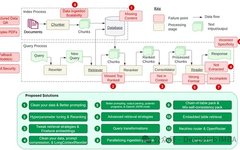
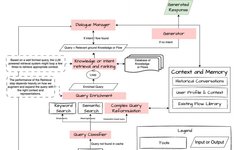
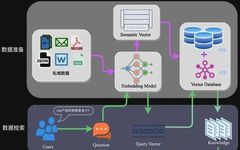
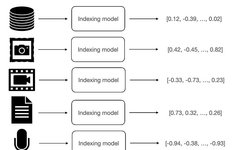
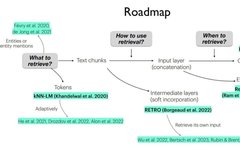
Design Patterns for Compound AI Systems (Conversational AI, CoPilots & RAG)

Author: Raunak Jain March 18, 2024 Translator: Chen Zhiyan Proofreader: zrx This article is approximately 3700 words long and is suggested to be read in 9 minutes. How to build a process-configurable compound AI system using open-source tools. Original Title: Design Patterns for Compound AI Systems (Conversational AI, CoPilots & RAG) Original Link: https://medium.com/@raunak-jain/design-patterns-for-compound-ai-systems-copilot-rag-fa911c7a62e0 What … Read more