
Introduction:
The author provides the most important design guidelines for RAG system design at various stages. This analysis covers five stages: indexing, storage, retrieval, synthesis, and evaluation, detailing the important design rules for each stage of the RAG system. The author combines practical experience in building RAG systems with significant design choices for specific modules.©️【Deep Blue AI】

Building a Retrieval-Augmented Generation (RAG) system is quite simple. Using tools like LamaIndex or LangChain, one can establish and run a large language model based on RAG in a short time. However, to ensure the system’s efficiency and good scalability, some engineering design work is needed. In principle, constructing a RAG is the easiest part; the more challenging task is how to design it well.
The author recently went through this process and found that building a retrieval-augmented generation system requires making many big and small design choices. Each of these choices can potentially affect the performance, behavior, and cost of the “RAG-based LLM,” sometimes in non-obvious ways. Next, the author will introduce this RAG design choice checklist, hoping it will be helpful to everyone.

Retrieval-Augmented Generation (RAG) allows chatbots to access external data, enabling them to answer user queries based on this data rather than general knowledge or their own hallucinations. For this reason, RAG systems can become complex: we need to acquire data, parse it into a chatbot-friendly format, make it accessible for LLM use and search, and ultimately ensure that the chatbot correctly utilizes the obtained data. The author will analyze the components of RAG systems, which mainly include five parts:
●Indexing: Embedding external data into vector representations. ●Storage: Persistently storing the indexed embeddings in a database. ●Retrieval: Finding relevant fragments in the stored data. ●Synthesis: Generating answers to user queries. ●Evaluation: Quantifying the performance of the RAG system.
The author will introduce each of these five parts in the following sections, discussing design choices, their impacts and trade-offs, as well as some quality resources to assist in decision-making.

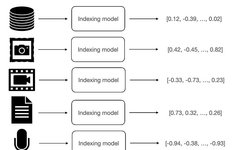
In a RAG system, indexing is the first step in providing external data to the LLM. It refers to acquiring data from various sources (SQL databases, Excel files, PDF files, images, video files, audio files, etc.) and converting it into vector representations.
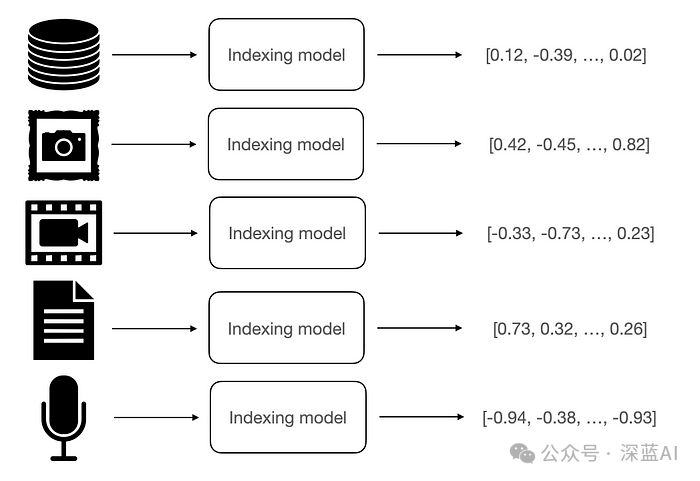
Essentially, the indexing step involves setting up, deploying, and maintaining a workflow that handles different types of input data and outputs numerical vectors representing the corresponding inputs. The author’s idea is that similar inputs will produce similar vector representations, while dissimilar inputs will be far apart in the embedding space. This is key to achieving retrieval, where the system looks for content related (similar) to the user query.
In this article, for simplicity, the author will stick to using text data for RAG, which is the most common use case. However, remember that using other formats is also possible. When designing the indexing step, several design choices need to be made:
●Data processing mode
●Indexing model
●Text segmentation method
●Chunk hyperparameters
■3.1 Data Processing Mode
We can index new data either in batch mode or stream mode. Batch mode refers to collecting all new data within a predefined time unit (hour, day, week, etc.) and passing it to the indexing model. Stream mode, on the other hand, operates continuously and indexes new data as it becomes available. This choice determines the speed at which the RAG system acquires new data. Batch mode is generally cheaper and easier to maintain, but in cases where the chatbot must obtain the latest information, streaming may be the only viable option.
For example, if the user wants to create a legal assistant to answer questions about new laws, and the government only publishes new laws in announcements weekly, a weekly scheduled batch would be very suitable for the user. On the other hand, if the user needs the chatbot to understand sports knowledge, including real-time results and statistics, streaming real-time data may be necessary.
■3.2 Indexing Model
Once we decide how to pass new data to the indexing model, we need to select a specific indexing model. Note that it does not have to be the same as the model we later use to generate responses; the indexing model is solely responsible for embedding text into vectors. We will use it to process external data and user queries, mapping them into the same vector space for similarity search.
The indexing model we choose will affect the quality of the embedded vectors we store, which in turn impacts the relevance of the context retrieved during synthesis. Typical considerations include: proprietary indexing models or large indexing models tend to be better but may be slower to access or run, and more costly. It is important to note that the best embedder is different from the best generator!
Particularly noteworthy is the “speed” factor, as indexing occurs not only when we embed new external data but also during the synthesis time when the model generates replies (the user query must be indexed before searching for matching relevant data). Therefore, a slower indexing model means the chatbot will take longer to generate answers, negatively impacting user experience.
When selecting an indexing model, another important aspect to consider is that changing the indexing model requires us to re-index all data, which can be costly for large datasets. Therefore, it is best to take some time to consider this design choice and select a model that is effective not only now but also in the future (considering the amount of predictive data to be embedded, requirements for indexing and synthesis latency, cost variations as data and/or query counts increase, etc.).
■3.3 Text Segmentation Method
Before indexing input text, we need to segment it into several parts and index each part separately. We can choose various ways to segment text: by sentence, by token, by paragraph, or even by semantics (each chunk is a set of semantically related sentences) or hierarchically (forming a hierarchy of sub-chunks and parent chunks).
This design choice determines which text segments will be retrieved during synthesis. If we choose paragraph-based segmentation, we ensure that when generating answers, our LLM can access complete text paragraphs. On the other hand, chunking by tokens may lead to sequences of words that do not even form complete sentences.
Additionally, this choice should be based on the specific context of our application. For example, for a Q&A system that requires precise, detailed answers, indexing by sentence or semantically related chunks may be most effective. This way, the model can retrieve and synthesize information from specific, closely related text segments, yielding more accurate and contextually relevant answers.
For applications that require a broader understanding or generation of text, such as summarization or topic exploration, paragraph-based or hierarchical indexing may be more desirable. These methods ensure that the model can access and integrate a wider range of information, providing a more comprehensive view of the topic.
■3.4 Chunk Hyperparameters
Finally, the text segmentation or chunking process requires setting several hyperparameters, such as chunk size (measured in token count) and chunk overlap (whether subsequent chunks overlap and by how much).
This choice will affect the precision of the generated embeddings; smaller information chunks will lead to very specific and refined embeddings. This can ensure that the retrieved information is accurate, but we risk missing the most useful information in the first retrieved chunks. On the other hand, larger information chunks should provide all necessary information, but they may miss fine-grained details. Another consideration is synthesis time. If the chunks are large, the LLM will require more time to retrieve context and respond to the user.

After passing input data to the indexing model to create embeddings, the system needs to persist them for retrieval by the LLM when needed. When designing the storage step of the RAG system process, there are two most important decisions:
●Database selection ●Metadata selection
■4.1 Database Selection
Although embedded data can be dumped into a conventional SQL database, this is a suboptimal choice; RAG systems typically use so-called vector databases or vector storage. Vector storage is a specific type of database optimized for storing vector representations and performing fast, efficient searches—precisely what RAG systems need. With the emergence of LLM systems, countless new vector database solutions have sprung up. Two main aspects to consider when selecting a database are cost and available features.

Depending on the budget, one can choose free open-source vector storage or hosted software-as-a-service products. The latter typically comes in two forms: one where everything runs on their cloud, providing services on a pay-as-you-go basis; the other where solutions are deployed on one’s own cloud, paying based on the resources used.
Some vector storage providers also offer a system where they host the database but allow users to pay only for the parts they use, such as storage and read/write units. Besides pricing, another important aspect of vector storage is the features it offers. Below is a list of features that users may want vector storage to provide:
●Integration with development frameworks like LlamaIndex or LangChain.
●Multi-modal search support—limited to cases that handle multiple modalities (e.g., images and text).
●Advanced search support, such as hybrid search techniques—detailed later.
●Embedding compression capabilities—some vector storage offers built-in compression features to reduce storage space usage, which is particularly useful when handling large data volumes.
●Auto-scaling—some vector storages can adapt to traffic demands, ensuring continuous availability.
When selecting vector storage, it is important to understand your budget and carefully consider which features you truly need. You will find that to stand out among numerous vector storages, some will offer very advanced features, but most of them may not be necessary for your use case.
■4.2 Metadata Selection
In addition to the indexed data itself, the designed RAG system stores some metadata in the vector storage, which helps find relevant input data during retrieval. For example, if the designed RAG system is a sports news chatbot, the designer may want to tag all input data with the corresponding subject (e.g., “football” or “volleyball”). During retrieval, if the user inquires about a football match, the system can eliminate all data without a “football” tag from the search, making the search faster and more accurate.
In many applications, the system already possesses a wealth of metadata: sources of the input text, topics, creation dates, etc. Storing this metadata in vector storage is very useful. Furthermore, frameworks like LlamaIndex also offer automatic metadata extraction capabilities, which use LLM to automatically create some metadata from input data, such as questions that the given text can answer or entities mentioned (e.g., place names, personal names, object names).
However, storing metadata is not free. Therefore, the author’s suggestion is to sketch out an ideal working RAG system and make assumptions: what kinds of questions will users ask, and what metadata can help find relevant data to answer these questions? Then, only store the essential metadata; storing all the metadata you can think of may lead to increased costs.

Retrieval refers to finding relevant fragments in the stored data based on user queries. In its simplest form, this involves embedding the query with the same model used for indexing and comparing the embedded query with the indexed data. When designing the retrieval step, several factors need to be considered:
●Retrieval strategy
●Retrieval hyperparameters
●Query transformation
■5.1 Retrieval Strategy
The simplest method for retrieving context from stored data is to select the embeddings most similar to the user query based on similarity measures like cosine similarity. This method is called semantic retrieval, as the system aims to find text that is semantically similar to the query. However, using this basic semantic retrieval method, the retrieved text may not contain the most important keywords from the query. A solution to this problem is the so-called hybrid retrieval, which combines the results of semantic retrieval and literal keyword retrieval.
Typically, the system will find multiple embeddings similar to the user query. Therefore, it is very useful to rank them correctly, meaning the higher the computed similarity to the user query, the higher the relevance of the text block. Ranking algorithms can solve this problem; one of the most commonly used algorithms in RAGs is BM25, or Best Matching 25. This is a term-based ranking algorithm that scores based on the length of text blocks and the frequency of different terms within them. Reciprocal Ranking Fusion or RRF is a slightly more complex method. It evaluates the search scores of the ranked results to generate an outcome. You will find that all these methods have already been implemented in frameworks like LlamaIndex.
Choosing the correct retrieval strategy should primarily consider the performance of the RAG (to be detailed later in RAG evaluation) and costs. It is advisable to consider this early in the indexing phase, as the choice of vector storage may limit the available retrieval strategies.
Chunk window retrieval is an interesting variation on traditional retrieval strategies. In this approach, the system uses any of the methods discussed above to identify the most relevant chunks; however, instead of passing only these retrieved chunks as context to the model, it also passes the preceding and succeeding chunks for each chunk. This provides the LLM with a larger context.
Increasing the window size (e.g., passing two preceding and two succeeding chunks, or three) is expected to yield more relevant context, but it also means using more tokens, thus increasing costs. Moreover, the benefits of increasing the window size often diminish, so the author’s suggestion is not to set the window too large.
■5.2 Retrieval Hyperparameters
Regardless of the final retrieval strategy chosen, there will be some hyperparameters that need to be tuned. Most strategies will involve at least the following two parameters:
●Top-k
●Similarity cutoff
Top-k will affect the number of text blocks provided to the model during synthesis. The larger the Top-k, the larger and more relevant the context, but at the cost of increasing the number of text blocks and costs. However, if Top-k is set too high, the system may pass text blocks with lower relevance to the model.
The similarity cutoff also plays a similar role. It limits the text blocks that the system passes to the LLM to those that are at least similar to the user query. If set too high, the retrieved text blocks may be few or even none. Setting it too low may result in a large number of irrelevant texts being passed to the model.
Retrieval hyperparameters should be treated like all hyperparameters in machine learning processes: they should be tuned based on the performance of the model. One important point to remember is to adjust both parameters simultaneously. The interaction between Top-k and similarity cutoff requires the system to jointly evaluate different combinations of these two parameters.
■5.3 Query Transformation
◆Subquery generation: Breaking the user’s query into several parts or generating new, more detailed queries based on the original query and passing them as separate, bullet-pointed subqueries to the model. This method can enhance the performance of RAG for short or vague queries.
◆Hypothetical Document Embedding (HyDE): This is a clever technique where the system has an ordinary LLM generate an answer to the user’s query (which may be a hallucination or other inaccuracies), and then performs retrieval on the combination of the query and the answer. This method assumes that even a poorly generated answer will be similar in some respects to the good answers the system is looking for, thus incorporating it into the search can enhance the relevance of the retrieval context.
Query transformation techniques can significantly improve RAG performance; however, it should be noted that the potential downside of adopting these techniques is slower retrieval speed (due to the increased number of query versions or the involvement of additional subqueries or answers in the search). Additionally, caution should be exercised when using techniques like HyDE, as they may lean towards open-ended queries and misinterpret the query without context (for examples of these situations, see LlamaIndex documentation).

Synthesis (also known as generation) is a step in RAG where the LLM synthesizes a response to the user query. The three most important considerations for this step are:
●Synthesis model
●System prompt
●Synthesis hyperparameters
■6.1 Synthesis Model
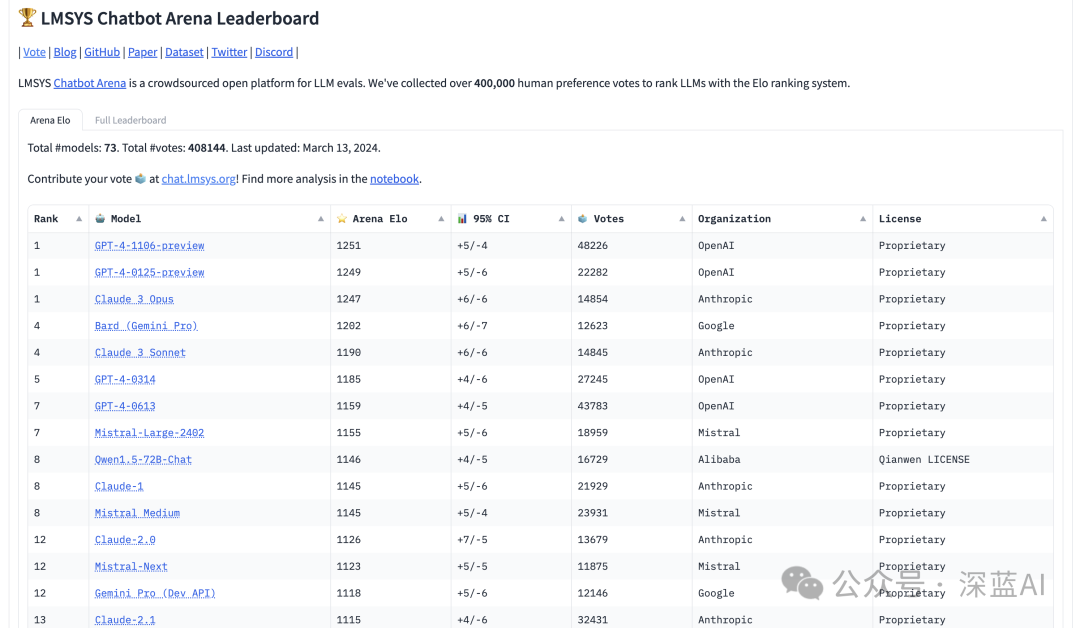
Selecting the model for generating replies is crucial, as it affects the coherence, grammatical correctness, usefulness, fairness, and safety of the replies. If a proprietary model is chosen, it may also significantly impact the cost of the solution. Unless constrained by budget or inference time requirements, one would typically want to use the best large language model available. But how to find it? A simple approach is to look at benchmarks.
In the chatbot arena, people ask two anonymous models (like ChatGPT, Claude, Llama) questions and vote for the better one without knowing which models are competing. The winner gains points, while the loser loses points (to be precise, they calculate ELO scores). This creates a leaderboard that shows which LLMs the community currently considers the best.
If your RAG application is highly domain-specific, such as analyzing legal texts, you may want the synthesis model to excel in logical reasoning, even if it performs poorly in other areas. In such cases, check common LLM evaluation benchmarks and choose a model optimized for the specific benchmarks that interest you.
■6.2 System Prompt
The system prompt is the contextual and inquiry pre-information sent to the LLM. It “pre-sets” how the chatbot behaves.

The exact wording of the system prompt is very important for RAG performance. Unfortunately, finding the correct wording is more of an art than a science, requiring constant experimentation to find the best phrasing for the application. One thing that should definitely be included in the system prompt is to behave like a good RAG, such as: “Based on the following contextual information, please answer the following question: “Based on the context below, answer the query. Only use information from the context. Do not use any common sense.” You might also consider using the system prompt to provide a template for answers, instructing the LLM to answer in the style of a famous person, as concisely as possible, or conversely, to provide lengthy and detailed answers. Just ensure it fits the user’s use case. LlamaIndex documentation details various RAG prompt engineering methods.
■6.3 Synthesis Hyperparameters
Another step in the RAG system process means another set of hyperparameters to guess and tune. Overall, the two main hyperparameters that designers should focus on are context window size and maximum response size. These influence how much context the model can see and how long of a response is allowed to be generated.
The discussion of context window size is somewhat similar to what we discussed regarding retrieval hyperparameters (top-k and similarity cutoff). A longer context window means the model can leverage more information, but it also risks including irrelevant information.
The maximum response size should generally be determined based on the application use case. For me, a simple adjustment strategy is to choose an initial value that you think is large enough for the response to be comprehensive but small enough to avoid generating lengthy narratives. Then, during evaluation (see below), if you observe that responses often only partially answer the query while hitting the maximum size limit, increase that limit.
Another important consideration is cost. If a proprietary LLM is used during synthesis, costs may be incurred based on the context length and the length of the generated output. Therefore, reducing these two hyperparameters can lower costs.


▲Figure 6|Comparison of Chatbot Evaluations ©️【Deep Blue AI】
RAG systems are fundamentally designed around large language models, and evaluating LLMs is inherently a complex topic, further complicated by contextual retrieval. The most important aspects of the evaluation step include:
●Evaluation protocols
●Evaluator prompts
●Model guidelines
■7.1 Evaluation Protocols
Evaluation protocols are detailed instructions on how to conduct system evaluations. They answer the following questions:
●What data to test?
●What metrics to focus on?
●What are the optimization metrics and satisfaction metrics?
Obtaining a good test set for RAG is immensely beneficial for designing high-quality systems. Unlike traditional machine learning systems, RAG evaluation often does not require ground truth; in this case, the ground truth is the “gold standard” reference answer. Collecting user queries, retrieval contexts, and generated answers is sufficient. Ideally, all of these should come from the target users of the RAG system. For example, users could be allowed to use an early version of the system while generating a test dataset for evaluation.
If this is not possible or if we want to evaluate it before releasing it to anyone, we can use one of the Llama datasets for this purpose. However, this evaluation will not represent the production environment in which the RAG will operate.
Next, we need to collect performance metrics to track and optimize. There are many metrics to choose from, including:
●Accuracy and truthfulness of answers; ●RAG triplet: foundational, answer relevance, and context relevance; ●Coherence and grammatical correctness of generated text; ●Degree of bias, harmful content, or impoliteness in answers; ●User satisfaction, which can be obtained through some survey.
Once the metrics are selected, we need to choose one as the optimization metric, which is the metric we want to optimize as much as possible, provided that other (satisfaction) metrics meet pre-set thresholds. Depending on the use case, designers may choose different metrics as optimization metrics. The author’s suggestion is to typically use the average (possibly weighted average) of the RAG triplet metrics.
■7.2 Evaluator Prompts
With the evaluation protocol in place, we can start calculating various metrics. The interesting part begins with LLM-based metrics (metrics generated by large language models that require prompts to generate). Consider the fidelity score, which captures whether the generated answer is supported by the retrieval context. To obtain this score, we prompt our RAG with a test set example and collect the generated answer and the retrieved context. We then pass both to another LLM for fidelity evaluation.
However, the exact wording of the evaluator prompts can greatly impact their behavior. While the default prompts in popular frameworks like LlamaIndex or LangChain work well (after all, a lot of work has gone into fine-tuning each little word), tweaking these prompts may benefit the designer’s use case.
■7.3 Model Guidelines
Model guidelines are a set of rules defined by the designer that the RAG system should follow. In general, designers may want to replace or extend them with something more suitable for their use case. For example, designers may want to emphasize clarity and conciseness, especially when the application focuses on delivering information quickly and clearly. In this case, they could add: “Responses should be concise, avoiding unnecessary words or complex sentences to prevent confusing users.”
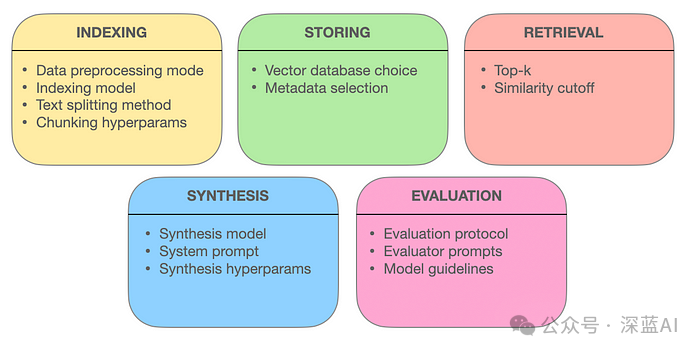
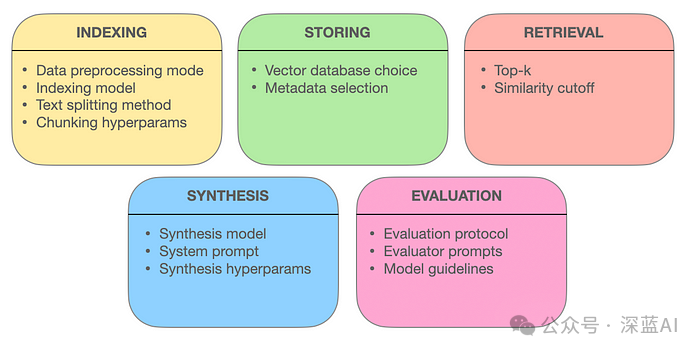
Designing a retrieval-augmented generation system requires making many big and small decisions, which can significantly impact the performance of RAG. Based on the author’s experience in building RAG, the most important decisions have been covered for the readers’ reference.
Citations:
[1]https://blog.tobiaszwingmann.com/p/deep-dive-rag-for-ai-applications
[2]https://medium.com/@pareto_investor/chatgpt-has-gone-bad-5272ff33c5cd
[3]https://twitter.com/WizardLM_AI/status/1709937556828430356
[4]https://www.rag.de/

TimesFM Base Model Shines, Leading Time Series Predictions into a New Era
2024-03-24

The Future of Autonomous Driving: The Expansion of Trajectory Models for Predictive Planning Revolution
2024-03-21

*Click to view, bookmark, and recommend this article*