
Click on the above “Beginner’s Guide to Visual Learning” to choose to add “Star” or “Top”
Heavyweight content delivered at the first time

Editor | Anke
Produced by | Panchuang AI Technology Team
Table of Contents:
-
Introduction to Gated Recurrent Neural Networks
-
Long Short-Term Memory Networks (LSTM)
-
Gated Recurrent Units (GRU)
-
Implementing LSTM and GRU with TensorFlow
-
References
1. Gated Recurrent Neural Networks
Gated recurrent neural networks adjust the structure of simple recurrent neural networks by adding gating mechanisms to control the flow of information within the neural network. The gating mechanism can determine how much information needs to be retained in the memory unit, how much needs to be discarded, and how much new state information needs to be saved in the memory unit. This allows gated recurrent neural networks to learn relatively long dependencies without the issues of gradient vanishing and gradient explosion. Mathematically, in a typical recurrent neural network, the relationship between the network’s state and its parameters W is nonlinear, and the parameters W are shared at each time step, which is the fundamental reason for gradient explosion and vanishing. The solution provided by gated recurrent neural networks is to add a linear dependency between the states, thereby avoiding the problems of gradient vanishing or explosion.
2. Long Short-Term Memory Networks (LSTM)
The structure of Long Short-Term Memory networks (LSTM) is shown in Figure 1. The LSTM network structure may seem complex, but it is quite simple when broken down into its components. In standard recurrent neural networks, memory units lack the ability to evaluate the value of information, leading to the storage of many useless information while discarding truly useful information. LSTM improves upon this by differentiating the network states into internal and external states. The external state of LSTM is akin to the state in standard recurrent neural networks, serving as both the output of the hidden layer at the current time and the input to the hidden layer at the next time step. The internal state is unique to LSTM.
In LSTM, there are three control units called “gates”: the input gate, output gate, and forget gate. The input and forget gates are crucial for LSTM’s ability to remember long-term dependencies. The input gate determines how much information from the current state should be saved in the internal state, while the forget gate decides how much past state information should be discarded. Finally, the output gate determines how much information from the current internal state should be output to the external state.
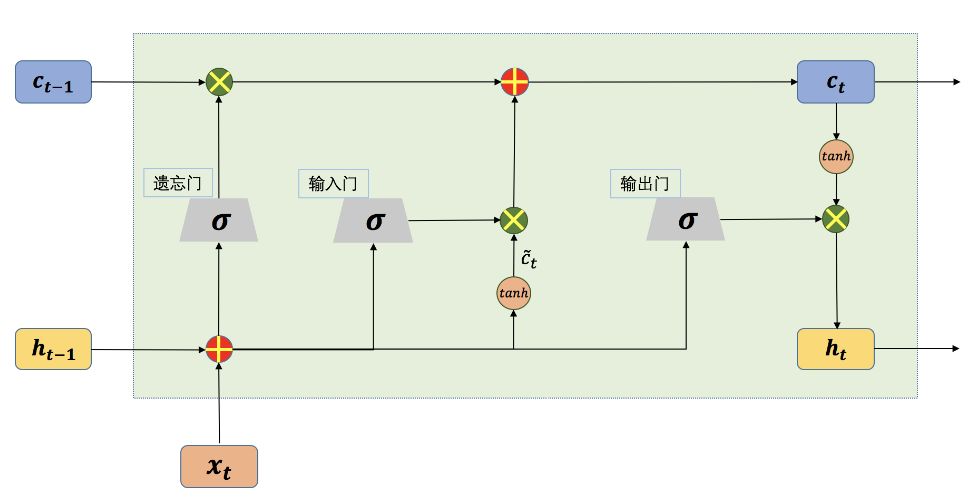
Figure 1: Schematic Diagram of LSTM Network Structure at a Single Time Step
As seen in the diagram, an LSTM unit receives three inputs at each time step: the current input, the internal state from the previous time step, and the external state from the previous time step. Here, the input from the current time and the previous internal and external states serve as inputs to the three gates.
… (content continues with similar translations for the remaining sections) …