
Originally from AI Technology Review

Compiled by Jocelyn
Edited by Chen Caixian
This article provides a comprehensive chronological survey of visual-language (VL) intelligence and summarizes the development of this field into three stages:
The first stage is from 2014 to 2018, during which specialized models were designed for different tasks. The second era is from 2019 to 2021, during which neural network models were able to learn joint representations of vision and language through pre-training using high-quality labeled VL datasets. Finally, with the emergence of CLIP in 2021, the third era began, where researchers sought to pre-train VL models on larger weakly labeled datasets and achieved powerful zero-shot or few-shot-based visual models through VL pre-training.
We believe this review will aid researchers and practitioners in artificial intelligence (AI) and machine learning (ML), especially those interested in computer vision and natural language processing.

Paper link: https://arxiv.org/pdf/2203.01922.pdf
1Research Background
Computer Vision (CV) and Natural Language Processing (NLP) are the two main branches of artificial intelligence, focusing on simulating human intelligence in vision and language. Over the past decade, deep learning has significantly advanced the development of unimodal learning in both fields, achieving state-of-the-art results across a range of tasks. The core of deep learning’s significant progress lies in the rapid development of GPUs and the availability of large-scale datasets, which have accelerated the large-scale training of deep learning models.
With the development of deep learning, we have also seen the emergence of a series of powerful neural networks. Traditional neural networks are often multi-layer perceptrons (MLPs) composed of multiple layers of linear layers and non-linear activations. In 1998, LeCun et al. proposed Convolutional Neural Networks (CNNs), which introduced translational invariance as a better inductive bias for 2D visual inputs, inspiring a large number of deep neural networks including AlexNet, VGGNet, GoogleNet, and ResNet.
Another major breakthrough was the Recurrent Neural Network (RNN) in the field of NLP, which introduced recurrent neurons for sequence data modeling. To alleviate the gradient vanishing and exploding problems in training long sequences, LSTM (a variant of RNN) and GRU (a more efficient version of LSTM) were proposed. Another significant breakthrough in NLP is the Transformer, which utilizes attention mechanisms to pursue better language representation. By using multiple stacked attention layers, the Transformer can globally fuse information across language symbols with high parallelism, facilitating effective representation and large-scale training.
While we have seen encouraging progress in unimodal technologies, real-world problems often involve multimodal aspects. For instance, autonomous vehicles should be able to process human commands (language), traffic signals (visual), and road conditions (visual and auditory). Even unimodal learning can benefit from multimodal learning. For example, language learning requires perception, which is the foundation for many semantic axioms.
Perception is the way humans understand the material world, determining the meaning behind human language. Because what we hear and see is the same, some knowledge is retained as common sense, which is not recorded in our language. Even in the realm of language, speech contains more useful information than plain text; for instance, prosody can indicate emotion.
Multimodal perception is helpful in both multimodal and unimodal tasks, leading to a wealth of related research. In the multimodal domain, because vision is one of the most important senses humans use to understand their environment, and the combination of visual and linguistic features can significantly improve performance in visual and visual-language tasks, research related to visual-language integration has gained much attention. Moreover, the popularity of visual-language intelligence has been aided by the rich datasets and evaluation standards in this field.
The ambition to solve specific task VL problems has driven the preliminary development of VL learning. These VL problems include image captioning, visual question answering (VQA), and image-text matching, among others. Xu et al. integrated a CNN image encoder and an RNN text decoder for image captioning in their 2015 work. Antol et al. addressed the VQA task in 2016 by mapping images and text into the same latent space and predicting answers from latent representations. Lee et al. performed image-text matching in 2018 by computing the similarity between images and text at the sentence or token level. These models were tailored for specific problems in various datasets, where each model could only solve one task.
Inspired by the popularity of pre-training and fine-tuning in language and vision, a new era for the interdisciplinary field of vision and language has arrived: learning joint representations of vision and language through pre-training on image-text pairs. The rise of VLP models has been primarily inspired by the architecture design and training methods of language models. For instance, many recent studies have adopted architectures and training methods similar to BERT. Due to the lack of sufficiently large-scale manually labeled data, the development of VL learning has faced severe challenges. Recently, some studies have broken this limitation by adopting contrastive learning and utilizing data crawled from large-scale web crawlers to learn visual-language features, which can be used for zero-shot learning.
With the rapid development of the VL field, there is currently an urgent need for a comprehensive survey of the existing research in this field. This article aims to provide a structured overview of the latest developments in the VL field to help researchers gain a holistic understanding of the VL domain and better comprehend the latest research outcomes.
We divide the development of VL learning into three stages. The first is from 2014 to 2018, during which specialized models were designed for different tasks. The second era is from 2019 to 2021, during which neural network models were able to learn joint representations of vision and language through pre-training using high-quality labeled VL datasets. Finally, with the emergence of CLIP in 2021, the third era began, where researchers sought to pre-train VL models on larger weakly labeled datasets and achieved powerful zero-shot or few-shot-based visual models through VL pre-training.
Reviewing the entire development process of VL intelligence, we find that its overall goal is to learn good visual features. A good visual feature should possess three attributes: object-level, language-aligned, and semantically rich. Object-level means that the fine granularity of visual and language features should remain consistent at the object level and word level, respectively. Language alignment emphasizes that visual features aligned with language can help complete visual tasks. Semantically rich refers to learning features from large-scale data without domain restrictions.
In the first era of VL, the goal of relevant scientific research was to solve specific problems rather than learning the aforementioned good features. In the second era, researchers trained models based on image-text pairs to obtain language-aligned visual features. Some research outcomes from this era adopted detected regions as image features to learn object-level features. Only in the third era could researchers handle large-scale datasets and use features rich in semantic information for pre-training.
2Specific Task Problems
Early VL methods were designed for specific tasks. The VL domain encompasses a wide range of tasks, including image captioning, visual question answering, image-text matching, and visual dialogue.
In this section, we detail three of the most common tasks: image captioning, visual question answering, and image-text matching. We summarize that the development of specific task methods has evolved from global representations to fine-grained, object-centered representations.
Most VL tasks involve three stages, including global vector representation and simple fusion; grid feature representation and cross-modal attention mechanisms; and object-centered feature representation and bottom-up top-down attention. The representative works of these three stages are illustrated in Figure 1.
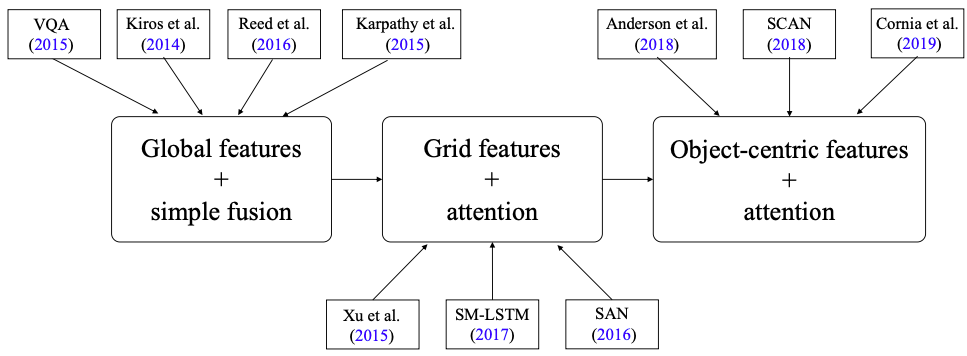
As shown in Figure 1, the specific methods for these three stages of tasks differ mainly in the granularity of visual representation and the way visual and language features are fused.
A Image Captioning
Task Definition: The goal of image captioning is to generate a “caption” for a given image, summarizing its content in one sentence. The caption typically includes the objects of interest, the actions of the objects, and the spatial relationships between the objects.
Methods: Before the advent of deep learning, early image captioning methods were primarily rule-based. They first identified objects and their relationships, then generated captions based on predefined rules. These early methods were limited in effectiveness due to the limited vocabulary of visual recognizers and the constraints of rule-based methods in handling complex scenes in human language.
The breakthroughs in deep learning technology greatly enhanced image captioning capabilities. Seq2Seq achieved tremendous success in machine translation by encoding the source language text with a text encoder and generating text from the target language using a text decoder.
Building on the Seq2Seq encoder-decoder structure, Xu et al. proposed replacing the text encoder with a GoogleNet image encoder, achieving state-of-the-art performance at the time. This encoder-decoder structure became popular and was widely adopted in subsequent works. This structure is referred to as img2seq, as illustrated in Figure 2.
Early research adopted CNN models as image encoders to extract a global CNN feature, which served as the initial hidden state input to the text decoder. m-RNN and LRCN proposed adding global CNN features to the LSTM decoder at each step.
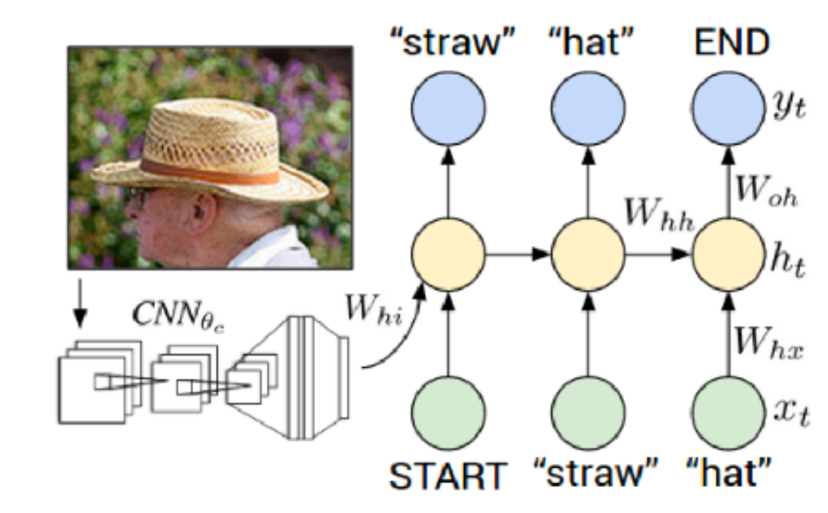
As shown in Figure 2, the img2seq structure includes an image encoder (e.g., CNN) and a language decoder (e.g., LSTM).
Global CNN features have a significant weakness, as the decoder cannot focus on important areas of the image like humans do. To address this issue, attention mechanisms were introduced.
In 2015, Xu et al. proposed a method to incorporate attention mechanisms into features. Assuming the output feature map shape of the CNN feature extractor is (H, W, C), where H and W are the height and width of the feature map, and C is the feature dimension. The feature map can be flattened along the spatial dimension into grid features of H × W with C dimensions. For each cell of the LSTM decoder, the hidden state must attend to the grid features to decide which grid to focus on.
Compared to convolutions, attention mechanisms have the following advantages. They allow the model to focus on certain parts of the image by giving higher attention weights to important grid features. Additionally, the model can learn alignment methods that are highly similar to human intuition. The interpretability of the model can also be improved through visualizing attention scores, which may help eliminate network errors.
However, segmenting an image into equally sized grids is a naive method of executing attention, as the grids poorly correspond to objects. To address this issue, some researchers have attempted to connect attention with more meaningful regions.
Anderson et al. (2018) proposed a bottom-up and top-down attention method (BUTD), which correlates attention with salient regions obtained from detection models. BUTD uses a Faster-RCNN model pre-trained on visual genome to extract region features. Since detected object regions typically contain meaningful visual concepts and can better match human language, BUTD significantly improves performance in image captioning and VQA. Consequently, pre-trained detectors have been widely adopted in subsequent VL research.
The application of attention mechanisms also varies. For example, Lu et al. proposed that since some words are irrelevant to visual features, the decoder does not need to maintain attention to visual features continuously. Therefore, they suggested using a gate to determine whether the attention mechanism should be involved. AoA designed a special “attention overlay mechanism” for the image captioning task. After the standard attention mechanism, they concatenate the attended vector and the query. The concatenated vector then generates an information vector and an attention gate, multiplying the information vector to obtain the output.
In addition to the aforementioned works, there are also works that do not use attention mechanisms. For instance, Neural Baby Talk first generates a sentence template and then fills it with concepts detected in the image. Cornia et al. generate a sentence by predicting a sequence of noun phrases. They first detect regions and then use a ranking network to order the regions. Finally, each region is converted into a noun phrase to form a sentence.
In summary, the development of early image captioning methods mainly involved two aspects: visual representation and language decoding. Visual representation evolved from image-level global features to fine-grained and object-level region features, while language decoding progressed from LSTM to attention-based models.
B. Visual Question Answering
Task Definition: Given an image-question pair, visual question answering requires answering a question based on the image. Most studies view visual question answering as a classification problem based on a predefined set of answers. For example, VQA v2 has about 2K predefined answers.
Methods: The typical visual question answering setup is a combination of an LSTM question encoder and a VGG image encoder. The output image embedding and question embedding are simply fused by pointwise multiplication. The fused vector then passes through a linear layer and a Softmax layer, outputting probabilities for each candidate answer. The architecture of the model is illustrated in Figure 3. Subsequent research in visual question answering typically adopts the same methodological prototype.
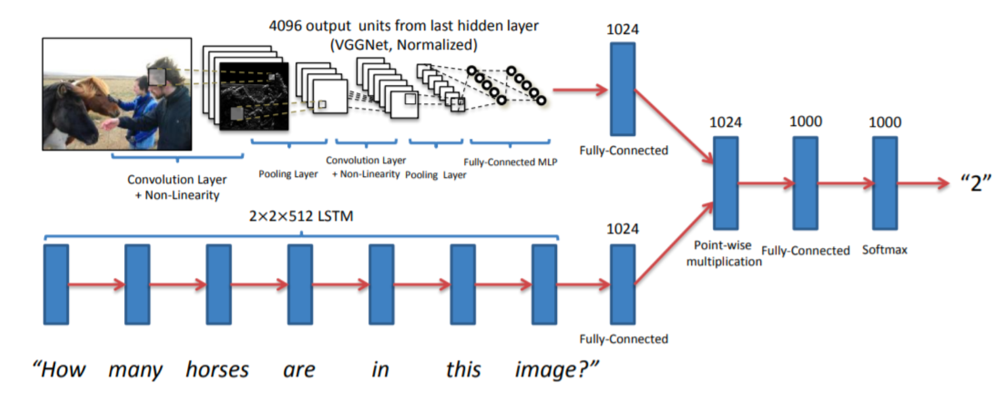
As shown in Figure 3, the vanilla VQA architecture includes a CNN model to encode the input image and an LSTM model to encode the input question. The encoded image and question features are merged through a dot product, followed by a fully connected layer to predict the probabilities of candidate answers.
Early research typically employed global image representations and simple fusion methods. Malinowski et al. (2015) proposed inputting CNN image features into each LSTM unit of the question encoder. That same year, Gao et al. used a shared LSTM to encode questions and decode answers. They fused CNN image features with the output of each decoder unit, generating answers word by word.
Question answering is usually only related to certain regions of the image. Therefore, due to noise from irrelevant regions, global representations lead to suboptimal solutions. Yang et al. (2016) proposed the Stacking Attention Network (SAN), which stacks multiple question-guided attention layers. In each layer, the semantic representation of the question is used as a query for the image grid. SAN serves as a validation of the effectiveness of attention in visual question answering. Fukui et al. also adopted grid features and fused image and language features through bilinear pooling.
As mentioned in the image captioning task, grid features have their limitations. To address this issue, Shih et al. proposed using region features located by bounding boxes as visual representations. BUTD pre-trained a powerful detector and used question features as queries to attend to region features. Lu et al. argued that attention to text is equally important as attention to images. Therefore, they developed a co-attention approach that jointly executes text-guided image attention and image-guided text attention.
In addition to attention, there are other modality fusion strategies. Ren et al. treated image features as language tokens. They connected image embeddings with language tokens as inputs to LSTM. Kim et al. proposed an element-wise multiplication iterative method for modality fusion called multimodal residual networks. MUTAN introduced bilinear interactions parameterized between modalities. Although there are many methods for fusing image and language features, attention mechanisms remain the most commonly used.
The core of image question answering is to obtain joint representations of image and language (question). Researchers in this field have explored various ways to better encode and fuse image and language, laying the foundation for subsequent visual learning representation VLP methods. Most works in this field independently encode images and language and then fuse them, similar to the dual-stream methods in visual learning representation VLP. Ren et al. treat image embeddings as language tokens, akin to single-stream methods.
C. Image-Text Matching
Task Definition: Image-text matching (ITM), or image-text retrieval, is one of the fundamental tasks in the visual domain. Given a query of a specific modality (visual or language), the goal is to find the semantically closest target from another modality. Depending on the query and target modalities, it includes two sub-tasks: image-text retrieval and text-image retrieval.
Methods: The core of image-text matching is to compute the similarity or distance between images and texts. A widely adopted model maps images and texts into a shared embedding space and then calculates their similarity. The matched image results are expected to have the highest similarity with the sentence.
Early methods primarily used global features to encode image-text information. Kiros et al. proposed a cross-view representation method based on hinge-based triplet ranking loss. Faghri et al. considered the hard negative sample factor to improve performance. Karpathy et al. proposed “Deep Fragment,” which was the first attempt to use fine-grained representations on both the image and text sides.
The architecture of “Deep Fragment” is illustrated in Figure 4. Unlike directly representing the entire image and sentence, this method maps each image fragment and sentence fragment into a cross-modal embedding space. It then arranges fragments across different modalities. Since an image region may correspond to multiple words, they find the most similar region for the embedding of each word. The similarity between the image and sentence is the sum of the similarities of aligned word pairs and region pairs.
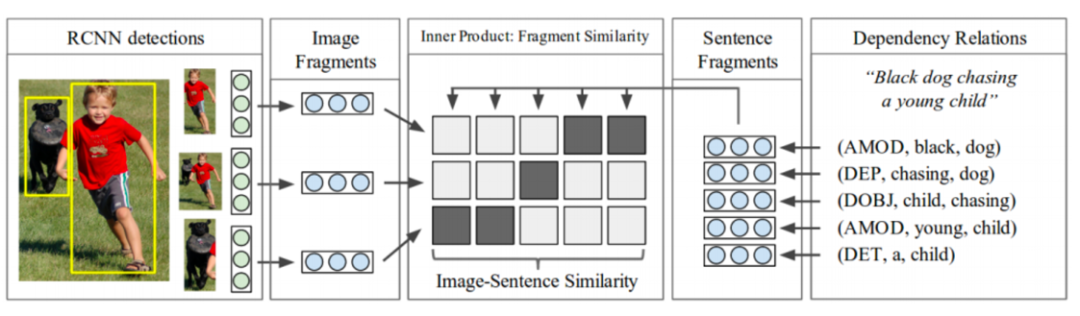
As shown in Figure 4, the Deep Fragment structure overview. Left: Mapping detected objects into fragment embedding space. Right: Dependency tree relationships are encoded into fragment embedding space.
Since attention mechanisms have achieved great success in other visual learning tasks, Huang et al. (2016) proposed introducing attention mechanisms into image-text matching (ITM). They developed a contextually adaptive attention scheme to focus on instance pairs appearing in both the image and text. Nam et al. (2017) proposed a dual attention framework that focuses on specific regions in the image and text through multiple steps and collects important information from both modalities.
These methods demonstrate the effectiveness of attention mechanisms in ITM tasks. However, they also have limitations, such as being based on multi-step methods and only focusing on one semantic part at a time. Lee et al. (2018) proposed a cross-attention algorithm called SCAN for computing similarity between images and sentences. To achieve cross-attention mechanisms, they represent images as a set of regions and sentences as a set of words. The core idea of cross-attention is to use the sentence as a query to focus on image regions while also using the image as a query to focus on words.
In simple terms, image-text matching is essentially a problem of calculating the similarity between images and texts. Early studies encoded images and texts into global features and calculated their cosine similarity through dot product. In subsequent works, fine-grained features—object-level features to represent images and word-level features to represent language—were adopted. They also developed more complex algorithms to calculate similarity, such as cross-attention methods.
D. Other Tasks
In the interdisciplinary field of visual-language, there are many tasks that we cannot elaborate on in detail. Therefore, we briefly list some important tasks below, including:
Text-to-Image Generation: Given a piece of text, generate an image containing the content of that text. More details on this part can be found in section IV-B of the article.
Visual Dialogue: Given an image, a history of dialogue, and a question about the image, answer that question.
Visual Reasoning: Similar to the VQA task that requires answering questions about the input image, visual reasoning requires further understanding of the image. Visual reasoning tasks typically include sufficient annotations about the objects in the image, question structure, etc.
Visual Entailment: Given an image and a piece of text, determine whether the image semantically contains the input text.
Phrase Grounding and Referring Expression Understanding: These two tasks require a model to output bounding boxes corresponding to the text. For phrase grounding, the text consists of a set of phrases; for referring expression understanding, the text is an expression.
During the era of specific task methods, researchers designed specific models for different tasks. Although the models for different tasks vary significantly, they follow a similar trajectory. They all have three stages, as shown in Figure 1. The technical developments of this era laid the foundation for the VLP era.
3Visual-Language Joint Representation
Pre-training and fine-tuning paradigms have been widely applied in multiple fields and various downstream tasks. The most important reason for utilizing popular large-scale pre-training is the availability of vast datasets and the rapid development of GPUs. Following the success of unimodal language/visual pre-training, researchers began to explore joint representations of language and vision, leading to the proposal of cross-modal VLP models.
In recent years, the rise of VLP models has been primarily inspired by architecture designs and training methods in language models. One of the most significant breakthroughs was the Transformer developed by Vaswani et al. in 2017, which improved language representation. By using multiple stacked attention layers, the Transformer can globally fuse information across language tokens with high parallelism, facilitating efficient representation and large-scale training.
A successful application of the Transformer is BERT, which utilizes the Transformer encoder and introduces a bidirectional masking technique that allows each language token to attend to other tokens in both directions. As illustrated in Figure 5, training is conducted by replacing some text tokens with a special [MASK] token (i.e., masking) and using its context information to predict each [MASK].
This technique can frame language representation training as a denoising process, where the input sentence learns to reconstruct itself using some noisy tokens. This denoising training forces the tokens with [MASK] to utilize all the information from the tokens without [MASK], resulting in contextualized representations.
The architecture design and masking training techniques based on the Transformer language model are the main principles behind various cross-modal developments, which have facilitated the recent surge of VLP models. Figure 5(b) shows a simple cross-modal BERT. Similar to language training, it tokenizes images and embeds them along with language tokens, which will be detailed later. Typically, tokenized visual features and text features are input together into a Transformer encoder with masked language training to learn joint representations.
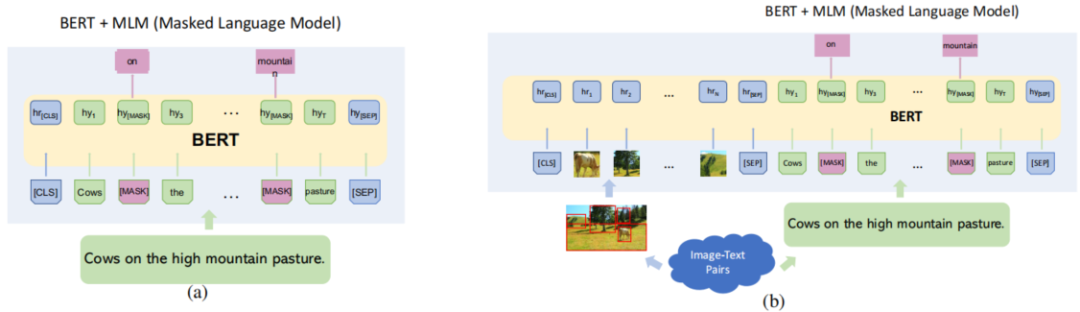
Figure 5 (a) The original unimodal BERT, in which some language tokens are hidden for prediction to train language representations. (b) The multimodal improved BERT, where both image and language tokens are input into a BERT-like Transformer model.
In this section, we will introduce the main components of VLP models. As shown in Figure 6, VLP models primarily consist of three parts: Visual Embedding (VE), Text Embedding (TE), and Modality Fusion (MF) modules. VE and TE are typically pre-trained using images and texts, respectively, while MF fuses the features extracted by VE and TE with image-text pre-training.
The goal of VLP is to learn object-level language-aligned and semantically rich visual representations. Object-level means that the learned representations are detailed and aligned with objects rather than targeting the entire image. Research results using features of detected objects to represent images are object-level. Semantically rich aims for a representation that can generalize to a wide range of semantic concepts and requires learning from large-scale datasets.
Pre-training on massive datasets is crucial for enhancing the performance of downstream tasks using smaller datasets, as the learned representations can transfer to downstream tasks. VLP models have proven to be very effective methods to support downstream tasks.
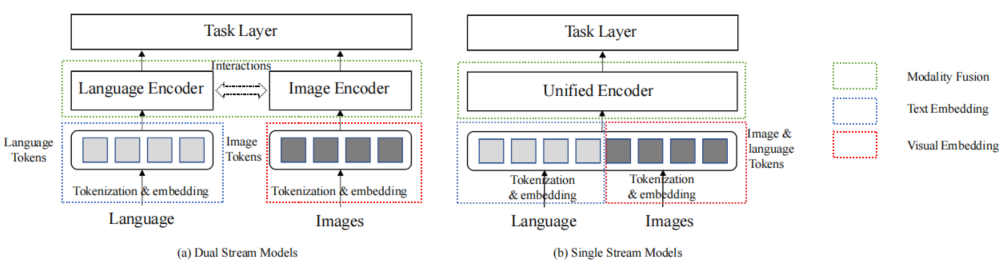
Figure 6 The architecture of VLP models typically includes Visual Embedding (VE), Text Embedding (TE), and Modality Fusion (MF). (a) is a dual-stream model, (b) is a single-stream model. In the dual-stream model, modality fusion is optional and is accomplished through interaction between the language and image encoders (usually cross-attention). In the single-stream model, modality fusion is completed in a unified encoder (typically a multi-layer transformer).
A Why Pre-training is Necessary
Deep learning is essentially a data-driven statistical method aimed at learning mapping functions from seen data to predict new data using the learned mapping function. It is important to note that the ultimate goal is to achieve good performance on new data. In statistical terms, such a goal is represented as minimizing the expected loss over the entire data space, which follows a fixed but unknown distribution. However, since the distribution is unknown, this expected loss minimization is not easy to handle.
In practice, data must be sampled from this distribution, and the empirical loss is defined as a substitute for the expected loss. This may sound strange, but it is actually a common practice in machine learning. For instance, for the image classification problem of determining whether an input image contains a cat, the most practical approach is to collect training images with and without cats and train the classifier by minimizing the empirical loss defined on that training set. However, the distribution of images with and without cats is indeed unknown.
Statistical learning theory indicates that for independent and identically distributed (iid) data sampled from a sufficiently large unknown distribution, the result of empirical loss minimization converges to the result of expected loss minimization. In other words, asymptotically, iid samples can be used to approximate the loss function defined by the unknown distribution. However, in practice, data is never sufficient to represent the unknown distribution, leading to many pitfalls, such as poor performance when using new training sets and vulnerability to adversarial attacks.
Pre-training allows people to leverage an infinite amount of unlabeled (or weakly labeled) data to learn features relevant to downstream tasks. Such large-scale datasets help better define the expected loss approximation, allowing for learning more robust and realistic patterns from data. Due to the shared model between the pre-training and fine-tuning phases, the features learned after fine-tuning can achieve high accuracy when used for downstream tasks under very limited (e.g., few-shot) supervision. This makes the pre-training and fine-tuning paradigm an effective solution to address (or alleviate) the data scarcity problem.
B. Modality Embedding
Text and images are fundamentally different levels of information regarding dimensions and structures. To address this modality difference, modality embedding is typically employed, which involves independently extracting features from each modality and then mapping the features into a shared feature space. As illustrated in Figure 6, modality embedding involves visual embedding and text embedding, both of which include tokenization processes and embedding processes. Visual embedding aims to follow the principles of text embedding, converting images into multiple tokens whose feature levels correspond to text tokens. Ablation studies conducted by Bugliarello et al. have demonstrated that the training of datasets and hyperparameters is the main reason for performance improvements across many different VLP models, emphasizing the importance of modality embedding.
1) Text Tokenization and Embedding
Before text embedding, the text should be tokenized. Considering the discrete nature of language, early works simply treated each word as a token. A pioneering study is Word2Vec, which proposed a continuous CBOW and a skip-gram model to train word vector representations. Word2Vec is computationally efficient, can scale to large corpora, and produces high-quality embeddings.
However, despite its vocabulary size of around one million, this method suffers from vocabulary insufficiency due to rare or unseen words, making it difficult to learn subword units such as “est.” To address this issue, Sennrich et al. proposed a subword tokenization method using byte pair encoding (BPE), which splits words into smaller units. Subword tokenization is widely used in many language models, including BERT.
Most VLP models adopt text embeddings from pre-trained BERT. Since BERT is trained using a transformer encoder with masked learning, it possesses strong bidirectional representation capabilities.
2) Visual Tokenization and Embedding
Unlike language tokens that are discrete and arranged in a single dimension, images come from high-dimensional spaces and have interrelated pixel values. Therefore, image tokenization is generally more complex than text tokenization. Essentially, image tokenization can be divided into region-based, grid-based, and block-based methods, which will be introduced separately below.
-
Grid features are directly extracted from equally sized image grids by convolutional feature extractors. For example, Huang et al. (2021) used grid features as image embeddings for their VLP model. The advantages of grid features are mainly twofold: first, they are convenient as they do not require a pre-trained object detector. Second, in addition to salient objects, grid features also contain background information that may be useful for downstream tasks.
-
Region features are extracted by pre-trained object detectors. Recent VLP models have adopted region features to learn object-level representations. Specifically, based on the work of BUTD, most VLP models use Faster R-CNN trained on the Visual Genome (VG) dataset as region feature embeddings. Region features consist of three basic components: bounding boxes, object labels, and RoI features (feature vectors after RoI pooling). Bounding boxes are typically used in VLP as position indicators, transformed to the same dimensional space as RoI features and added to RoI features. Object labels are widely used in training methods, such as Masked Region Classification, which will be detailed later in III-D3. The advantage of region features is that they help VLP models focus on meaningful areas in the image, which are often closely related to downstream tasks.
-
Block features are typically extracted through linear projections on uniformly divided image blocks. The main difference between block features and grid features is that grid features are extracted from the feature maps of convolutional models, while block features utilize linear projections directly. The concept of block features was first introduced by the Vision Transformer (ViT) and then adopted by VLP models. The advantage of using block features is efficiency. For instance, ViLT accelerated pre-training speed by ten times, achieving competitive results.
Image embedding methods often vary due to different tokenization schemes. Grid features and region features typically come from pre-trained convolutional models, while block features can be simply embedded through linear layers.
C. Modality Fusion
The core of VLP models is modality fusion, which models intra-modal and inter-modal fusion to produce contextual joint representations of images and texts. The MF mode can be divided into dual-stream modeling and single-stream modeling. The general structure of VLP is illustrated in Figure 6.
1) Dual-Stream Modeling: Dual-stream modeling aims to map visual and language modalities into the same semantic space. It is a pioneering method for modality fusion. As shown in Figure 6(a), it employs two independent encoders to learn high-level representations of visual and language modalities, respectively. The dual-stream design allows the network depth and architecture to adapt to each modality. In addition to intra-modal fusion within each modality, some studies also explicitly design inter-modal interactions between the two encoders to achieve modality fusion at different encoding stages.
2) Single-Stream Modeling: Single-stream modeling aims to learn a joint representation. Image and text tokens are concatenated and input into the Transformer, as illustrated in Figure 6(b). Most VLP models adopt this modality fusion scheme. Single-stream modeling performs implicit intra-modal and inter-modal fusion, unconstrained by the architectural design of fusion stages in dual-stream modeling.
D. Training
To learn joint representations of vision and language, visual-language models are typically pre-trained on large datasets using multiple self-supervised learning loss functions. Currently, there are mainly three pre-training methods: Image Text Matching (ITM), Masked Language Modeling (MLM), and Masked Visual Modeling (MVM).
1) Image-Text Matching:
ITM aims to predict whether a pair of image and text matches. ITM can be formulated as a binary classification task. Previous works applied the sigmoid function on the output of a special token [CLS] to predict whether the input image and text match. The loss function is:
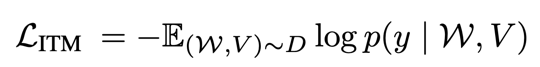
where X represents a sequence of language symbols, Y represents the visual content. y indicates whether the image is matched or unmatched.
2) Masked Language Modeling:
Chen et al. (2020) utilized MLM to incentivize the model to learn the implicit relationship between language tokens and visual content. The goal is to reconstruct masked language tokens based on known language tokens and visual content. This goal can be formulated as:
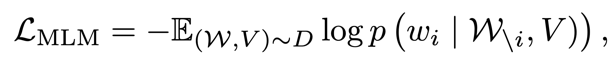
where X represents the sentence without the i-th word. Note that while BPE is typically used for language tokenization, the smallest masked unit is a complete word rather than a subword. This is because, due to information leakage, subwords can easily be predicted from surrounding subwords.
There are also improved versions of MLM. For example, Sun et al. (2019) proposed a knowledge masked language model that performs phrase-level masking and entity-level masking, integrating phrase-level and entity-level knowledge into language representation. For entity-level masking, they treat named entities as a whole. For example, J.K. Rowling contains three symbols and should be masked together in entity-level masking. Phrase-level masking masks all tokens belonging to a phrase and predicts them simultaneously.
3) Masked Visual Modeling:
Inspired by MLM, MVM is designed to learn more realistic visual representations by reconstructing masked visual content. Since the information density of images is lower than that of language, MVM poses greater challenges than MLM. When reconstructing missing words, complex understanding of language is required.
In contrast, missing image patches can be recovered from neighboring patches without requiring cross-modal understanding. To bridge this gap, most works mask information-dense target regions. Other works, such as SOHO, utilize a visual dictionary (VD) to represent visual domains more comprehensively and compactly, allowing them to apply MVM like MLM. In summary, there are mainly four MVM schemes.
1) Masked Region Prediction (MRP): MRP minimizes the distance between features predicted for masked regions and those outputted by a trained object detector.
2) Masked Region Classification (MRC): MRC requires a model to predict the semantic category of each masked region.
3) Masked Region Classification with KL-divergence (MRC-KL): Due to the inaccurate target labels of MRC, MRC-KL uses soft labels as supervisory signals, which are the raw outputs of the object detector after SoftMax.
4) Masked Visual Modeling with Visual Dictionary (MVMVD): Similar to language models with vocabulary dictionaries, MVMVD requires a visual vocabulary dictionary (VD). The goal of MVMVD is to reconstruct masked VD tokens.
Two points are worth noting. First, to encourage cross-modal fusion, some works, such as UNITERVL, only mask tokens from one modality at a time during training to encourage the masked tokens to process missing information from another modality. Second, since adjacent image grids are highly correlated, MVMVD tends to map to the same VD tokens; when performing reconstruction, the model can directly copy the surrounding tokens.
Therefore, all visual embedding vectors mapped to the same VD token are masked together in SOHO. Despite the aforementioned methods, effective visual modeling remains a challenging issue. Results from ablation studies of some VLP models (such as SOHO) indicate that increasing MVM tasks only yields minor additional improvements in performance. Cao et al. (2020) found that VLP models tend to focus on textual information rather than visual information in downstream tasks.
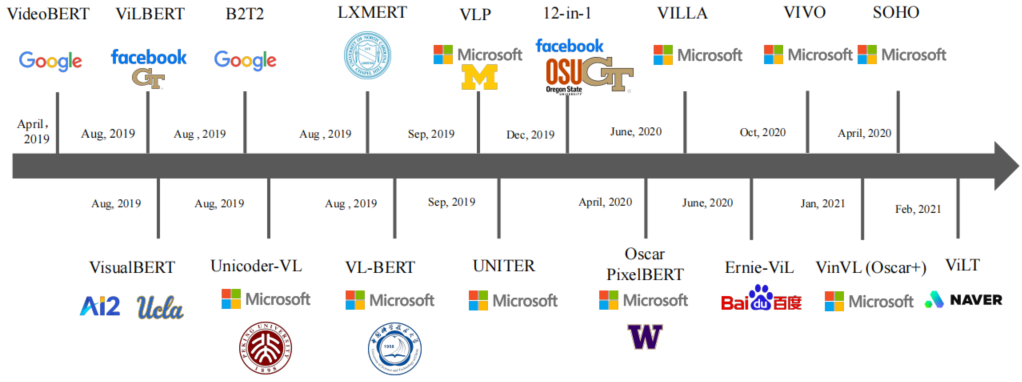
Figure 7 Overview of VLP methods. Research outcomes are categorized by publication time. We also show the logos of the main institutions from which each work originates.
E. Overview of Pre-training Research
This section summarizes some pioneering works in cross-domain VLP after introducing the general workflow of VLP models. Inspired by the success of NLP and CV pre-training, research in the VLP field has surged in recent years, seeking unified cross-modal representations. The landscape of VLP research outcomes is illustrated in Figure 7. We elaborate on some representative studies in this section.
Single-Stream Models: VideoBERT is a pioneering work for learning joint representations of video and language. Its main idea is to input visible and textual tokens into a single-stream model built on BERT. Text tokens are extracted by converting video speech into text using automatic speech recognition methods, while visual tokens are obtained by extracting features from video clips using convolutional backbones. VideoBERT can perform a wide range of downstream classification and generation tasks, including video captioning and zero-shot masked verb/noun prediction. Notably, VideoBERT is pre-trained using cooking videos, which are instructional and of high quality. It assumes that the spoken language aligns with the visual content, which limits its application to certain types of videos (e.g., instructional videos). Another limitation affecting its generalizability is its carefully designed subtitle text templates, such as the template: now let’s [MASK] the [MASK] to the [MASK], and then [MASK] the [MASK], which only applies to cooking videos.
Li et al. proposed a simple single-stream VLP model called VisualBERT. The extracted visual and text tokens are directly combined and input into the Transformer, allowing implicit cross-modal fusion within the Transformer. Similar to VisualBERT, several parallel studies, such as Unicoder VL, VL-BERT, and UNITER, also adopt single-stream architectures. These VLP studies share several similarities: 1) they all utilize object detection backbones to compute image embeddings; 2) they all employ masked language modeling tasks; 3) they all use single-stream BERT architectures. However, they differ in the pre-training methods and datasets used.
Dual-Stream Models: ViLBERT and LXMBERT are pioneering works that extend BERT to dual-stream VLP models. They are pre-trained on the Conceptual Captions dataset and utilize pre-trained Faster R-CNN models to detect regions as visual tokens. ViLBERT processes visual and textual tokens in two parallel streams, which can fuse cross-modal information through cross-attention layers when needed. In other words, ViLBERT assumes different processing architectures for visual and language modalities. Its cross-modal fusion design is a sparse and explicit fusion between the two processing streams. LXMBERT differs from ViLBERT by decoupling intra-modal and inter-modal processing. More specifically, visual tokens and text tokens are encoded separately in the first stage and then input into a cross-modal encoder to produce joint representations.
Other Fusion Methods: Fundamentally, single-stream modeling and dual-stream modeling differ in the timing of fusion, where single-stream prefers early fusion of different modalities while dual-stream favors extracting high-level features from each modality before fusion. SemVLP proposes combining these two popular modeling architectures through iterative training. This approach leverages both architectures and performs cross-modal semantic alignment at both low and high levels. Specifically, the Transformer encoder shares across the two modeling methods, with an additional cross-modal attention module added in the dual-stream encoder to aid in semantic alignment and reduce parameters. Most VLP models attempt to encode visual and language as separate tokens that interact explicitly or implicitly through modality fusion. Another class of VLP models attaches visual tokens to text tokens based on object detection models. B2T2 proposes to fuse features of detected objects into text tokens, performing MLM and ITM during pre-training. In B2T2, the token T can be represented as:
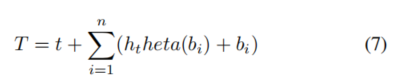
where t is the original text embedding, n represents the number of detected objects, f represents the embedding of the bounding box of the j-th object, and v represents the visual features extracted from the bounding box. B2T2 also analyzes the stages of fusing object and text tokens. The results demonstrate the effectiveness of early fusion.
Early Attempts to Bridge Modality Gaps: To achieve generative and understanding tasks, Zhou et al. proposed a unified visual-language pre-training method. It introduces two masking schemes, namely bidirectional attention masking and sequence-to-sequence masking, to enhance both understanding and generative tasks. Notably, this unified VLP approach only employs MLM during pre-training and achieves competitive performance in image captioning and VQA.
12-in-1 extends multi-task training to four broad tasks and is pre-trained on twelve datasets. Experimental results indicate that multi-task training can consistently improve performance on downstream tasks and produce lighter models with fewer parameters.
VILLA, based on UNITER’s design, introduces adversarial training into visual and text tokens at the embedding level. It performs adversarial training by adding perturbations in the embedding space as regularization, resulting in significant performance improvements.
Inspired by ERNIE’s knowledge masking scheme, structured knowledge has been incorporated into the VLP model of ERNIE-ViL. To develop better cross-modal semantic alignment, ERNIE-ViL proposes a scene graph prediction task to model objects, attributes, and relationships in the graph to learn object-level and attribute-aware representations. Incorporating knowledge into cross-modal training is challenging and remains an open question.
Grid & Patch Features: While the popularity of region feature embeddings has facilitated the training of VLP models, it has also limited the scalability and generalization capabilities of VLP models. Analysis shows the weaknesses of region features from Faster R-CNN:
-
Limited Number of Categories: Visual features are constrained by object detection models trained on relatively small datasets with predefined object categories. For instance, the Faster R-CNN model widely adopted in BUTD was trained on VG, which has a fixed number of 1594 object classes and 524 attributes.
-
Low Quality: Since the Faster R-CNN model is trained on well-labeled small datasets, region features are often affected by low quality.
-
Lack of Context: Region features extract RoI features belonging to specific categories without any background information, leading to the neglect of the semantic relationships between these region features. In fact, these semantic relationships are important.
PixelBERT attempts to break this limitation by learning directly from pixel features to fully utilize visual information. To reduce computational costs and improve model robustness, it does not use all pixels as visual features but randomly samples 100 pixels during pre-training. However, experimental results indicate that random sampling only slightly improves performance, with VQA scores in downstream tasks falling below 0.5.
SOHO is another pioneering work that utilizes grid features for cross-modal understanding. To learn a comprehensive semantic representation of visual context, SOHO proposes a learning method for visual tokenization using a visual dictionary (VD). SOHO learns the VD by first obtaining high-level features from convolutional networks, then grouping these features based on similarity, and feeding them into a moving average encoder for dynamic updates of the VD.
Since visual embeddings are trainable, SOHO is an end-to-end pre-training framework that can learn directly from pixels without requiring bounding boxes. Through dynamic VD updates during the training process, the sequence number of each token in the VD can be treated as a label, allowing for natural execution of masked visual modeling. For the pre-training task, SOHO proposes a novel MVMVD method (described in III-D3) to simultaneously mask all visual tokens of the same label in the image, avoiding any information leakage.
The aforementioned image embeddings based on regions or grids are computationally intensive, and the extracted high-level features hinder early fusion of cross-modal information. Inspired by ViT, ViLT adopts simple linear projections of image patches as visual embeddings, accelerating pre-training speed by ten times and achieving competitive experimental results. This suggests that compared to visual embeddings, modality fusion is more likely to be the key to improving VLP model representations.
Improving Alignment Representations: Visual-language alignment representation is a fundamental goal of VLP. To achieve this goal, some studies have proposed that additional object-level data can be adopted in VLP. For instance, many VLP methods have adopted RoI region features and detection models. However, the detected object labels, which are important components, have not been explicitly modeled in VLP models. To leverage this additional information, Oscar introduces object labels as anchors to assist in learning cross-modal aligned representations. This learning process is empirically natural, as detected object labels frequently appear in the text paired with images, aiding in aligning visual and language.
Moreover, training with object labels helps learn co-occurrences of objects (e.g., words that commonly appear with object words). Therefore, Oscar achieves significant improvements in downstream understanding and generation tasks. However, the drawbacks of Oscar are also evident; it relies on well-labeled image caption datasets, making it challenging to scale up training.
Due to the insufficient alignment of (image, caption) pairs in VLP models, VIVO suggests using a large number of (image, label) pairs to increase the degree of pre-training. VIVO employs Hungarian matching loss for masked label prediction, enabling visual vocabulary learning and enhancing the model’s ability to generalize to new objects in downstream tasks. It first surpassed human performance on the NoCaps benchmark. More specifically, it utilizes ResNeXt152-C4 and merges four public datasets, including VG, COCO, Objects365, and OpenImagesV5 for large-scale training. Compared to VLP models like VIVO and Oscar, VinVL has made significant improvements, achieving the best results on NoCaps, image captioning, and VQA leaderboards.
4Scaling Up Models and Data
Although researchers have made encouraging progress in visual-language joint representations, most of the above studies primarily focus on pursuing good cross-modal aligned object-level representations. Moreover, they operate under a high-threshold assumption: that image and text pairs are well-labeled. This assumption limits the training datasets to relatively small ones with “golden labels.” For example, Conceptual Captions is the largest public dataset widely used for VL pre-training, containing 3 million image-text pairs.
To enable models to acquire richer semantics and stronger generalization capabilities, researchers urgently need larger weakly labeled datasets, such as web-crawled datasets. CLIP and DALL-E are the first successful practical cases of utilizing large-scale web-crawled data for pre-training. Inspired by the success of CLIP and DALL-E, several recent studies have further constructed more powerful models based on larger datasets.
This section aims to introduce models trained using large-scale weakly labeled datasets. The section is divided into two parts. The first part includes works that utilize large-scale datasets for visual understanding, such as CLIP, ALIGN, SimVLM, and Florence. The second part includes visual generative models based on large datasets such as DALL-E, GODIVA, and NUWA.
A. Visual Understanding
The core idea of CLIP is its training method. Unlike other VLP methods that predict masked visual or textual tokens through training, CLIP learns to recognize paired images and texts. The goal of CLIP is: given a batch of N (image-text) pairs, CLIP should be able to predict which of the N × N possible pairs are matching pairs (positive samples) and which are non-matching pairs (negative samples). After pre-training, CLIP can perform zero-shot image classification by using phrases like “a photo of” along with category names to tell the model which categories the input image is most similar to, outperforming the fully supervised baseline in 16 out of 27 datasets.
Similar to CLIP, ALIGN also employs a dual-encoder model with contrastive loss for zero-shot tasks. It utilizes a larger raw dataset containing 1.8 billion image-text pairs. ALIGN outperforms CLIP on many zero-shot visual tasks, demonstrating that training on larger datasets yields better performance.
In addition to visual tasks, ALIGN also outperforms previous works in image-text retrieval tasks. SimVLM develops a new VL pre-training method. It follows a simple prefix language modeling objective to predict the next token in an autoregressive manner. It achieves competitive results on multiple VL tasks and has text-guided zero-shot learning capabilities. Unlike previous works that employed coarse (image-level) representations and static (image) data, Florence adopts fine-grained (object-level) representations and extends to dynamic (video) data. For object-level representations, researchers added a Dynamic Head adapter to the image encoder in Florence and trained using additional object detection datasets. By pre-training on 900 million pairs of image-text pairs, Florence achieved new state-of-the-art results in most of the 44 representative benchmarks.
Aside from zero-shot classification, CLIP can also assist in detection. For instance, ViLD proposed a zero-shot detector distilled from CLIP. Other studies indicate that CLIP can learn multimodal features that resemble neurons in the human brain, and it can also assist in completing VL tasks.
B. Visual Generation
In addition to visual understanding, large-scale weakly labeled image-text paired data can also assist in generating text-to-image. Ramesh et al. (2021) developed an image generation system called DALL-E. DALL-E uses a discrete variational autoencoder (dVAE) to convert images into discrete visual tokens, treating a (text, image) pair as a single data stream.
During training, the text-image stream is fed into a Transformer that serves only as a decoder. When applying attention masks, each image token can see all text tokens. The attention mask between text tokens is a standard causal mask. The attention between images utilizes row, column, or convolutional attention masks. During inference, given text tokens, the generation process predicts image tokens in an autoregressive manner, just like in GPT. DALL-E demonstrates impressive results in four aspects: creating anthropomorphized versions of animals and objects, combining unrelated concepts, rendering text, and applying transformations to existing images.
Inspired by DALL-E’s training methods, Wu et al. (2021a) proposed a method called GODIVA to generate videos from text. Similar to DALL-E, GODIVA tokens each frame of the video and sequentially connects text and visual tokens to train the model. DALL-E and GODIVA are designed for text-to-image generation and text-to-video generation, respectively, while Wu et al. (2021b) proposed a unified visual generation model that achieves state-of-the-art results across eight downstream tasks, including text-to-image, text-to-video, and video prediction.
They proposed a 3D Transformer that can encode all three data formats, including text (1D), image (2D), and video (3D). To optimize video effects, they also designed a 3D Nearby Attention to apply attention along spatial and temporal axes.
5Future Trends
In the past few years, we have witnessed how VLP models have gradually utilized large amounts of weakly labeled and more diverse data. In the future, both the scale of models and data will continue to expand, achieving stronger modality cooperation and even unified representations. Furthermore, integrating knowledge can further enhance VLP models, enabling them to achieve better generalization capabilities. In this section, we will discuss these future trends.
A. Towards Modality Cooperation
In addition to improving cross-modal tasks using VL datasets, modality cooperation techniques are gradually being utilized in pre-training to enhance the performance of both unimodal and multimodal tasks. Modality cooperation refers to different modalities helping each other to learn better representations. For example, using visual data to improve language tasks and using unimodal data to enhance cross-modal tasks.
-
Utilizing Visual Data to Improve Language Tasks
Researchers have attempted to leverage visual information to improve language learning and explored a wide range of language tasks, including machine translation, semantic parsing, and language grounding. These research explorations are tailored for specific language tasks, and there may be modality differences among these findings.
Tan and Bansal (2020) proposed a general pre-training model with visual-assisted language representations, introducing a “vokenization” model to extrapolate visual-language alignment from image captioning datasets to pure language corpora. More specifically, the “vokenization” model is trained using image-text matching pairs to construct a visual image vocabulary, which is then used to map text tokens in language-only datasets to retrieved highest-scoring images. Experimental results show that its performance has made additional progress compared to self-supervised language models.
2. Using Unimodal Data to Improve Cross-modal Tasks
To address data scarcity issues, some VLP models utilize additional unimodal data to enhance representation capabilities. For instance, in image-text datasets, text is often short, containing only a few tokens, which limits the representation power of the text. Therefore, researchers added additional language corpora to VL-BERT to improve the language component in cross-modal tasks.
B. Towards General Unified Modality
Thanks to the Transformer architecture, researchers have made significant progress in both unimodal and multimodal representation learning. In the previous sections, we discussed multimodal representations and modality cooperation, which connect vision and language in different ways. Currently, a larger goal in this field is to establish a general representation model that can unify multiple modalities.
In a pioneering work, UNIMO proposed a unified pre-training model that can simultaneously handle both unimodal and multimodal downstream tasks, including understanding and generation. It utilized a large amount of unimodal and cross-modal data for pre-training, including BookWiki (Zhu et al., 2015) and OpenWebText (language data), OpenImages (Krasin et al., 2017) and COCO (Lin et al., 2014) (image data), COCO (Lin et al., 2014), Visual Genome (Krishna et al., 2016), Conceptual Captions (Sharma et al., 2018), and SBU (Ordonez et al., 2011) (image-text data).
As a result, UNIMO has significantly improved performance when executing many unimodal and multimodal downstream tasks. Another interesting research outcome is the general visual system developed by Gupta et al., which can be used for a range of visual and cross-modal tasks.
C. VL + Knowledge
Models performing VL tasks often require common sense and factual information that goes beyond the training dataset to complete many tasks. However, most VLP models lack mechanisms for consuming additional knowledge.
ERNIE proposed a knowledge-based multi-stage masking strategy. This method does not directly add knowledge embeddings but masks language at three levels: foundational level, phrase level, and entity level. For entity-level masking, the model masks entire entities rather than subwords. Such entities include people, places, organizations, products, etc. There is also a method for integrating knowledge into VLP models.
Shevchenko et al. (2021) proposed directly injecting knowledge embeddings into the visual-language Transformer. They first built a knowledge base (KB) using knowledge embeddings and then matched sentences in the training data with knowledge embeddings. During training, they used auxiliary loss to encourage the learned representations to align with the knowledge embeddings. Although some research has attempted to integrate knowledge into VLP models, many challenges remain to be addressed, such as how to effectively utilize large noisy Wikipedia data and how to learn from knowledge in an interpretable manner.
THE END
Long press the QR code to follow CAAI for more media matrix

Official WeChat

Membership Number

English Official WeChat