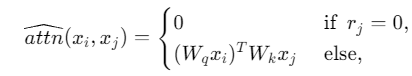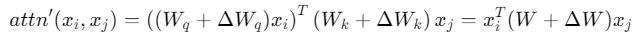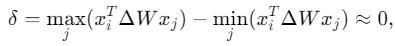MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, with an audience covering NLP graduate students, university teachers, and industry researchers.
The Vision of the Community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for the progress of beginners.
Reprinted from | Xinzhiyuan
In recent years, large language models have demonstrated outstanding capabilities across various tasks. However, due to a lack of factual information, current LLMs often exhibit severe hallucination phenomena; additionally, the knowledge in LLMs is encoded through their parameters, which means that integrating new knowledge requires further fine-tuning, consuming a large amount of time and computational resources. Therefore, enhancing LLM performance by combining external retrievers has become a mainstream solution.
Although RAG has been widely adopted in modern LLMs, a deep understanding of how RAG assists inference remains an unresolved issue. Currently, most researchers mainly view RAG as a method for providing domain-specific knowledge and often attempt to adapt LLMs to specific subfields through RAG. However, the impact of RAG on enhancing reasoning capabilities has not been thoroughly studied.
Recently, scholars from Renmin University of China pointed out that RAG can help LLMs enhance their reasoning abilities, but the improvement is limited, and due to noise in the retriever, RAG may even lead to a decline in reasoning capabilities.
Paper link: https://export.arxiv.org/abs/2410.02338
Background and Motivation
We can view LLMs as computing 𝑝(𝑦∣𝑞), where q represents the query, and 𝑦 is the corresponding answer.
In this case, retrieval-augmented generation (RAG) can be represented as 𝑝(𝑦∣𝑞,𝑑1,𝑑2,…,𝑑𝑘), where 𝑑𝑖 is the i-th document retrieved based on query 𝑞.
Additionally, the well-known prompt method “Chain of Thought” (CoT) significantly enhances the reasoning ability of LLMs, which can be expressed as 𝑝(𝑦∣𝑞,𝑥1,𝑥2,…,𝑥𝑘), where 𝑥𝑖 represents the results of step-by-step reasoning. Both CoT and RAG aim to incorporate additional information into the input to achieve better performance. It has been theoretically and experimentally proven that CoT can effectively enhance the reasoning ability of LLMs. The question is: can RAG also enhance the reasoning ability of LLMs?
Due to the limited number of layers in LLMs, their reasoning ability is constrained to a fixed depth. When conceptualizing the reasoning path as a tree, its maximum depth remains unchanged. Chain of Thought (CoT) generates answers through step-by-step reasoning or explanation rather than providing answers directly, which is formally expressed as 𝑥1=𝑓(𝑥), 𝑥2=𝑓(𝑥,𝑥1),…,𝑦=𝑓(𝑥,𝑥1,…,𝑥𝑘).
This process allows CoT to effectively expand reasoning depth by executing 𝑓 multiple times, potentially reaching infinite depth as the number of CoT steps increases.
In contrast, retrieval-augmented generation (RAG) does not support multiple reasoning; it retrieves existing relevant information to generate answers, thus cannot stack transformer layers.
Although RAG cannot enhance reasoning ability by stacking LLM layers, the retrieved documents may contain intermediate reasoning results, thereby reducing the number of layers required for reasoning, allowing LLMs to handle more complex questions and thus helping to enhance their reasoning capabilities.
Tree Structure of Reasoning
For a reasoning tree 𝑇 with 𝐿 layers, let the number of nodes at the 𝑖-th layer be 𝑛𝑖, and represent the 𝑗-th node at the 𝑖-th layer as 𝑢𝑖,𝑗. The relevant information contained in the retrieved document 𝑑 can be used to replace the content of certain reasoning nodes.
For example, consider the query “Who is the actor playing Jason on General Hospital?”.
In this case, there may be a node 𝑢𝑖,𝑗 that represents information about “what is General Hospital?” If we provide a document containing detailed information about “General Hospital,” then the computation of 𝑢𝑖,𝑗 can be effectively replaced by extracting relevant information from that document.
This document not only simplifies the computation of 𝑢𝑖,𝑗 but also eliminates all nodes connected only to 𝑢𝑖,𝑗. These nodes contribute only to the reasoning of 𝑢𝑖,𝑗; since the information of 𝑢𝑖,𝑗 can be directly derived from the document, their reasoning becomes unnecessary. Therefore, retrieving a single document relevant to node 𝑢𝑖,𝑗 may reduce the presence of multiple lower-layer nodes. This process is similar to the fission reaction in nuclear weapons, where reducing one node triggers the reduction of multiple other nodes.
Consequently, if all nodes at a certain layer 𝑙′ are simplified through the retrieval-augmented generation (RAG) method, any layer 𝑙≤𝑙′ can be eliminated, effectively reducing the overall reasoning depth.
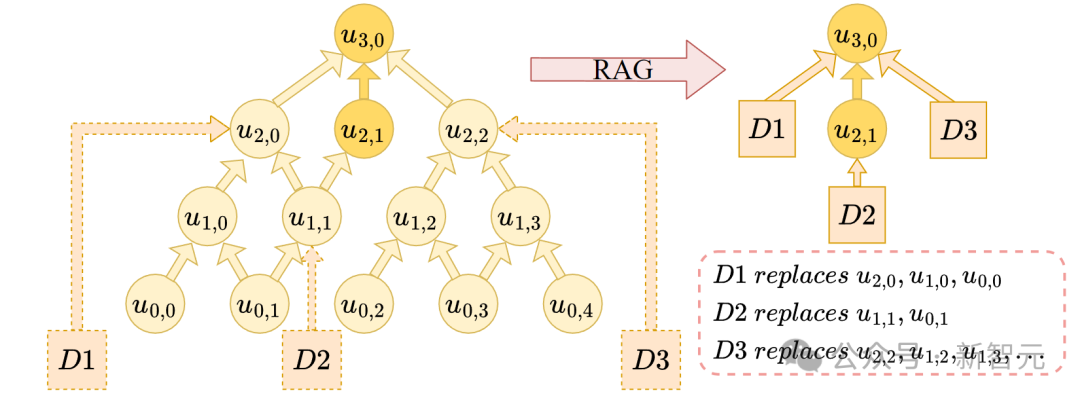
As shown in the figure above, the reasoning tree consists of 4 layers, and we have retrieved 3 documents 𝐷1, 𝐷2, 𝐷3, which provide information for nodes 𝑢2,0, 𝑢1,1, and 𝑢2,2 respectively.
Through document 𝐷1, node 𝑢1,0 can also be removed because it only contributes to 𝑢2,0; through document 𝐷2, 𝑢0,1 is no longer needed; and due to document 𝐷3, nodes 𝑢1,2 and 𝑢1,3 can also be removed.
Thus, all 4 nodes at the first layer can be eliminated through document information, meaning that all nodes at the first and zero layers are unnecessary. Consequently, the reasoning depth is reduced from 4 layers to 2 layers. Therefore, with the help of relevant documents, RAG can effectively reduce the reasoning complexity of the problem, enabling LLMs to tackle more complex questions.
We can observe that eliminating a single node significantly affects many nodes in shallower layers, similar to a fission reaction. If this fission process can expand indefinitely, RAG may significantly enhance the reasoning ability of LLMs.
However, if the fission reaction stops at a certain threshold, its effect may be limited. Therefore, to assess how many layers RAG can reduce, it is crucial to determine whether this fission-like process will terminate. Understanding this dynamic is essential for evaluating how RAG enhances reasoning capabilities and the overall efficiency of LLMs in solving complex problems.
Clearly, for layer 𝑙, the probability of the nodes at that layer being erased consists of two parts: one is that the reasoning of the upper layer nodes is no longer needed, and the other is that some document contains the information of that node, assuming that the probability of a document containing that node’s information is a constant 𝑝.
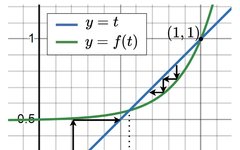
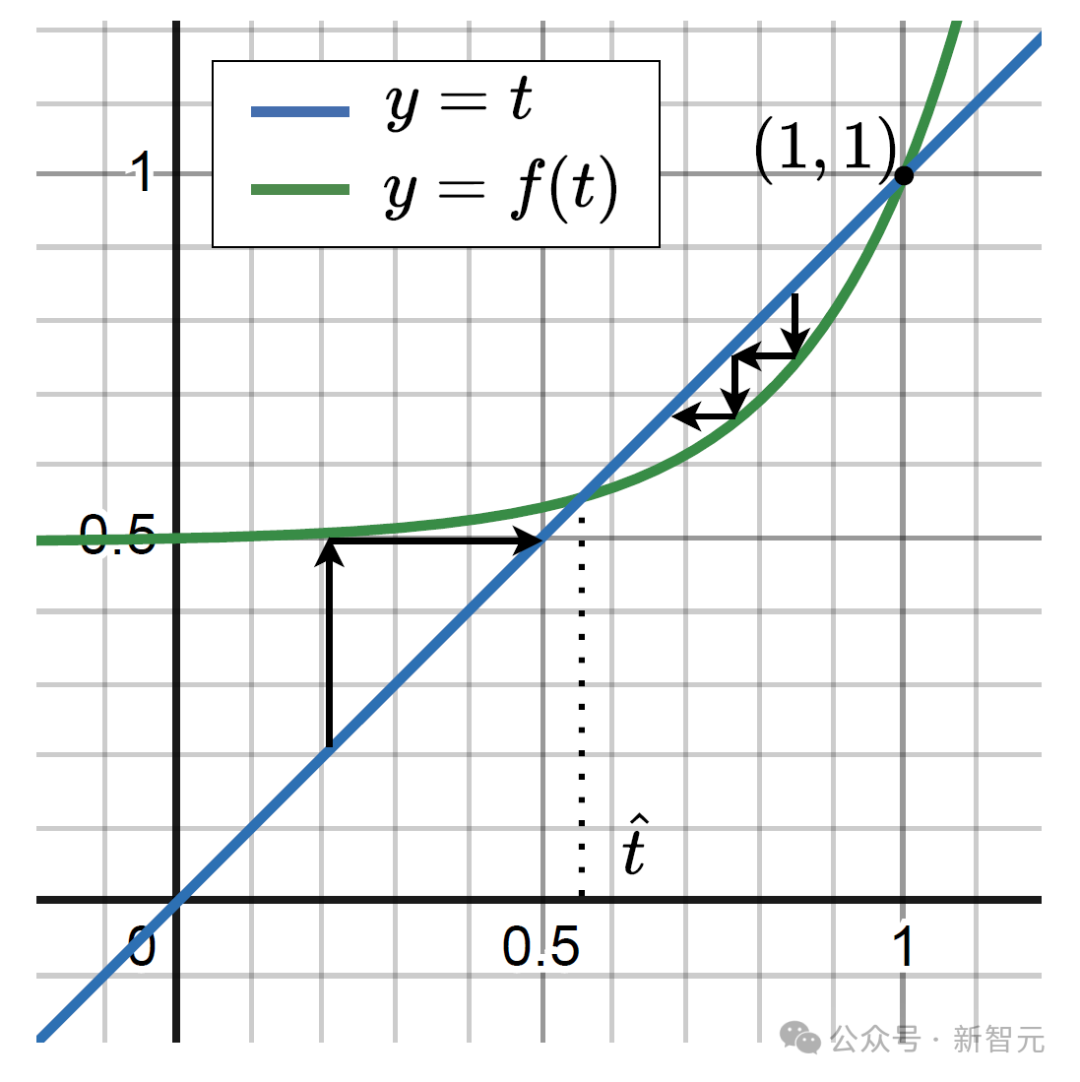
And if 𝑡𝑙+1% is eliminated in layer 𝑙+1, then the probability of the nodes at layer 𝑙 being eliminated can be expressed as 𝑡𝑙=𝑓(𝑡𝑙+1)=𝑓(𝑡).
Let 𝑔(𝑡)=𝑓(𝑡)−𝑡 represent the growth of layer 𝑙, and consider that there exists a point 𝑡^ in the interval (0,1) such that 𝑔(𝑡^)=0.
If at 𝑡>𝑡^, then 𝑔(𝑡)<0, indicating that the expected number of erased nodes will be less than in the previous layer, meaning that the fission reaction will not spread indefinitely but will reach a critical threshold. Beyond this point, the number of erased nodes in the next layer is expected to decrease compared to the current layer, thus limiting the expansion of the fission reaction.
As seen in the figure above, when 𝑡^ exists, the probability of nodes being erased gradually converges to 𝑡^, unable to expand indefinitely, while the position of 𝑡^ depends on the degree of connection between layers and the probability of a document containing the node’s information. When the connections between layers are sparse or the performance of the retriever is strong, it can make 𝑡^>1, thus the probability of nodes being erased converges to 1, allowing the erasure of an entire layer, thereby reducing the reasoning depth required for the problem, enabling LLMs to solve more complex problems.
Document Noise
However, in practical RAG scenarios, the information retrieved from documents is not always directly usable and often requires further processing because documents may contain noisy information, and some documents may even contain incorrect answers. This noise and distracting documents can negatively impact performance.
While some studies attempt to fine-tune models to filter noise and distracting documents, this approach causes LLMs to complete filtering before reasoning, reducing reasoning capability. Additionally, some studies train another filtering model, but this method incurs additional reasoning costs and cannot eliminate the inherent noise contained in the documents.
Thus, a critical question arises: is it difficult to filter out irrelevant documents, and can we effectively solve it within a limited number of layers? If the cost required to filter noise exceeds the benefits brought by RAG, then RAG will not enhance reasoning capabilities.
Let 𝑟 represent the relevance of tokens, where 𝑟𝑖=0 indicates that the i-th token 𝑥𝑖 is noise; otherwise, that token is relevant.
Let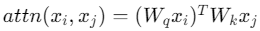 represent the original attention layer of the LLM. We assume the expected self-attention function is:
The fine-tuning of the model can be expressed as
where
represent the original attention layer of the LLM. We assume the expected self-attention function is:
The fine-tuning of the model can be expressed as
where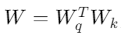 , ΔW represents the remaining terms.
In this case, if we need
, ΔW represents the remaining terms.
In this case, if we need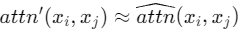 , we need for all relevant tokens 𝑥𝑗 that
Thus, for all relevant tokens, we need
, we need for all relevant tokens 𝑥𝑗 that
Thus, for all relevant tokens, we need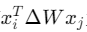 to be a constant, so that
to be a constant, so that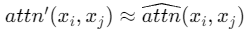 .
.
Triple-Wise Problem
For the input sequence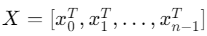 , 𝑟 represents the relevance of each token.
Specifically, for each token 𝑥𝑖, the relevance score 𝑟𝑖=0 indicates that the token is irrelevant to the query.
It should be noted that calculating 𝑟𝑖 does not solely depend on the token 𝑥𝑖 and the query; rather, it may require involving three or more tokens.
For example, suppose the input is “Alice is exhausted, but Bob is still very excited, showing no signs of fatigue. How does Bob feel?” The word “exhausted” is a noise token that should be excluded during reasoning.
However, determining the relevance of that token requires considering “Bob” from the query and “Alice” as the subject of “exhausted.” Thus, identifying a token’s relevance requires information from multiple tokens, while the self-attention mechanism only computes relationships pairwise, making it challenging to resolve this issue within a single transformer layer.
In retrieval-augmented generation (RAG) scenarios, we can simplify this triple-wise problem. By precomputing the information in the document and summarizing it as one or several additional tokens (virtual tokens), we can evaluate the relevance of tokens using only information from the tokens themselves, the query, and the virtual tokens. In this case, the triple-wise problem becomes a pair-wise problem.
When determining whether token 𝑥𝑖 is relevant, it is no longer necessary to traverse all input tokens 𝑥𝑗 to search for conflicts with the query; it suffices to traverse all virtual tokens.
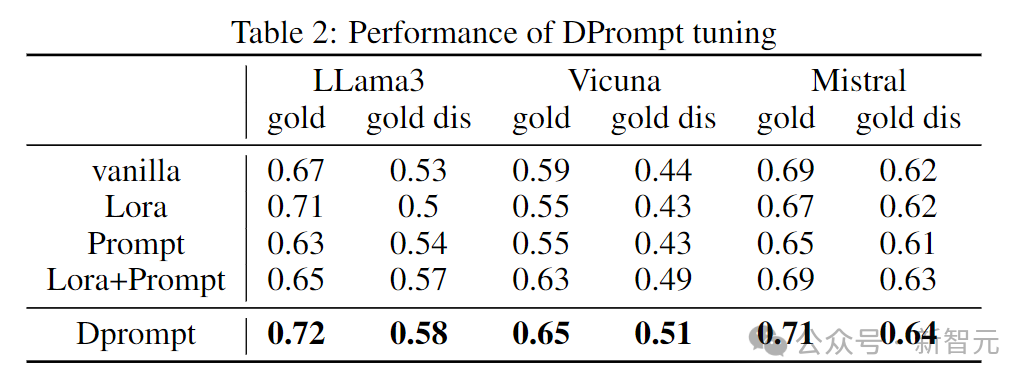
We fine-tune a BERT model to obtain representations of the documents and map them to appropriate dimensions through MLP, inserting them as virtual tokens into the model’s input prompt for fine-tuning. The experimental results are as follows:
Where gold represents a document containing only one document that directly includes the answer to the query, but there is still some noise in that document; gold dis represents a document containing both the gold document and distracting documents, where the distracting documents contain incorrect answers. As seen in the figure above, DPrompt tuning effectively enhances the performance of LLMs in the presence of noise.
https://arxiv.org/html/2410.02338v2
Technical Group Chat Invitation
, 𝑟 represents the relevance of each token.
Specifically, for each token 𝑥𝑖, the relevance score 𝑟𝑖=0 indicates that the token is irrelevant to the query.
It should be noted that calculating 𝑟𝑖 does not solely depend on the token 𝑥𝑖 and the query; rather, it may require involving three or more tokens.
For example, suppose the input is “Alice is exhausted, but Bob is still very excited, showing no signs of fatigue. How does Bob feel?” The word “exhausted” is a noise token that should be excluded during reasoning.
However, determining the relevance of that token requires considering “Bob” from the query and “Alice” as the subject of “exhausted.” Thus, identifying a token’s relevance requires information from multiple tokens, while the self-attention mechanism only computes relationships pairwise, making it challenging to resolve this issue within a single transformer layer.
In retrieval-augmented generation (RAG) scenarios, we can simplify this triple-wise problem. By precomputing the information in the document and summarizing it as one or several additional tokens (virtual tokens), we can evaluate the relevance of tokens using only information from the tokens themselves, the query, and the virtual tokens. In this case, the triple-wise problem becomes a pair-wise problem.
When determining whether token 𝑥𝑖 is relevant, it is no longer necessary to traverse all input tokens 𝑥𝑗 to search for conflicts with the query; it suffices to traverse all virtual tokens.
We fine-tune a BERT model to obtain representations of the documents and map them to appropriate dimensions through MLP, inserting them as virtual tokens into the model’s input prompt for fine-tuning. The experimental results are as follows:
Where gold represents a document containing only one document that directly includes the answer to the query, but there is still some noise in that document; gold dis represents a document containing both the gold document and distracting documents, where the distracting documents contain incorrect answers. As seen in the figure above, DPrompt tuning effectively enhances the performance of LLMs in the presence of noise.
https://arxiv.org/html/2410.02338v2
Technical Group Chat Invitation

△ Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction
(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)
to apply to join the Natural Language Processing/Pytorch and other technical group chats
About Us
MLNLP Community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from home and abroad. It has now developed into a well-known machine learning and natural language processing community, aiming to promote progress among the academic and industrial circles of machine learning and natural language processing.
The community can provide an open communication platform for relevant practitioners regarding further education, employment, and research. We welcome everyone to follow and join us.