

From | Zhihu
Address | https://www.zhihu.com/question/278825804/answer/402634502
Author | Tian Yu Su
Editor | Machine Learning Algorithms and Natural Language Processing Public Account
This article is for academic sharing only. If there is an infringement, please contact the background for deletion.
I have done some similar work, so I will share my personal understanding.
The key to LSTM’s effectiveness in handling sequence problems is the Gate.
Take a simple sentiment classification problem as an example:
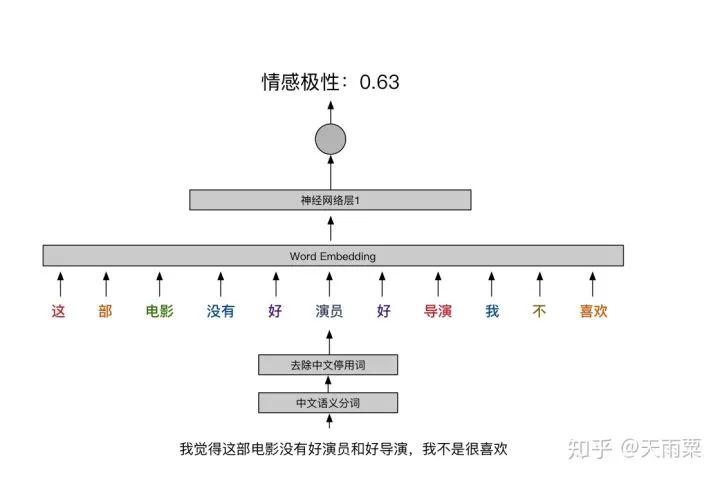
For example, in this sentence, we remove stop words, and finally perform Word Embedding to feed into DNN. There are 2 positive words “good” and 1 “like”, and 1 negative word “not” and 1 “no”. Due to more positive words, DNN tends to judge positive sentiment; in fact, this sentence expresses a negative sentiment. The two “good” are negated by “not”, and “like” is also negated by “no”, but DNN does not have the capability for sequential learning between hidden nodes, so it cannot capture this information;
However, if we use an LSTM:
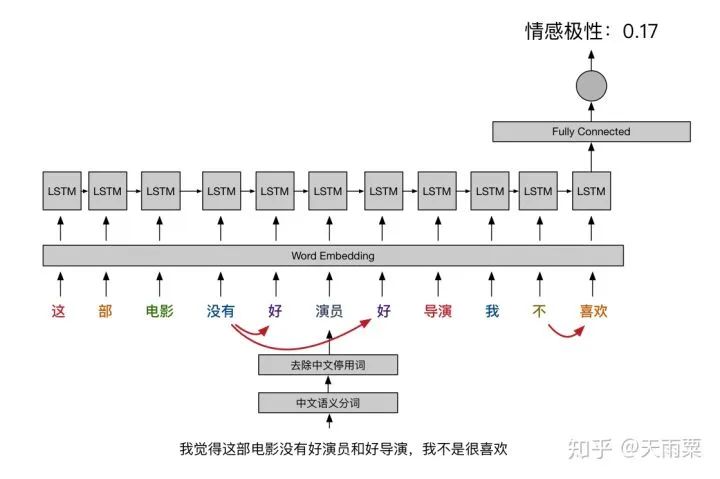
Because LSTM has the transmission of cell state, as shown in the arrows linked in the LSTM, it can capture this negation relationship, thereby outputting the correct sentiment coefficient.
From the formula of LSTM (not considering peephole), the forget gate is a unit activated by the sigmoid function, with values between 0 and 1.

Our cell state update formula is:

When the forget gate is closer to 0, it means loss of historical information (at time t-1); when the forget gate is closer to 1, it means more retention of historical information.
As the questioner said, most positions in the forget gate are 0, with few being 1. This part of 1 is the information it wants to retain in the network. I also agree with the questioner that this gate is somewhat similar to attention; for the information I need, I give high attention (corresponding to 1), for useless information, I choose not to pay attention (corresponding to 0). Similarly, if the information is more important at a certain moment, its corresponding forget gate position will remain close to 1, allowing this moment’s information to be passed down without being lost. This is one of the reasons why LSTM can handle long sequences.
Next, let’s talk about Bi-RNN. I think Bi-RNN is intuitively easier to understand. For example, when we read a sentence: “Although this person is very hardworking, he really has no achievements.” If we look at it from the LSTM perspective, it learns from front to back. By reading the first half of the sentence, we can extract the information that this person is hardworking, which seems to be a positive message, but only by reading down can we know that the focus of this sentence is that he has no achievements. Bi-RNN simulates human behavior well, that is, reading the complete sentence first. Bi-RNN transmits information in reverse order, so when Bi-RNN finishes reading “Although this person is very hardworking”, its reverse sequence has already captured the content information of the second half, thus making a more accurate judgment.
Supplement:
In response to the question from the comments section @Herry, let’s talk about GRU. Simply put, GRU has a simpler structure than LSTM, with only 2 gates, while LSTM has 3 gates, requiring fewer training parameters and is generally faster in implementation; additionally, GRU has only one state, treating LSTM’s cell state and activation state as one state.
From the formula, GRU has two gates, one is the reset gate and the other is the update gate.
The reset gate resets the state at time t-1, and it is also an output activated by the sigmoid function.

Then this reset gate is used to calculate  :
:

From the formula, we can see that the candidate state at the current moment  does not completely use
does not completely use  to learn, but first resets it. In LSTM, when calculating
to learn, but first resets it. In LSTM, when calculating  , it directly uses
, it directly uses  .
.
Another point is that GRU uses the update gate as both update and forget.

Where  corresponds to the forget gate in LSTM.
corresponds to the forget gate in LSTM.
In contrast, the forget gate in LSTM is separate and not closely related to the update gate. Here we can only say that GRU has made a reasonable simplification, reducing some computational load without sacrificing too much performance.
Furthermore, as mentioned above, GRU only needs to control one state, where its cell state equals the activation state, while LSTM controls two states, where the cell state must pass through the output gate to obtain the activation state.
Finally, regarding their specific performance comparison, in the models I have built, there is basically no significant difference; both perform well. However, I generally prefer LSTM, perhaps due to my initial exposure to LSTM. GRU is relatively faster and has a simpler structure, suitable for quickly developing model prototypes.
For a comparison of their performance, you can refer to the paper [1412.3555] Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling.
Important! The Yizhen Natural Language Processing – Academic WeChat Group has been established.
You can scan the QR code below, and the assistant will invite you to join the group for discussion.
Please modify the note to [School/Company + Name + Direction] when adding.
For example — Harbin Institute of Technology + Zhang San + Dialogue System.
The account holder requests that WeChat business please avoid. Thank you!

Recommended Reading:
PyTorch Cookbook (Collection of Common Code Snippets)
Easy to Understand! Implementing Transformer with Excel and TF!
Multi-task Learning in Deep Learning (Keras Implementation)