
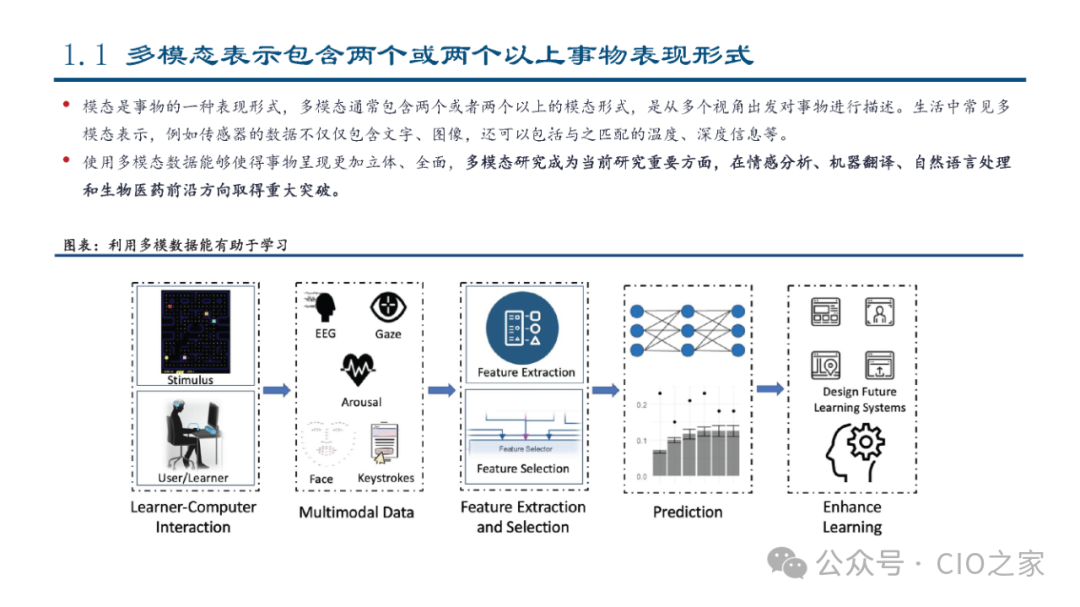
“Multimodal” refers to the ability to simultaneously process and understand various types of information or data. In the field of artificial intelligence, modality typically refers to the representation or perception of information, such as text, images, audio, and video. For example, humans perceive the world through multiple senses, including sight, hearing, and touch, which is known as multimodal perception. In AI, multimodal learning aims to integrate data from different modalities to enhance the model’s perception and understanding capabilities. Visual question-answering tasks require models to simultaneously comprehend both image and text information to answer questions about the image content.The key advantage of multimodal technology lies in its ability to provide more comprehensive information processing capabilities, enhancing system robustness and user interaction experience. By integrating multiple information sources, multimodal systems can better understand complex scenes and user needs, thus playing an important role in various applications.
The Relationship Between Multimodal and Large Models
Multimodal Large Models (MLLMs) refer to large AI models capable of processing and understanding information from multiple modalities. These models typically consist of billions to trillions of parameters, specifically designed to handle various types of data inputs such as text, images, audio, and video. By training on large multimodal datasets, MLLMs can jointly understand and generate information across different modalities, demonstrating exceptional performance in tasks like visual question-answering, image captioning, and video analysis.
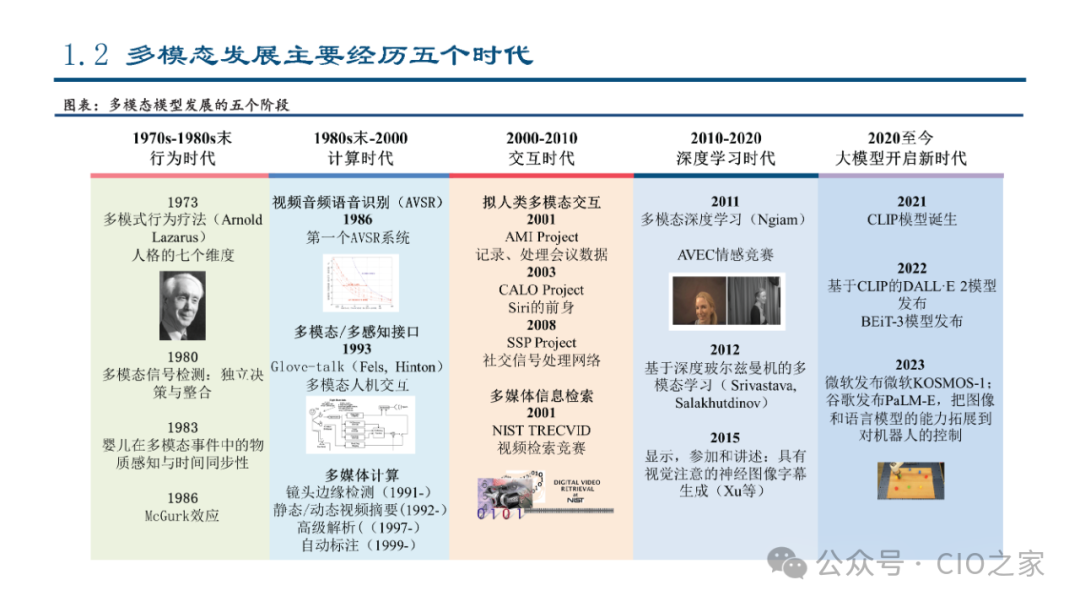
Development Stages of Multimodal Technology
-
Initial Integration Stage: Research began focusing on human-computer interaction by combining speech recognition with visual processing to achieve basic multimodal interactive systems, such as intelligent assistants and voice-controlled multimodal systems.
-
Deep Integration Stage: With advancements in computing power and improvements in image processing and speech recognition technologies, multimodal technology has gained more attention. Researchers gradually combined visual, auditory, and textual data to enhance human-computer interaction experiences.
-
Large Model Stage: In recent years, with breakthroughs in large language models (LLMs) and large visual models (LVMs), multimodal large models (MLLMs) have emerged.
Definition and Characteristics of Multimodal Large Models
Multimodal large models are deep learning models capable of simultaneously processing and understanding data from multiple modalities (such as text, images, audio, etc.). These models learn to establish connections between different modalities through large-scale pre-training, enabling cross-modal understanding and generation.
-
Cross-Modal Fusion: Multimodal large models can simultaneously process and fuse data from various modalities, achieving comprehensive perception and understanding of information.
-
Strong Generalization Ability: Through large-scale pre-training, the models possess strong generalization capabilities, enabling them to handle diverse tasks and scenarios.
-
Efficient Processing: Utilizing advanced algorithms and computational support, the models can efficiently process vast amounts of data, achieving rapid response and decision-making.
Technical Principles and Implementation
The technical principles of multimodal large models are primarily based on the pre-training-fine-tuning paradigm in deep learning. First, the model is pre-trained on large-scale multimodal datasets, learning the associations and mapping relationships between different modalities. Then, it is fine-tuned for specific tasks to adapt to particular application scenarios. During implementation, multimodal large models typically employ advanced network architectures, such as Transformers, to achieve efficient cross-modal feature extraction and fusion. Additionally, various optimization techniques, such as attention mechanisms and knowledge distillation, are introduced to enhance model performance and efficiency.
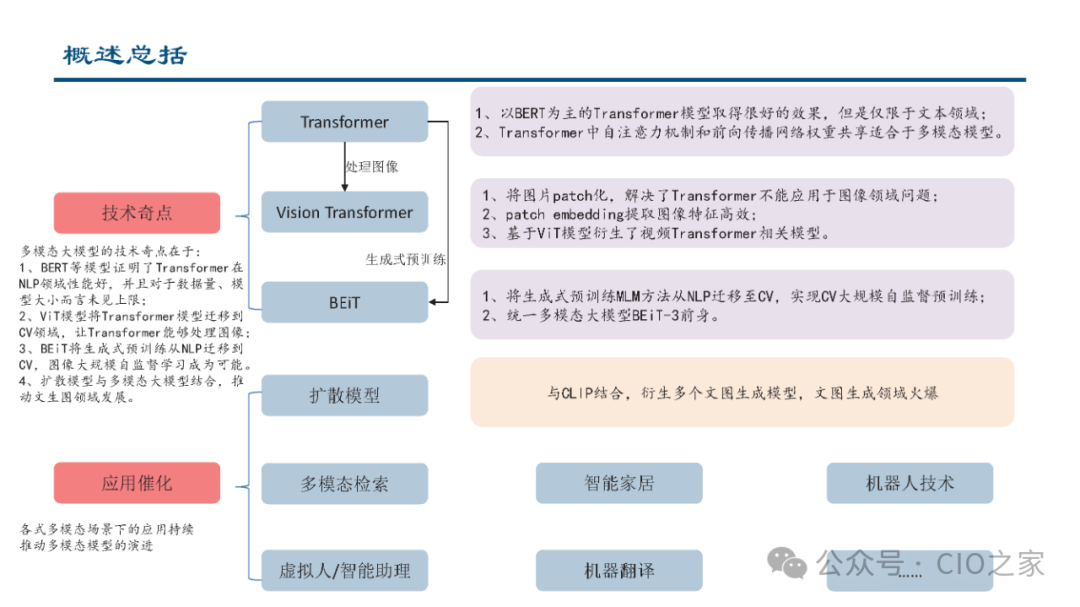
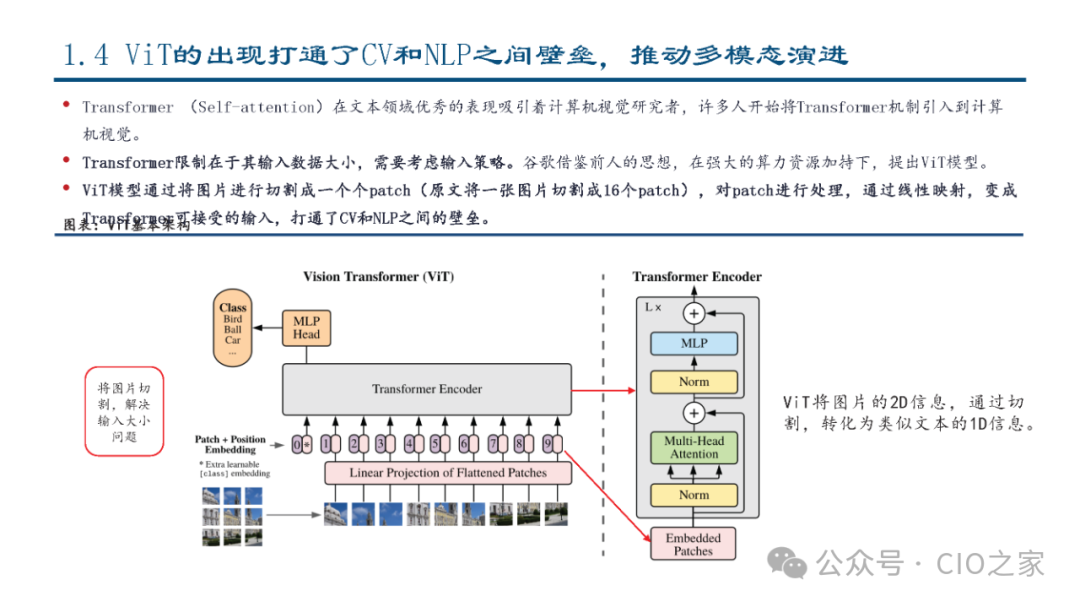
Compared to unimodal models, multimodal large models can simultaneously process various types of information, including text, images, audio, and video, which aligns closely with how humans receive, process, and express information. This allows for more flexible interaction with humans, demonstrating greater intelligence and the ability to execute a broader range of tasks, potentially becoming human intelligence assistants and propelling AI towards AGI. In terms of technical architecture, multimodal technology can be broken down into steps such as encoding, alignment, decoding, and fine-tuning, gradually uncovering multimodal associative information to output target results. The CLIP model, which generates images from text, is one of the most mature multimodal technologies, and currently, multimodal applications are no longer limited to just text and images.
| Long Press QR Code Image for Automatic Recognition and Download of This Document |
|
Code 1739346109
Reply with the Keyword 1739346109 to Get More Documents |

| Recommended Documents | ||
| Reply with Document Code or Long Press to Scan QR Code to View and Download the Document | ||
| Document Code | Title | |
| 1739260787 | DeepSeek Principles and Effects |
|
| 1739233960 | DeepSeek Beginner’s Tutorial |
|
| 1739233934 | DeepSeek Core Q&A |
|
| 1738997522 | DeepSeek From Beginner to Expert |
|
| 1737366768 | Cutting-Edge Multimodal Technologies and Industrial Applications |
|
| 1737365803 | Opportunities and Implementations of Multimodal RAG |
|
| 22321152353 | Progress in the Field of Multimodal Large Language Models |
|
| 22321152184 | Practical Applications and Prospects of Multimodal Large Models in the Financial Sector |
|
| Reply with Multimodal Large Model LLM DeepSeek to Get More Related Documents |








Related Articles Recommended
- Evolution of Large Models and Their Impact on Software Costs
- Exploration and Development Practices of Large Models in Finance
- The Key Role of AI Agent Large Models in Applications
- Integration Practices of Knowledge Graphs and Large Models
- AI Large Model Technology in Database DevOps Practices
- Trends of AI Large Models in China
Recently Popular Articles
-
Experience in Developing AI Agent Applications
-
Essential Skills Beyond Technology: Software Skills IT Professionals Need to Hone
-
Struggle! Is AI Programming a Helper or a Threat to Programmers?
-
Thought-Provoking! If IT Departments Don’t Change, They Will Disappear!
-
Questioning! Everyone Can Use AI, How to Stand Out?
-
Think Twice! Where is AI’s Potential? Enterprises Need More Than Just Access to Large Models
-
Shocking! Over 300 Large Models! Is It a Battle of Wits or Just Noise?
-
Who to Choose? DeepSeek VS ChatGPT VS Gemini
-
Understanding DeepSeek from 0 to 1
-
How DeepSeek Combines with Enterprise Applications to Create Greater Value
Note: Some text and image resources in this article are sourced from the internet. Sharing this article aims to convey more information. If there are any errors in source attribution or infringement of your legitimate rights, please notify us immediately through the backend, and we will delete it promptly if the situation is confirmed, and we apologize for any inconvenience caused.
