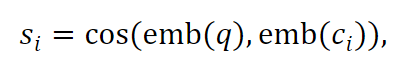MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, targeting NLP master’s and doctoral students, university professors, and researchers from enterprises.
The Vision of the Community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for beginners.
Reprinted from | New Intelligence Yuan
Not long ago, LLMs were still quite naive.
The knowledge in their minds was rather chaotic, and their context window length was also limited.
The emergence of Retrieval-Augmented Generation (RAG) significantly improved the performance of these models.
However, LLMs quickly became powerful, and the length of the context window rapidly expanded.
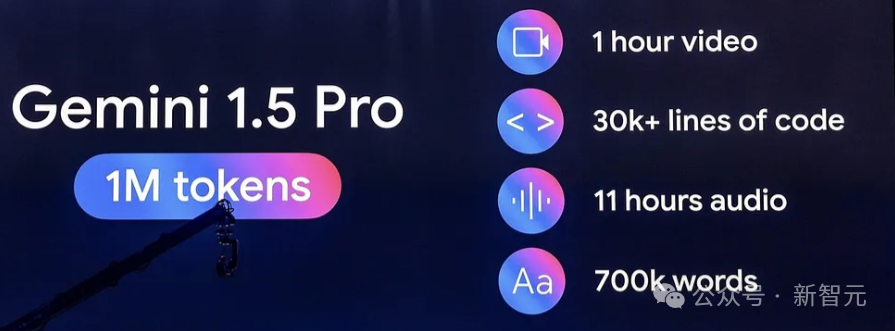
Current mainstream large models, such as GPT-4o, Claude-3.5, Llama3.1, Phi-3, and Mistral-Large2, support context lengths of up to 128K, with Gemini-1.5-pro even reaching 1M.
Thus, people cannot help but ask: In the era of long-context LLMs, is there still a need for RAG?
This question is reasonable; a previous study has proven that long context (LC) consistently outperforms RAG in terms of answer quality:
Paper link: https://www.arxiv.org/pdf/2407.16833
In this vibrant spring, will RAG truly fall out of favor?
Recently, researchers from NVIDIA re-examined this question and found that the order of retrieved blocks in LLM context is crucial for answer quality.
Traditional RAG arranges retrieved blocks in descending order of relevance, but this work shows that preserving the order of retrieved blocks from the original text can significantly improve the answer quality of RAG.
Paper link: https://arxiv.org/pdf/2409.01666
Thus, the researchers proposed an order-preserving mechanism — Order-Preserve RAG (OP-RAG).
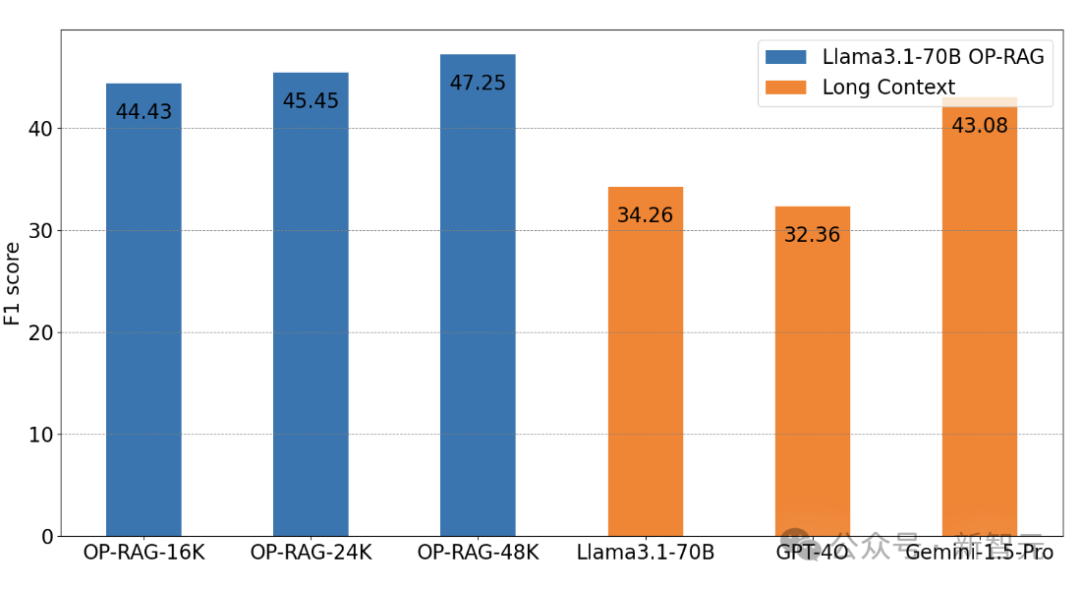
In experiments on the En.QA dataset, the OP-RAG method (Llama3.1-70B) achieved an F1-score of 44.43 using only 16K retrieved tokens.
In contrast, Llama3.1-70B without RAG, fully utilizing the 128K context, only achieved an F1-score of 34.32.
While GPT-4o and Gemini-1.5-Pro scored 32.36 and 43.08, respectively.
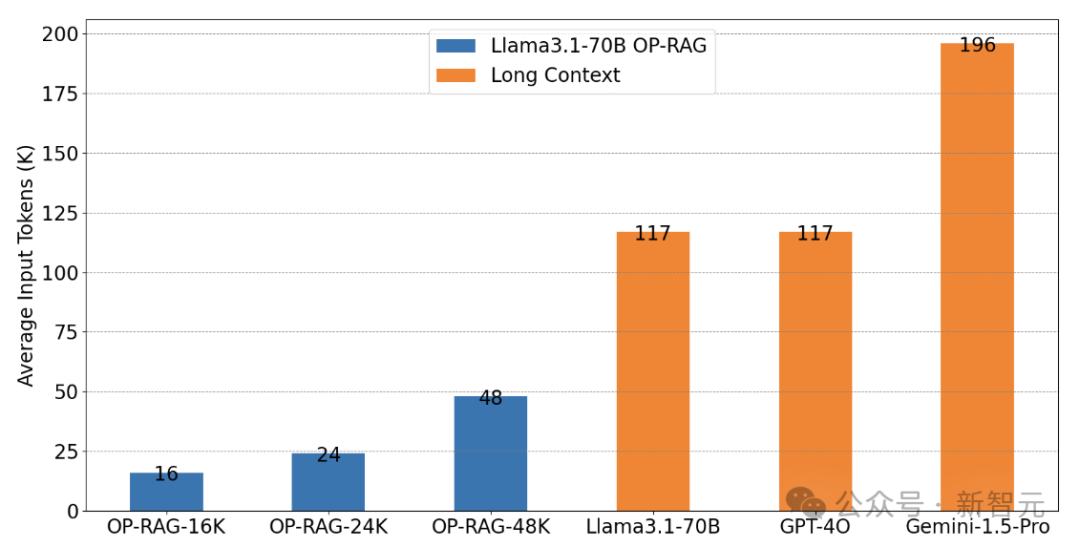
The above figure shows the average number of tokens input for each group of experiments, suggesting that OP-RAG achieves results beyond long context with minimal resource usage.
— this again proves the unique value of RAG.
Make RAG Great Again
RAG once helped early LLMs overcome the limitations of limited context by accessing the latest information, significantly reducing LLM hallucinations and improving factual accuracy.
Although long context research is gradually gaining favor, the authors argue that ultra-long context can lead to reduced attention to relevant information by LLMs, ultimately decreasing answer quality, while the OP-RAG proposed in this paper can achieve higher answer quality with fewer tokens.
OP-RAG
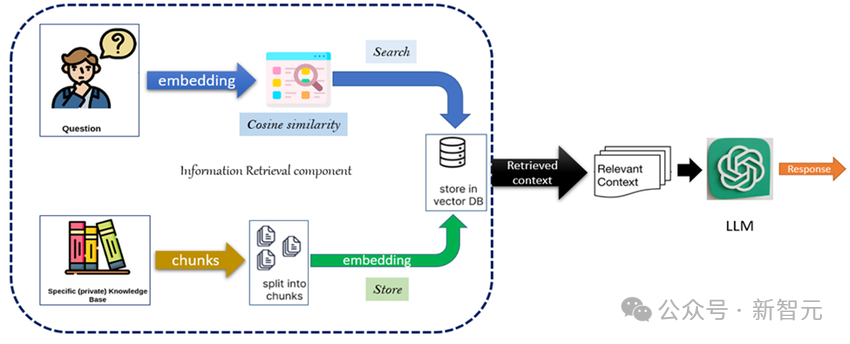
First, long context is represented as follows: split the long text d into N continuous and uniform blocks c, where ci represents the i-th block. Given a query q, the relevance score of ci blocks can be obtained (by calculating the cosine similarity between embeddings):
Retrieve the top k blocks with the highest similarity scores, but preserve the order of these blocks in the original long context d.
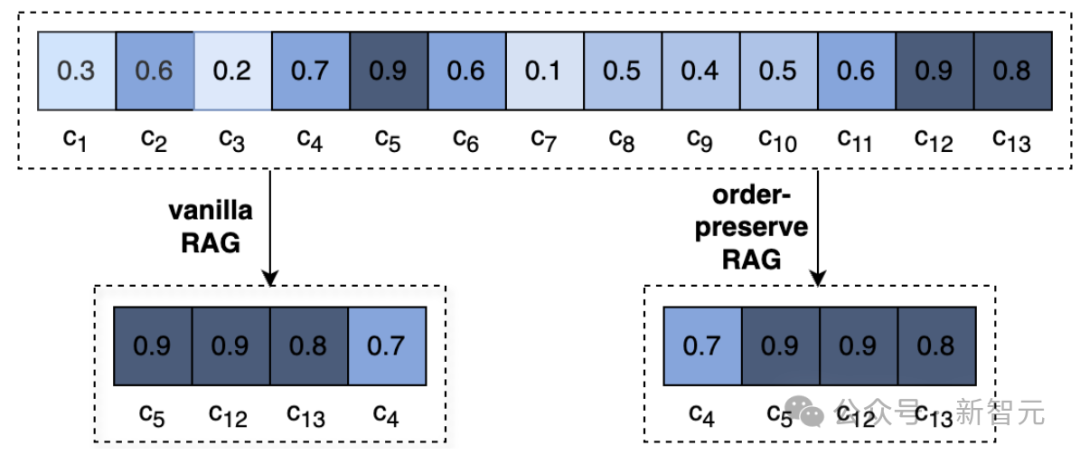
The above figure visually demonstrates the difference between ordinary RAG and OP-RAG: a long document is split into 13 blocks, and similarity scores are calculated.
Both retrieve the top 4 blocks with the highest similarity scores, but Vanilla RAG reorders them in descending order of scores, while OP-RAG preserves the relative order of the blocks.
Experimental Setup
The researchers chose the EN.QA and EN.MC datasets, designed specifically for long context QA evaluation, for their experiments.
EN.QA consists of 351 manually annotated Q&A pairs, where the long context averages 150,374 words; F1-score is used as the evaluation metric for EN.QA.
EN.MC consists of 224 Q&A pairs, with annotations similar to EN.QA, but each question provides four answer choices.
The long context in EN.MC averages 142,622 words; accuracy is used as the evaluation metric for EN.MC.
All datasets have a block size set to 128 tokens, with no overlap between blocks, and the default settings of BGE-large-en-v1.5 are used to obtain the embeddings for queries and blocks.
Ablation Study
The authors assessed the impact of context length on OP-RAG performance. In the experiment, each block contains 128 tokens, and the number of blocks retrieved for generating answers is 128.
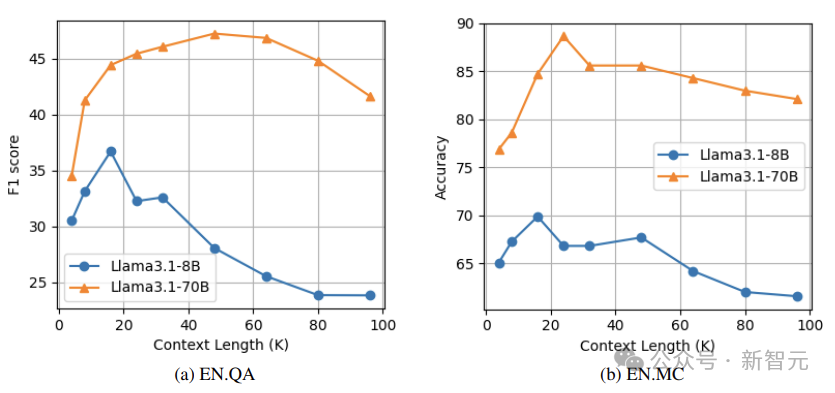
As shown in the figure below, performance initially improves with increasing context length. This is because more context may have a greater chance of covering relevant blocks.
However, as the context length further increases, answer quality decreases due to more irrelevant blocks causing interference.
In the experiment with the Llama3.1-8B model, the performance peaks at a context length of 16K on the EN.QA and EN.MC datasets, while the optimal performance point for the Llama3.1-70B model is 16K on EN.QA and 32K on EN.MC.
The peak point for Llama3.1-70B is later than that for Llama3.1-8B, possibly because the larger model has a stronger ability to distinguish between relevant blocks and irrelevant interference.
There are two insights here: first, a trade-off is needed between retrieving more context to improve recall and limiting interference to maintain accuracy;
second, introducing too much irrelevant information can reduce model performance, which is also a challenge faced by current long-context LLMs.
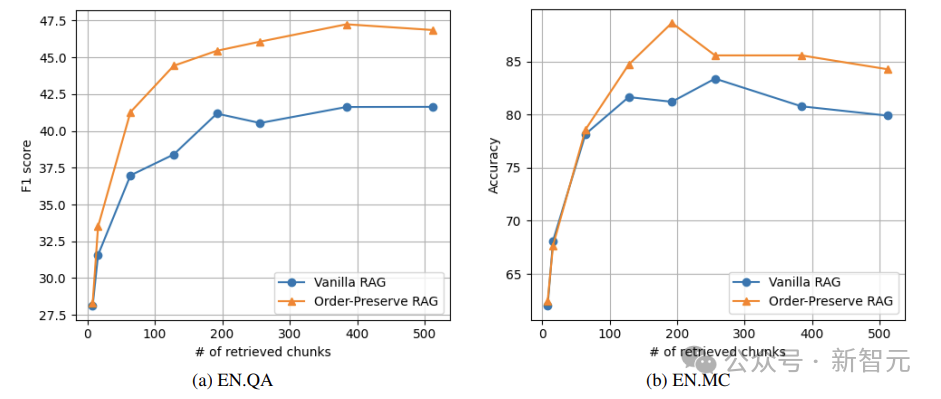
OP-RAG and Number of Retrieved Blocks
As shown in the figure below, when the number of retrieved blocks is small (e.g., 8), the proposed order-preserving RAG does not show significant advantages over ordinary RAG.
However, when the number of retrieved blocks is large, OP-RAG significantly outperforms ordinary RAG.
On the EN.QA dataset, when the number of retrieved blocks is 128, ordinary RAG only achieves an F1-score of 38.40, while OP-RAG achieves 44.43.
On the EN.MC dataset, with 192 retrieved blocks, ordinary RAG has an accuracy of 81.22, while OP-RAG reaches 88.65.
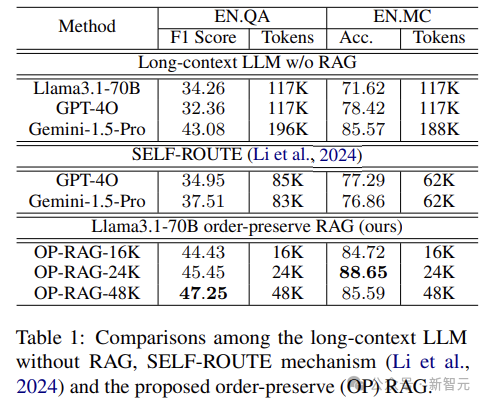
Experimental Results
The researchers compared OP-RAG with two types of baselines.
The first type of method uses long-context LLM without RAG. As shown in the table below, without RAG, LLMs require a large number of tokens as input, which is inefficient and costly.
In contrast, the proposed order-preserving RAG not only significantly reduces the number of tokens required but also improves answer quality.
For the Llama3.1-70B model, the method without RAG only achieves an F1-score of 34.26 on the EN.QA dataset, requiring an average of 117K tokens as input. In comparison, OP-RAG achieves a score of 47.25 with 48K tokens input.
The second type of baseline employs the SELF-ROUTE mechanism, which routes queries to RAG or long-context LLM based on the model’s self-reflection. As shown in the table above, the OP-RAG method significantly outperforms methods that use fewer tokens in LLM input.
https://arxiv.org/pdf/2409.01666
Technical Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant on WeChat
Please note: Name – School/Company – Research Direction
(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue System)
to apply to join technical groups such as Natural Language Processing/Pytorch
About Us
MLNLP community is a grassroots academic community built by machine learning and natural language processing scholars from home and abroad, which has developed into a well-known machine learning and natural language processing community, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing.
The community can provide an open communication platform for practitioners’ further education, employment, and research. We welcome everyone to follow and join us.