
What to do when internal prior knowledge of LLM conflicts with RAG?
Recently, I completed a work on Adaptive RAG at Huawei Noah and am currently working on aligning fictional world knowledge with real-world knowledge, especially for intelligent game NPCs. I would like to share some thoughts on how to balance internal and external knowledge in LLMs and some exploratory, analytical, and summarizing works we have done in this area.
This writing is somewhat stream-of-consciousness; corrections are welcome.
Background (RAG)
1.1 What is RAG
Retrieval-Augmented Generation (RAG): RAG generally refers to the method of introducing external knowledge into the generation process of LLMs through retrieval.
The sources for retrieval can be search engines or off-line databases (such as confidential data from companies or governments).
The way to combine external knowledge can be through some Encoder that encodes external knowledge into a vector combined with the intermediate layer or output layer of the LLM, or it can be directly input into the LLM as a prompt. The former is represented by KNN-LM [1]; the latter is simpler, more intuitive, and does not require fine-tuning, and is currently the mainstream method.
BTW, the former method has also seen extensive application in recommendation systems/tabular prediction, and the way of application is relatively easier to understand. Refer to RIM [2] and ROK [3]. Both are works from Huawei Noah. Among them, RIM is a work from KDD 2021, while ROK is from CIKM’24.
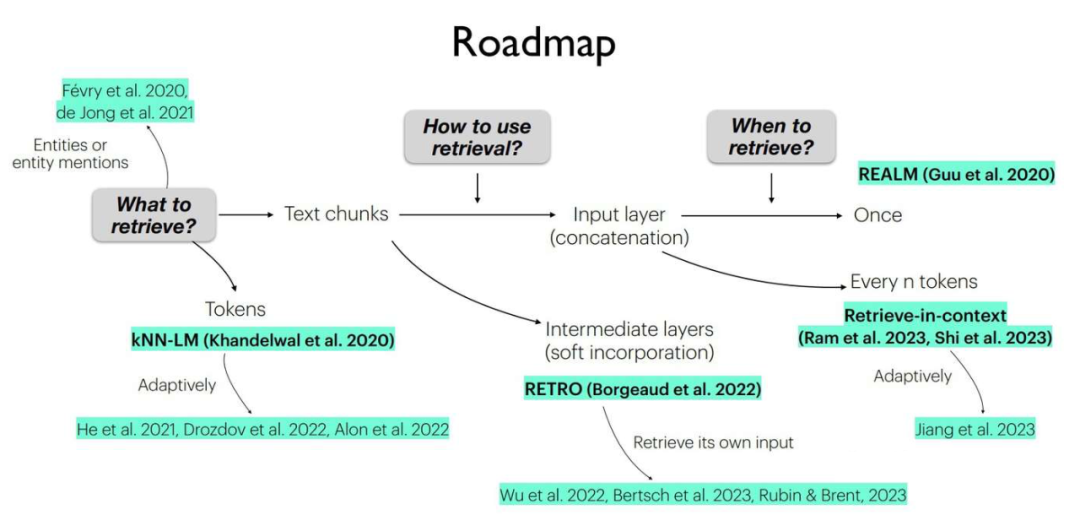
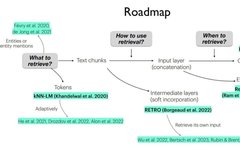
The above image is taken from the ACL 2023 Tutorial [4], from Princeton NLP and UW NLP. They break down the process of Retrieval-Augmented Generation (RAG) into what to retrieve (how to handle the source needing retrieval), how to use what is retrieved (combined into input, intermediate layer, or output layer), and when to retrieve (when we need to retrieve). This article mainly focuses on when to retrieve and how to use what is retrieved.
1.2 Why RAG is Needed
First, let’s introduce a few viewpoints:
-
LLMs always need to continuously introduce new knowledge, such as knowledge in a specific niche, confidential information from companies or governments, and real-time information.
-
The hallucination problem (LLMs making things up) is almost unavoidable, but we hope to make LLM outputs as traceable as possible.
For knowledge updates, we can either continue pre-training or fine-tune the LLM to turn knowledge into the LLM’s parametric memory (training), or we can use retrieval to let the LLM answer through ICL (RAG).
So why use RAG?
1. RAG can enhance the interpretability of LLM outputs (specifically which supporting document was used).
2. In terms of effectiveness:
-
The results of Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs [5] show that RAG is more effective than fine-tuning in injecting new knowledge.
-
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? [6] shows that fine-tuning LLMs may actually increase the risk of hallucinations.
-
A shallow viewpoint: The pre-training phase is the main process for injecting knowledge; fine-tuning may not be able to inject new knowledge but only trains the model’s ability to follow certain instructions.
Compared to the various uncertainties of fine-tuning, RAG is a simpler, cost-effective, and interpretable solution.
1.2.1 Comparing Long Context LLMs
By the way, we can discuss whether RAG is still needed when the model has long-context capabilities.
The conclusion is that it is indeed needed.
The reason is that RAG and long-context aim to achieve similar goals. RAG retrieves and slices documents to more finely process and recall the context needed by the LLM for answering questions. Long-context LLMs do this by passing this recall back to the LLM itself through prompts. Therefore, RAG can be understood as a process of denoising the prompt (context) given to the LLM.
Here are some simple viewpoints:
1. Effectiveness and Interpretability
-
Aside from simple needle-in-a-haystack evaluations, we cannot currently determine whether LLMs can effectively reason in large contexts.
-
Noisy contexts can damage LLM performance [7][8].
-
There is still no complete theory and analysis on how prompts affect LLM responses (even for the simplest demonstration ICL scenarios, let alone ultra-long contexts).
2. Costs: The inference cost of Transformers increases with the length of context; over-reliance on long contexts may not be cost-effective and does not make sense (of course, many works are currently trying to reduce this cost).
So what insights does long context provide for RAG?
RAG doesn’t need to focus too much on particularly fine-grained slicing, meaning in the future we will care more about the recall of the retrieved documents rather than precision (more concerned with whether we can retrieve something that helps us answer the question rather than how many of the 10 retrieved documents can actually help us answer the question).
When to Retrieve and How to Use What is Retrieved
These two questions are closely related:How do we balance the model’s internal knowledge (parametric knowledge) and external knowledge?
In other words, the model’s internal knowledge can be right or wrong, and the retrieved knowledge can also be right or wrong (it may even be harmful). The ideal situation is that when the model’s internal knowledge is correct, we use that; when external knowledge is correct, we can also choose to use that correct external knowledge.
If both internal and external knowledge are correct, there is no problem; either can be used. But what if only one of the internal or external knowledge is correct? Or if they are both incomplete and need to complement each other?
External knowledge does not necessarily help the model’s accuracy:
We conducted an experiment in a simple setting: Mistral-7B + BGE (using Wikipedia as the data source) + TriviaQA.
About 10% of the questions were correctly answered using internal knowledge, but after introducing retrieved external knowledge, the answers were wrong.. In this setting, the quality of the retrieved documents and the capability of the LLM can be guaranteed (good dense retriever + clean data source + simple questions + capable model), but still, many questions can be harmed by introducing external knowledge. In actual situations, it will only get worse (uncertain retriever + dirtier data source + more complex questions + model capabilities not guaranteed).
2.1 Analysis of Internal and External Knowledge Conflicts and Fusion
Some articles on the conflict and fusion of internal and external knowledge (How to use retrieval) have studied this issue, attempting to analyze how models can balance internal and external knowledge in a setting where the model is always retrieving.
1. Conflict: How does the model handle when the answer it believes differs from the answer in the context?
ClashEval [9] analyzes when the model uses internal knowledge versus external knowledge based on the prior probability of the answer obtained without using external knowledge and the degree to which the context deviates from the correct answer [10].
This review provides a comprehensive analysis and summary. You can also refer to the author @Mo Jingzhe’s interpretation and analysis of this paper [11].
2. Fusion: How does the model handle answering a question that may require multiple pieces of information, where some information is only available from internal knowledge or only from external knowledge?
Evaluating the External and Parametric Knowledge Fusion of Large Language Models [12] systematically analyzed the issue of knowledge fusion for the first time. This article deconstructs knowledge fusion into four scenarios and analyzes the performance of LLMs in these four scenarios:
-
Internal knowledge is sufficient to answer the question.
-
External knowledge is sufficient to answer the question.
-
Both internal and external knowledge are needed to answer the question; either alone is insufficient.
-
Neither internal nor external knowledge can help answer the question.
However, research in this area is still relatively preliminary, and there is currently no clear conclusion [3].
2.2 Adaptive RAG
On the other hand, intuitively controlling whether the model retrieves can also balance internal and external knowledge (naturally, if no retrieval is done, only internal knowledge is used). This work pertains to the exploration of When to retrieve.
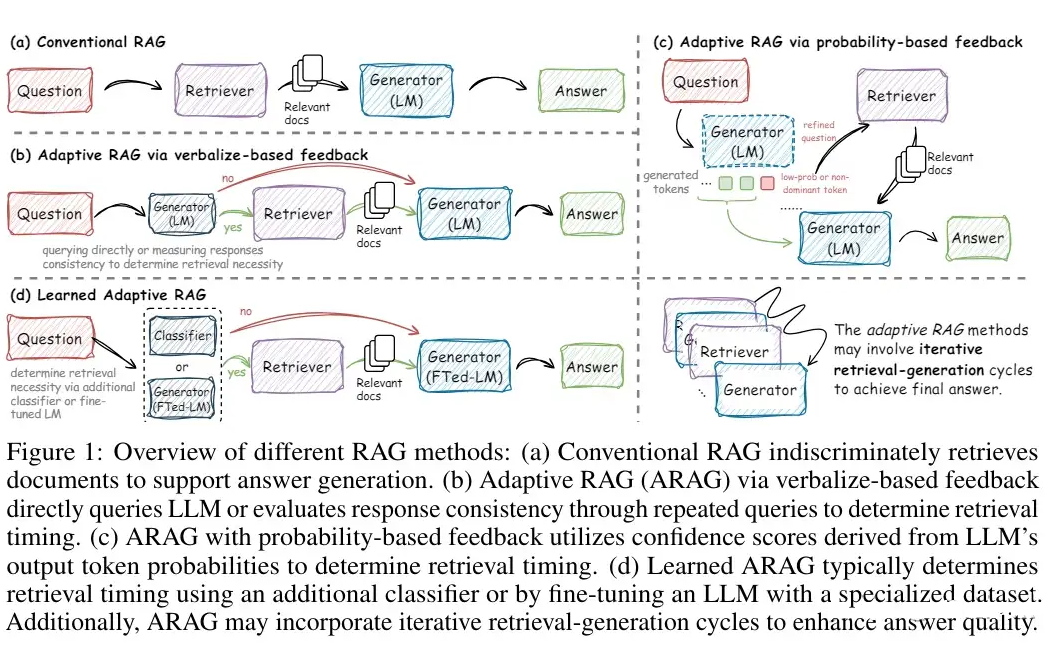
The above image is from CtrlA. [13] Intuitively, the methods of ARAG essentially hope to probe the knowledge boundaries of the model. That is, we want to know what the model knows and what it does not know. Naturally, if we know the model’s knowledge boundaries, we can let the model answer directly when it knows the answer, and retrieve when it does not know the answer. However, probing the model’s knowledge boundaries is a very difficult problem, so existing ARAG works often take a roundabout way to determine when to retrieve:
1. Based on explicit model response feedback: For example, perturbing the model’s prompt and questions in different ways to see if the model’s responses are consistent. Consistency indicates that the model knows the answer and does not need to search.Representative work—Rowen [14]
2. Through probability feedback: Assuming the model is well-calibrated, meaning the probabilities of the output tokens represent its confidence. If the probability is high, it indicates high confidence, and no retrieval is needed.Representative work—FLARE [15]
3. By fine-tuning or additionally training a classifier: These two methods hope to inject the model with the ability to judge whether to search. For example, judging the type of question, if external knowledge is beneficial for this type of question, then retrieve; if not helpful, do not retrieve.Representative work—Self-RAG [16]
However, judging the model’s knowledge boundaries/confidence/when to search based on the model’s surface behavior has some issues. First, we can look at what conditions need to be met for an LLM to answer a question (let’s assume it is a question with a clear answer) without retrieving external knowledge.
Condition 1: Model’s Internal Cognition = Ground Truth
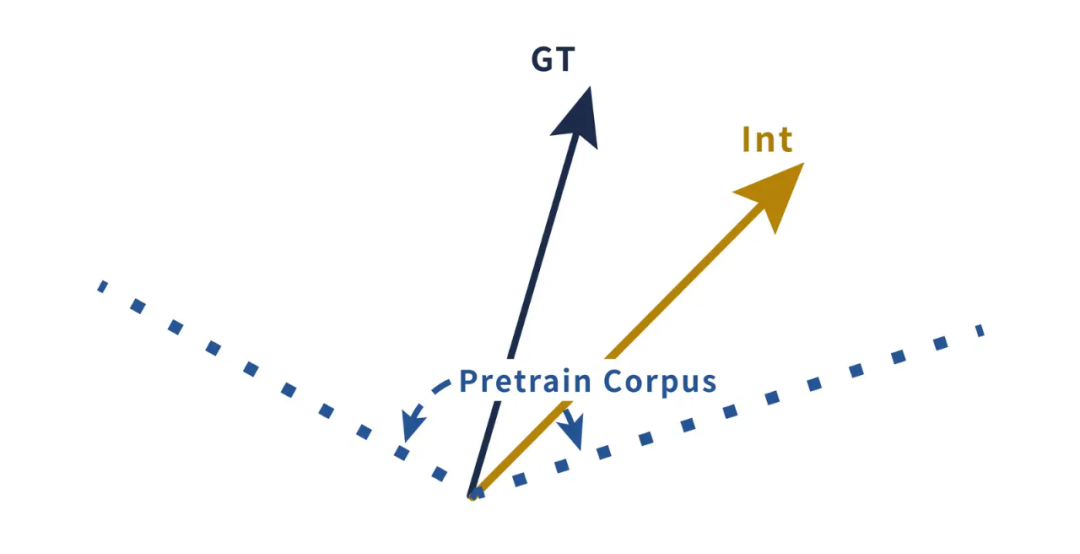
Internal cognition is determined by the pre-training corpus, and due to noise in the pre-training corpus, as well as ground truth potentially changing over time [18], the LLM’s internal cognition may not align with the Ground Truth.
Condition 2: Model’s Internal Cognition = Model’s Desired Output
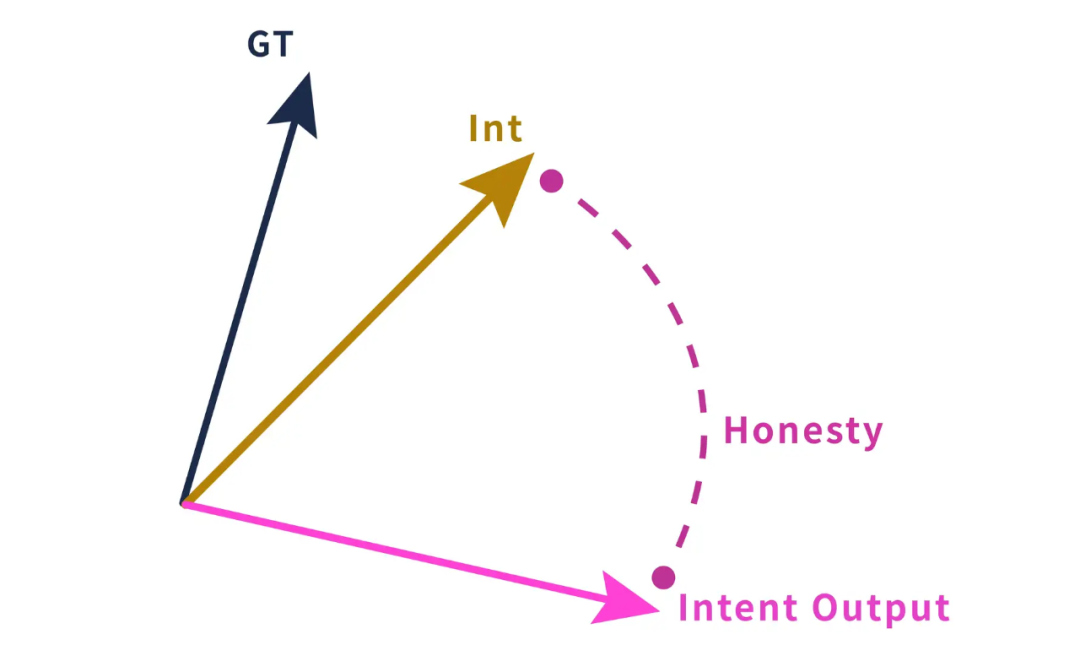
Why is Condition 2 necessary? Because the model’s cognition of something may not be what it wants to output.
A typical example is narrow lying. For instance, we tell the LLM that it scored a C on an exam, but it does not want to be scolded when it goes back. Then we ask it how it would respond. It might say it got an A to avoid punishment. At this point, the LLM’s output deviates from its cognition [19].
Another example is unconscious lying by the model, which is common in TruthfulQA. In other words, the LLM may be misled by the prompt [20]. In this case, the model may not be able to decode its true cognition.
Condition 3: Model Decodes Its Intent to Output
Even if the LLM has a clear intention to output something, it may not be able to decode its intended output.
An example: multiple samplings may yield completely different answers.
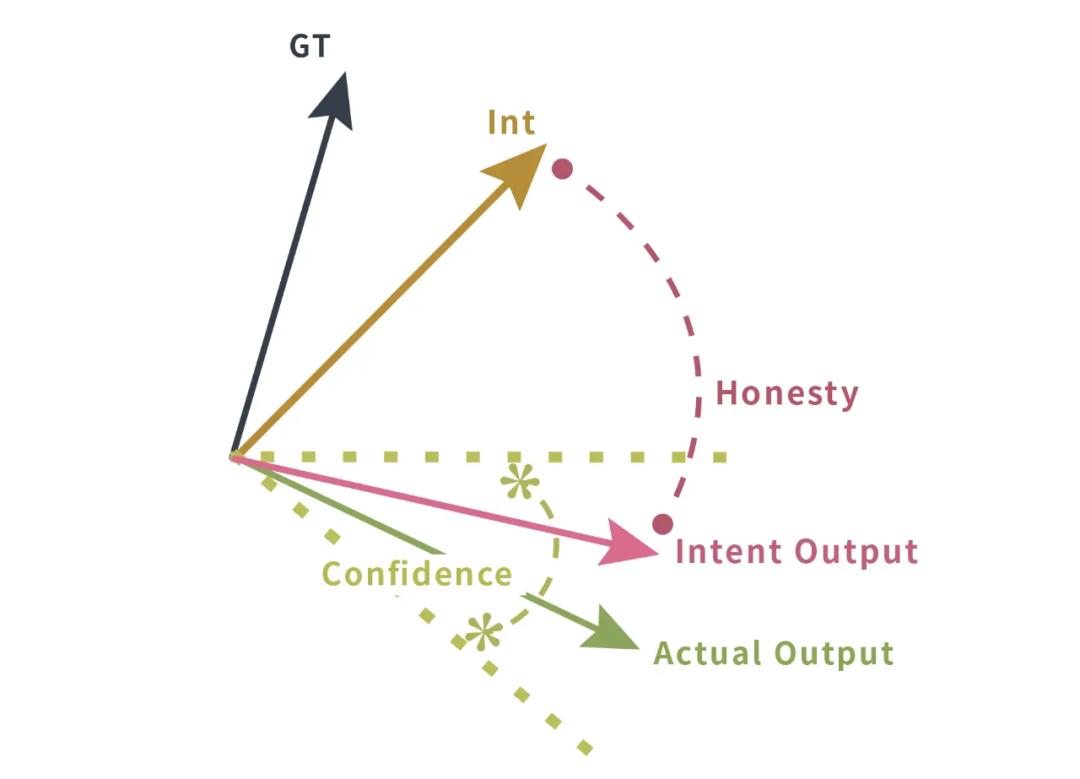
So what does RAG do to align the LLM’s answers with the Ground Truth and improve accuracy?
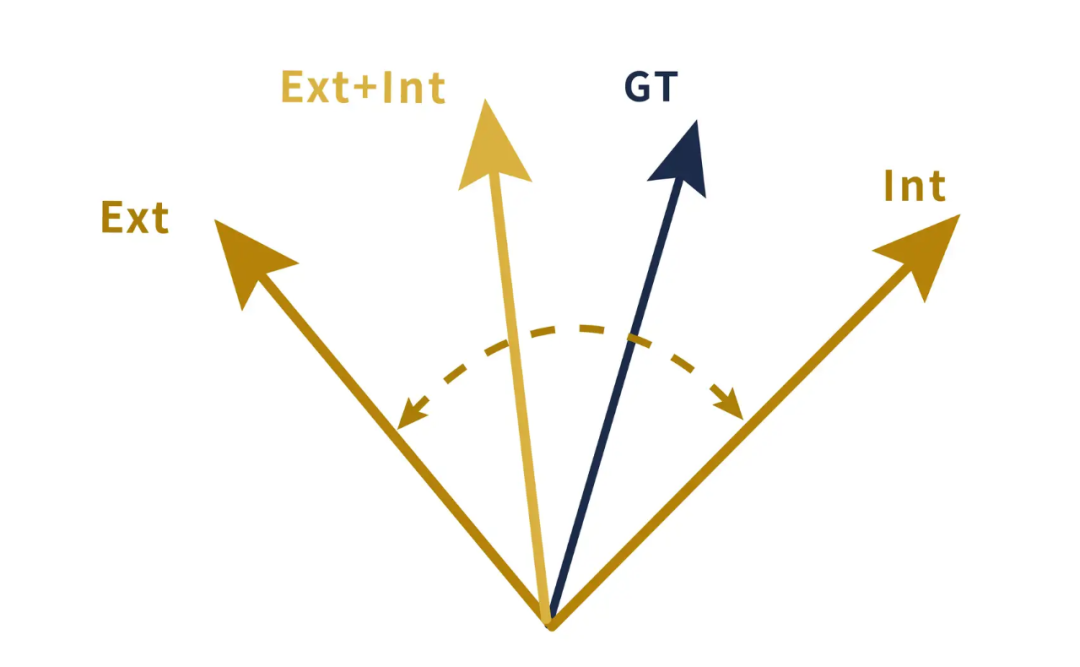
The answer: RAG aligns the model’s cognition with the Ground Truth by introducing external knowledge, thus allowing the model to output answers that conform to the ground truth.
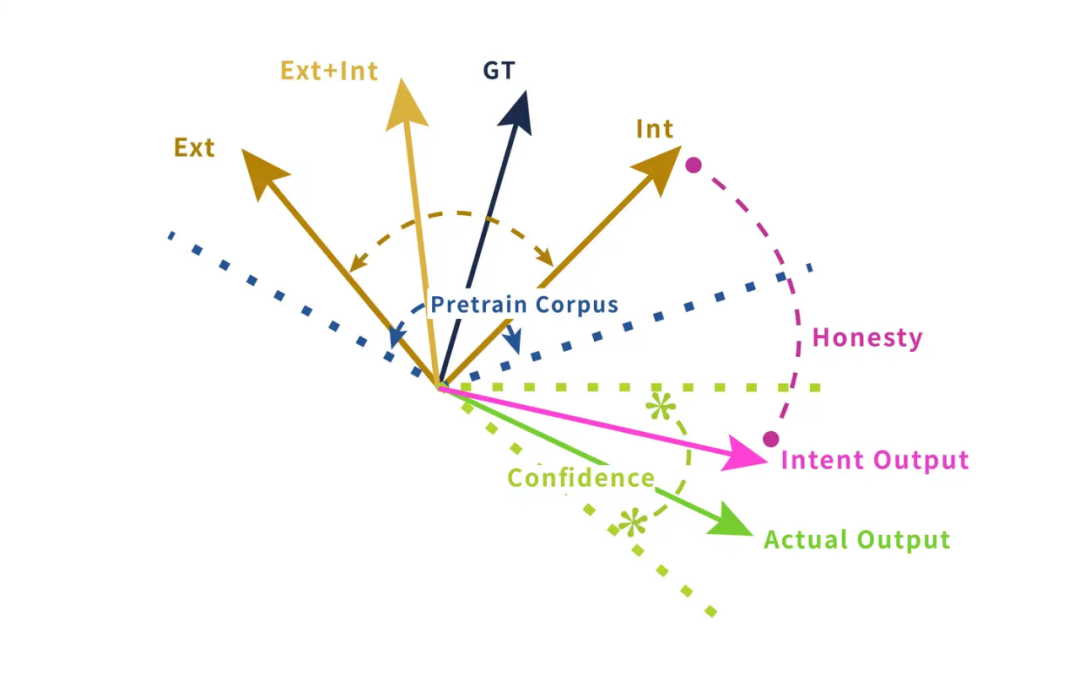
2.3 Limitations of Existing ARAG Methods
First, existing ARAG methods do not consider the situation where the LLM’s output does not align with its internal cognition. In such cases, various methods of judging the model’s confidence become ineffective.
Second, methods based on explicit model response feedback have some obvious drawbacks:
a. Methods based on the consistency of model outputs:
First, there is no good definition for the consistency of LLM outputs.
Secondly, these methods require the model to output many answers, greatly reducing efficiency [In actual RAG production, the retrieval time is very short (milliseconds), while the delay mainly occurs in the LLM decoding process].
b. Methods based on probability feedback:
This method first assumes that the LLM is well-calibrated (the logits of the model’s output layer represent its confidence), but in reality, LLMs are not well-calibrated. In other words, the probabilities of the model’s output tokens do not fully represent the model’s confidence.
Furthermore, this method cannot distinguish between cognitive uncertainty and incidental uncertainty [21].
-
Cognitive uncertainty: Uncertainty caused by unstable internal cognition, meaning the model does not know the answer to a question but cannot clearly state that it does not know.
-
Incidental uncertainty: The model may not be able to decode its intended output, or the same question may have multiple different answers.
c. Methods that involve fine-tuning or training an additional classifier:
This method is highly dependent on the quality of the data, and fine-tuning is costly and may impair the model’s capabilities. For example, the authors of Repoformer [22] pointed out that the strategy for choosing when to retrieve in Self-RAG may sometimes be as random as choosing randomly.
CtrlA
Paper Link:
https://arxiv.org/abs/2405.18727
Paper Code:
https://github.com/HSLiu-Initial/CtrlA
We designed Honesty probes and Confidence probes based on the model’s internal representations, which can represent the model’s cognition of honesty and confidence, respectively.
We first controlled the model using the Honesty probe to align the model’s internal cognition and intended output, and then used the Confidence probe to determine whether the model was confident in its answer at that time (Interestingly, we do not start from the uncertainty of the model’s answer but directly probe the model’s general confidence. In other words, we hope to probe the LLM’s cognition of confidence itself).
If there is no confidence, we will introduce retrieval.
Experiments show that our method can improve the accuracy of RAG without needing to process the retrieved documents further. In addition, compared to the extra costs of fine-tuning, our probe training only takes less than a minute and shows strong generalization.
3.1 Motivation
We hope to have a method that can align the LLM’s internal cognition and output, and after alignment, judge its “general” confidence. Thus, achieving that when the LLM is confident, it does not need to search, and when it is not confident, it retrieves.
3.2 Method
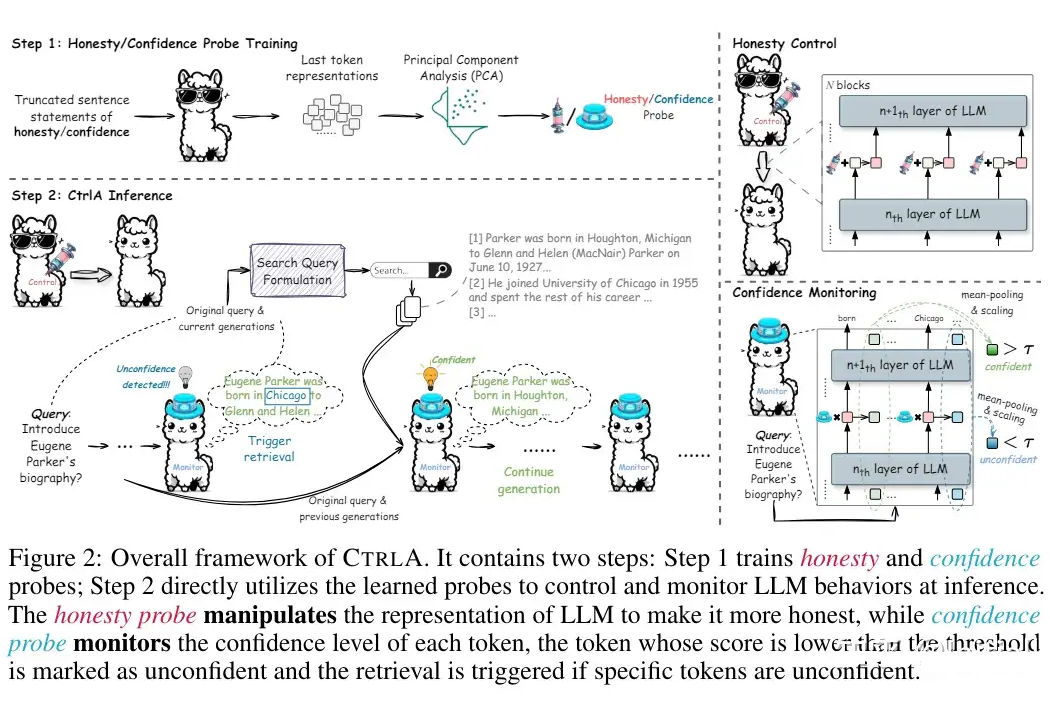
We extract the directions representing Honesty and Confidence from the internal representations of the LLM using RepE [23]. Next, we forcefully change the internal representations of the LLM to make it honest and probe the length (dot product) of the LLM’s internal representations in the confidence direction to determine the LLM’s confidence in its output. If it is not confident, we will introduce search.
3.3 Experimental Results
3.3.1 Main Results
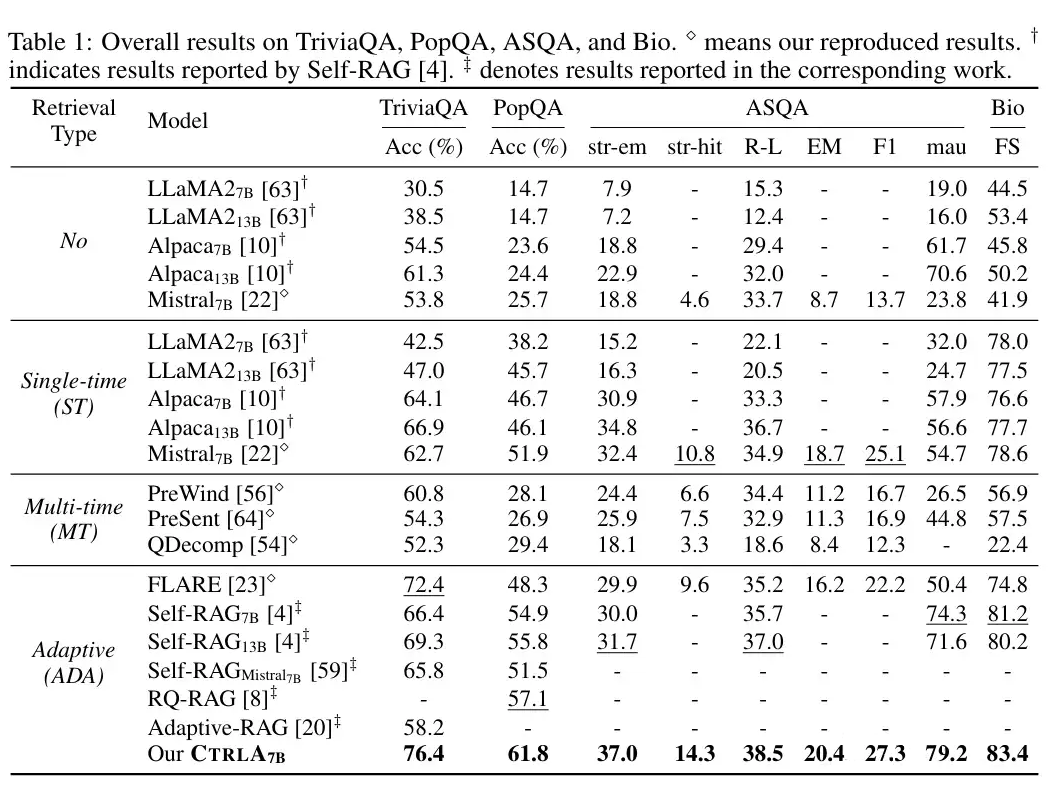
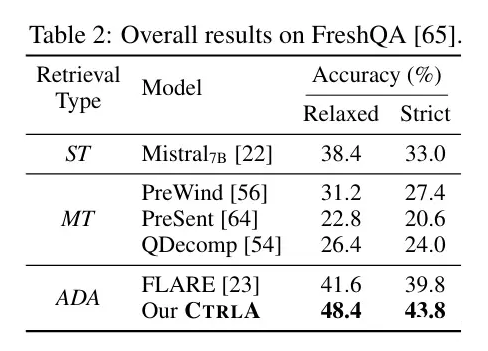
We have outperformed some existing ARAG methods across five datasets.
3.4 How Good is the Honesty Probe
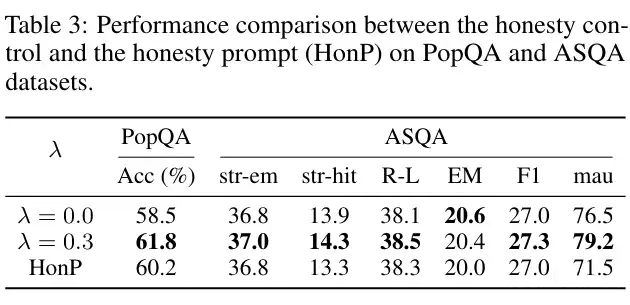
We conducted experiments using the Honesty probe in a setting without retrieval on TruthfulQA, and the Honesty probe improved the LLM’s performance on TruthfulQA.

We compared directly adding prompts to make the LLM honest and found that while it could improve results, the improvement was not as significant as controlling with the honesty probe.
3.5 How Good is the Confidence Probe
We used self-aware [24] and our constructed datasets to simulate questions that could make the model confident or unconfident and used the confidence probe to detect whether the model was confident. Specifically, unanswerable questions made the model unconfident, while simple, uncontroversial, and clear questions could make the LLM confident. The confidence probe showed high precision in identifying these questions.
On TriviaQA, the confidence probe identified questions with over 80% correctness, indicating that there was no need to search.
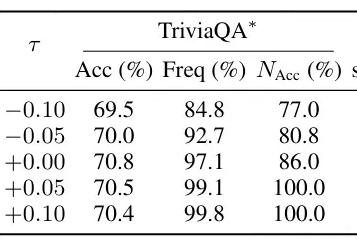
3.6 Some Examples
By using the Honesty probe, the LLM can admit its shortcomings (saying it does not know for unknown questions, stating no relevant information for irrelevant contexts).
Our backbone model is Mistral-7B v0.1, which was released before the Xiaomi SU7 and Huawei Wanjie M9, so it lacks relevant knowledge. The confidence probe identified that the model did not know the relevant information about these two cars.

The Honesty probe alleviates the model’s dishonesty (narrow lying).

The Confidence probe also identifies various situations of unconfidence.

The Confidence probe can also be used to control the model’s generation, and the effectiveness of this control demonstrates that we have indeed extracted the direction representing ‘confidence’ in the LLM’s representation space.

Scan the QR code to add the assistant’s WeChat
About Us
