (as shown in the above LCEL).
When building with LangChain, you must know exactly what you want. For example, the position of calling from_documents makes it a very troublesome task for beginners, requiring more learning curve.
LlamaIndex can be used directly without explicitly choosing a vector storage backend, while LangChain requires explicit specification, which also requires more information because we are unsure if we made a wise decision when choosing the database.
Although both LangChain and LlamaIndex provide cloud services similar to Hugging Face (i.e., LangSmith Hub and LlamaHub), LangChain integrates it into almost all functionalities. We use pull to only download a short text template, which is as follows:
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don’t know the answer, just say that you don’t know. Use three sentences maximum and keep the answer concise. Question: {question} Context: {context} Answer:**
This is definitely an overkill. Although it does encourage sharing prompts within the community, is it really necessary?
3. RAG-Supported Chatbot
We will integrate the two simple functionalities above to obtain a truly usable simple application that can converse with local files.
Using LlamaIndex is as simple as swapping as_query_engine with as_chat_engine:
engine = index.as_chat_engine()
output = engine.chat("What do I like to drink?")
print(output) # "You enjoy drinking coffee."
output = engine.chat("How do I brew it?")
print(output) # "You brew coffee with a Aeropress."
When using LangChain, following the official tutorial, let’s first define memory (responsible for managing chat history):
# Everything above this line is the same as that of the last task.
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_core.messages import get_buffer_string
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import format_document
from langchain_core.prompts import ChatPromptTemplate
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
At the start of LLM, we need to load the chat history from memory.
load_history_from_memory = RunnableLambda(memory.load_memory_variables) | itemgetter(
"history"
)
load_history_from_memory_and_carry_along = RunnablePassthrough.assign(
chat_history=load_history_from_memory
)
Then we ask the LLM to enrich our questions with context:
rephrase_the_question = (
{
"question": itemgetter("question"),
"chat_history": lambda x: get_buffer_string(x["chat_history"]),
}
| PromptTemplate.from_template(
"""You're a personal assistant to the user.
Here's your conversation with the user so far:
{chat_history}
Now the user asked: {question}
To answer this question, you need to look up from their notes about """
)
| llm
| StrOutputParser()
)
However, we cannot just connect the two because topics may change during the conversation, making most semantic information in the chat history irrelevant.
Then we run RAG.
retrieve_documents = {
"docs": itemgetter("standalone_question") | retriever,
"question": itemgetter("standalone_question"),
}
Answering the questions:
rephrase_the_question = (
{
"question": itemgetter("question"),
"chat_history": lambda x: get_buffer_string(x["chat_history"]),
}
| PromptTemplate.from_template(
"""You're a personal assistant to the user.
Here's your conversation with the user so far:
{chat_history}
Now the user asked: {question}
To answer this question, you need to look up from their notes about """
)
| llm
| StrOutputParser()
)
After obtaining the final response, we append it to the chat history.
final_chain = (
load_history_from_memory_and_carry_along
| {"standalone_question": rephrase_the_question}
| retrieve_documents
| compose_the_final_answer
)
# Demo. inputs = {"question": "What do I like to drink?"}
output = final_chain.invoke(inputs)
memory.save_context(inputs, {"answer": output.content})
print(output) # "You enjoy drinking coffee."
inputs = {"question": "How do I brew it?"}
output = final_chain.invoke(inputs)
memory.save_context(inputs, {"answer": output.content})
print(output) # "You brew coffee with a Aeropress."
This is a very complex process, and through this process, we learned a lot about how LLM-driven applications are built. In particular, the LLM is called several times, assuming different roles: query generator, summarizer of retrieved documents, and participant in the conversation. This is very helpful for learning, but is it a bit complex for applications?
4. Agent
The RAG pipeline can be considered a tool. The LLM can access multiple tools, such as providing search, encyclopedia queries, weather forecasts, etc. In this way, the chatbot can answer questions beyond its direct knowledge.
Tools do not necessarily have to provide information; they can also perform other operations, such as placing orders or replying to emails.
With these tools, the LLM needs to decide which tools to use and in what order. The LLM’s role when using these tools is called an “agent.”
There are various ways to provide agents for the LLM. The most model-generic method is the ReAct paradigm.
Here is how to use it in LlamaIndex:
from llama_index.tools import ToolMetadata
from llama_index.tools.query_engine import QueryEngineTool
notes_query_engine_tool = QueryEngineTool(
query_engine=notes_query_engine,
metadata=ToolMetadata(
name="look_up_notes",
description="Gives information about the user.",
),
)
from llama_index.agent import ReActAgent
agent = ReActAgent.from_tools(
tools=[notes_query_engine_tool],
llm=llm,
service_context=service_context,
)
output = agent.chat("What do I like to drink?")
print(output) # "You enjoy drinking coffee."
output = agent.chat("How do I brew it?")
print(output) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."
For our follow-up question, “how do I brew coffee,” the agent’s response is different from when it was just a query engine. This is because the agent can decide for itself whether to look at our local notes. If they are confident enough to answer the question, the agent may choose not to use any tools. If the LLM finds that it cannot answer the question, it will use RAG to search our local files (the responsibility of our query engine is to find documents from the index, so it will definitely choose this).
Agents are a high-level API in LangChain:
from langchain.agents import AgentExecutor, Tool, create_react_agent
tools = [
Tool(
name="look_up_notes",
func=rag_chain.invoke,
description="Gives information about the user.",
),
]
react_prompt = hub.pull("hwchase17/react-chat")
agent = create_react_agent(llm, tools, react_prompt)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools)
result = agent_executor.invoke(
{"input": "What do I like to drink?", "chat_history": ""}
)
print(result) # "You enjoy drinking coffee."
result = agent_executor.invoke(
{
"input": "How do I brew it?",
"chat_history": "Human: What do I like to drink?\nAI: You enjoy drinking coffee.",
}
)
print(result) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."
Although we still need to manage chat history manually, creating an agent is much easier than creating RAG. create_react_agent and AgentExecutor integrate most of the underlying work.
Conclusion
LlamaIndex and LangChain are two frameworks for building LLM applications. LlamaIndex focuses on RAG use cases, while LangChain has a broader application. We can see that for RAG-related use cases, LlamaIndex is much more convenient and can be considered the first choice.
However, if your application requires some non-RAG functionalities, LangChain may be a better choice.
Editor: Huang Jiyan
