1 Algorithm Introduction
-
Knowledge Limitations: The knowledge of the model itself is entirely derived from its training data. The training datasets of mainstream large models (ChatGPT, Wenxin Yiyan, Tongyi Qianwen, etc.) are primarily constructed from publicly available data on the internet, which means they cannot access real-time, non-public, or offline data, resulting in a lack of knowledge in these areas.
-
Hallucination Issues: All AI models are fundamentally based on mathematical probabilities, and their outputs are essentially a series of numerical computations. Large models are no exception; they can sometimes generate nonsensical outputs, especially in areas where the model lacks knowledge or is not proficient. Distinguishing these hallucination issues can be challenging, as it requires users to have relevant domain knowledge.
-
Data Security: For enterprises, data security is crucial. No company is willing to take on the risk of data leakage by uploading its private domain data to third-party platforms for training. This leads to applications that rely entirely on the capabilities of generic large models having to make trade-offs between data security and effectiveness.

2 Algorithm Principles
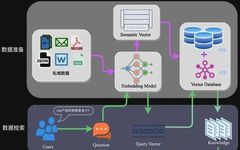
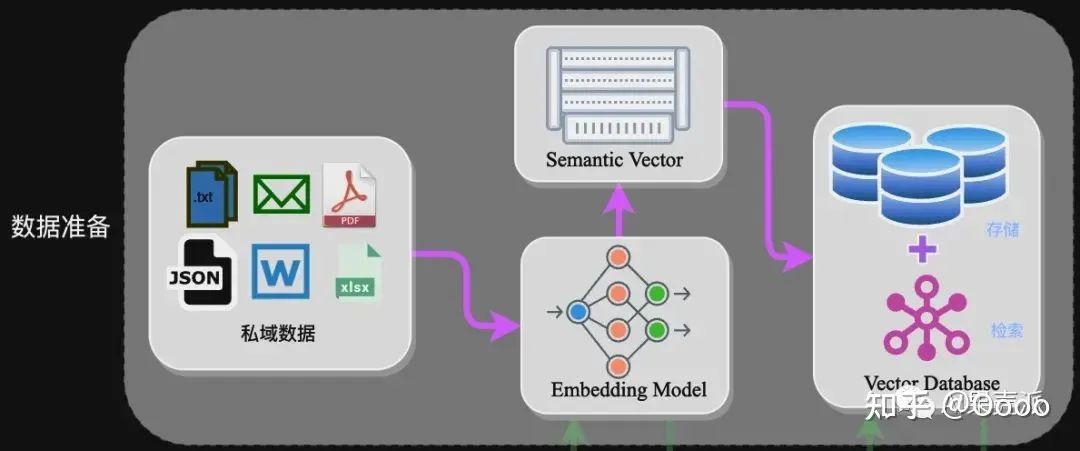
Data Preparation Stage: Data Extraction -> Text Segmentation -> Vectorization (embedding) -> Data Storage
Application Stage: User Inquiry -> Data Retrieval (Recall) -> Inject Prompt -> LLM Generates Answer
Data Preparation Stage:
-
Data Extraction:
-
Data Loading: Includes multi-format data loading, obtaining data from different sources, etc. Based on the data itself, process it into a uniform format.
-
Data Processing: Includes data filtering, compression, formatting, etc.
-
Metadata Extraction: Extract key information from the data, such as file names, titles, timestamps, etc.
-
Text Segmentation: Text segmentation mainly considers two factors: 1) the token limit of the embedding model; 2) the impact of semantic integrity on overall retrieval effectiveness. Some common text segmentation methods are as follows:
-
Sentence Segmentation: Segmenting at the level of “sentences” to retain the complete semantics of a sentence. Common delimiters include periods, exclamation marks, question marks, line breaks, etc.
-
Fixed-Length Segmentation: Segmenting the text into fixed lengths (e.g., 256/512 tokens) based on the token length limit of the embedding model. This segmentation method often loses a lot of semantic information, typically alleviated by adding a certain redundancy at the beginning and end.
-
Vectorization (embedding):
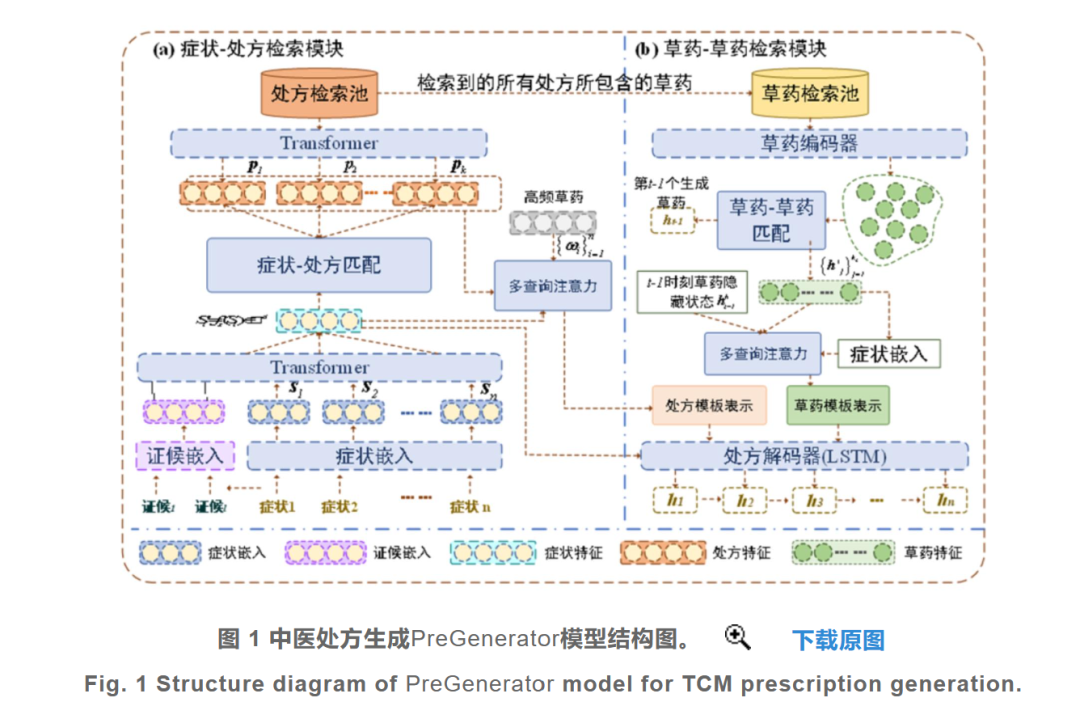
3 Algorithm Applications
4 Conclusion
For traditional Chinese medicine, the most widely adopted form of preserving medical knowledge, experimental results, medical analysis results, and clinical case histories is text. Utilizing these literature resources is a challenging task, which is very important for applying AI models in medical literature resources.
Many technologies spawned by AI models exist, and each step requires careful research over a long period to truly meet practical applications, along with continuous practice to refine high-quality results.
References:
[1] Zhao Zijuan, Ren Xue Ting, Song Kai, et al. Research on a Retrieval-Augmented Traditional Chinese Medicine Prescription Generation Model [J/OL]. Journal of Taiyuan University of Technology: 1-19 [2024-03-21]. http://kns.cnki.net/kcms/detail/14.1220.N.20230714.1922.002.html.
[2] Zhihu Column. “Introduction to the Mainstream Application of Large Models RAG – From Architecture to Technical Details”. Published on March 21, 2024. https://zhuanlan.zhihu.com/p/676982074.

Ancient and Modern Medical Case Cloud Platform
Providing Retrieval Services for Over 500,000 Ancient and Modern Medical Cases
Supports Manual, Voice, OCR, and Batch Structured Input of Medical Cases
Designed Nine Analytical Modules, Close to Clinical Practical Needs
Supports Collaborative Analysis of Massive Medical Cases and Personal Cases
EDC Traditional Chinese Medicine Research Case Collection System
Supports Multi-Center, Online Random Grouping, Data Entry
SDV, Inspection Trails, SMS Reminders, Data Statistics
Analysis and Other Functions
Supports Customized Form Design
Users can log in at: https://www.yiankb.com/edc
Free Trial!

Institute of Traditional Chinese Medicine Information Research, Chinese Academy of Chinese Medical Sciences
Ancient and Modern Medical Case Cloud Platform
Providing Retrieval Services for Over 500,000 Ancient and Modern Medical Cases
Supports Manual, Voice, OCR, and Batch Structured Input of Medical Cases
Designed Nine Analytical Modules, Close to Clinical Practical Needs
Supports Collaborative Analysis of Massive Medical Cases and Personal Cases
EDC Traditional Chinese Medicine Research Case Collection System
Supports Multi-Center, Online Random Grouping, Data Entry
SDV, Inspection Trails, SMS Reminders, Data Statistics
Analysis and Other Functions
Supports Customized Form Design
Users can log in at: https://www.yiankb.com/edc
Free Trial!
Institute of Traditional Chinese Medicine Information Research, Chinese Academy of Chinese Medical Sciences
Intelligent R&D Center for Traditional Chinese Medicine Health
Big Data R&D Department
Phone: 010-64089619
13522583261
QQ: 2778196938
https://www.yiankb.com