

Source: AI Technology Review
This article is approximately 6625 words long and is recommended to be read in 10 minutes.
This article introduces a deep discussion by Professor Sun Maosong, Executive Vice Dean of the Institute of Artificial Intelligence at Tsinghua University, on the contributions, current state, and future challenges of natural language processing.
 Recently, Professor Sun Maosong, Executive Vice Dean of the Institute of Artificial Intelligence at Tsinghua University, penned a deep discussion on the contributions, current state, and future challenges of natural language processing.。
Recently, Professor Sun Maosong, Executive Vice Dean of the Institute of Artificial Intelligence at Tsinghua University, penned a deep discussion on the contributions, current state, and future challenges of natural language processing.。
The importance of human language (i.e., natural language) cannot be overstated. Edward O. Wilson, the father of sociobiology, once said, “Language is the greatest evolutionary achievement after eukaryotic cells.” James Gleick, the author of the popular science bestseller “The Information: A History, A Theory, A Flood,” profoundly pointed out: “Language itself is the greatest technological invention in human history.” These assertions carry a philosophical significance, reflecting the deepening understanding of the essence of language by modern humans.
It is well known that language is unique to humans, serving as the carrier of thought and the most natural, profound, and convenient tool for humans to communicate ideas and express emotions. The significance of these few “most” words is not trivial. Language to humans is like air to living beings; it permeates the world we live in silently and continuously. It is so natural that we often fail to realize its existence, but once it is gone, humanity will struggle to survive. Unfortunately, human language capability is precisely what modern computer systems lack, presenting a significant gap. An obvious logic is that machines without language capability cannot possess true intelligence.
Natural language has infinite semantic combinability, high ambiguity, and continuous evolution, making it “extremely difficult” for machines to achieve a complete understanding of natural language. Natural language understanding (a fallback term—natural language processing) attracts generations of scholars who exhaust their efforts and pursue it due to its unparalleled scientific significance and academic challenge.
01. Three Milestone Contributions of NLP to Global AI Development
“Yet looking back on the path I’ve taken, the verdant hills stretch endlessly.” The author believes that research in natural language processing (including text processing and speech processing, which complement each other) has made three milestone contributions that set the trend in the history of global artificial intelligence development. This is just a humble opinion and not necessarily accurate, merely to provoke thought.The First Milestone ContributionThe research of modern artificial intelligence technology originated from natural language processing. The obsession and exploration of machine intelligence have a long history. The emergence of the first general-purpose computer, ENIAC, in 1946 was undoubtedly a historical watershed. As early as 1947, Warren Weaver, then director of the Natural Sciences Division of the Rockefeller Foundation, discussed the possibility of using digital computers to translate human languages in a letter to Norbert Wiener, the father of cybernetics. In 1949, he published the famous “Translation” memorandum, formally proposing the task of machine translation and designing a scientifically rational development path (which actually encompasses two major research paradigms: rationalism and empiricism).In 1951, Israeli philosopher, linguist, and mathematician Yehoshua Bar-Hillel began machine translation research at MIT. In 1954, a machine translation experimental system developed by Georgetown University and IBM was publicly demonstrated. Machine translation is a typical cognitive task, clearly belonging to the field of artificial intelligence.The Second Milestone ContributionNatural language processing was one of the first fields to systematically practice the idea of unstructured “big data” in artificial intelligence and even the entire field of computer science and technology, overall achieving a transformation from the rationalist research paradigm to the empiricist research paradigm. Here are two typical works.The first is continuous speech recognition. Since the mid-1970s, the IBM research team led by the famous scholar Frederick Jelinek proposed a large vocabulary continuous speech recognition method based on the corpus n-gram language model (which is essentially an n-th order Markov model), significantly improving the performance of speech recognition. This idea had a profound impact on the field of speech recognition for about 20 years, even including the IBM statistical machine translation model launched in the 1990s, which reintroduced machine translation research back to the empiricist research paradigm suggested by Warren Weaver in 1949, fully demonstrating his foresight.The second is automatic part-of-speech tagging. In 1971, a scholar carefully designed a TAGGIT English part-of-speech tagging system, using 3,300 manually crafted context-sensitive rules, achieving a tagging accuracy of 77% on a million-word Brown corpus. Between 1983 and 1987, a research group at Lancaster University in the UK took a different approach, proposing a new data-driven method that did not require manual rules, utilizing the already tagged Brown corpus to construct the CLAWS English part-of-speech tagging system based on a hidden Markov model, achieving a tagging accuracy of 96% on the million-word LOB corpus.The Third Milestone ContributionThe current wave of artificial intelligence sweeping the globe originated from natural language processing. Between 2009 and 2010, the renowned scholar Geoffrey Hinton, in collaboration with Dr. Li Deng of Microsoft, first proposed a speech recognition method based on deep neural networks, breaking through nearly a decade of bottlenecks in speech recognition performance and taking it to a new level, allowing the academic community to initially experience the power of deep learning and increasing confidence, sweeping away doubts about deep learning frameworks. Subsequently, various research fields followed suit, rushing to keep up. In 2016, Google launched the deep neural network machine translation system GNMT, completely ending the IBM statistical machine translation model and opening a new chapter.Deep Learning-Based NLP: The Current Basic SituationSince 2010, deep learning has emerged rapidly, driving the comprehensive development of artificial intelligence.The result of 10 years of development is:On one hand, deep learning has transformed artificial intelligence technology from being nearly completely “unusable” to “usable,” achieving historically extraordinary progress;On the other hand, although it has significantly improved the performance of artificial intelligence systems across almost all classic tasks, the profound shortcomings inherent in deep learning methods have resulted in many application scenarios still not reaching the standards of “usable, manageable, and easy to use.” The field of natural language processing is largely the same; this article will not elaborate.On a macro level, the development of the artificial intelligence field has invariably benefited from two major types of methodological tools: Convolutional Neural Networks (CNN) for images, and Recurrent Neural Networks (RNN) for natural language text. Initially, the former was particularly prominent, while in recent years, the latter has made more significant contributions. Several major ideas influencing the global deep learning landscape, such as attention mechanisms, self-attention mechanisms, and the Transformer architecture, all originated from the latter. Deep learning-based natural language processing has undergone three splendid iterations of model frameworks in just 10 years, “traveling along the winding path, mountains and rivers reflect each other, leaving one in awe,” reaching three realms (which are also the three realms of deep learning).The First RealmFor each different natural language processing task, an independent set of manually annotated datasets is prepared, almost starting from scratch (often supplemented by word2vec word vectors), training a neural network model dedicated to that task.I call this characteristic “starting from scratch + each family sweeps their own snow.” The Second Realm First, based on a large-scale corpus, a large-scale pre-trained language model (PLM) is trained through self-learning and unsupervised learning; then, for each different natural language processing task (also known as downstream tasks at this point), an independent set of manually annotated datasets is prepared, using the PLM as a common support to train a lightweight fully connected feedforward neural network dedicated to that downstream task.In this process, the parameters of the PLM will be adaptively adjusted.I call this characteristic “pre-trained large model + size coordination.” The Third Realm First, based on an enormous corpus, a very large-scale PLM is trained through self-learning and unsupervised learning; then, for each different natural language processing downstream task, using the PLM as a common support, the task is completed through few-shot learning or prompt learning techniques. In this process, the parameters of the PLM are not adjusted (in fact, due to the enormous scale of the model, downstream tasks also lack the ability to adjust). I call this characteristic “pre-trained giant model + one giant supports many small ones.” These three realms are increasingly profound; each realm has more of a “metaphysical” feeling. The performance on the GLUE and SuperGLUE public evaluation sets is also progressively better (currently at the third realm). In recent years, a variety of talents in the global AI community have engaged in fierce competition around pre-trained language models, with model sizes rapidly expanding (for example, in June 2020, OpenAI launched the GPT-3 model with 175 billion parameters, and in October 2021, Microsoft and NVIDIA jointly launched the MT-NLG model, which soared to 530 billion parameters), creating a lively scene. In August 2021, Stanford University held a two-day academic seminar, naming the “pre-trained giant model” in the third realm as the “foundation model,” and subsequently published a lengthy paper outlining their views. The paper included a diagram (see Figure 1) revealing the central role of the “foundation model” in intelligent information processing (its scope has expanded to all data types and multimodalities).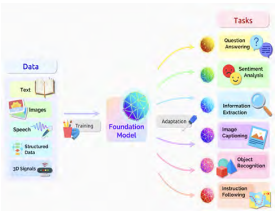 Figure 1 The Central Role of the “Foundation Model” in Intelligent Information ProcessingThere are many voices questioning the “foundation model.” For example, Turing Award winner Judea Pearl recently asked on Twitter: “What is the scientific principle that allows the ‘foundation model’ to bypass the theoretical limitations of data-centric methods?”However, regardless, the “foundation model” has established its important position as a public foundational “soft” infrastructure for intelligent information processing.The first realm is akin to each family building houses on a beach with an elevation of nearly zero, where everyone can only build their own foundation, brick by brick, making it laborious and inefficient; The second realm, however, builds a common platform at an elevation of 20-30 meters, allowing families to build houses on this platform, significantly reducing the need to lay their own foundations and greatly improving efficiency. However, due to the platform’s insufficient height, the foundation may not be reliable everywhere, so families still need to consider the platform situation and appropriately compact and adjust it; The third realm raises the public platform to 200-300 meters, with a solid foundation. Even if a simple gazebo is built, the view will be delightful. Families need to worry less about various factors, and efficiency can be further improved.This is an illustrative explanation of my positioning of the “foundation model.”Let us take the Baidu Wenxin NLP large model (https://wenxin.baidu.com/wenxin/ernie) with a parameter scale of hundreds of billions as an example to initially experience the large model. First, let’s briefly examine its “free creative” function. Input a sentence like this and let the machine continue writing:As I walked along the winding path, I saw The machine’s continuation is quite impressive: a person, with a few tall ginkgo trees and some unknown flowers blooming brilliantly in the sunlight, and occasionally two small birds can be seen.Using the same input, let the machine continue writing another paragraph: anyone, yet a small village quietly stands there. This is Qianshiwu Village in Yufa Town, Daxing District, with about 300 households and over 800 people. Now, the countryside has become one of the main sources of life for many families. We not only have good food and clothing, but also many beautiful and exciting programs!This passage, while smooth, has some strange developments in its narrative flow.Next, let’s examine its “free Q&A” function. The question is:What is the highest mountain in Shandong?The machine answers: Mount Tai.Rephrasing the question: Which is the tallest mountain in Shandong? The machine replies: Mount Tai! Considering this is a generative response, the machine does quite well. However, if the same question is asked multiple times, the machine becomes “confused” and gives random answers: Mount Laoshan in Qingdao. This should not be thought of as Wulian Mountain, which has an elevation of 1,095 metersin Jinan. This indicates that the large model has considerable broad knowledge capability but lacks precision and self-awareness, making it vulnerable to semantic logic attacks or difficulties. Turning back to examine its “free creative” function. Input: As I walked along the crowded winding path, I saw The machine continues: anyone; is there another life presence here? Everything I see along the way are dead trees and fallen grass. Yet they do not notice the lush valley behind them! “So beautiful~” she lightly jumped in the air, looking at the busy crowd below and exclaimed. Hearing this, Mo Yunshang also stopped his work and turned to look, only to see that the forest in the distance was filled withFrom the above examples, it can be seen that the large model has obvious strengths but also significant weaknesses. It is like a platform with a certain elevation, making it relatively convenient to build houses, but it does not mean that the houses are already complete.In fact, to build a truly “usable, manageable, and easy to use” house on it, considerable effort is still required.03. The Confusions and Reflections Brought by the Third Realm:The Main Challenges Facing NLP in the Coming YearsI believe that natural language processing will face two major challenges in the coming years.The First Challenge: Is Might Right?This follows the current basic trend, where the “foundation model” naturally extends forward. While this path continues to advance vigorously, the “foundation model” itself clearly cannot solve deep semantic issues; in other words, it is destined not to directly lead to general artificial intelligence (although it will certainly be a foundational component of the envisioned general artificial intelligence). Thus, a naturally arising question emerges: How far can this strategy of pursuing extreme scale (data, models, computing power) go? Another related question is, what should we do?I think we can answer this from the two angles of the development (exploitation) and exploration of the “foundation model.” Development (exploitation) focuses more on the engineering aspect of the “foundation model,” and several points should be noted.
Figure 1 The Central Role of the “Foundation Model” in Intelligent Information ProcessingThere are many voices questioning the “foundation model.” For example, Turing Award winner Judea Pearl recently asked on Twitter: “What is the scientific principle that allows the ‘foundation model’ to bypass the theoretical limitations of data-centric methods?”However, regardless, the “foundation model” has established its important position as a public foundational “soft” infrastructure for intelligent information processing.The first realm is akin to each family building houses on a beach with an elevation of nearly zero, where everyone can only build their own foundation, brick by brick, making it laborious and inefficient; The second realm, however, builds a common platform at an elevation of 20-30 meters, allowing families to build houses on this platform, significantly reducing the need to lay their own foundations and greatly improving efficiency. However, due to the platform’s insufficient height, the foundation may not be reliable everywhere, so families still need to consider the platform situation and appropriately compact and adjust it; The third realm raises the public platform to 200-300 meters, with a solid foundation. Even if a simple gazebo is built, the view will be delightful. Families need to worry less about various factors, and efficiency can be further improved.This is an illustrative explanation of my positioning of the “foundation model.”Let us take the Baidu Wenxin NLP large model (https://wenxin.baidu.com/wenxin/ernie) with a parameter scale of hundreds of billions as an example to initially experience the large model. First, let’s briefly examine its “free creative” function. Input a sentence like this and let the machine continue writing:As I walked along the winding path, I saw The machine’s continuation is quite impressive: a person, with a few tall ginkgo trees and some unknown flowers blooming brilliantly in the sunlight, and occasionally two small birds can be seen.Using the same input, let the machine continue writing another paragraph: anyone, yet a small village quietly stands there. This is Qianshiwu Village in Yufa Town, Daxing District, with about 300 households and over 800 people. Now, the countryside has become one of the main sources of life for many families. We not only have good food and clothing, but also many beautiful and exciting programs!This passage, while smooth, has some strange developments in its narrative flow.Next, let’s examine its “free Q&A” function. The question is:What is the highest mountain in Shandong?The machine answers: Mount Tai.Rephrasing the question: Which is the tallest mountain in Shandong? The machine replies: Mount Tai! Considering this is a generative response, the machine does quite well. However, if the same question is asked multiple times, the machine becomes “confused” and gives random answers: Mount Laoshan in Qingdao. This should not be thought of as Wulian Mountain, which has an elevation of 1,095 metersin Jinan. This indicates that the large model has considerable broad knowledge capability but lacks precision and self-awareness, making it vulnerable to semantic logic attacks or difficulties. Turning back to examine its “free creative” function. Input: As I walked along the crowded winding path, I saw The machine continues: anyone; is there another life presence here? Everything I see along the way are dead trees and fallen grass. Yet they do not notice the lush valley behind them! “So beautiful~” she lightly jumped in the air, looking at the busy crowd below and exclaimed. Hearing this, Mo Yunshang also stopped his work and turned to look, only to see that the forest in the distance was filled withFrom the above examples, it can be seen that the large model has obvious strengths but also significant weaknesses. It is like a platform with a certain elevation, making it relatively convenient to build houses, but it does not mean that the houses are already complete.In fact, to build a truly “usable, manageable, and easy to use” house on it, considerable effort is still required.03. The Confusions and Reflections Brought by the Third Realm:The Main Challenges Facing NLP in the Coming YearsI believe that natural language processing will face two major challenges in the coming years.The First Challenge: Is Might Right?This follows the current basic trend, where the “foundation model” naturally extends forward. While this path continues to advance vigorously, the “foundation model” itself clearly cannot solve deep semantic issues; in other words, it is destined not to directly lead to general artificial intelligence (although it will certainly be a foundational component of the envisioned general artificial intelligence). Thus, a naturally arising question emerges: How far can this strategy of pursuing extreme scale (data, models, computing power) go? Another related question is, what should we do?I think we can answer this from the two angles of the development (exploitation) and exploration of the “foundation model.” Development (exploitation) focuses more on the engineering aspect of the “foundation model,” and several points should be noted.
-
The algorithms currently used to construct and utilize the “foundation model” are still relatively crude. The “issues” observed in the performance of the Baidu Wenxin NLP large model mentioned earlier can hopefully be partially resolved through active algorithm improvements.
-
Research and development of new techniques such as few-shot learning, prompt learning, and adapter-based learning that complement the “foundation model” should be strengthened.
-
Is it really good to have training data that encompasses everything? Should we filter out the significant noise present in big data?
-
Rankings are undoubtedly important for model development. However, rankings are not the only gold standard; application is the ultimate gold standard.
-
Companies developing the “foundation model” should not “praise their own products”; they need to open it up for academic testing. The performance of a “foundation model” that is not open to academic testing is questionable. The academic community should not blindly trust or follow.
-
“Foundation models” urgently need to find killer applications to convincingly demonstrate their capabilities.
Exploration (exploration) focuses more on the scientific nature of the “foundation model.” Given that the “foundation model” indeed presents some astonishing (or “strange”) phenomena that currently lack scientific explanations. Typical examples include:
-
Why do large-scale pre-trained language models exhibit the deep double descent phenomenon (this seems to transcend the golden rule of machine learning that “data complexity and model complexity should generally match”)?
-
Why do “foundation models” possess few-shot learning or even zero-shot learning capabilities? How are these capabilities acquired? Do complex emergent phenomena occur within these huge systems?
-
Why does prompt learning work? Does this suggest that the “foundation model” may spontaneously generate several functional partitions, and each prompt learning provides a key to activate each functional partition?
-
If so, what might the distribution of these functional partitions look like? Given that the core training algorithm of the “foundation model” is extremely simple (language models or fill-in-the-blank models), what profound implications does this have?
I personally believe that the exploration of the scientific significance of the “foundation model” may outweigh its engineering significance. If it indeed contains the aforementioned mysteries, it will profoundly inspire the new development of artificial intelligence models, and the “foundation model” may usher in a new atmosphere of “after the mountains and rivers, there is another village ahead.” Additionally, it may also be enlightening for brain science and cognitive neuroscience research.The Second Challenge: Is Intelligence Supreme?This is the “original intention” and eternal dream of artificial intelligence, which is quite different from the first challenge’s approach, but its necessity is beyond doubt. Here’s an example to illustrate.The aforementioned pioneer of machine translation, Yehoshua Bar-Hillel, published a long article in 1960 titled “The Current State of Language Automatic Translation,” forecasting the future of machine translation. In this article, he presented a sentence that is easy for humans but exceptionally challenging for machine translation (note the dual meanings of the word “pen”): Little John was looking for his toy box. Finally, he found it. The box was in the pen. John was very happy. In this sentence, “pen” has two meanings: “fountain pen” and “fence.” To correctly translate it as “fence,” the machine needs to understand the meaning of the preposition “in” and possess relevant world knowledge. We present this simple English sentence to a machine translation system armed with deep neural networks and big data.The results from Google Translate: The box is in the pen. The results from Baidu Translate: The box is in the fountain pen. Over 60 years have passed, and it still hasn’t been resolved.Fortunately, amidst the grand momentum of the “might is right” trend, a group of scholars still insist on and actively advocate the next generation of artificial intelligence development concepts focusing on small data, rich knowledge, and causal reasoning, known as “intelligence is supreme.” However, progress in this area has been limited. There are two major “roadblocks” on this path.One is the serious lack of formal knowledge bases and world knowledge bases. Knowledge graphs like Wikidata seem to be vast, but a closer examination reveals that their coverage of knowledge is still quite limited. In fact, Wikidata has significant compositional deficiencies, primarily containing static attribute knowledge about entities, with almost no formal descriptions of actions, behaviors, states, and event logical relationships. This severely restricts its scope and significantly reduces its practical effectiveness.The second is the serious lack of systematic capabilities to obtain formal knowledge such as “actions, behaviors, states, and event logical relationships”. Conducting large-scale syntactic and semantic analysis on open texts (like Wikipedia texts) is essential. Unfortunately, this syntactic and semantic capability is still lacking (although there has been significant progress in recent years through deep learning methods).These two “roadblocks” must be addressed. Otherwise, it will be difficult to proceed on this path.The aforementioned two major challenges are also what the entire field of artificial intelligence must confront.04. ConclusionNatural language processing has come a long way to today, forming two paths: “might is right” and “intelligence is supreme.” The former is broad, moving with the wind, but seems to be nearing its end; the latter is narrow, going against the wind, but should be enduring and profound. In the future, both can coexist harmoniously, learn from each other, and support one another, as the “foundation model” is expected to effectively enhance the ability of large-scale syntactic and semantic automatic analysis, thereby providing the necessary conditions for large-scale automatic knowledge acquisition. The “foundation model” may conceal some profound computational principles or secrets, potentially leading to significant “turnarounds,” warranting close attention. In the next decade, it is anticipated that natural language processing will create a grand pattern in research and application overall and make critical contributions to the development of the field of artificial intelligence.——END——