
MLNLP ( Machine Learning Algorithms and Natural Language Processing ) community is a well-known natural language processing community both domestically and internationally, covering audiences of NLP master’s and doctoral students, university teachers, and industry researchers.The vision of the community is to promote communication between the academic and industrial circles of natural language processing and machine learning, as well as among enthusiasts, especially for beginners.
Reproduced from | PaperWeekly
Author | Cui WenqianAffiliation | Beijing University of Posts and TelecommunicationsResearch Direction | Medical Natural Language Processing
This article aims to help everyone quickly understand the research context and progress in the field of text semantic similarity, including my summary of the processing steps for text semantic similarity tasks, the development history of text similarity models, related datasets, and important paper shares.
1
『Processing Steps for Text Similarity Tasks』
Through extensive reading of papers in this field, I believe that the processing of text similarity tasks can be divided into the following three steps:
-
Preprocessing: such as data cleaning. This step aims to perform some normalization operations on the text, filter useful features, and remove noise.
-
Text Representation: Once the data is preprocessed, it can be fed into the model. In text similarity tasks, a module is needed for vectorizing the text to prepare for the next step of similarity comparison. This part generally selects some backbone models, such as LSTM, BERT, etc.
-
Choice of Learning Paradigm: This step is also the most important module in text similarity tasks and distinguishes it from other tasks in the NLP field. The main reason is that similarity is a comparative process, so we can choose various comparison methods to achieve the goal. Available learning methods include: siamese network models, interactive network models, contrastive learning models, etc.
2
『Development History of Text Similarity Models』
From traditional unsupervised similarity methods to siamese models, interactive models, BERT, and some improvements based on BERT, as shown in the figure below:
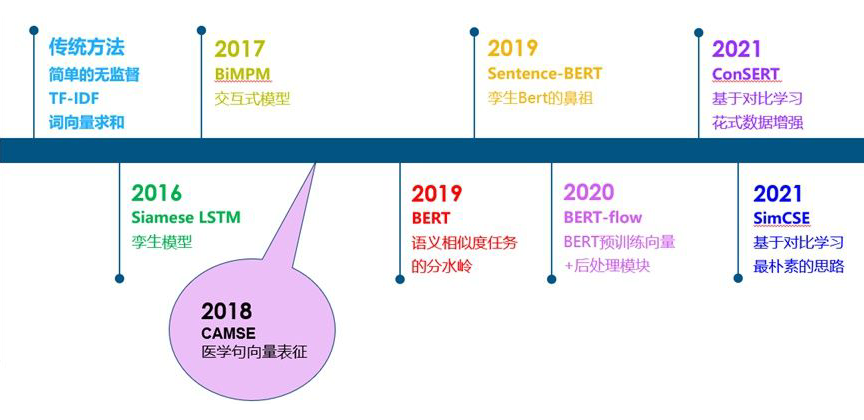
Overall, before the emergence of BERT, the text similarity task can be said to be a flourishing process. Everyone used various methods to perform similarity comparisons. After the emergence of BERT, due to its outstanding performance, subsequent work mainly focused on improvements based on BERT. During this phase, the datasets, evaluation metrics, etc., gradually became unified.
3
『Datasets』
After BERT, everyone gradually unified the choice of datasets for text similarity tasks, namely STS12, STS13, STS14, STS15, STS16, STS-B, and SICK-R, a total of seven datasets. STS12-16 are datasets from the SemEval competition from 2012 to 2016. Additionally, STS-B and SICK-R are also datasets from the SemEval competition. In these datasets, each text pair has a manually labeled similarity score ranging from 0 to 5 (also known as the gold label), representing the degree of similarity between the text pairs.
4
『Evaluation Metrics』
First, for each text pair, cosine similarity is used to score it. After scoring, Spearman Correlation is calculated using all cosine similarity scores and all gold labels.
Among them, Pearson Correlation and Spearman Correlation are both metrics used to calculate the degree of correlation between two distributions. Pearson Correlation measures whether two variables are linearly related, while Spearman Correlation focuses on whether the monotonicity of two sequences is consistent. Moreover, the paper “Task-Oriented Intrinsic Evaluation of Semantic Textual Similarity” proves that using Spearman Correlation is more suitable for evaluating semantic similarity tasks. The formulas for Pearson Correlation and Spearman Correlation are as follows:
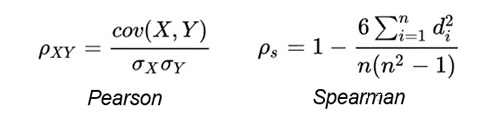
5
『Paper Sharing』
Siamese Recurrent Architectures for Learning Sentence Similarity, AAAI 2016
https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/download/12195/12023
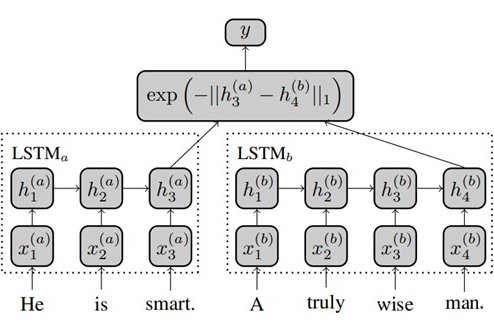
Siamese LSTM is a classic siamese network model that encodes the two sentences to be compared through different LSTMs, and calculates the Manhattan distance using the outputs of the last time step of the two LSTMs, and performs backpropagation using MSE loss.
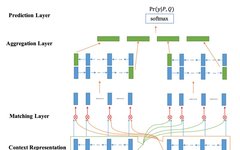
Bilateral Multi-Perspective Matching for Natural Language Sentences, IJCAI 2017
https://arxiv.org/abs/1702.03814
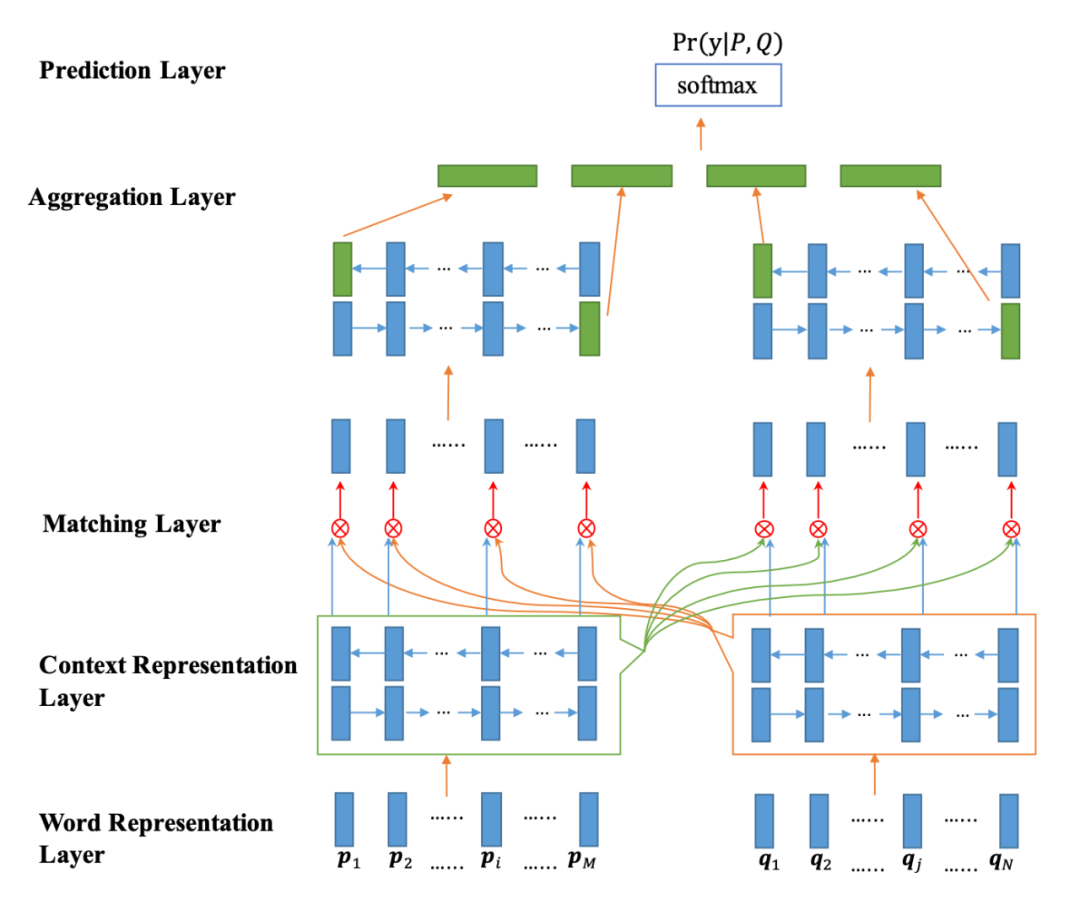
BiMPM is a classic interactive model that encodes the two sentences using different Bi-LSTM models and establishes interactive relationships between each word of the current sentence and each word of the other sentence through attention (the left and right sentences are symmetrical processes), thus learning deeper matching knowledge. After interaction, it is then encoded again by the Bi-LSTM model and finally output.
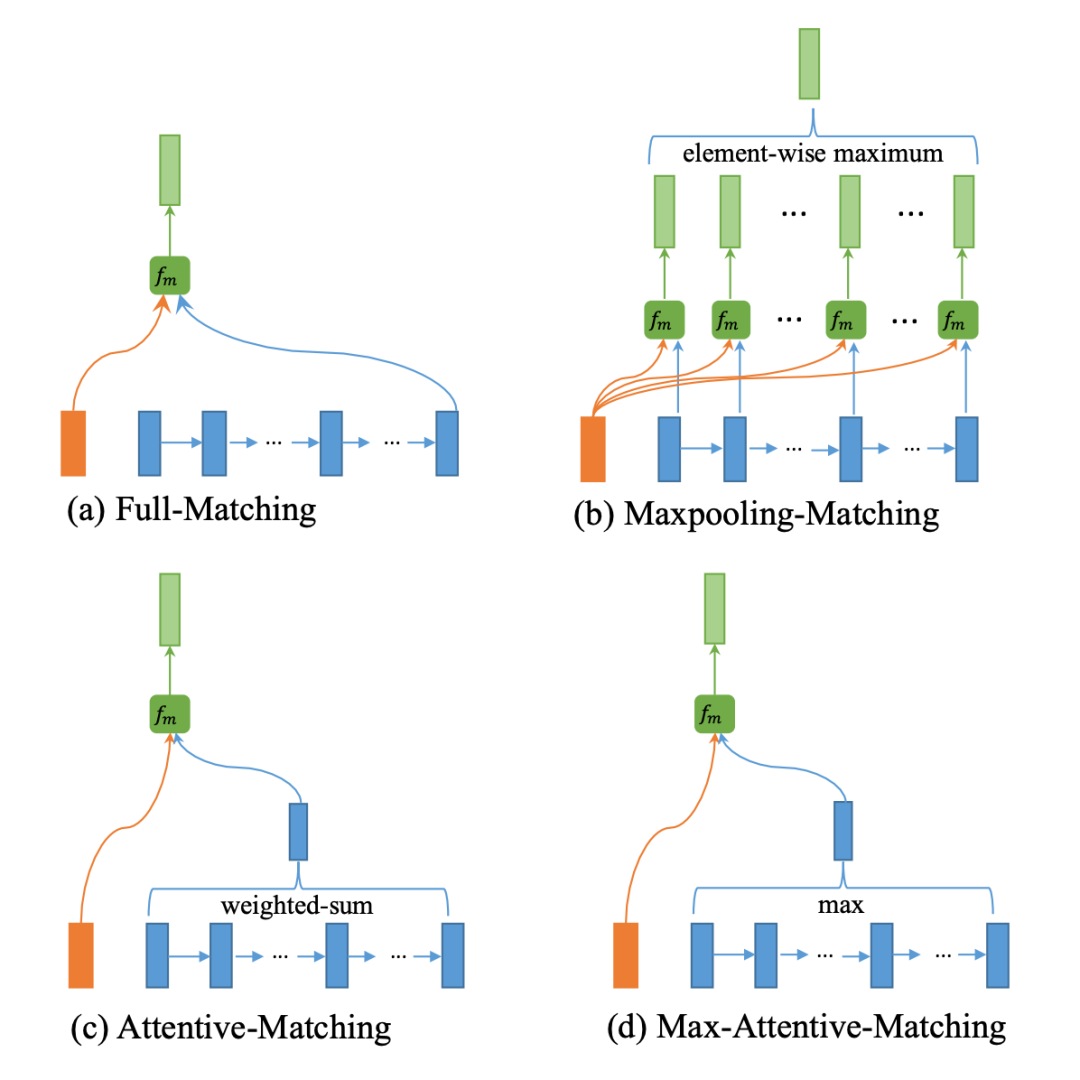
For the interaction process, the author designed four interaction methods, which are:
-
Each word in sentence A interacts with the last word of sentence B
-
Each word in sentence A interacts with each word in sentence B and takes the element-wise maximum
-
Words in sentence A filter each word in sentence B, and the word vectors of sentence B are weighted and summed, and finally compared with the words in A
-
Almost identical to c, except that the weighted summation operation is replaced with element-wise maximum
The specific interaction form is completed using weighted cosine similarity.
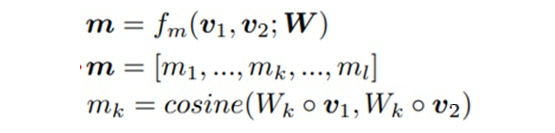
Where Wk is the parameter matrix, which can be understood as the attention’s query or key, and v1 and v2 are the two words to interact, so calculating cosine similarity l times will yield m vectors (an l-dimensional vector).
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/abs/1810.04805
BERT can be considered a watershed in semantic similarity tasks. In the BERT paper, supervised training on the STS-B dataset achieved a Spearman Correlation value of 85.8. This score is higher than that of most subsequent improvement works, but BERT’s shortcomings are also evident. For semantic similarity tasks:
-
In the supervised paradigm, BERT needs to merge the two sentences into one sentence for encoding, and if many texts need to be compared pairwise, BERT needs to arrange and combine them before feeding them into the model, which greatly increases the computational load of the model.
-
In the unsupervised paradigm, BERT’s sentence vectors carry less semantic similarity information. As shown in the figure below, whether using the CLS vector or averaging the word vectors, it still performs worse than averaging the word vectors trained by GloVe.
Based on these pain points, a number of excellent works based on BERT improvements have emerged.
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, EMNLP 2019
https://arxiv.org/abs/1908.10084
Sentence-BERT is a work that adopts a siamese BERT architecture. The authors of Sentence-BERT pointed out that if you want to calculate the similarity between 10,000 sentences using BERT, the arrangement and combination method would take 65 hours on a V100 GPU; whereas if you first compute the sentence vectors for the 10,000 sentences and then calculate the cosine similarity matrix, it would take only about 5 seconds. Therefore, the authors proposed a method to train BERT sentence vectors using a siamese network architecture.
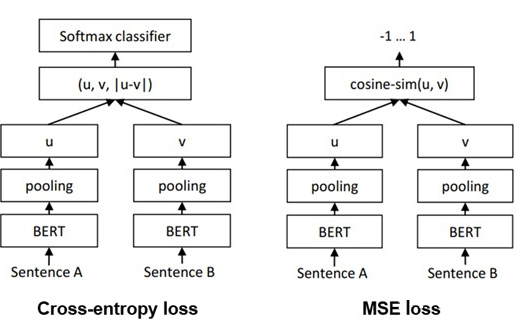
Sentence-BERT employs a total of three losses, which are three different ways to train the siamese BERT architecture, namely Cross-entropy loss, MSE loss, and Triple loss. The model diagram is as follows:
On the Sentence Embeddings from Pre-trained Language Models, EMNLP 2020
https://arxiv.org/abs/2011.05864
BERT-flow is a work that performs post-processing on BERT sentence vectors. The authors believe that the reason for the poor performance of using BERT sentence vectors for similarity calculations is not that they lack semantic similarity information, but that the similarity information contained in them cannot be well reflected under simple metrics like cosine similarity.
First, the authors argue that whether it is Language Modeling or Masked Language Modeling, it is essentially maximizing the co-occurrence probability between given context and target word, which is the contribution probability of Ct and Xt. The objective functions for Language Modeling and Masked Language Modeling are as follows:
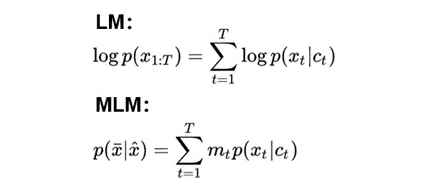
Thus, if the Xt predicted by the two sentences is consistent, it is likely that the Ct vectors of the two sentences are also similar! Consider the following two sentences:
-
What to eat for lunch today?
-
What to eat for dinner today?
The language models trained on these two sentences predict the word “eat” through context, indicating that the sentence vectors of these two sentences are likely similar and contain similar semantic information.
Secondly, the authors observed that BERT’s sentence vector space is anisotropic, with high-frequency words being closer to the origin and low-frequency words being farther away, resulting in a sparse distribution. Therefore, BERT sentence vectors cannot reflect the similarity information contained within them.

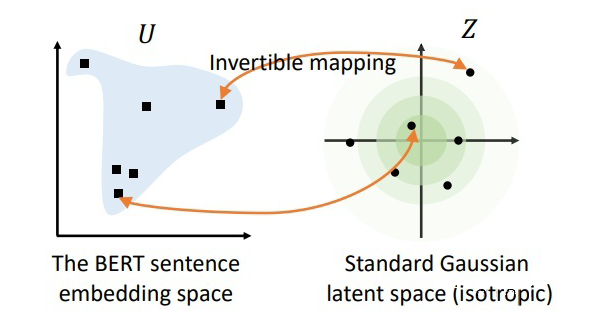
Therefore, the authors believe that a generative model based on flow can be used to map the BERT sentence vector space. Specifically, the authors aim to train a standard Gaussian distribution such that points in this distribution can be mapped one-to-one with points in the BERT sentence vector space. Since the mapping method used is reversible, it is possible to map a given BERT sentence vector back to the standard Gaussian space and then perform similarity calculations. Since the standard Gaussian space is isotropic, it can better showcase the semantic similarity information contained in the sentence vectors.
SimCSE: Simple Contrastive Learning of Sentence Embeddings, EMNLP 2021
https://arxiv.org/abs/2104.08821
SimCSE is a semantic similarity model based on contrastive learning. First, compared to matching between text pairs, contrastive learning can pull positive examples closer while simultaneously pushing them farther away from more negative examples, thus training a more uniform hyperspherical vector space. As a type of unsupervised algorithm, one of the most important innovations in contrastive learning is how to construct positive sample pairs to learn some essential features within the category.
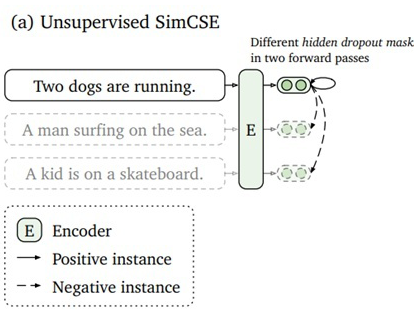
SimCSE employs a very simple yet surprisingly effective method, which is to input the same sentence into the model twice during training, using the model’s own dropout to generate two different sentence embeddings as positive examples for comparison. The model diagram is as follows:
ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer, ACL 2021
https://arxiv.org/abs/2105.11741
ConSERT is also a text similarity work based on contrastive learning. ConSERT uses various data augmentation methods to construct positive examples, including adversarial attacks, shuffling the order of words in the text, Cutoff, and Dropout. It is important to note that although ConSERT and SimCSE both use Dropout, ConSERT’s data augmentation operations only stay at the embedding layer, while SimCSE uses Dropout across all layers of BERT. Additionally, the authors’ experiments show that among the four data augmentation methods, Token Shuffling and Token Cutoff are the most effective.
Exploiting Sentence Embedding for Medical Question Answering, AAAI 2018
https://arxiv.org/abs/1811.06156
Note: As my work mainly involves smart healthcare, I will have a biased focus on methods and models in the field of medical artificial intelligence.
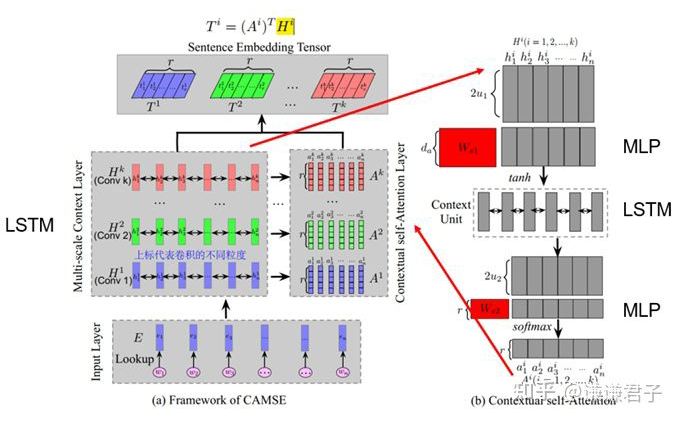
MACSE is a work on sentence vector representation for medical texts. Although it mainly focuses on the QA task, its sentence vector representation method is also applicable in text similarity tasks.
A significant characteristic of medical texts, as opposed to general texts, is the inclusion of complex multi-scale information, as shown below:
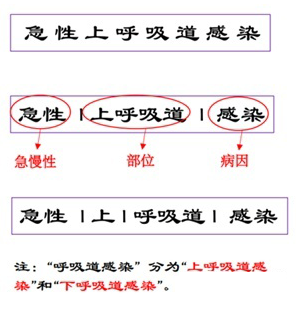
Therefore, we need a model that can pay attention to the multi-scale information in medical texts.
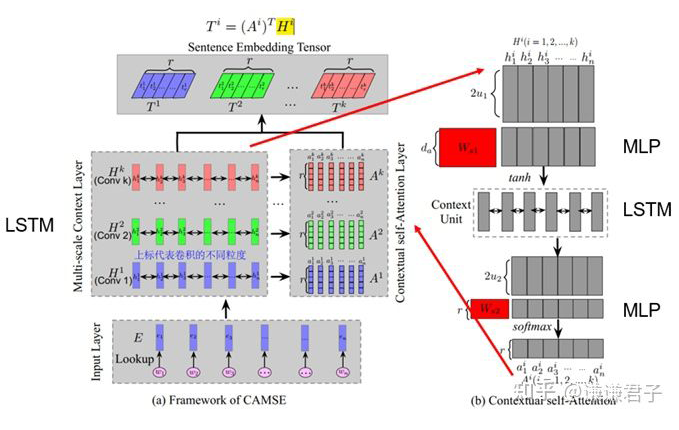
In this article, through multi-scale convolution operations, we can effectively extract multi-scale information from the text and use attention mechanisms to weight this multi-scale information, thereby effectively focusing on important information present in specific texts at specific scales.
6
『Summary of Experimental Results』
The following are the results of numerous BERT-based improved models tested on standard datasets, sourced from the SimCSE paper:
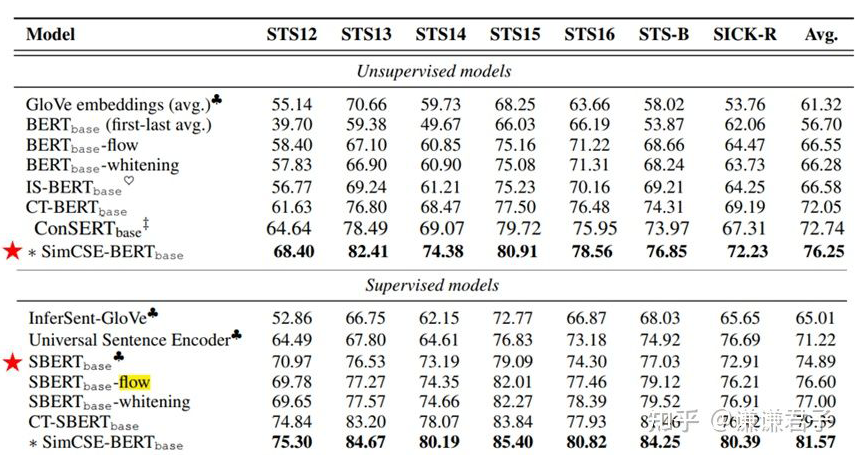
It can be seen that BERT-flow improved nearly 10 points compared to the original BERT, while contrastive learning-based works performed significantly better than post-processing works. Additionally, it should be noted that here, Sentence-BERT is classified as a supervised model. This is because although Sentence-BERT did not use STS labels, the training was done using the NLI dataset, which also used manually labeled labels from NLI, thus the authors of SimCSE categorized Sentence-BERT as a supervised model.
Well, that’s the research context and progress in the field of text semantic similarity. I hope it can be helpful to everyone. Of course, many excellent works emerged in 2022 as well, but we will leave that for later!
Technical Exchange Group Invitation

△Long press to add the assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)to apply for joining the Natural Language Processing/Pytorch and other technical exchange groups
About Us
MLNLP Community ( Machine Learning Algorithms and Natural Language Processing ) is a grassroots academic community jointly built by scholars in natural language processing from home and abroad, which has developed into a well-known natural language processing community both domestically and internationally, including well-known brands such as Ten Thousand People Top Conference Exchange Group, AI Selection Exchange, AI Talent Exchange, and AI Academic Exchange, aimed at promoting progress between the academic and industrial circles of machine learning and natural language processing, as well as among enthusiasts.The community can provide an open communication platform for related practitioners’ further study, employment, and research. Everyone is welcome to follow and join us.
