Recommended Reading Time: 8min~13min
Reason for Recommendation: This is a summary and reflection after watching Professor Li Hongyi’s deep learning videos from National Taiwan University. After finishing the introduction of the first part, particularly the introduction to RNN and especially LSTM, I felt enlightened.
Recurrent Neural Network (RNN) is a type of neural network used for processing sequential data. Compared to general neural networks, it can handle data that changes over sequences. For example, the meaning of a word can differ based on the preceding context, and RNN can effectively solve such problems.
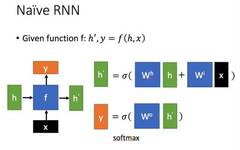
Let me briefly introduce a standard RNN.
The main form is shown in the figure below (all images are from Professor Li Hongyi’s PPT):
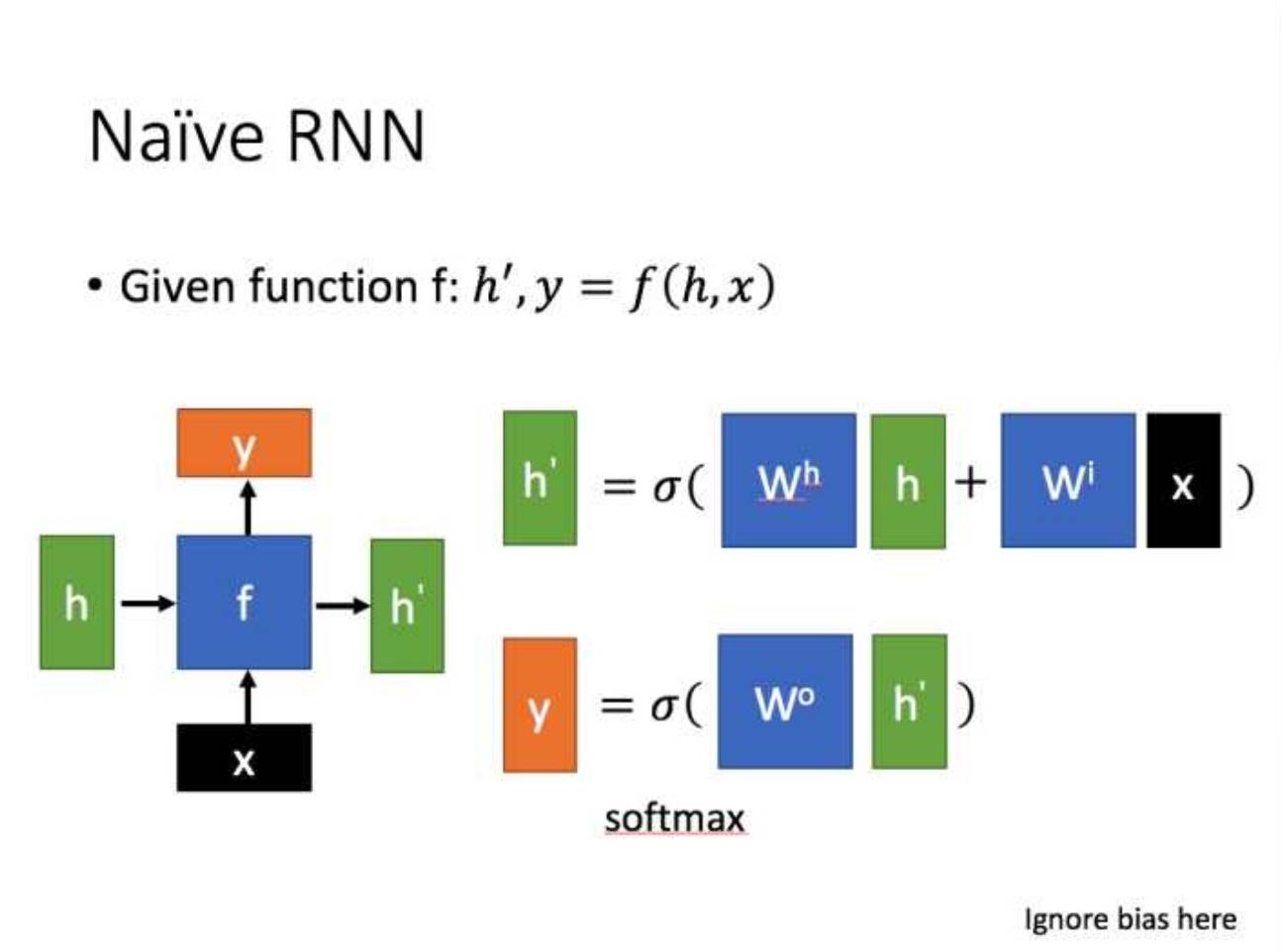

By inputting in sequential form, we can obtain the following form of RNN.
Long Short-Term Memory (LSTM) is a special type of RNN, mainly designed to address the issues of vanishing and exploding gradients during the training of long sequences. In simple terms, compared to ordinary RNNs, LSTM performs better over longer sequences.
The LSTM structure (right figure) mainly differs from ordinary RNN in terms of input and output as shown below.
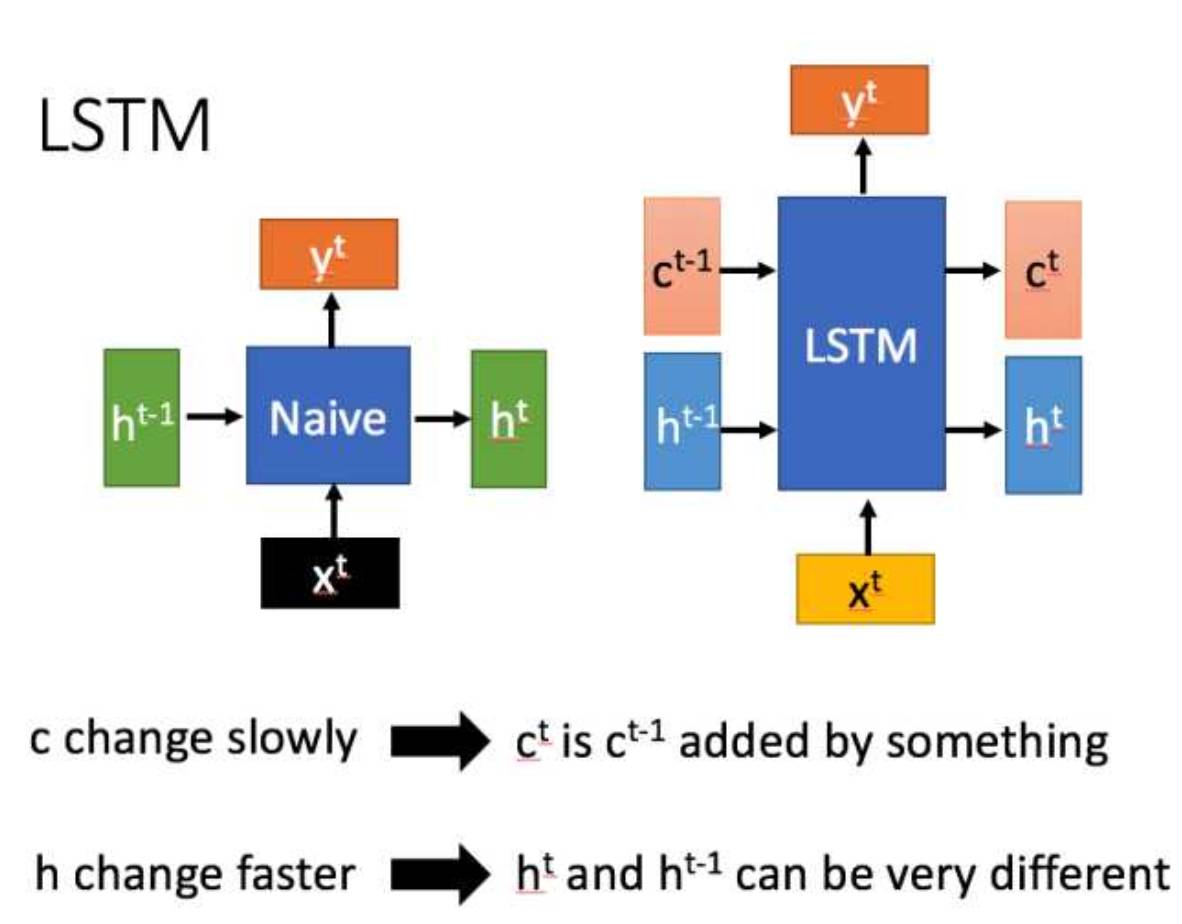

Next, let’s analyze the internal structure of LSTM in detail.
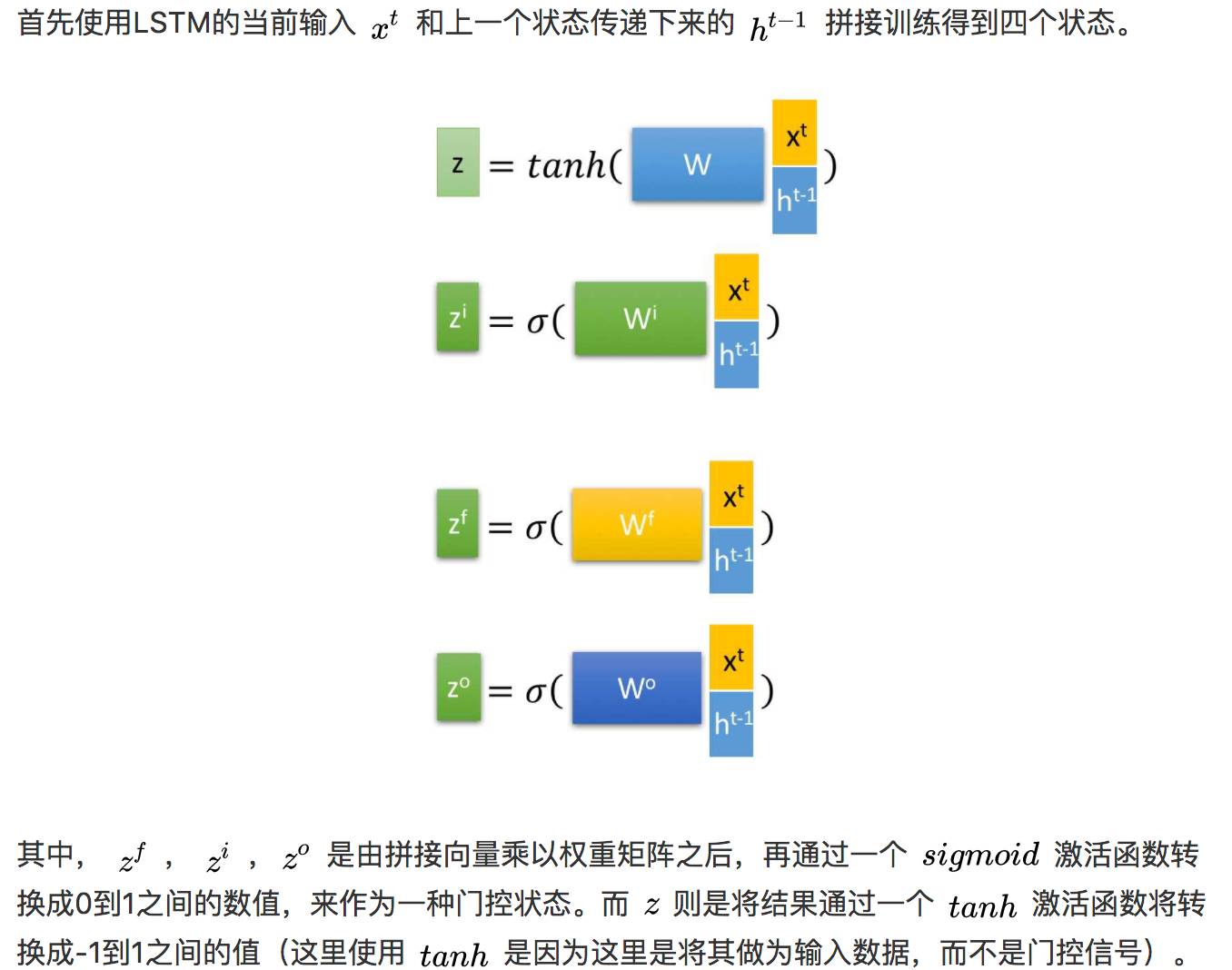
Now, let’s begin to introduce how these four states are used internally in LSTM. (Take note)
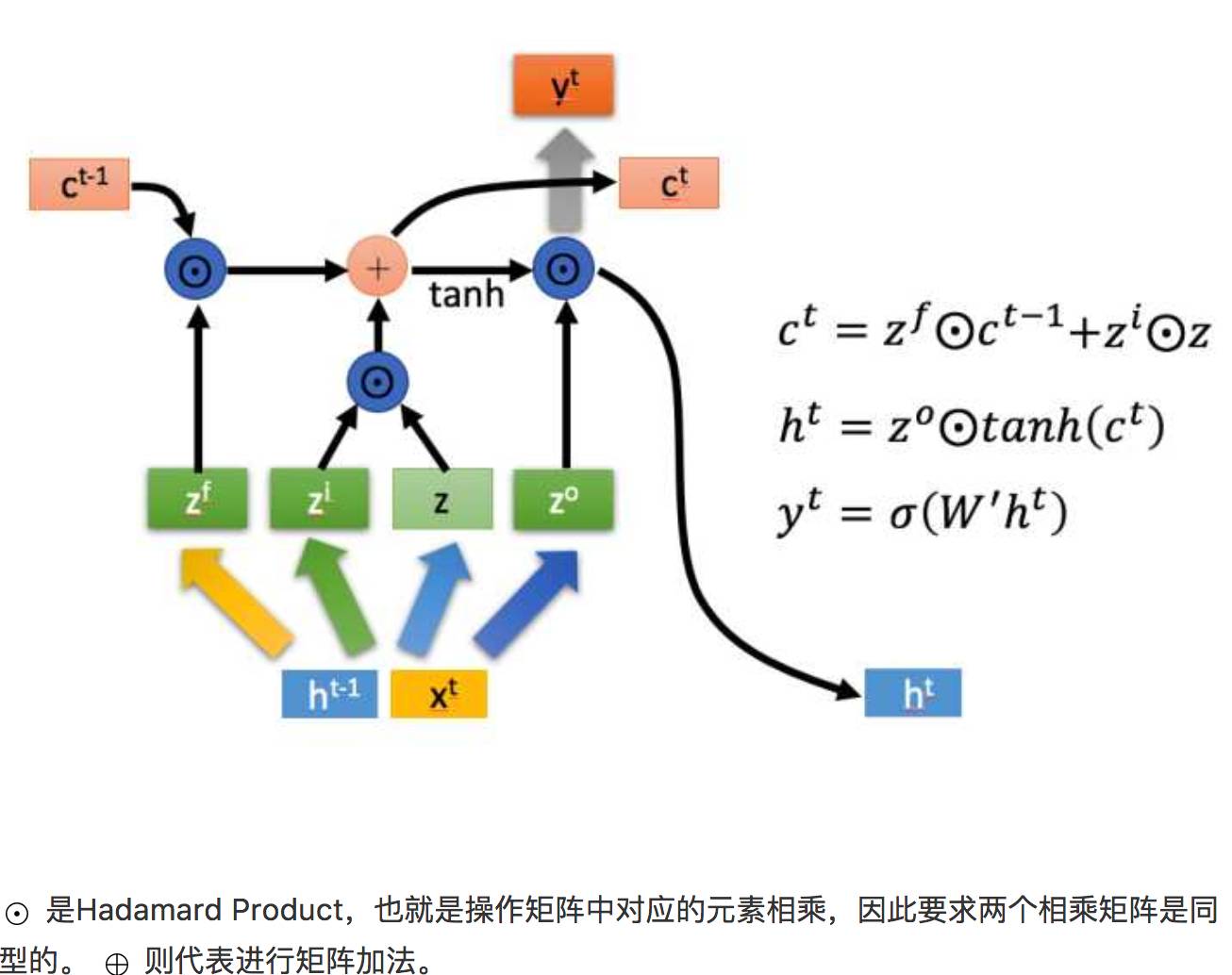
The internal workings of LSTM mainly involve three stages:

In summary, this is the internal structure of LSTM. It controls the transmission states through gated states, remembering what needs to be remembered for a long time and forgetting unimportant information; unlike ordinary RNNs that can only have one naive way of memory accumulation. This is particularly useful for many tasks that require “long-term memory”.
However, the introduction of many components leads to an increase in parameters, making training significantly more difficult. Therefore, many times we often use GRU, which has a performance comparable to LSTM but fewer parameters, to build models for large training volumes.
I will introduce GRU in future articles.
Guide for Ordinary Programmers Transitioning to Deep Learning Recommended
Recommended Reading:
Selected Insights | Summary of Insights from the Last Six Months
Insights | Mastering the Mathematical Foundations of Machine Learning Optimization [1] (Key Knowledge)
[Intuitive Explanation] What are PCA and SVD
Welcome to Follow Our Public Account for Learning and Communication~

Welcome to Join Our Group for Communication and Learning~