Author: Raunak Jain March 18, 2024
Translator: Chen Zhiyan
Proofreader: zrx
This article is approximately 3700 words long and is suggested to be read in 9 minutes.
How to build a process-configurable compound AI system using open-source tools.
Design Patterns for Compound AI Systems (Conversational AI, CoPilots & RAG)
https://medium.com/@raunak-jain/design-patterns-for-compound-ai-systems-copilot-rag-fa911c7a62e0
What is a Compound AI System?
Recently, researchers from Berkeley wrote an article titled “From Models to Compound AI Systems Migration,” summarizing the latest developments in the application of large language models and emphasizing the evolution towards building complex pipeline intelligent systems rather than closed single models. The final system may use the same underlying model (like GPT-4), but treats prompts and contexts as different components.
Common deployment patterns for compound AI systems include:
1. RAG (Retrieval and Understanding are Key)— Through thought generation, reasoning, and contextual data, the system can self-reflect and attempt to understand user queries in a more advanced way, then provide answers; the ideal setting is an agent-assisted system. It integrates with user-facing model/system dialogue models, and RAG systems can also be part of conversational AI or CoPilot systems.
2. Multi-Agent Problem Solvers (Collaborative Role-Playing is Key)— The system relies on collaboration and automation construction from multi-agent outputs, where agent outputs input into each other, and each agent has a clear role and purpose. Each agent can access its own set of tools and takes on specific roles when reasoning and planning its actions.
3. Conversational AI (Dialogue is Key)— Like customer service agent class automation software, they interact with humans within the application ecosystem and can perform repeatable tasks based on human input and validation. Most importantly, dialogue memory and dialogue generation give the feeling of conversing with a human. Dialogue models can access the underlying RAG system and are multi-agent problem solvers.
4. CoPilots (Human in the Loop is Key)— By accessing tools, data, reasoning, and planning capabilities, along with professional profiles, the system can independently interact with humans when solving closed-loop problems. The key to CoPilot is understanding the context of human work. For example, MetaGPT researchers: searching the web and writing reports, weighing Devin’s opinions, and building tools with CrewAI.
Note: Based on the author’s experience in deploying multiple LLM systems, I believe these systems are not a panacea. Like other AI systems, a lot of work needs to be done around LLMs to make them do basic things, and even then, they cannot be completely reliable and scalable, and performance is hard to guarantee.
The Path Forward: The greatest value of using LLMs in ecosystems is enabling machine learning, i.e., understanding the weaknesses of products or experiences and feeding data back into the system in a way that improves performance over the long term, thereby replacing or reducing the work of human annotators. When testing and evaluating LLM outputs in closed systems, it can do a lot of surprising things! Although the cost of doing so is still considerable… this also generates data for building better LLMs, and the feedback effect that this machine learning relies on is the greatest value of LLMs.
System Components and How They Interact to Build Complex Systems
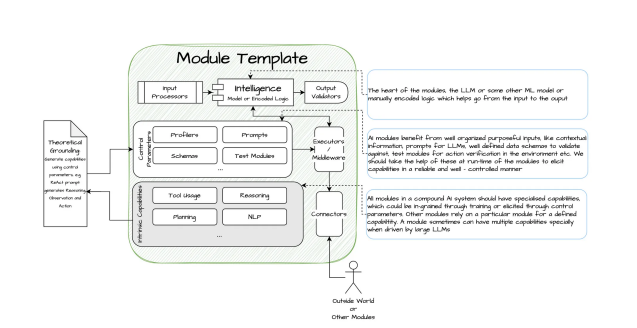
Deployment of compound AI systems typically uses interconnected “modules,” which perform specific tasks through interconnections and can be chained together to achieve specific design patterns.
Here, a module refers to different components in the system that can perform clearly defined tasks, including underlying systems such as search engines and LLMs. Common modules include generators, retrievers, rankers, classifiers, etc., traditionally referred to as NLP tasks. These conceptual abstractions focus on specific domains (for example, while NLP modules may have different abstract modules from computer vision or recommendation systems, they all rely on the same underlying model services or search providers).
Key Components of Modules
In the current popular AI culture, people have become accustomed to terms like “tools,” “agents,” and “components,” all of which can be viewed as modules.
LLM-Based Autonomous Agents — Key Modules in Compound AI Systems
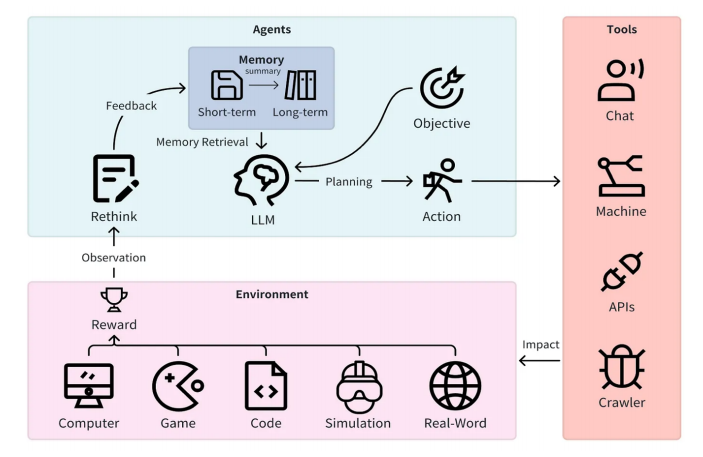
Autonomous agents are a form of module that can autonomously reason and plan with the help of LLMs. Autonomous agents rely on a series of sub-modules to decide how to reason and plan actions while interacting with the environment.
Key capabilities or skills of autonomous agents:
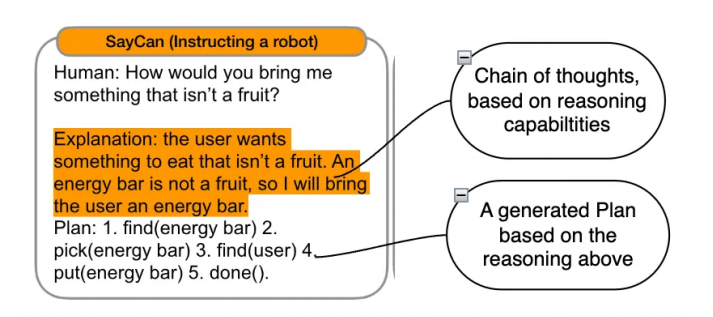
Reasoning ability, forming action plans through thought chains.
1. Reasoning — Solving problems through logical methods of observation, generating hypotheses, and validating based on data.
2. Thinking — Applying reasoning to generate consistent causal relationships.
3. Thought Chains — A series of thoughts that break down solutions into a series of logically interconnected reasoning.
4. Planning — Decision-making ability, forming sub-goals and constructing paths from the current state to the future state, capable of accessing the underlying environment to take actions and learn. Learn more about LLM planning here.
5. Tools — Sub-modules that agents interact with the external world based on instructions.
6. Actions — As the name suggests, these are decisive steps taken by agents to pursue goals, invoking tools according to the plan to trigger actions that take place in the environment.
7. Environment — The external source of agent actions and rewards, such as custom applications (like Microsoft Word, coding environments), games, or simulations.
Are We Collaborating with Random Parrots?
Note: Despite the theoretical work surrounding the lack of reasoning and planning capabilities in LLMs, it is clear that LLMs can mimic “solutions” well. If a problem needing a solution is presented, along with some examples of how the problem was previously solved, LLMs can replicate logical thinking processes well, without worrying about whether it generalizes, as Yann LeCun said, autoregressive models are doomed to fail!
In enterprise environments, all that is needed is to reliably repeat tasks and learn from past experiences, without the need for innovation like parroting.
How to Plan a Parrot in Real Environments?
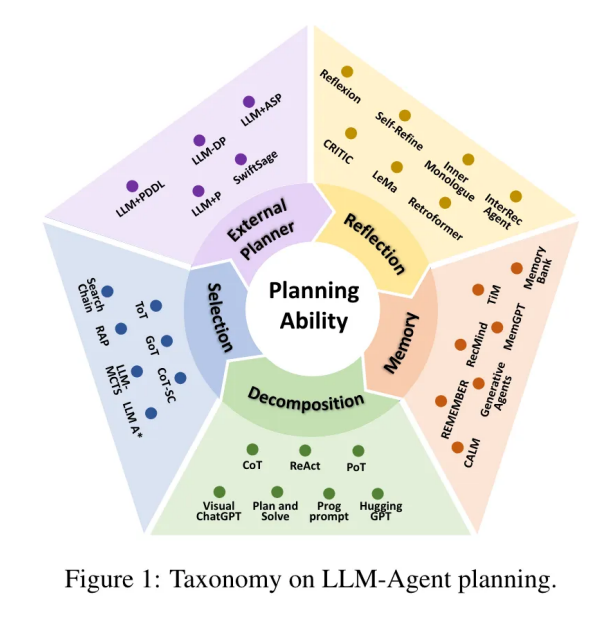
Research shows that LLMs can empower autonomous agents in the following ways:
1. Task Decomposition — Real-life tasks are often complex and multi-step, posing significant challenges for planning. To address this, a divide-and-conquer approach is adopted, breaking down complex tasks into several sub-tasks and then sequentially planning for each sub-task, such as TDAG.
2. Multiple Planning Choices — This method focuses on making LLMs “think” more by generating various alternative plans for tasks, then using task-related search algorithms to choose a plan for execution, such as ReWoo.
3. External Module-Assisted Planning — This refers to plan retrieval.
4. Reflection and Refinement — This method emphasizes improving planning capabilities through reflection and refinement, encouraging LLMs to reflect on failures and then refine plans, such as self-criticism and refinement loops.
5. Memory-Augmented Planning — This method enhances planning through additional memory modules that store valuable information, such as common knowledge, past experiences, and domain-specific knowledge. This information is retrieved during planning as auxiliary signals.
Understanding LLM Agent Planning: A Survey
How to train these capabilities for RAG? See “Fine-Tuning LLM for RAG Enterprises — Design Perspectives”.
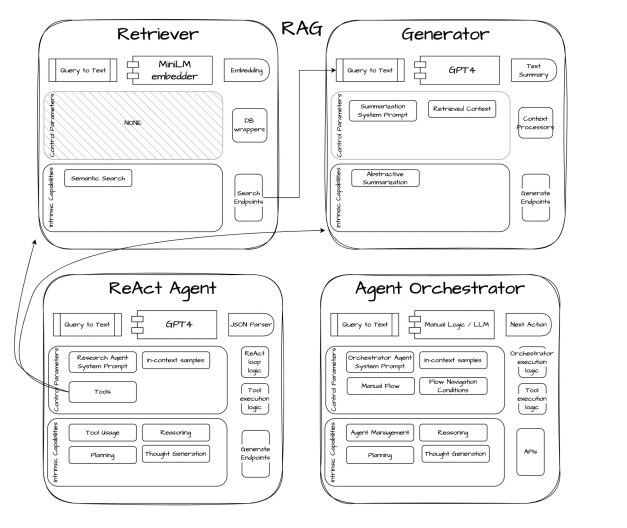
With these module abstractions in mind, let’s take a look at how to develop different design patterns to solve complex problems in conversational AI, RAG, and CoPilot systems.
Design Patterns for Compound AI Systems
Clarifying Some Definitions
Given the misused and misunderstood terms in the current AI “pop culture” environment, I feel compelled to clarify some facts before proceeding:
1. What is an “Agent” Pattern?
The core of autonomous agents is that they can autonomously decide which steps to take; if a process or decision needs to be manually defined, it is just an intelligent workflow. However, if no process needs to be defined and decision-making is enabled through the use of the aforementioned tools and actions, it is called an “agent” pattern. For example, an agent RAG is a pattern where a module is granted access to search tools, allowing it to automatically generate complex search processes without any predefined step intervention.
Simply put, a workflow is a pre-coded and manually declared plan to solve problems in a predictable and repeatable manner.
3. What is “Multi-Agent”?
Different modules in the system that take on different roles and responsibilities, interact with each other, and collaboratively process each other’s outputs to solve problems.
When building agents, the following key aspects need to be optimized:
1. Agent Profiles — The performance of agents is driven by prompts and is highly dependent on “role” profiles.
2. Agent Communication — The communication patterns between modules can be abstracted as shown in the diagram below.
3. Agent Environment Interfaces — Collecting feedback from execution environments to learn, adapt, and position generation is particularly important.
4. Agent Learning and Evolution — Agent systems learn from interactions with the environment (especially for coding assistants), other agents, self-reflection, human feedback, tool feedback, etc. Next, we will explore what strategies each architecture uses in real-time problem-solving.
Considerations Before Choosing a Pattern
To abstractly define design patterns, it is necessary to develop RAG, conversational AI, CoPilots, and complex problem solvers, for which the following questions are posed:
1. Is the flow between modules clearly defined or autonomous? Project flow versus agent systems.
2. Is the flow directional or inspired by “messaging”? Is it collaborative or competitive? Agent modules.
3. Is the flow self-learning? Is self-reflection and correction important?
-
Can reasoning and action loops be established?
-
Can modules provide feedback to each other?
4. Can the outputs of each module be tested in the environment?
5. Does the execution of the flow change with user input?
In the following sections, we will introduce three deployment patterns for compound AI systems.
Author: Raunak Jain, searching for patterns and building abstractions.
Chen Zhiyan, graduated from Beijing Jiaotong University with a master’s degree in Communication and Control Engineering. He has worked as an engineer at Great Wall Computer Software and Systems Company, and Datang Microelectronics Company. Currently, he is a technical support specialist at Beijing Wuyi Chaoqun Technology Co., Ltd. He is engaged in the operation and maintenance of intelligent translation teaching systems, accumulating experience in deep learning and natural language processing (NLP) in artificial intelligence. In his spare time, he enjoys translation and creative writing, with translated works including: IEC-ISO 7816, Iraq Oil Engineering Project, New Fiscal Taxism Declaration, etc. His English translation of the “New Fiscal Taxism Declaration” was officially published in GLOBAL TIMES. He hopes to join the translation volunteer group of the THU Data Tribe platform in his spare time, to communicate, share, and progress together with everyone.
Translation Group Recruitment Information
Job Content: Requires a meticulous heart to translate selected foreign articles into fluent Chinese. If you are an international student in data science/statistics/computer science, or working overseas in related fields, or confident in your foreign language skills, you are welcome to join the translation group.
You Will Get: Regular translation training to improve volunteers’ translation skills, enhance understanding of cutting-edge data science, and overseas friends can stay connected with domestic technological applications. The background of the THU Data Tribe’s industry-academia-research provides good development opportunities for volunteers.
Other Benefits: You will have partners in the translation group from data scientists of well-known companies and students from prestigious universities like Peking University and Tsinghua University, as well as overseas institutions.
Click on “Read the Original” at the end to join the Data Tribe team~
Reprint Instructions
If you need to reprint, please indicate the author and source prominently at the beginning (Reprinted from: Data Tribe ID: DatapiTHU), and place a prominent QR code for Data Tribe at the end of the article. For articles with original identification, please send [Article Name – Authorized Public Account Name and ID] to the contact email to apply for whitelist authorization and edit as required.
After publishing, please provide the link to the contact email (see below). We will pursue legal responsibility for unauthorized reprints and adaptations.
Data Tribe THU, as a data science public account, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, striving to build a data talent gathering platform, and creating the strongest group of data scientists in China.

Sina Weibo: @数据派THU
WeChat Video Account: 数据派THU
Today’s Headlines: 数据派THU
Click “Read the Original” to Embrace the Organization