
MLNLP community is a well-known machine learning and natural language processing community in China and abroad, covering NLP master’s and doctoral students, university teachers, and corporate researchers.The community’s vision is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for beginners. Reprinted from | Quantum Bit Author | Meng Chen
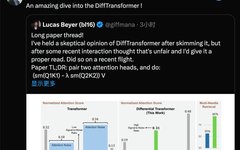
Core author of ViT Lucas Beyer has analyzed a paper on improving the Transformer architecture and shared his detailed annotations and interpretations.
Recently, he transitioned from Google to OpenAI, and he read the paper and wrote his analysis while on a plane.
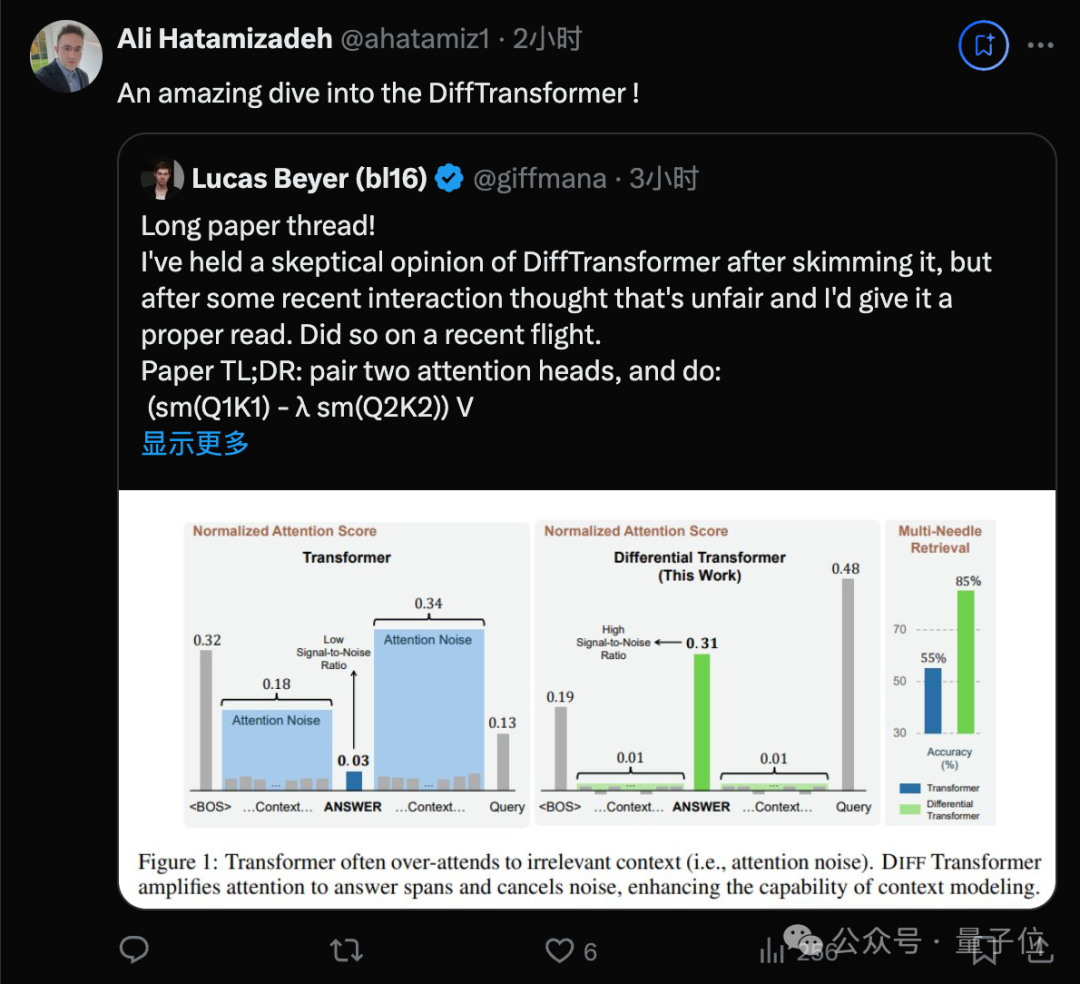
This paper is abbreviated by him as DiffTransformer, but it is not the Diffusion Transformer based on the Sora architecture, rather it is the Differential Transformer from Microsoft.
The paper introduces an overall idea similar to differential amplification circuits or noise-canceling headphones, using the difference between two signals to filter out common-mode noise, addressing the low signal-to-noise ratio issue of the Transformer model.
This paper garnered significant attention upon its release, but also faced some skepticism. In the bullet-screen version of alphaXiv, the author engaged in many discussions with readers.

Beyer initially held a reserved attitude towards this paper, questioning, “Can’t the two attention heads in MHA learn these?”.
However, after some recent interactions with peers, he felt that one should not jump to conclusions too easily. After reviewing the paper again, he changed his perspective.
My initial impression was completely shattered by the team’s experiments, which were very fair and cautious.
Additionally, there is a little Easter egg:
Big names often use their airplane time to play a few quick rounds of Dota 2.
Writing this post cannot count as work for paper review in my resume; it is purely a contribution of personal time, and I won’t be writing frequently in the future.
In any case, let’s give a thumbs up to the big names.
Insights on Hot Papers by Experts
Beyer evaluates the core innovation of this paper as very simple and nice, which can be summarized in one sentence.
Pair two attention heads and then execute (softmax(Q1K1) – λ*softmax(Q2K2)) V, where λ is a learnable scalar.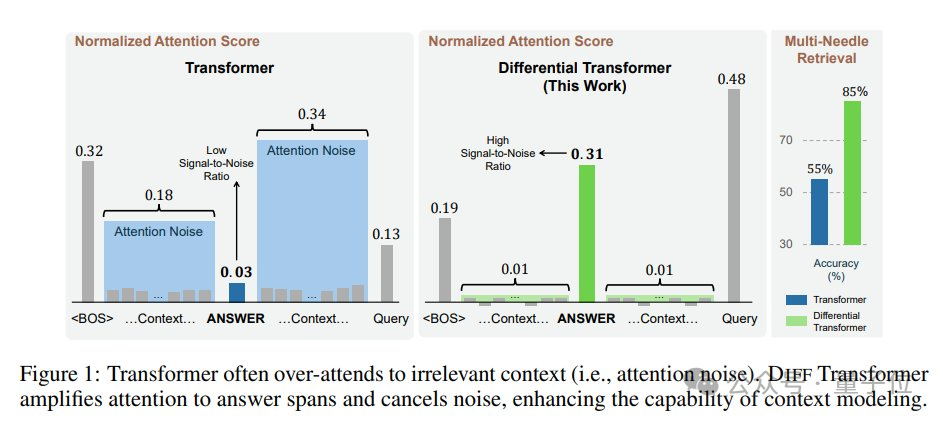
He believes the motivation for this research is very sufficient: as the context length increases, the sum of attention to (slightly) irrelevant tokens may exceed the attention to a few relevant tokens, thereby drowning them out.
This insight indicates that as the input length increases, the classic Transformer may struggle more to capture key information. The DIFF Transformer attempts to address this issue.
However, he is still uncertain how significant this issue is for well-trained models and hopes to see some graphs about attention distribution/entropy in the DIFF Transformer paper to substantiate the reasonableness of this illustration.
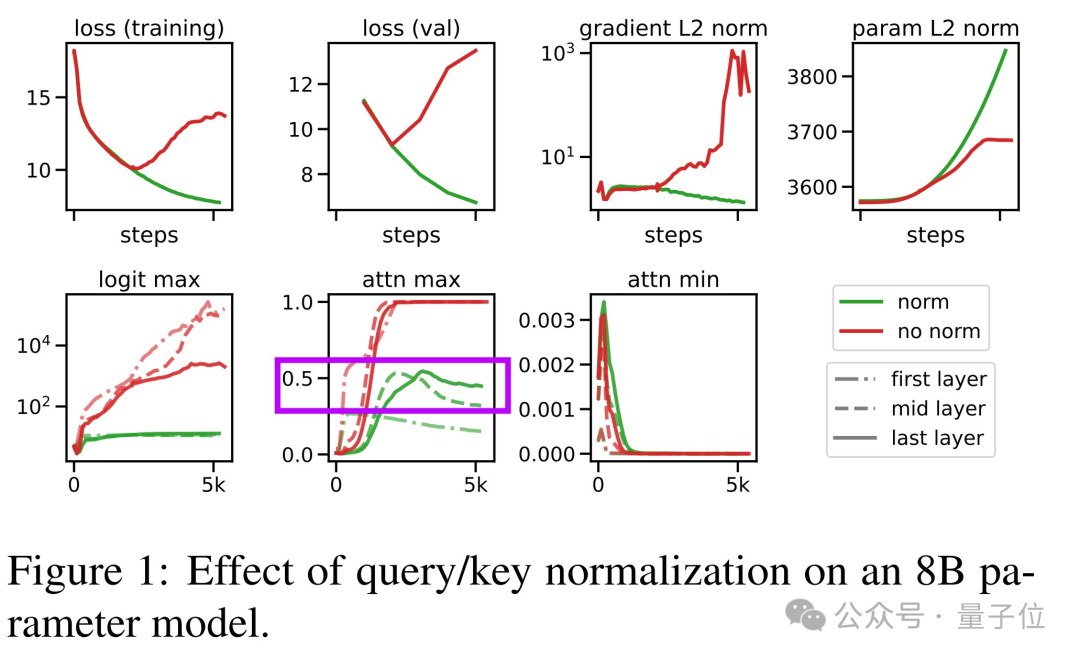
Next, he pointed out several easily overlooked details:
-
Unlike Figure 1, DiffAttn does not actually renormalize the difference. So how does it “amplify” the “relevant” scores?
Beyer suggests that the paper provides more actual training analysis graphs of the DIFF Transformer.

-
The calculation of λ is quite complex, involving the difference of two learnable exponential functions, plus some baseline λ_init, which is 0.1 in the early layers and then 0.8 later.
Beyer believes λ does not necessarily need to be positive and suggests providing more analysis on the learnable λ parameter.
-
The output of each attention head is normalized and multiplied by (1-λ_init), then concatenated and multiplied by WO, where more graphs are needed to prove this.

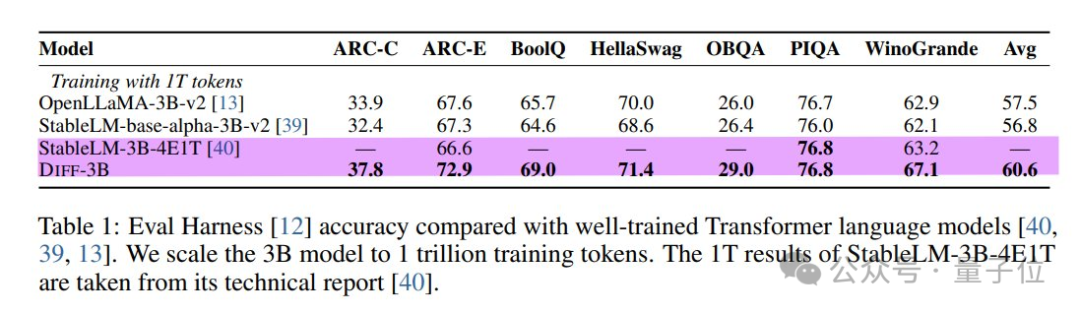
Next, discussing the numerous experiments in the paper. The researchers essentially forked StableLM-3B-4E1T, calling it Diff-3B, for comparison as the baseline model.
Unfortunately, the baseline model only reported results on three datasets, of which Diff-3B performed quite well on two.
Beyer doubts whether this StableLM-3B is truly a strong baseline.
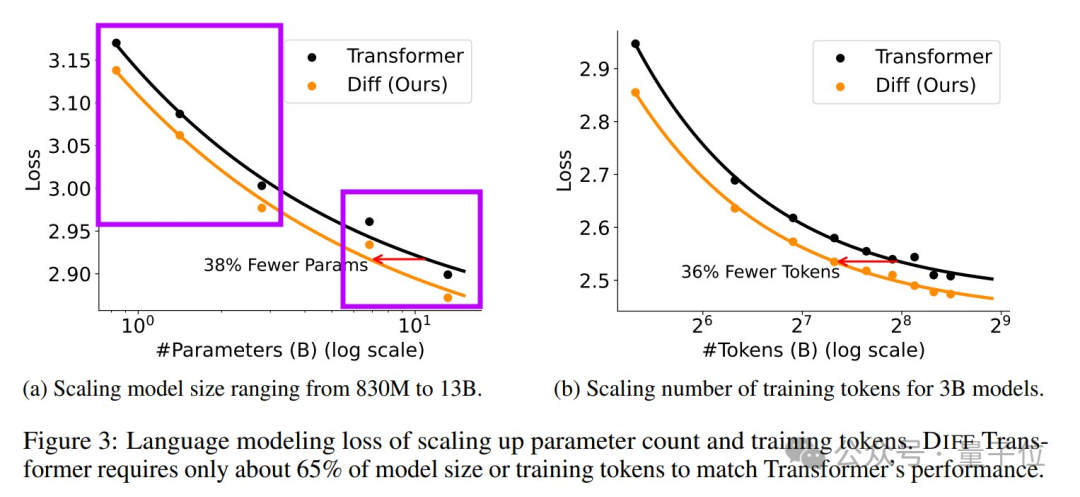
In the scaling curves of parameter count and token number, the DIFF Transformer initially appears promising. However, upon closer inspection, Beyer raises two points of concern:
-
The scaling curves are clearly divided into two groups, drawing a line between them seems a bit forced. Looking at the appendix, it can be seen that the researchers lowered the learning rate for the larger two models. Does this mean they encountered stability issues?
-
Each experiment used only 10B tokens for training, which is quite small. Beyer understands the computational resource limitations but still feels a bit uneasy.

These experiments suggest that the DIFF Transformer performs somewhat better given the same size and training time.
However, its inference speed is also slightly slower (5-10% slower).
Beyer suggests it would be best to see scaling curves with computational load or actual time on the x-axis.
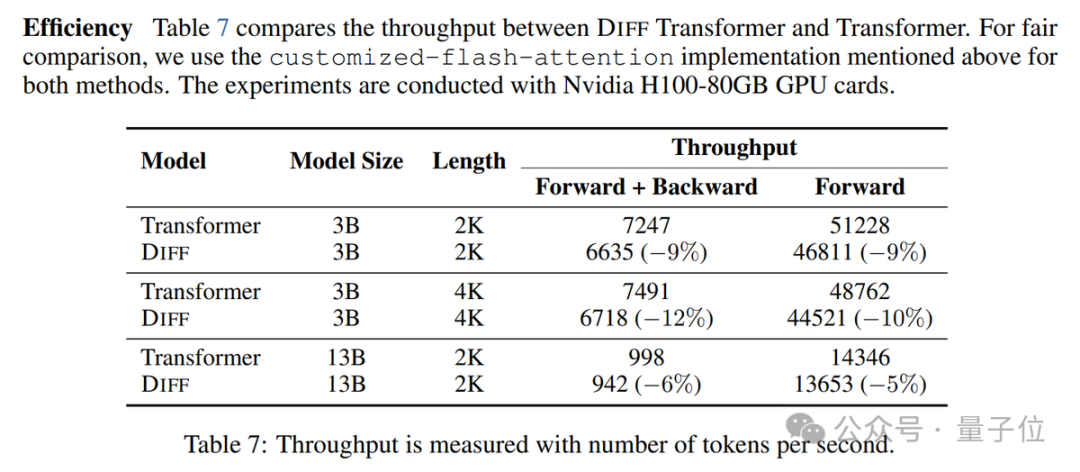
In long text evaluation and robustness to input sample order, the DIFF Transformer showed significant advantages.
Especially in the robustness experiment of context learning, the DIFF Transformer had far less performance variance under different sample arrangements compared to the classic Transformer.
This indicates that it is less susceptible to subtle changes in input, while the classic Transformer is easily affected by sample order, showing a large performance gap between the best and worst cases.
Overall, Beyer’s view of this paper has changed:
The researchers’ experiments are very comprehensive and cautious, indeed showing more potential for the DIFF Transformer than merely “subtracting two attention heads”.
This work shows some promising sparks. Whether it can replicate well in others’ training tasks or provide assistance remains to be seen.
Who is Lucas Beyer
In early December, Lucas Beyer, along with Xiaohua Zhai and Alexander Kolesnikov, was collectively poached from Google to OpenAI.
They together proposed the Vision Transformer, pioneering the application of Transformers in the field of CV.

According to his personal website, he grew up in Belgium, dreaming of making video games and engaging in AI research.
He studied mechanical engineering at RWTH Aachen University in Germany, where he obtained a Ph.D. in robotic perception and computer vision, and joined Google in 2018.

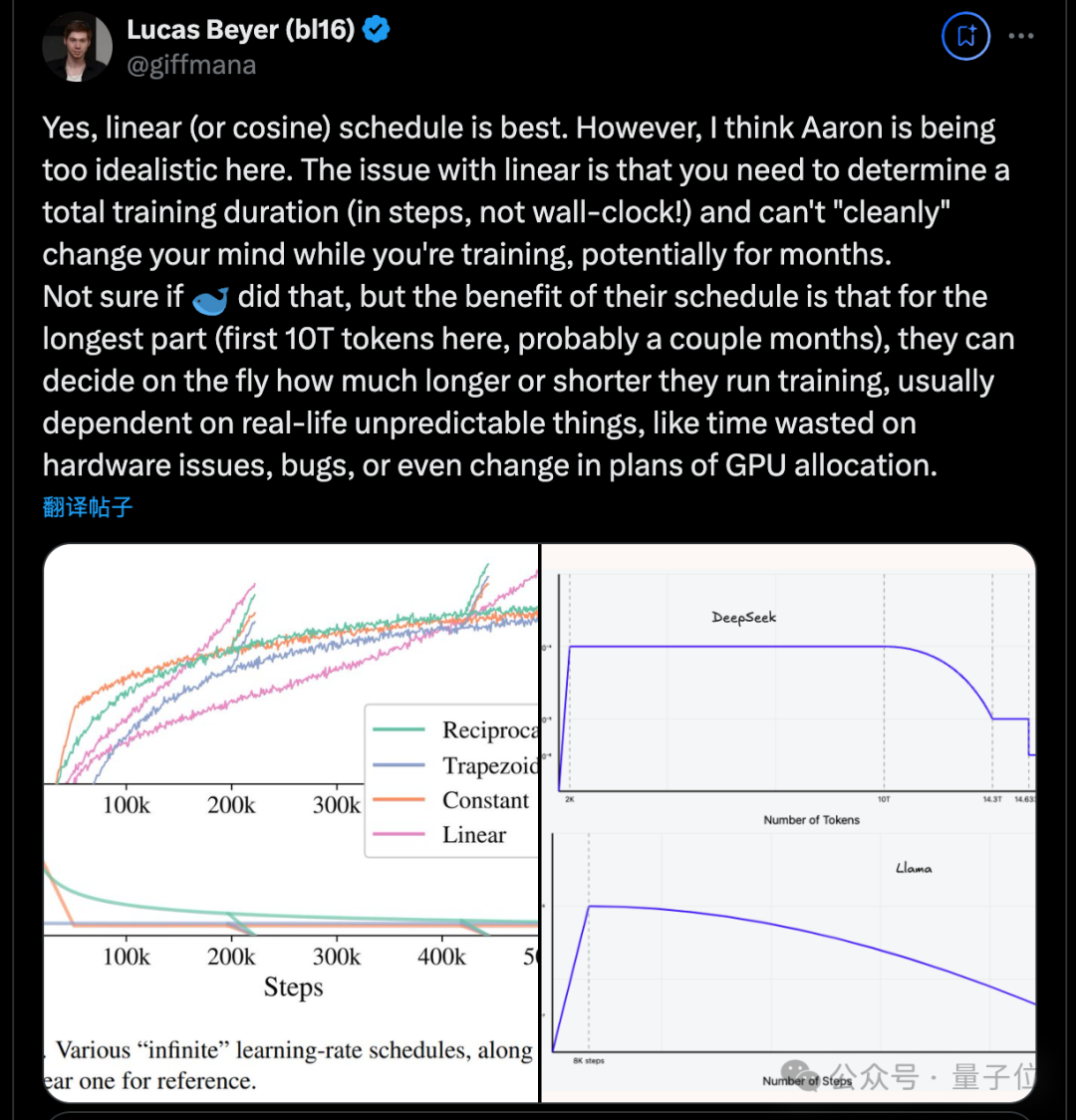
Aside from this long analysis of the DIFF Transformer, he often makes brief comments on new research, such as the recently popular DeepSeek v3, where he also offers his suggestions.
In summary, he is a scholar worth paying attention to.
DIFF Transformer paper: https://arxiv.org/abs/2410.05258
Reference link: [1]https://x.com/giffmana/status/1873869654252544079
Technical Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant’s WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System) to apply for joining technical groups such as Natural Language Processing/Pytorch
About Us
MLNLP community is a grassroots academic community jointly built by machine learning and natural language processing scholars from home and abroad. It has developed into a well-known machine learning and natural language processing community, aiming to promote progress among practitioners in academia, industry, and enthusiasts.The community can provide an open communication platform for the further education, employment, and research of related practitioners. Everyone is welcome to follow and join us.
