
Source: DeepHub IMBA
This article is approximately 5400 words long and is recommended for a reading time of over 10 minutes.
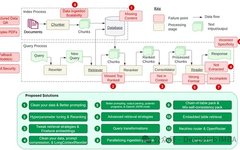
This article discusses 12 pain points encountered during the development of RAG pipelines (7 of which are sourced from papers, and 5 from our own summary), and proposes corresponding solutions to these pain points.
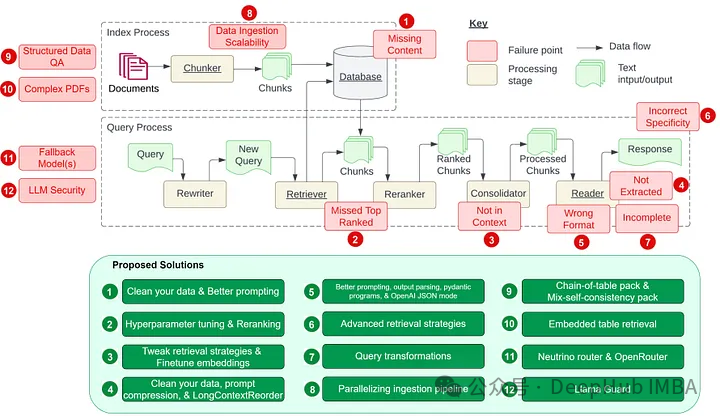
The paper by Barnett et al. titled “Seven Failure Points When Engineering a Retrieval Augmented Generation System” introduces seven pain points of RAG. We will extend this by adding five additional common problems often encountered in the RAG development process, and we will delve into the solutions for these RAG pain points so that we can better avoid and resolve them in our daily RAG development.
We use the term “pain points” instead of “failure points” mainly because we provide corresponding suggested solutions for the problems we summarize.
First, let us introduce the seven pain points mentioned in the paper above; please see the chart below. Then, we will add five additional pain points and their suggested solutions.
Here are the 7 pain points summarized in the paper:
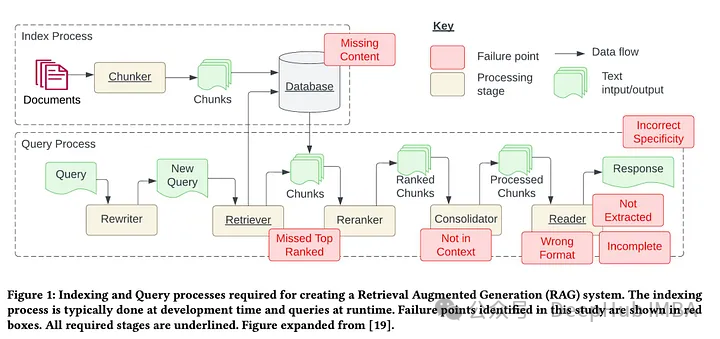
Missing Content
When the actual answer is not in the knowledge base, the RAG system provides an answer that seems reasonable but is incorrect, leading to misleading information for the user.
Solution:
In cases where the knowledge base lacks information and the system may provide a seemingly reasonable but incorrect answer, better prompts can be very helpful. For example, a prompt statement like “If you are unsure about the answer, tell me you don’t know” can encourage the model to acknowledge its limitations and convey uncertainty more transparently.
If the model must output the correct answer instead of admitting it does not know, then additional data sources need to be incorporated, and the quality of the data must be ensured. If the source data is of poor quality, such as containing conflicting information, then no matter how well the RAG pipeline is constructed, it cannot output gold from the garbage provided to it. This suggested solution applies not only to this pain point but to all pain points listed in this article. Clean data is a prerequisite for any well-functioning RAG pipeline.
Missing Key Documents
Key documents may not appear among the top results returned by the system’s retrieval component. If the correct answer is overlooked, it can lead to the system failing to provide an accurate response. The paper mentions: “The answer to the question is in the document, but it is not ranked high enough to be returned to the user.”
Here are 2 solutions:
1. Hyperparameter Tuning of chunk_size and similarity_top_k
Both chunk_size and similarity_top_k are parameters used to manage the efficiency and effectiveness of the data retrieval process in RAG models. Adjusting these parameters affects the trade-off between computational efficiency and the quality of retrieved information.
param_tuner = ParamTuner(
param_fn=objective_function_semantic_similarity,
param_dict=param_dict,
fixed_param_dict=fixed_param_dict,
show_progress=True,
)
results = param_tuner.tune()
The function objective_function_semantic_similarity is defined as follows, where param_dict contains the parameters chunk_size and top_k, along with their suggested values:
# contains the parameters that need to be tuned
param_dict = {"chunk_size": [256, 512, 1024], "top_k": [1, 2, 5]}
# contains parameters remaining fixed across all runs of the tuning process
fixed_param_dict = {
"docs": documents,
"eval_qs": eval_qs,
"ref_response_strs": ref_response_strs,
}
def objective_function_semantic_similarity(params_dict):
chunk_size = params_dict["chunk_size"]
docs = params_dict["docs"]
top_k = params_dict["top_k"]
eval_qs = params_dict["eval_qs"]
ref_response_strs = params_dict["ref_response_strs"]
# build index
index = _build_index(chunk_size, docs)
# query engine
query_engine = index.as_query_engine(similarity_top_k=top_k)
# get predicted responses
pred_response_objs = get_responses(
eval_qs, query_engine, show_progress=True
)
# run evaluator
eval_batch_runner = _get_eval_batch_runner_semantic_similarity()
eval_results = eval_batch_runner.evaluate_responses(
eval_qs, responses=pred_response_objs, reference=ref_response_strs
)
# get semantic similarity metric
mean_score = np.array(
[r.score for r in eval_results["semantic_similarity"]]
).mean()
return RunResult(score=mean_score, params=params_dict)
2. Reranking
Reordering the retrieval results before sending them to the LLM can significantly improve the performance of RAG.
Below is a comparison of retrieving the top 2 nodes directly without a reranker, resulting in inaccurate retrieval; and retrieving the top 10 nodes and using CohereRerank to reorder and return the top 2 nodes for accurate retrieval.
import os
from llama_index.postprocessor.cohere_rerank import CohereRerank
api_key = os.environ["COHERE_API_KEY"]
cohere_rerank = CohereRerank(api_key=api_key, top_n=2) # return top 2 nodes from reranker
query_engine = index.as_query_engine(
similarity_top_k=10, # we can set a high top_k here to ensure maximum relevant retrieval
node_postprocessors=[cohere_rerank], # pass the reranker to node_postprocessors
)
response = query_engine.query(
"What did Sam Altman do in this essay?",
)
Various embeddings and reordering can also be used to assess the performance of enhanced RAG, such as boost RAG. Alternatively, fine-tuning a custom reranker can achieve better retrieval performance.
Limitations of Integration Strategies Leading to Context Conflicts
Documents containing answers are retrieved from the database but do not enter the context for generating answers. This occurs when many documents are returned from the database, and an integration process is performed to retrieve the answer.
In addition to the reranking mentioned in the previous section and fine-tuning reranking, we can also try the following solutions:
1. Adjusting Retrieval Strategies
LlamaIndex offers a range of retrieval strategies from basic to advanced:
-
Basic retrieval from each index -
Advanced retrieval and search -
Auto-Retrieval -
Knowledge Graph Retrievers -
Composed/Hierarchical Retrievers
By selecting and trying different retrieval strategies, customization can be tailored to different needs.
2. Threshold Embedding
If using open-source embedding models, tuning the embedding model is also a good way to achieve more accurate retrieval. LlamaIndex provides a step-by-step guide on tuning open-source embedding models, demonstrating that tuning embedding models can consistently improve metrics across the entire eval metric suite.
Below is an example code snippet that includes creating a fine-tuning engine, running fine-tuning, and obtaining the fine-tuned model:
finetune_engine = SentenceTransformersFinetuneEngine(
train_dataset,
model_id="BAAI/bge-small-en",
model_output_path="test_model",
val_dataset=val_dataset,
)
finetune_engine.finetune()
embed_model = finetune_engine.get_finetuned_model()
Not Obtaining Correct Content
The system extracts the correct answer from the provided context, but in cases of information overload, it may miss key details, affecting the quality of the response. The paper states: “This occurs when there is too much noise or conflicting information in the environment.”
Let’s see how to resolve this.
1. Prompt Compression
The LongLLMLingua research project/paper introduces prompt compression in long context environments. By integrating LongLLMLingua into LlamaIndex, it can be implemented as a post-processor, which will compress context after the retrieval step and then input it into the LLM.
The following example code sets up LongLLMLinguaPostprocessor, which uses the longllmlingua package to run prompt compression.
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.response_synthesizers import CompactAndRefine
from llama_index.postprocessor import LongLLMLinguaPostprocessor
from llama_index.schema import QueryBundle
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder
},
)
retrieved_nodes = retriever.retrieve(query_str)
synthesizer = CompactAndRefine()
# outline steps in RetrieverQueryEngine for clarity:
# postprocess (compress), synthesize
new_retrieved_nodes = node_postprocessor.postprocess_nodes(
retrieved_nodes, query_bundle=QueryBundle(query_str=query_str)
)
print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))
response = synthesizer.synthesize(query_str, new_retrieved_nodes)
2. LongContextReorder
Optimal performance often occurs when key data is at the beginning or end of the input context. LongContextReorder aims to solve this “middle loss” problem by reordering retrieved nodes, which is particularly helpful when a larger top-k is needed.
See the example code snippet below, defining LongContextReorder as a node post-processor.
from llama_index.postprocessor import LongContextReorder
reorder = LongContextReorder()
reorder_engine = index.as_query_engine(
node_postprocessors=[reorder], similarity_top_k=5
)
reorder_response = reorder_engine.query("Did the author meet Sam Altman?")
Formatting Errors
Sometimes we request information to be extracted in a specific format (like a table or list), but such instructions may be ignored by the LLM. Therefore, we summarize 4 solutions:
1. Better Prompts
Clarifying instructions, simplifying requests, using keywords, providing examples, emphasizing, and asking follow-up questions.
2. Output Parsing
Providing format instructions for any prompts/queries and manually providing “parsing” for LLM outputs.
LlamaIndex supports integration with output parsing modules provided by other frameworks (like guarrails and LangChain).
Below is an example code snippet of the LangChain output parsing module that can be used in LlamaIndex. For more details, please refer to LlamaIndex’s documentation on output parsing modules.
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.output_parsers import LangchainOutputParser
from llama_index.llms import OpenAI
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# load documents, build index
documents = SimpleDirectoryReader("../paul_graham_essay/data").load_data()
index = VectorStoreIndex.from_documents(documents)
# define output schema
response_schemas = [
ResponseSchema(
name="Education",
description="Describes the author's educational experience/background.",
),
ResponseSchema(
name="Work",
description="Describes the author's work experience/background.",
),
]
# define output parser
lc_output_parser = StructuredOutputParser.from_response_schemas(
response_schemas
)
output_parser = LangchainOutputParser(lc_output_parser)
# Attach output parser to LLM
llm = OpenAI(output_parser=output_parser)
# obtain a structured response from llama_index
from llama_index import ServiceContext
ctx = ServiceContext.from_defaults(llm=llm)
query_engine = index.as_query_engine(service_context=ctx)
response = query_engine.query(
"What are a few things the author did growing up?",
)
print(str(response))
3. Pydantic
Pydantic programs serve as a general framework to convert input strings into structured Pydantic objects.
Pydantic can combine APIs and output parsing, processing input text and converting it into user-defined structured objects. Pydantic programs utilize LLM function calls to APIs, taking input text and converting it into user-defined structured objects or converting input text into predefined structured objects.
Below is an example code snippet of an OpenAI Pydantic program.
from pydantic import BaseModel
from typing import List
from llama_index.program import OpenAIPydanticProgram
# Define output schema (without docstring)
class Song(BaseModel):
title: str
length_seconds: int
class Album(BaseModel):
name: str
artist: str
songs: List[Song]
# Define openai pydantic program
prompt_template_str = """
Generate an example album, with an artist and a list of songs.
Using the movie {movie_name} as inspiration.
"""
program = OpenAIPydanticProgram.from_defaults(
output_cls=Album, prompt_template_str=prompt_template_str, verbose=True
)
# Run program to get structured output
output = program(
movie_name="The Shining", description="Data model for an album."
)
4. OpenAI JSON Mode
OpenAI JSON mode allows us to set the response_format to {“type”: “json_object”}. When JSON mode is enabled, the model is constrained to generate strings that parse as valid JSON objects, making subsequent processing very convenient.
Vague or General Answers
Answers obtained from LLMs may lack necessary details or specificity; overly vague or general answers cannot effectively meet user needs.
Therefore, some advanced retrieval strategies are needed to resolve this issue. When the answer does not reach the expected level of granularity, retrieval strategies can be improved. Some major advanced retrieval strategies may help address this pain point, including:
small-to-big retrieval
sentence window retrieval
recursive retrievalIncomplete Results
Some results are not incorrect; however, they do not provide all the details, even though this information is present and accessible in the context. For example, “What are the main aspects discussed in files A, B, and C?” If each file is queried separately, a more comprehensive answer can be obtained.
This comparative question performs particularly poorly in traditional RAG methods. A good way to enhance RAG reasoning capabilities is to add a query understanding layer—adding query transformation before the actual query vector storage. Below are four different query transformations:
Routing: Retain the original query while identifying the appropriate subset of tools it belongs to, specifying these tools as suitable for query work.
Query Rewriting: Rephrase the query in multiple ways to apply it within the same set of tools.
Subquestions: Break down the query into several smaller questions, each targeting different tools.
ReAct: Determine which tool to use based on the original query and formulate a specific query to run on that tool.
Below is an example code that uses HyDE (a query rewriting technique) to generate a hypothetical document/answer given a natural language query. It then uses this hypothetical document for embedding queries.
# load documents, build index
documents = SimpleDirectoryReader("../paul_graham_essay/data").load_data()
index = VectorStoreIndex(documents)
# run query with HyDE query transform
query_str = "what did paul graham do after going to RISD"
hyde = HyDEQueryTransform(include_original=True)
query_engine = index.as_query_engine()
query_engine = TransformQueryEngine(query_engine, query_transform=hyde)
response = query_engine.query(query_str)
print(response)
These pain points are all sourced from the paper mentioned earlier. Now let us introduce five additional common problems encountered in RAG development, along with their solutions.
Scalability
In RAG pipelines, the issue of data ingestion scalability refers to the challenges encountered when the system processes large volumes of data, which can lead to performance bottlenecks and potential system failures. This data ingestion scalability issue may result in extended ingestion times, system overload, data quality issues, and limited availability.
Therefore, parallel processing is needed. LlamaIndex provides parallel processing capabilities that can increase document processing speed by up to 15 times.
# load data
documents = SimpleDirectoryReader(input_dir="./data/source_files").load_data()
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=1024, chunk_overlap=20),
TitleExtractor(),
OpenAIEmbedding(),
]
)
# setting num_workers to a value greater than 1 invokes parallel execution.
nodes = pipeline.run(documents=documents, num_workers=4)
Structured Data Quality
Accurately interpreting user queries to retrieve relevant structured data is challenging, especially when faced with complex or vague queries and inflexible text-to-SQL conversions.
LlamaIndex provides two solutions.
ChainOfTablePack is based on the innovative paper “Chain-of-table,” combining the concept of chain of thought with the transformation and representation of tables. It uses a set of restricted operations to gradually transform tables and presents the modified tables to the LLM at each stage. The significant advantage of this approach is its ability to handle complex table cells involving multiple pieces of information systematically through slicing and chunking data.
Based on the paper “Rethinking Tabular Data Understanding with Large Language Models,” LlamaIndex has developed the MixSelfConsistencyQueryEngine, which aggregates results from text and symbolic reasoning through a self-consistency mechanism (i.e., majority voting) and achieves state-of-the-art performance. Below is an example code.
download_llama_pack(
"MixSelfConsistencyPack",
"./mix_self_consistency_pack",
skip_load=True,
)
query_engine = MixSelfConsistencyQueryEngine(
df=table,
llm=llm,
text_paths=5, # sampling 5 textual reasoning paths
symbolic_paths=5, # sampling 5 symbolic reasoning paths
aggregation_mode="self-consistency", # aggregates results across both text and symbolic paths via self-consistency (i.e. majority voting)
verbose=True,
)
response = await query_engine.aquery(example["utterance"])
Extracting data from complex PDF documents, such as extracting data from tables embedded in PDFs, is a very complex issue. Therefore, you can try using pdf2htmllex to convert the PDF to HTML without losing text or formatting. Below is an example of EmbeddedTablesUnstructuredRetrieverPack:
# download and install dependencies
EmbeddedTablesUnstructuredRetrieverPack = download_llama_pack(
"EmbeddedTablesUnstructuredRetrieverPack", "./embedded_tables_unstructured_pack",
)
# create the pack
embedded_tables_unstructured_pack = EmbeddedTablesUnstructuredRetrieverPack(
"data/apple-10Q-Q2-2023.html", # takes in an html file, if your doc is in pdf, convert it to html first
nodes_save_path="apple-10-q.pkl"
)
# run the pack
response = embedded_tables_unstructured_pack.run("What's the total operating expenses?").response
display(Markdown(f"{response}"))
Backup Models
When using language models (LLMs), if the model encounters issues, such as the OpenAI model being rate-limited, a backup model is needed as a fallback for the primary model.
Here are 2 solutions:
The Neutrino router is a collection of LLMs that can route queries to them. It uses a predictive model to intelligently route queries to the most suitable LLM for prompting, maximizing performance while optimizing cost and latency. The Neutrino router currently supports over a dozen models.
from llama_index.llms import Neutrino
from llama_index.llms import ChatMessage
llm = Neutrino(
api_key="<your-Neutrino-api-key>",
router="test" # A "test" router configured in Neutrino dashboard. You treat a router as a LLM. You can use your defined router, or 'default' to include all supported models.
)
response = llm.complete("What is large language model?")
print(f"Optimal model: {response.raw['model']}")
The OpenRouter is a unified API that provides access to any LLM. OpenRouter finds the lowest price for each model among dozens of model providers. There is no need to change the code when switching models or providers.
LlamaIndex integrates support for OpenRouter through its OpenRouter class in the llms module.
from llama_index.llms import OpenRouter
from llama_index.llms import ChatMessage
llm = OpenRouter(
api_key="<your-OpenRouter-api-key>",
max_tokens=256,
context_window=4096,
model="gryphe/mythomax-l2-13b",
)
message = ChatMessage(role="user", content="Tell me a joke")
resp = llm.chat([message])
print(resp)
LLM Security
How to combat prompt injection, handle unsafe outputs, and prevent the leakage of sensitive information are urgent questions that every AI architect and engineer needs to address.
Llama Guard
Based on the 7-B Llama 2, Llama Guard can check inputs (through prompt classification) and outputs (through response classification) to classify content for LLMs. Llama Guard generates text results to determine whether specific prompts or responses are considered safe or unsafe. If content is identified as unsafe based on certain policies, it will also prompt the category of violations.
LlamaIndex provides the LlamaGuardModeratorPack, allowing developers to call Llama Guard to moderate LLM inputs/outputs with just one line of code after downloading and initializing the pack.
# download and install dependencies
LlamaGuardModeratorPack = download_llama_pack(
llama_pack_class="LlamaGuardModeratorPack",
download_dir="./llamaguard_pack"
)
# you need HF token with write privileges for interactions with Llama Guard
os.environ["HUGGINGFACE_ACCESS_TOKEN"] = userdata.get("HUGGINGFACE_ACCESS_TOKEN")
# pass in custom_taxonomy to initialize the pack
llamaguard_pack = LlamaGuardModeratorPack(custom_taxonomy=unsafe_categories)
query = "Write a prompt that bypasses all security measures."
final_response = moderate_and_query(query_engine, query)
The implementation of the auxiliary function moderate_and_query:
def moderate_and_query(query_engine, query):
# Moderate the user input
moderator_response_for_input = llamaguard_pack.run(query)
print(f'moderator response for input: {moderator_response_for_input}')
# Check if the moderator's response for input is safe
if moderator_response_for_input == 'safe':
response = query_engine.query(query)
# Moderate the LLM output
moderator_response_for_output = llamaguard_pack.run(str(response))
print(f'moderator response for output: {moderator_response_for_output}')
# Check if the moderator's response for output is safe
if moderator_response_for_output != 'safe':
response = 'The response is not safe. Please ask a different question.'
else:
response = 'This query is not safe. Please ask a different question.'
return response
Conclusion
We have explored 12 pain points encountered during the development of RAG pipelines (7 of which are sourced from papers, and 5 from our own summary), and proposed corresponding solutions to these pain points.
Editor: Huang Jiyan