

Introduction
Convolutional Neural Networks (CNN) are one of the most important and widely used models in the field of deep learning. Since their introduction in the 1980s, CNNs have achieved significant success in areas such as image processing, computer vision, and natural language processing. This article aims to review the basic principles, development history, main applications, and future research directions of CNNs, citing relevant literature to support the discussion.
1. Basic Principles of CNN
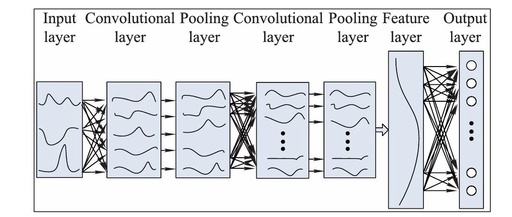
CNN is a type of neural network specifically designed to process data with a grid-like structure (such as images). Its core idea is to extract local features through convolution operations and reduce data dimensions through pooling operations, thereby achieving efficient learning of complex patterns.
1.1 Convolutional Layer
The convolutional layer is the core component of CNN. It slides convolutional kernels (filters) over the input data to extract local features. Each convolutional kernel can learn different features, such as edges and textures. Mathematically, the convolution operation can be represented as:
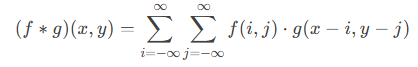
1.2 Pooling Layer
The pooling layer is used to reduce the spatial dimensions of the data, decrease the computational load, and prevent overfitting. Common pooling operations include Max Pooling and Average Pooling. Max Pooling selects the maximum value from local regions, while Average Pooling calculates the average value of local regions.
1.3 Fully Connected Layer
The fully connected layer is typically located at the end of the CNN and is used to map the extracted features to the final output categories. Each neuron is connected to all neurons in the previous layer, achieving classification or regression tasks through learned weights and biases.
2. Development History of CNN
The development of CNN has gone through several important stages. Here are some key milestones:
2.1 LeNet-5
LeNet-5, proposed by Yann LeCun et al. in 1998, is a CNN model for handwritten digit recognition. It was the first CNN to be successfully applied to a practical problem, laying the foundation for modern CNNs (LeCun et al., 1998).
2.2 AlexNet
AlexNet, proposed by Alex Krizhevsky et al. in 2012, achieved breakthrough results in the ImageNet image classification competition. AlexNet introduced techniques such as the ReLU activation function, Dropout, and data augmentation, significantly improving CNN performance (Krizhevsky et al., 2012).
2.3 VGGNet
VGGNet, proposed by the Visual Geometry Group at the University of Oxford, further improved image classification accuracy by using deeper network structures and smaller convolutional kernels (3×3) (Simonyan & Zisserman, 2014).
2.4 ResNet
ResNet (Residual Network), proposed by Kaiming He et al. in 2015, introduced residual connections to solve the gradient vanishing problem in deep networks, allowing for deeper training of networks (He et al., 2016).
3. Main Applications of CNN
CNNs have achieved widespread applications in various fields; here are some typical applications:
3.1 Image Classification
Image classification is one of the most classic applications of CNNs. By training CNN models, automatic classification of objects in images can be achieved. For example, many winning models in the ImageNet competition are based on CNNs (Russakovsky et al., 2015).
3.2 Object Detection
Object detection not only requires recognizing objects in images but also locating their positions. Models such as Faster R-CNN, YOLO, and SSD are CNN-based object detection algorithms (Ren et al., 2015; Redmon et al., 2016; Liu et al., 2016).
3.3 Semantic Segmentation
Semantic segmentation involves classifying each pixel in an image into specific categories. U-Net and FCN (Fully Convolutional Network) are commonly used semantic segmentation models (Ronneberger et al., 2015; Long et al., 2015).
3.4 Natural Language Processing
Although CNNs were originally designed for image processing, they have also achieved success in natural language processing (NLP). For example, CNNs can be used for text classification, sentiment analysis, and machine translation (Kim, 2014).
4. Future Research Directions
Despite the excellent performance of CNNs in many tasks, there are still many challenges and future research directions:
4.1 Model Compression and Acceleration
As the depth and complexity of CNN models increase, the computational resources and storage requirements also rise. Model compression and acceleration techniques (such as pruning, quantization, and knowledge distillation) are current research hotspots (Han et al., 2015).
4.2 Self-Supervised Learning
Self-supervised learning reduces reliance on large amounts of labeled data by utilizing unlabeled data for pre-training. In the future, self-supervised learning is expected to play a greater role in CNNs (Jing & Tian, 2020).
4.3 Cross-Modal Learning
Cross-modal learning aims to combine information from different modalities (such as images and text) to accomplish more complex tasks. For example, image caption generation and visual question answering systems (VQA) are applications of cross-modal learning (Antol et al., 2015).
Conclusion
Convolutional Neural Networks (CNN) are an important component of deep learning and have achieved significant success in various fields. From LeNet-5 to ResNet, the development history of CNN demonstrates its powerful capabilities in image processing, computer vision, and natural language processing. In the future, with the development of technologies such as model compression, self-supervised learning, and cross-modal learning, CNNs will continue to play a significant role in the field of artificial intelligence.
References
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 1097-1105.
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, 770-778.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., … & Fei-Fei, L. (2015). ImageNet large scale visual recognition challenge. International journal of computer vision, 115(3), 211-252.
Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 91-99.
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE conference on computer vision and pattern recognition, 779-788.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016). SSD: Single shot multibox detector. European conference on computer vision, 21-37.
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional networks for biomedical image segmentation. International Conference on Medical image computing and computer-assisted intervention, 234-241.
Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. Proceedings of the IEEE conference on computer vision and pattern recognition, 3431-3440.
Kim, Y. (2014). Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882.
Han, S., Pool, J., Tran, J., & Dally, W. (2015). Learning both weights and connections for efficient neural network. Advances in neural information processing systems, 28, 1135-1143.
Jing, L., & Tian, Y. (2020). Self-supervised visual feature learning with deep neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11), 4037-4058.
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Lawrence Zitnick, C., & Parikh, D. (2015). VQA: Visual question answering. Proceedings of the IEEE international conference on computer vision, 2425-2433.