Tip: Click the "English Writing Teaching and Research" above for free follow-up.
Call for Papers: Second Language Writing
Language Teaching | Harvard University Writing Teaching Series Collection
Language Teaching | 40 Academic Writing Videos Collection
Language Teaching | Purdue University Writing Teaching Series Collection
Language Teaching | Duke University Writing Teaching Series Collection
Wordless is a multilingual integrated corpus processing and analysis software that can be used for research in linguistics, literary studies, translation studies, and other language-related fields. It was developed by Ye Lei, a doctoral student from the 2021 class of the Institute of Corpus Studies at Shanghai International Studies University.

Ye Lei, a doctoral student from the 2021 class of the Institute of Corpus Studies at Shanghai International Studies University, holds a bachelor’s degree in English from Shanghai University of Science and Technology (2017) and a master’s degree in English Language and Literature from Shanghai International Studies University (2020). His research interests include interpreting and translation studies, corpus-based translation research, and corpus tool development. He has experience in accompanying interpretation, exhibition interpretation, and telephone interpretation, and is familiar with Python development. During his master’s studies, he independently designed and developed the multilingual corpus integration tool Wordless, obtaining two software copyrights.
To excel in your work, you must first sharpen your tools. Two significant barriers have long hindered all corpus researchers: the construction of the corpus and retrieval. The former has a low technical threshold, but the monotonous repetitive labor can deter many attempts. The latter involves less workload, but the high technical barrier makes it daunting for remaining novices. The purpose of using a corpus is to solve problems, yet using a corpus often reveals more issues. Overcoming the former requires physical strength, while overcoming the latter requires intellectual ability, which is a significant manifestation of human wisdom—the ability to create and use tools.
Currently, the most widely used corpus retrieval tools internationally are WordSmith and AntConc. The former has relatively complete functions but is noted for its “complex interface and difficulty in operation” (Xu & Jia, 2013). The latter has a relatively reasonable interface layout and is easy to operate, but its functional details are not fully developed. Among parallel corpus retrieval tools, ParaConc stands out, but it often suffers from garbled text issues. Other multimodal corpus retrieval software, besides ELAN, has no alternatives. Mac users are forced to master the use of virtual machines due to the lack of cross-platform support, while Windows users often struggle with software licensing fees or choose to become victims of pirated software and suffer from guilt day and night. On one hand, a basic rule-based segmentation method is widely used, while on the other, industrial-strength NLP segmentation algorithms have very few users. Since “pointwise mutual information” (PMI) was introduced (Church & Hanks, 1990), it has been incorrectly labeled as “mutual information” (MI) (cf. Bouma, 2009) and is reflected in some corpus tools. WordSmith misunderstands the overall standard deviation as the sample standard deviation in the implementation of Juilland’s D (cf. Scott, 2021) (cf. Bouma, 2009). Numerous researchers, including Carroll (1970) and Lyne (1985), have optimized Juilland’s D algorithm multiple times or proposed entirely new word frequency distribution algorithms, but as of version 8.0, WordSmith still only supports the classic Juilland’s D algorithm. The rapid development of statistics, natural language processing, and artificial intelligence has not been matched by the iterative updates of corpus tools. The excessively high entry barriers restrict the long-term development of the corpus research community, and the existence of technical barriers turns corpus technology into an exclusive resource for a small elite in the field. However, it is not impossible to have both fish and bear’s paw; one of the main purposes of developing Wordless is to attempt to solve the above problems.
Wordless has built-in language and encoding detection features, allowing users to specify the language of each file manually and eliminating concerns about compatibility issues caused by unclear or differing corpus file encodings. All features in Wordless will process each file according to its language settings and display the calculated results.
The Overview Module provides overall statistical information for each corpus file, including readability statistics, paragraph/sentence/character/class symbol/syllable/character counts, (normalized) class symbol-character ratios, and mean and standard deviation of paragraph/sentence/character/class symbol/syllable lengths, as well as counts of sentences/characters of various lengths. Wordless supports the calculation of various readability statistics, including the Automated Readability Index, Coleman-Liau Index, Dale-Chall Readability Score, Devereaux Readability Index, Flesch Reading Ease, Flesch Reading Ease (Simplified), Flesch-Kincaid Grade Level, FORCAST Grade Level, Gunning Fog Index, SMOG Grade, Spache Grade Level, and Write Score.
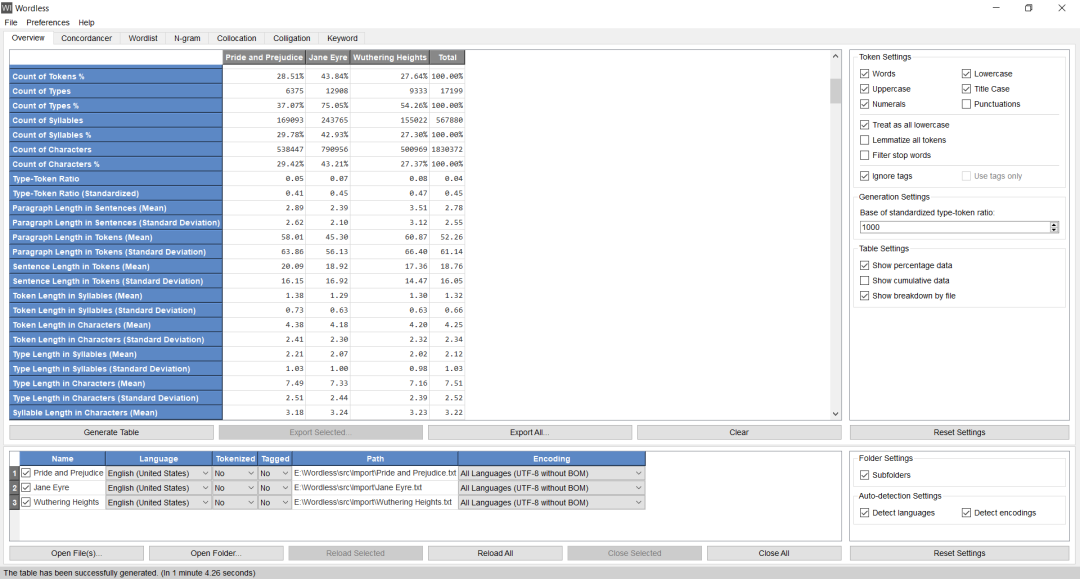
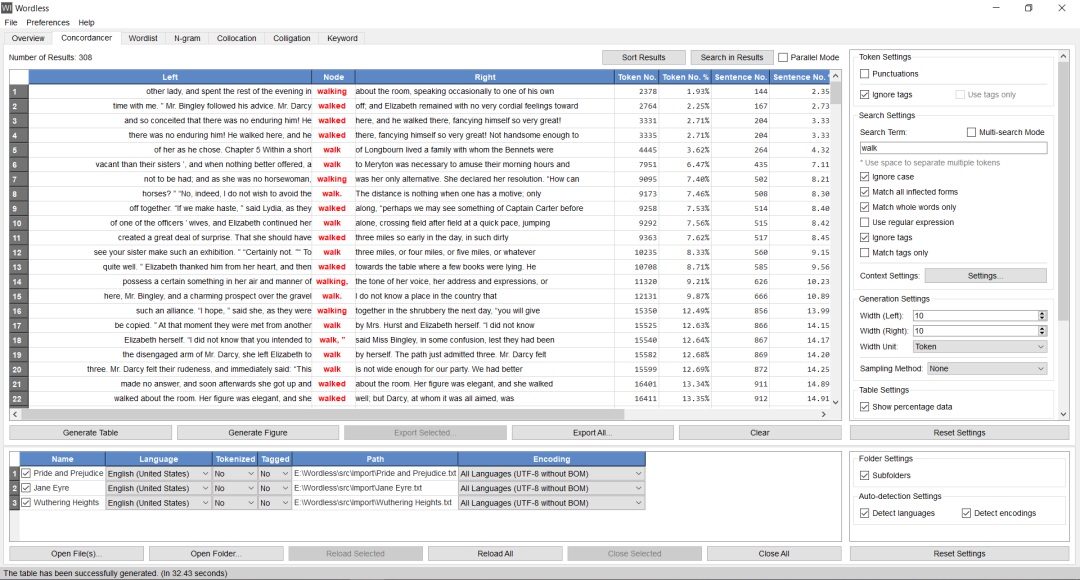
The Concordancer Module provides keyword in context (KWIC) search functionality, supporting monolingual and parallel searches, specifying the context display range by character/word/sentence/paragraph, setting context constraints (such as must/must not include certain words), result sampling/search/sorting, masking search terms (zapping) for creating fill-in-the-blank exercises, and drawing index line distribution graphs. The search function supports case-insensitive matching, (multi-language) inflectional form matching (searching for ‘take’ automatically matches ‘takes’, ‘took’, etc.), exact word matching, regular expressions, and tag matching.
The Wordlist Module provides functionalities related to word frequency statistics, supporting the counting of all characters in corpus files (percentage) frequency/distribution/adjusted frequency, filtering lowercase words/uppercase words/capitalized words/numbers/punctuation, merging word forms, (custom) stop word filtering, and drawing line graphs/word clouds, etc. Among the distribution algorithms, Wordless currently supports Carroll’s D₂, Gries’s DP, Gries’s DPnorm, Juilland’s D, Lyne’s D₃, Rosengren’s S, and Zhang’s Distributional Consistency. In the adjusted frequency algorithms, Wordless currently supports Carroll’s Um, Engwall’s FM, Juilland’s U, Kromer’s UR, and Rosengren’s KF.

The N-gram Module provides functionalities related to n-grams and skip-grams, with details similar to the Wordlist module, so they will not be repeated here.
The Collocation Module provides functionalities for collocation extraction, supporting the calculation of co-occurrence frequency/total co-occurrence frequency/significance test statistics/p-values/Bayesian factors/effect sizes for node words and their collocates at various distance positions in each file, limiting the search range for collocates (same sentence/paragraph), and drawing line graphs/word clouds/network graphs, etc. In significance testing, Wordless supports the calculation of Berry-Rogghe z-values, Fisher’s exact test, log-likelihood ratios, Pearson’s chi-square tests, one-sample Student’s t-test, and z-values. For Bayesian factors, Wordless supports the calculation of log-likelihood ratio Bayesian factors, and for effect sizes, Wordless supports the calculation of the Cubic Association Ratio (MI3), Dice coefficient, Jaccard coefficient, Log-Frequency Biased MD, logDice, MI.log-f, Minimum Sensitivity, Mutual Dependency, Mutual Expectation, mutual information (MI), pointwise mutual information (PMI), Poisson Collocation Measure, and the square of the Phi coefficient.

The Colligation Module provides functionalities for class connection extraction, supporting automatic tagging of files without part-of-speech coding, with other functionalities similar to the Collocation module.
The Keyword Module provides functionalities for keyword extraction, supporting the counting of all characters in each file in reference and observation corpora, significance test statistics/p-values/Bayesian factors/effect sizes, limiting the search range for collocates (within the same sentence/paragraph), and drawing line graphs/word clouds/network graphs, etc. In significance testing, Wordless supports the calculation of Fisher’s exact test, log-likelihood ratios, Mann-Whitney U tests, Pearson’s chi-square tests, and two-sample Student’s t-tests. For Bayesian factors, Wordless supports the calculation of two-sample Student’s t-tests and log-likelihood ratio Bayesian factors, and for effect sizes, Wordless supports the calculation of %DIFF, Difference Coefficient, Kilgarriff ratio, Log Ratio, and odds ratios.
Wordless currently supports the detection of 98 languages and 102 encodings, at least 108 languages for sentence/word/word form restoration, 42 languages for phoneme segmentation, 27 languages for part-of-speech tagging, 45 languages for lemmatization, and stop word lists for 99 languages. Users can use the preview function in the settings interface to perform NLP-related processing operations on the corpus.
Wordless provides multi-platform support, including 64-bit Windows 7/8/8.1/10, macOS 10.11+/11.0+, and Ubuntu 16.04+. Wordless is completely free, so users no longer need to worry about financial constraints or cumbersome payment processes. All source code for Wordless has been open-sourced on GitHub, allowing future researchers interested in corpus tool development to avoid the painful development period that I experienced without any prior experience for reference.
Wordless is a project I started at the end of my first year at Shanghai International Studies University. The first version was successfully released after eight months of continuous learning and development, and it has undergone multiple version iterations. In the future, I will continue to focus on optimizing parallel corpus-related functions and adding modules for dependency analysis, named entity recognition, multimodal corpus alignment and retrieval, and NLP model training. Conducting this project independently at a foreign language university has been incredibly challenging for someone with a purely language background like me. Therefore, I hope more people will participate in the difficult yet immensely potential work of corpus tool development. I also hope users will feel the increase in research efficiency brought by the reduction of learning barriers and the breaking down of technical barriers after seeing the startup interface shown below, allowing them to focus on the analysis and interpretation of data results without being overly concerned with technical issues that should not be overemphasized.

|
Homepage |
https://github.com/BLKSerene/Wordless |
|
GitHub Download |
https://github.com/BLKSerene/Wordless#download |
|
Cloud Drive Download (Extraction Code: wdls) |
https://pan.baidu.com/s/1–ZzABrDQBZlZagWlVQMbg |
|
User Documentation |
https://github.com/BLKSerene/Wordless#documentation |
|
Citation Information |
https://github.com/BLKSerene/Wordless#citing |
|
Donate for Development |
https://github.com/BLKSerene/Wordless#donating |
|
WeChat Official Account |
Wordless |
If anyone around you has related research needs, recommending Wordless or forwarding this article is the greatest support for Wordless. If you have used Wordless in publicly published papers or other achievements, please cite it to increase its visibility. You can check citation information through the links above or in the help menu of Wordless. If you have registered a GitHub account, you can Watch/Star/Fork the Wordless repository to show your support. If you wish to provide financial support for the subsequent development of Wordless, you can do so through the links above or in the help menu of Wordless.
References
[1] Bouma, G. (2009). Normalized (pointwise) mutual information in collocation extraction. In C. Chiarcos (Ed.), From form to meaning: Processing texts automatically, proceedings of the biennial GSCL conference (pp. 31–40). National Bureau of Standards. Gunter Narr Verlag.
[2] Carroll, J. B. (1970). An alternative to Juilland’s usage coefficient for lexical frequencies and a proposal for a standard frequency index. Computer Studies in the Humanities and Verbal Behaviour, 3(2), 61–65. https://doi.org/10.1002/j.2333-8504.1970.tb00778.x
[3] Church, K. W., & Hanks, P. (1990). Word association norms, mutual information, and lexicography. Computational Linguistics, 16(1), 22–29. https://doi.org/10.3115/981623.981633
[4] Juilland, A., & Chang-Rodriguez, E. (1964). Frequency dictionary of Spanish words. Mouton.
[5] Lyne, A. A. (1985). Dispersion. In The vocabulary of French business correspondence: Word frequencies, collocations, and problems of lexicometric method (pp. 101–124). Slatkine/Champion.
[6] Scott, M. (2021). WordSmith Tools Help. https://lexically.net/downloads/version8/HTML/formulae.html
[7] Xu, J., & Jia Y. (2013). 基于R-gram的语料库分析软件PowerConc的设计与开发 [The design and development of the R-gram based corpus analysis tool ‘PowerConc’]. Technology Enhanced Foreign Languages, 149, 57–62.
[i] Mutual information (MI) refers to the expected value of pointwise mutual information (PMI), and the two concepts are different.
[ii] Although the original literature of Juilland’s D (Juilland, 1964) is no longer traceable, it can be inferred from the calculation examples quoted in Carroll (1970) that the original formula used the overall standard deviation rather than the sample standard deviation. In the online documentation of WordSmith, the author suggests that changing the denominator from n-1 to n in the final calculation yields better results, but after testing, I found that the final calculation result does not change. Therefore, it is inferred that WordSmith actually used the sample standard deviation in the implementation of Juilland’s D, and after two modifications, the denominator in the original formula changed from (n-1)*n to n*(n-1), resulting in no change in the final result, but the statement that “the original formula is ineffective” is incorrect; in fact, the author did not conduct thorough research on the original literature.
-END-
This article is reproduced from: Linguistic Communications.
Author: Dr. Ye Lei, Shanghai International Studies University.