
1. Introduction to RNN
Recurrent Neural Network (RNN) is a type of neural network used for processing sequential data. Unlike traditional feedforward neural networks, RNN introduces an “internal state” (also known as “hidden state”), which allows the network to store past information and use it to influence subsequent outputs. The updating process of this internal state enables RNN to handle input sequences of varying lengths, such as text or speech data.
The characteristic of RNN is that there are connections between units at different time steps, forming a directed graph that unfolds along the time dimension. This structure allows RNN to capture dynamic features that change over time in a sequence, making it particularly suitable for tasks related to time series data, such as natural language processing, speech recognition, and stock prediction.
Application of RNN in Deep Reinforcement Learning
In Deep Reinforcement Learning (DRL), RNN is used to solve decision-making problems with temporal dependencies. For example, the DRQN (Deep Recurrent Q-Learning Network) algorithm combines RNN and Q-Learning to handle incomplete information issues that may arise in environments like Atari games.
Variants of RNN
As research has progressed, it has been found that traditional RNNs are prone to the problems of gradient vanishing or explosion, which limits the model’s ability to handle long sequences. To address this issue, several variants of RNN have been proposed, the most famous being Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRU). These variants introduce gating mechanisms to more effectively control the flow of information, thus better learning long-range dependencies.
Role of RNN in MDP
In Markov Decision Process (MDP), the agent needs to make decisions based on the current observation state and previous historical states at each time step. RNN, through its continuous updating of internal states, allows the agent to incorporate historical information into current action choices.
Support for RNN by DI-engine
DI-engine is a deep reinforcement learning framework that supports RNN networks and provides a user-friendly API, making it easier for researchers and developers to implement RNN and its variants. Through these APIs, users can integrate RNN into their reinforcement learning models to solve complex tasks that require processing sequential data.
Relevant Components in DI-engine

Here we briefly analyze the main functions of ding/torch_utils/network/rnn.py:
1. Defines several utility functions:
is_sequence: Determines if the input is a list or tuple
sequence_mask: Generates a mask based on sequence lengths
LSTMForwardWrapper: Wraps the forward and backward processing logic of LSTM
2. Implements three types of LSTM units:
LSTM: Custom LSTM unit using LayerNorm
PytorchLSTM: Wraps nn.LSTM in PyTorch, formats inputs and outputs
GRU: Wraps nn.GRUCell, also formats inputs and outputs
3. get_lstm: Returns different implementations of LSTM units based on input parameters
Supports four types: ‘normal’, ‘pytorch’, ‘hpc’, ‘gru’
hpc type requires calling the implementation on the HPC platform, others are standard PyTorch implementations
4. Each type of LSTM unit implements a forward function, differing in:
Input/output formatting
Whether LayerNorm is used
For hidden states, can return either Tensor or List formats
5. The forward function calls the hook function of LSTMForwardWrapper for input/output encapsulation
This design allows different LSTM implementations to be called through a unified interface, isolating the input/output format handling logic. The program implements flexible and configurable LSTM units, providing a clear and unified interface by combining basic PyTorch modules.
The implementation of the forward function in the LSTM class is very elegant:
1. Calls the hook function for preprocessing input states, enhancing reusability
2. Executes the LSTM computation process layer by layer and time step by time step, with a clear code structure
3. Uses a list to save the output at each time step, which is stacked at the end
4. Adds configurable dropout operations
5. Encapsulates the output format of next_state, enhancing flexibility
This implementation considers both the clarity of the computation process and the flexibility of the interface, making the LSTM unit easier to reuse and extend.
def forward(self, inputs: torch.Tensor, prev_state: torch.Tensor, list_next_state: bool = True) -> Tuple[torch.Tensor, Union[torch.Tensor, list]]:<br/> # Call the hook function for preprocessing input states<br/> prev_state = self._before_forward(inputs, prev_state) <br/> H, C = prev_state x = inputs next_state = [] for l in range(self.num_layers): h, c = H[l], C[l] new_x = [] for s in range(seq_len): # Compute the values of different gates gate = ... i, f, o, u = gate<br/> # LSTM computation formula c = f * c + i * u h = o * torch.tanh(c)<br/> new_x.append(h) next_state.append((h, c)) x = torch.stack(new_x, dim=0)<br/> # Add dropout if self.use_dropout and l != self.num_layers - 1: x = self.dropout(x)<br/> # Encapsulate the format of next_state next_state = self._after_forward(next_state, list_next_state) return x, next_stateWhich Strategies in DI-engine Support RNN Structure
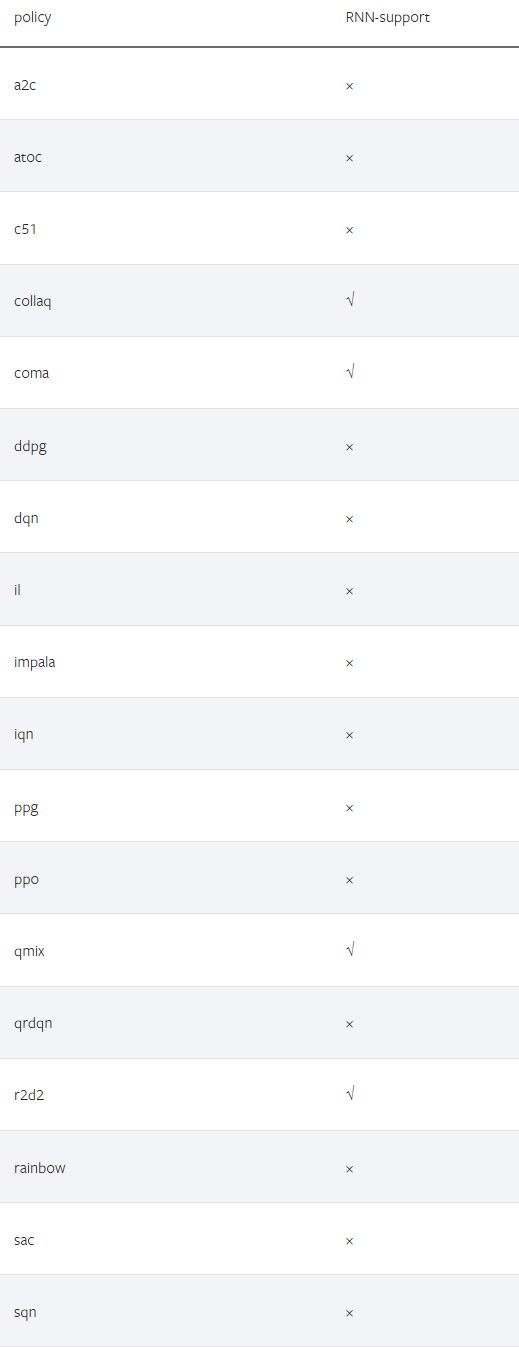
2. Using RNN in DI-engine
Building a Model with RNN
We can use DI-engine’s implemented models containing RNN or define our own models.
Using DI-engine Implemented Models:
DI-engine’s DRQN provides RNN support for discrete action space environments (default is LSTM). We can specify the model type in the configuration or set a default model in the strategy to use it.
# in config file<br/>policy=dict(<br/> ...<br/> model=dict(<br/> type='drqn',<br/> import_names=['ding.model.template.q_learning']<br/> ),<br/> ...<br/>),...policy is a dictionary that contains parameters for configuring the agent’s behavior.
model is a key in the policy dictionary, and its value is also a dictionary used to define the specific settings of the model.
In the model dictionary, the type key is set to ‘drqn’, indicating that the model type we are using is DRQN.
import_names is a list that includes the module path where the DRQN model implementation code is located, ding.model.template.q_learning.
# or set policy default model<br/>def default_model(self) -> Tuple[str, List[str]]: return 'drqn', ['ding.model.template.q_learning']In the above method:
The default_model method returns a tuple, the first element is the model name ‘drqn’, and the second element is a list containing the module path of the model implementation [‘ding.model.template.q_learning’].
Using a custom model. Please refer to https://www.guyuehome.com/45791. Our custom model’s output dict should include the next_state key.
class your_model(nn.Module):<br/>def forward(x): # the input data `x` must be a dict, contains the key 'prev_state', the hidden state of last timestep ... return { 'logit': logit, 'next_state': hidden_state, ... }Using Model Wrapper to Wrap the Model in the Strategy
RNN models need to maintain certain state information during continuous decision-making. RNN-type models rely on hidden states to maintain and transmit time series information.
The HiddenStateWrapper provided by DI-engine can manage and maintain the hidden state of RNN models in sequential decision-making. This wrapper allows users to embed their models into the strategy. We only need to wrap the model during the initialization phase of the strategy’s learning/collection/evaluation. The HiddenStateWrapper will help the agent retain hidden states during model computation and send these hidden states during the next model computation.
The workflow of HiddenStateWrapper can be represented as follows:
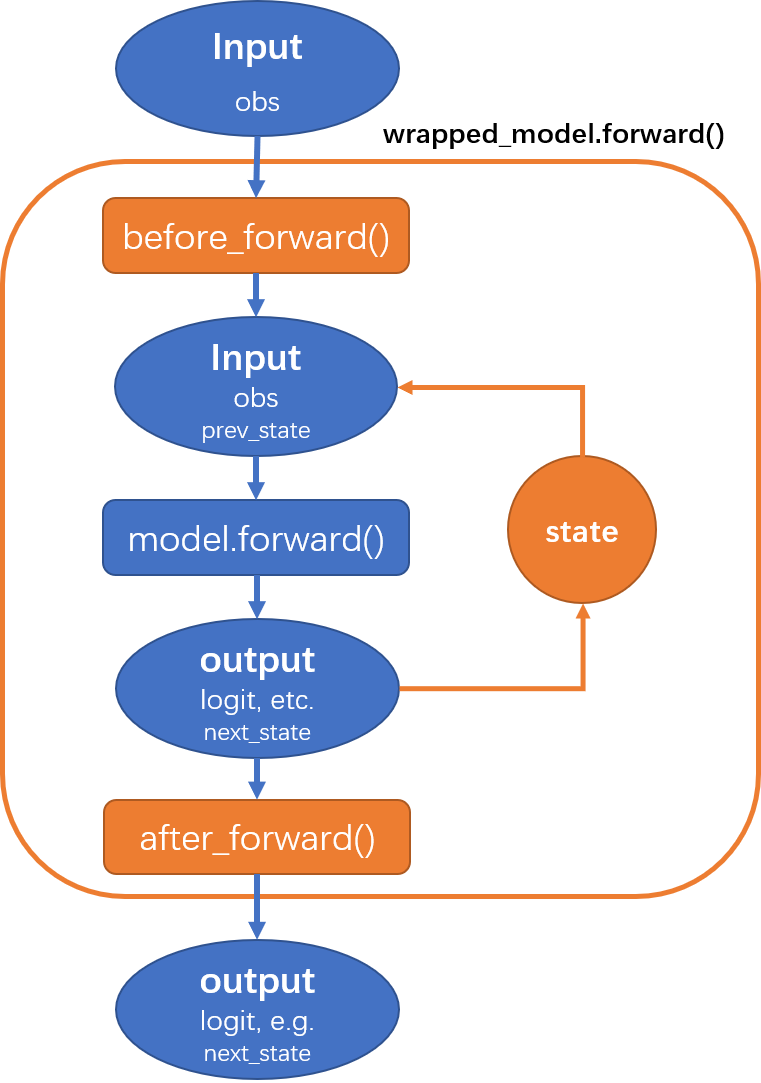
# In policy<br/>class your_policy(Policy):<br/> def _init_learn(self) -> None: ... self._learn_model = model_wrap(self._model, wrapper_name='hidden_state', state_num=self._cfg.learn.batch_size)<br/> def _init_collect(self) -> None: ... self._collect_model = model_wrap( self._model, wrapper_name='hidden_state', state_num=self._cfg.collect.env_num, save_prev_state=True )<br/> def _init_eval(self) -> None: ... self._eval_model = model_wrap(self._model, wrapper_name='hidden_state', state_num=self._cfg.eval.env_num)This policy class contains three initialization methods, used for learning (_init_learn), data collection (_init_collect), and evaluation (_init_eval) phases, respectively. All three methods utilize the model_wrap function to wrap the model in the strategy to manage the model’s hidden states during these different phases.
Now, let’s analyze these three methods one by one:
_init_learn Method
def _init_learn(self) -> None:<br/> ...<br/> self._learn_model = model_wrap( self._model, wrapper_name='hidden_state', state_num=self._cfg.learn.batch_size )During initialization in the learning (training) phase, the _init_learn method wraps self._model (the strategy’s model) using the model_wrap function. Here, wrapper_name=’hidden_state’ specifies the use of the hidden state wrapper, and state_num=self._cfg.learn.batch_size specifies the number of hidden states, which should match the training batch size. This is because each batch of data during learning may require independent hidden states.
Imagine you are learning something new, and you take notes each time, so you can continue learning next time. The _init_learn method does this. It uses model_wrap to set the model to remember the state of each learning session. state_num is the amount of memory, which should be the same as our learning batch size, for the simple reason that each batch of data may need to remember something separately.
_init_collect Method
def _init_collect(self) -> None:<br/> ...<br/> self._collect_model = model_wrap( self._model, wrapper_name='hidden_state', state_num=self._cfg.collect.env_num, save_prev_state=True )Data collection phase initialization is performed in the _init_collect method. Similarly, the model is wrapped using the model_wrap function, this time the state_num is set to self._cfg.collect.env_num, which represents the number of environments, because each environment needs to maintain its own hidden state during parallel data collection. The save_prev_state=True parameter indicates that the wrapper should save the previous state after each time step, which is crucial for maintaining state coherence in continuous decision-making.
In simpler terms, when you are collecting information in different environments, each environment may have different situations, and you need to remember the information for each environment separately. The _init_collect method follows this logic. The state_num is the number of environments because we may collect data simultaneously in several places. save_prev_state=True tells the model not to forget to record after each collection so that it can know what happened last time.
_init_eval Method
def _init_eval(self) -> None:<br/> ...<br/> self._eval_model = model_wrap( self._model, wrapper_name='hidden_state', state_num=self._cfg.eval.env_num )The evaluation phase initialization is performed in the _init_eval method. Here, the model is also wrapped using model_wrap, with state_num set to self._cfg.eval.env_num, referring to the number of environments used during evaluation. Each environment also needs to have its own hidden state to ensure the accuracy of the evaluation.
Evaluation is like taking a test; you need to remember which classroom you took the test in, as each classroom may have different conditions. The _init_eval method is set up this way, using model_wrap to manage the state of each environment. The state_num here is the number of environments used during evaluation.
Putting all this together, this code allows the model’s memory to be preserved and used when needed through model_wrap and a hidden state wrapper called hidden_state during learning, data collection, and evaluation phases. The benefit of this approach is that using RNN, which requires memory, for decision-making becomes much easier, especially in tasks that require continuous memory.
Now that we have completed the construction of the RNN model and wrapped it in the strategy, in the next article, we will complete: raw data processing, initializing hidden states, and Burn-in (Optional).