Author: Luv Bansal
Translation: wwl
Proofreading: Zhang Yiran
This article is approximately 4400 words long and is recommended for a reading time of over 10 minutes. This article discusses various techniques for optimizing different parts of the RAG pipeline and enhancing the overall RAG workflow.
Image generated by the author using Dalle-3 provided by Bing Chat
In my previous blog, I provided an in-depth introduction to RAG and how it is implemented with LlamaIndex. However, RAG often encounters many challenges when answering questions. In this blog, I will address these challenges and, more importantly, we will delve into solutions for improving RAG performance to make it suitable for production environments.
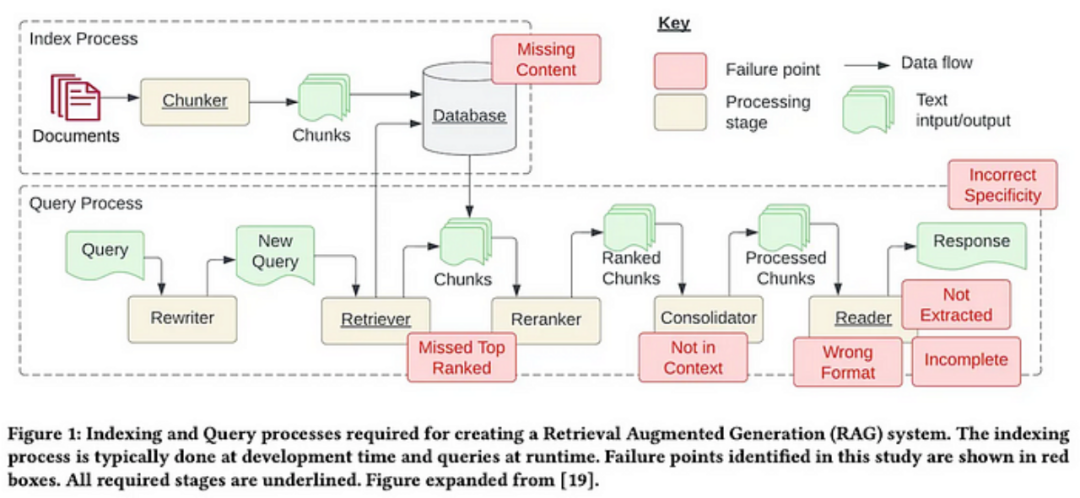
Image source: https://arxiv.org/pdf/2401.05856.pdf
I will discuss various optimization techniques from different research papers. Most of these techniques will be based on a research paper that I particularly like, titled “Retrieval-Augmented Generation for Large Language Models: A Survey.” (Link: https://arxiv.org/pdf/2312.10997.pdf). This paper contains most of the latest optimization methods.
1. Breakdown of the RAG Workflow
First, to enhance the understanding of RAG, we will break down the RAG workflow into three parts and optimize each part to improve overall performance.
In the Pre-Retrieval step, new data (also known as external data) is prepared beyond the original training dataset of the LLM and divided into chunks. Then, using an embedding model, the chunked data is converted into numerical representations and stored in a vector database. This process creates a knowledge base that the LLM can understand.
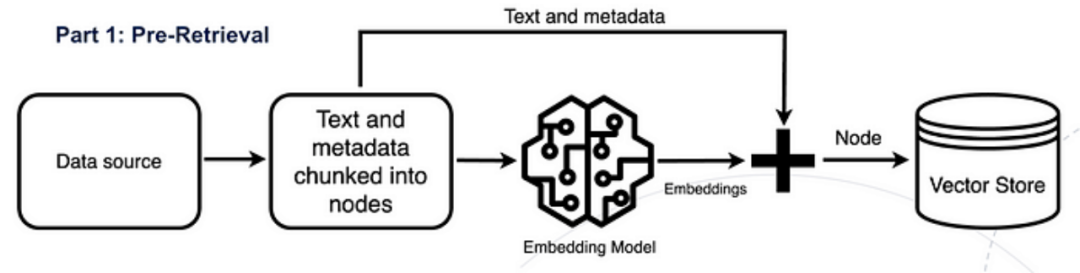
In the crucial Retrieval step, user queries are converted into vector representations called embeddings, and cosine similarity is used to find relevant chunks from the vector database. It attempts to find highly relevant document chunks from the vector store.
Next, the RAG model enhances user input (or prompts) by adding relevant retrieval data in context (query + context). This step uses prompt engineering techniques to communicate effectively with the LLM. The enhanced prompt allows the LLM to generate accurate answers to user queries using the given context.
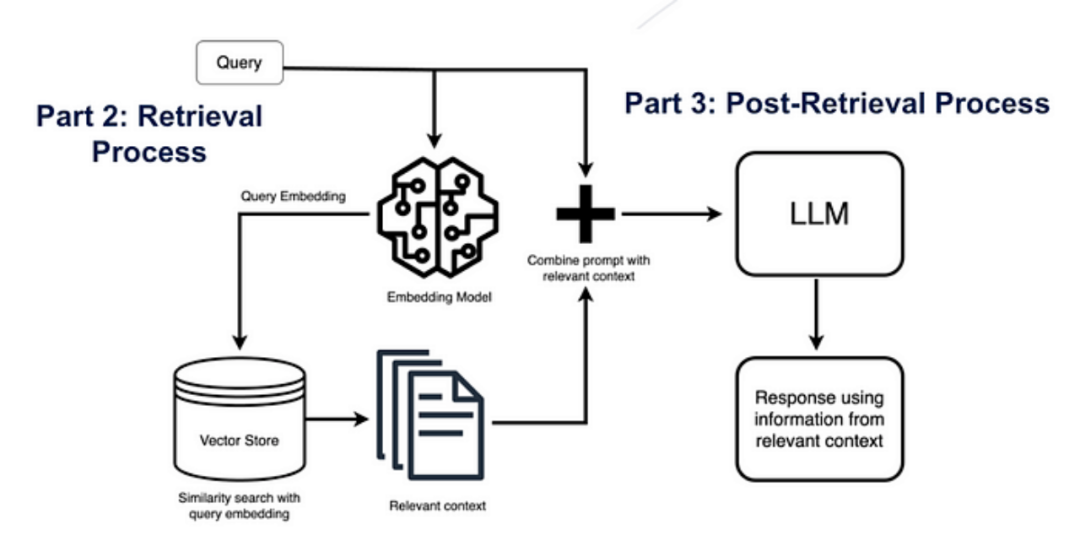
Our goal is to enhance the capabilities of each component of the RAG workflow by applying various techniques to different parts.
2. Pre-Retrieval Optimization
Pre-retrieval techniques include improving the quality of indexed data and chunk optimization. This step can also be referred to as enhancing semantic representation.
-
Enhancing Data Granularity
Improve data quality: “Garbage in, garbage out.”
Data cleaning plays a crucial role in the RAG framework. The effectiveness of RAG depends on the quality of data cleaning and organization. Remove unnecessary information, such as special characters, unwanted metadata, or text.
-
Remove irrelevant text/documents: Eliminate all irrelevant documents that the LLM does not need to answer. Also, remove noisy data, which includes deleting special characters, stop words (common words like “the” and “a”), and HTML tags.
-
Identify and correct errors: This includes spelling mistakes, typos, and grammatical errors.
-
Using names instead of pronouns in chunking can enhance semantic importance during retrieval.
Add metadata, such as concepts and hierarchical tags, to improve the quality of indexed data.
Adding metadata information includes integrating referenced metadata (such as date and usage) into the chunks for filtering and integrating referenced chapters and sections metadata into the chunks to improve retrieval efficiency.
Here are some scenarios where metadata is useful:
-
If the condition for searching an object is recent, then date metadata can be sorted.
-
If you are searching for research papers, and you know in advance that the information you are looking for is always in a specific section, like the experimental section, you can add the article section as metadata for each chunk and filter it to match only the experimental section.
Metadata is useful because it adds a layer of structured search on top of vector search.
Selecting the right chunk_size is a critical decision that can impact the efficiency and accuracy of the RAG system in several ways:
-
Relevance and Granularity
Smaller chunk_sizes, such as 128, produce finer-grained chunks. However, this granularity has risks, such as important information possibly not being in the most retrieved chunks, especially when the similarity_top_k setting is limited to 2. In contrast, a chunk size of 512 may contain all necessary information in the top chunks, ensuring that answers to queries are readily available.
As chunk_size increases, the amount of information inputted into the LLM to generate answers also increases. While this can ensure more comprehensive context, it may also slow down the system’s response speed.
If document chunks are too small, they may not contain all the information needed by the LLM to answer user queries. If chunks are too large, they may contain too much irrelevant information, confusing the LLM, or may be too large to fit the context size.
Determine the optimal length of chunks and how much overlap each chunk has based on downstream task needs.
Advanced tasks like text summarization require larger chunk sizes, while lower-level tasks like encoding require smaller text chunks.
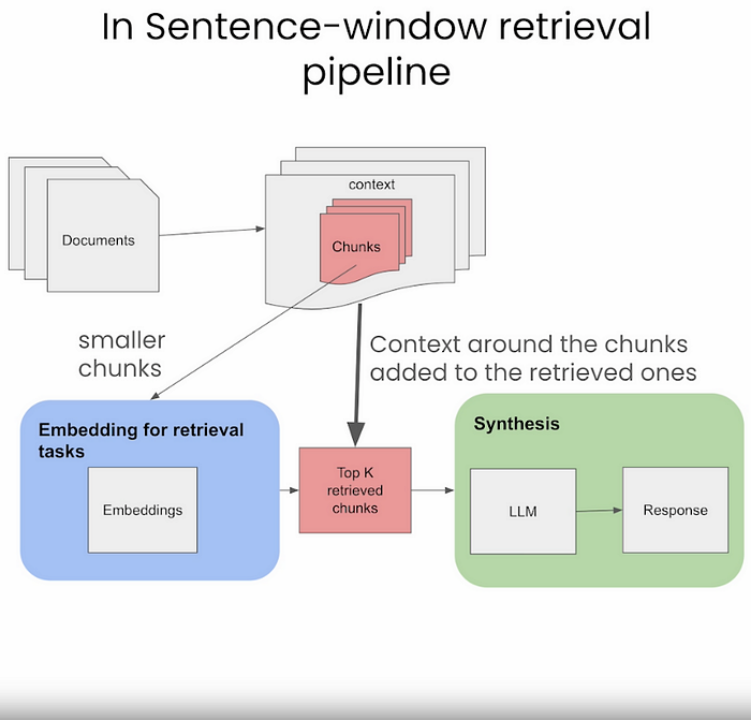
Small2big or Parent Document Retrieval
ParentDocumentRetriever achieves this balance by splitting and storing small chunk data. During the retrieval process, it first retrieves small chunks and then looks for the parent ID of those chunks, returning these larger documents to the LLM.
It uses small text chunks during the initial search phase, then provides larger relevant text chunks for processing to the language model.
Recursive retrieval involves obtaining smaller chunks during the initial retrieval phase to capture key semantics. Subsequently, larger text chunks containing more contextual information are provided to the LLM in the later stages of the process. This two-step retrieval approach helps balance efficiency and providing context-rich responses.
1. The process involves breaking down the original large document into smaller, more manageable units (referred to as sub-documents) and larger chunks (referred to as parent documents).
2. It focuses on creating embeddings for each sub-document, which are richer and more detailed than embeddings for each complete parent chunk. This helps the framework identify the most relevant sub-documents containing information related to the user query.
3. Once alignment with the sub-documents is established, it retrieves the entire parent document associated with that sub-document. In the illustrated image, the final parent chunk is obtained.
4. This retrieval of the parent document is important because it provides a broader context for understanding and responding to user queries. The framework can now access the entire parent document instead of relying solely on the content of the sub-documents.
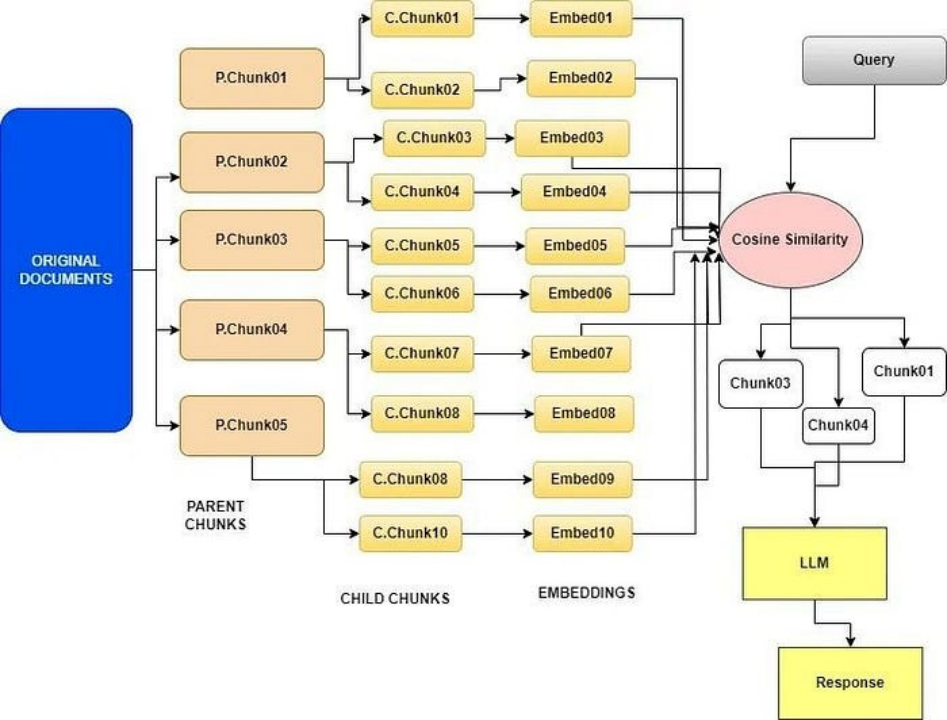
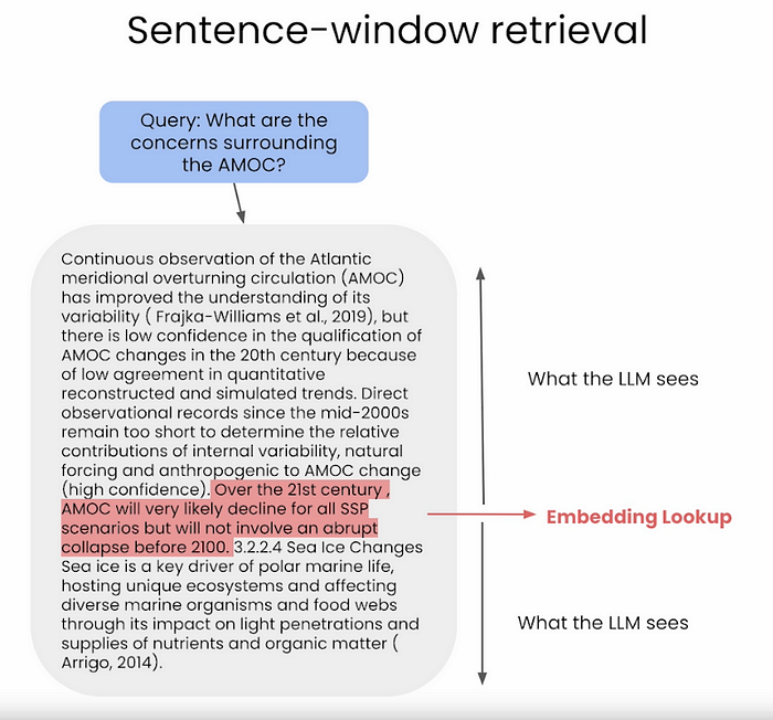
5. Sentence Window Retrieval
This chunking technique is very similar to the one above. The core idea of sentence window retrieval is to selectively obtain context from a custom knowledge base based on the query, and then utilize a broader version of that context to generate more robust text.
This process involves encoding a limited set of sentences for retrieval, along with additional context around those sentences, referred to as “window context,” which is stored separately and linked to them. Once the most similar sentences are identified, the context is re-integrated before these sentences are sent to the large language model (LLM) for generation, enriching the overall contextual understanding.
6. Retrieval Optimization
This is the most important part of the RAG workflow, which involves retrieving documents from the vector database based on user queries. This step can also be referred to as aligning queries and documents.
Query rewriting is a fundamental method for aligning the semantics of queries and documents.
In this process, we leverage the capabilities of the language model (LLM) to rewrite the user’s query to generate a new query. It is important to note that two questions that appear the same to humans may not be similar in embedding space.
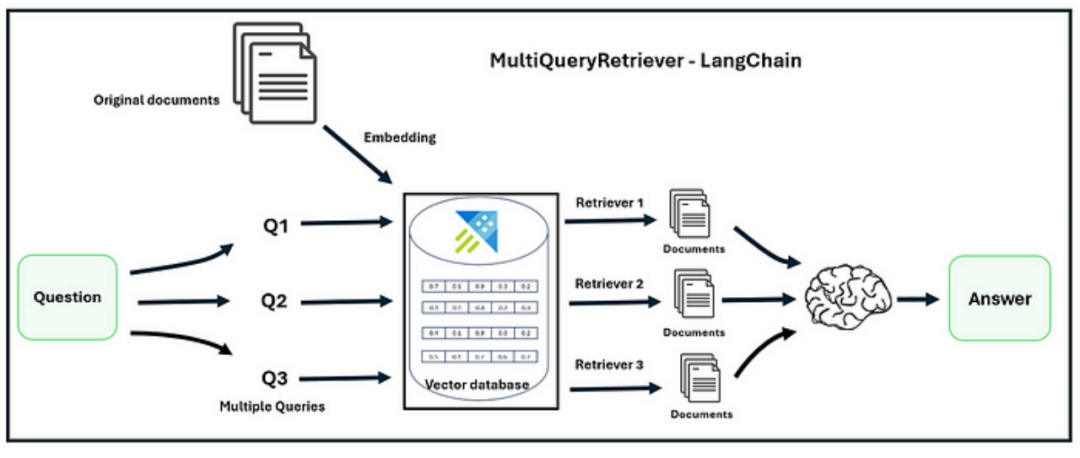
The multi-query retrieval approach utilizes the LLM to generate multiple queries from different perspectives for a given user input query, which is beneficial for addressing complex problems with multiple sub-questions.
For each query, it retrieves a set of relevant documents and obtains a unique union across all queries to achieve a larger potential relevant document set.
By generating multiple sub-questions on the same issue, the MultiQuery Retriever may be able to overcome some limitations of distance-based retrieval and obtain a richer result set.
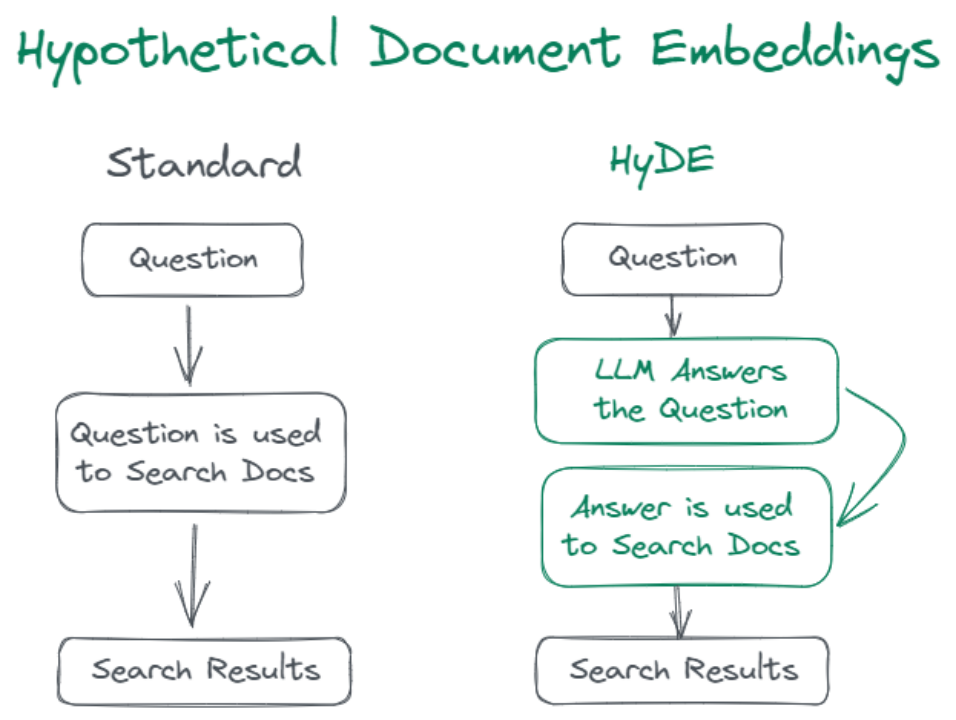
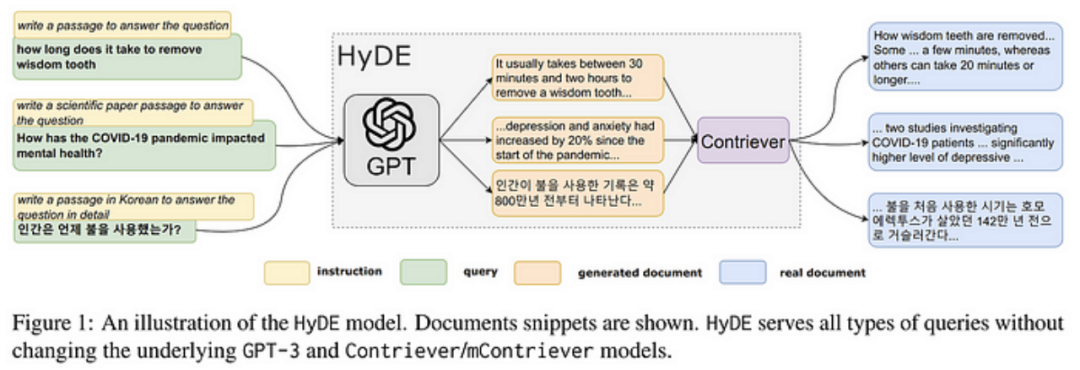
Hyde and Query2doc are similar query rewriting optimizations. Given that search queries are often short, ambiguous, or lack necessary background information, the LLM can provide relevant information to guide the retrieval system as it has memorized a vast amount of knowledge and language patterns by pre-training on trillions of tokens.
-
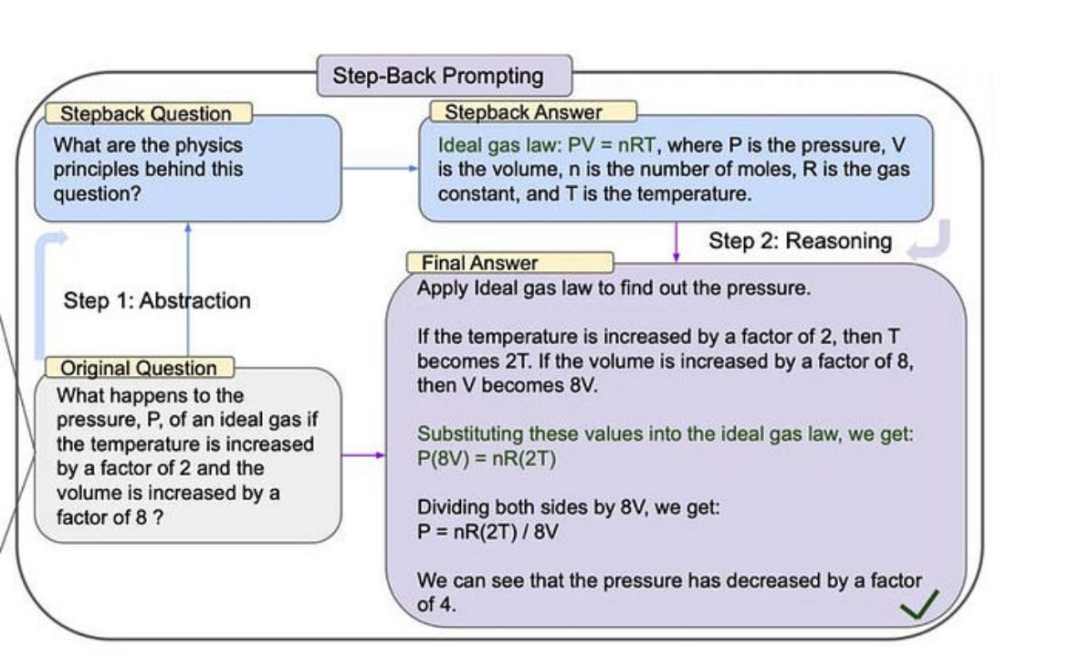
StepBack-prompt (Abstract Prompt)
The step-back prompting method encourages the language model to go beyond specific examples and focus on broader concepts and principles.
This template replicates the “step-back” prompting technique, which improves the handling of complex issues by first asking a “step-back” question. By retrieving information from both the original question and the step-back question, this technique can be combined with standard Q&A RAG applications. Below is an example of a step-back prompt.
7. Fine-tuning Embedding Models
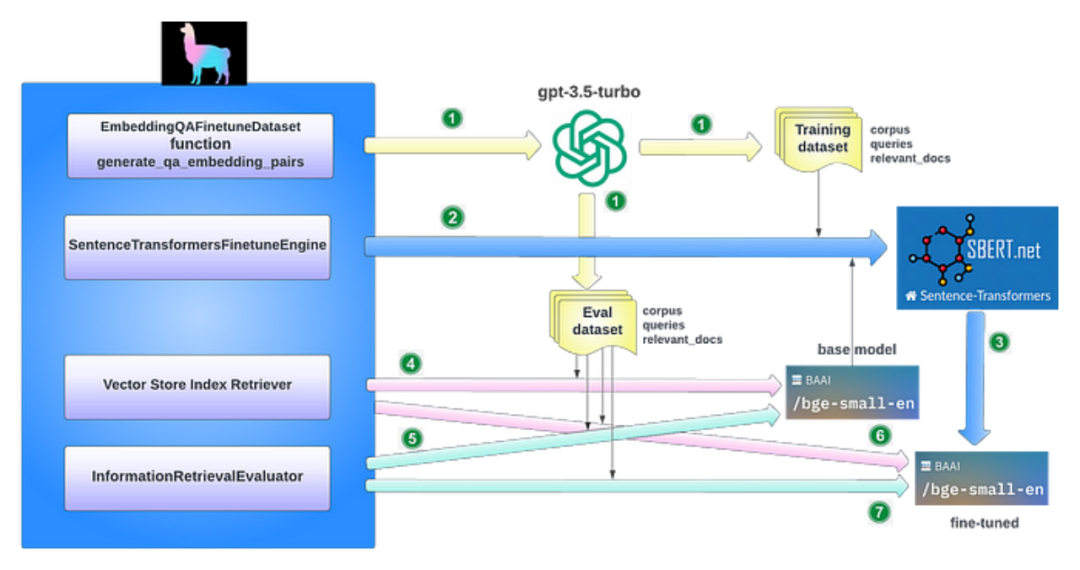
Fine-tuning embedding models significantly affects the relevance of retrieved content in the RAG system. This process involves customizing embedding models to enhance retrieval relevance in specific domain contexts, especially in specialized fields with ongoing updates or rare terms.
-
Generate Synthetic Datasets for Training and Evaluation
The key idea here is to generate training data for fine-tuning using language models like GPT-3.5-turbo to formulate questions based on document chunks. This allows us to generate synthetic pairs (queries, relevant documents) in a scalable manner without manual labeling. The final dataset will consist of paired questions and text chunks.
-
Fine-tune Embedding Models
Fine-tune any embedding model on the generated training dataset.
-
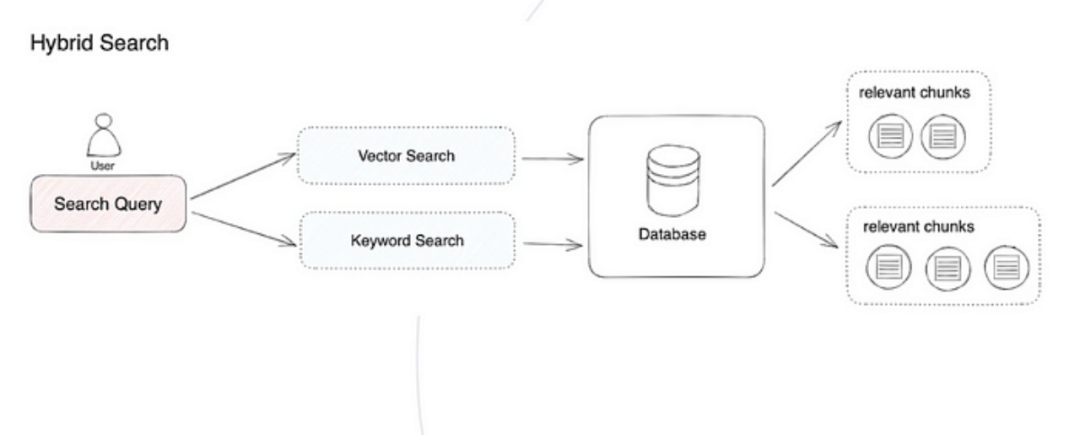
Hybrid Search Exploration
The RAG system optimizes its performance through the intelligent integration of various techniques, including keyword-based search, semantic search, and vector search.
This approach leverages the specific advantages of each method to accommodate different query types and information needs, ensuring consistent retrieval of highly relevant and context-rich information. Using hybrid search as a powerful complement to retrieval strategies enhances the overall efficiency of the RAG pipeline.
The most common pattern is to combine sparse retrievers (like BM25) with dense retrievers (like embedding similarity) because their strengths are complementary. This is also referred to as “hybrid search.” Sparse retrievers excel at finding relevant documents based on keywords, while dense retrievers excel at finding relevant documents based on semantic similarity.
8. Post-Retrieval Optimization
Re-ranking the retrieved results before sending them to the LLM can significantly improve RAG performance.
A high score from vector similarity search does not necessarily mean it has the highest relevance.
Core concepts include reordering document records, placing the most relevant at the top, thereby limiting the total number of documents. This addresses the challenge of expanding the context window during retrieval and improves retrieval efficiency and response speed.
Increasing similarity_top_k in the query engine to retrieve more contextual paragraphs can be reduced to top_n after re-ranking.
Noise in the retrieved documents can adversely affect RAG performance, so the most relevant information may be hidden in documents containing a lot of irrelevant text. Passing complete documents in applications may lead to higher costs for LLM calls and poorer responses.
Here, the focus is on compressing irrelevant context, highlighting key paragraphs, and reducing the overall length of the context.
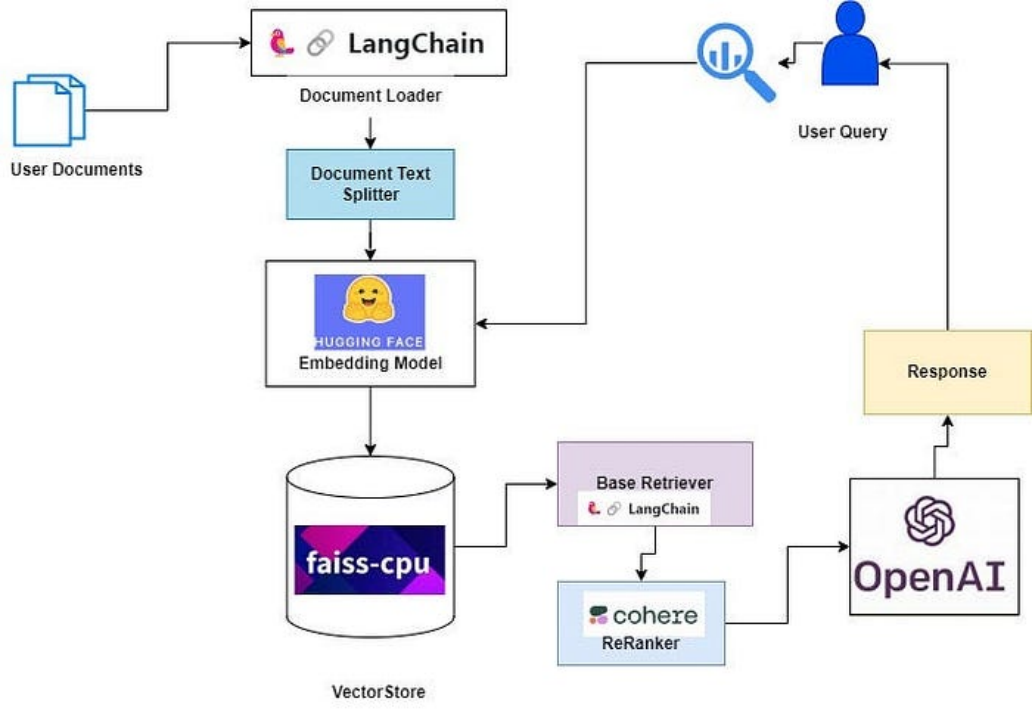
Context compression aims to solve this problem. The idea is simple: rather than immediately returning the retrieved documents as they are, they can be compressed using the context of the given query to return only relevant information. Here, “compression” refers both to compressing the content of individual documents and filtering out entire documents.
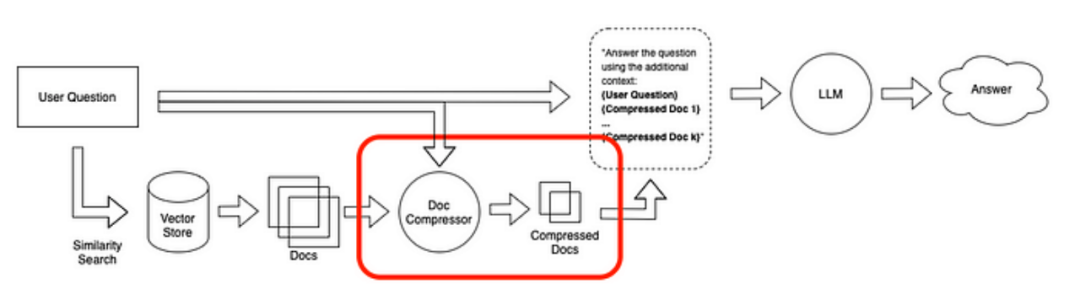
The document compressor is a small language model that calculates the mutual information of the prompts between the user query and the retrieved documents, estimating the importance of elements.
Modular RAG integrates multiple approaches to enhance different components of RAG, such as adding similarity retrieval search modules in the retriever and applying fine-tuning methods.
RAG fusion technology combines two methods:
Utilizing LLMs to generate multiple queries from different perspectives for a given user input query, which is beneficial for addressing complex problems containing multiple sub-questions.
-
Re-ranking Retrieved Documents
Re-ranking all retrieved documents and removing all documents with low relevance scores.
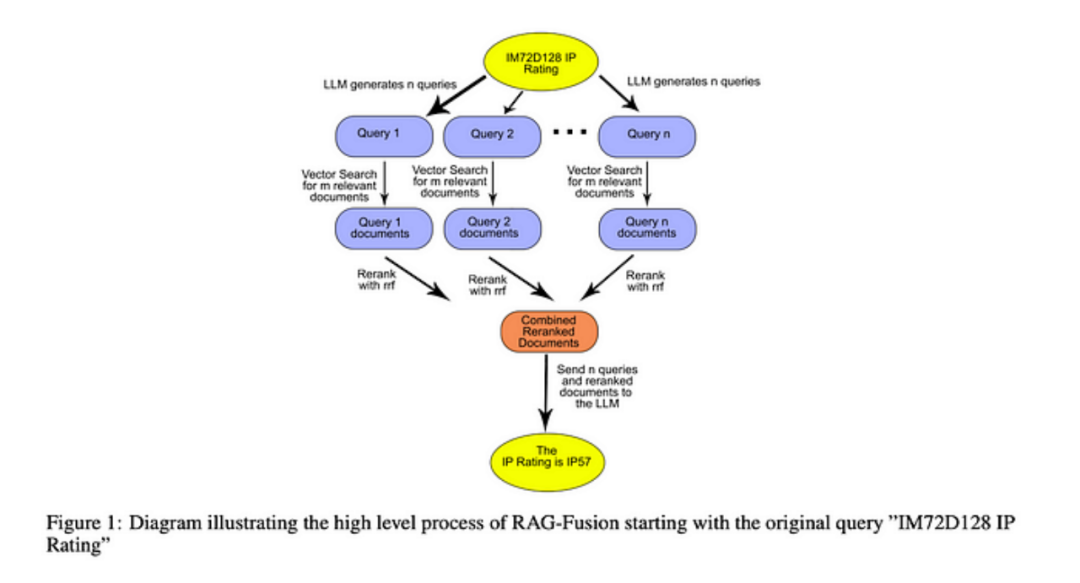
This advanced technology ensures that search results align with user intent, whether or not it is obvious. It helps users find more insightful and relevant information.
This article discussed various techniques for optimizing different parts of the RAG pipeline and enhancing the overall RAG workflow. You can use one or more of these techniques in your RAG pipeline, making it more accurate and efficient. I hope these techniques can help you build a better RAG pipeline for your applications.
Original Title: Advance RAG- Improve RAG performance
Subtitle: Ultimate guide to optimize RAG pipeline from zero to advance- Solving the core challenges of Retrieval-Augmented Generation
Original Link: https://luv-bansal.medium.com/advance-rag-improve-rag-performance-208ffad5bb6a
Translation Team Recruitment Information
Work Content: A meticulous heart is needed to translate selected foreign articles into fluent Chinese. If you are an international student in data science/statistics/computer science or work overseas in related fields, or if you are confident in your language skills, you are welcome to join the translation team.
You will get: Regular translation training to improve volunteers’ translation skills, enhance awareness of cutting-edge data science, and overseas friends can stay connected with domestic technological application development. The THU data team’s background in industry-academia-research provides good development opportunities for volunteers.
Other Benefits: You will have peers from data science workers in well-known companies, students from prestigious universities such as Peking University and Tsinghua University, and overseas students in the translation team.
Click the “Read the original text” at the end to join the data team~
Reprint Notice
If you need to reprint, please indicate the author and source (reprinted from: Data Team ID: DatapiTHU) prominently at the beginning and place the Data Team’s prominent QR code at the end of the article. For articles with original identifiers, please send [Article Name – Public Account Name and ID to be authorized] to the contact email to apply for whitelist authorization and edit as required.
After publication, please provide the link feedback to the contact email (see below). Unauthorized reprints and adaptations will be pursued legally.
Click “Read the original text” to embrace the organization



