
Machine Heart Report
Contributors: Si Yuan, Qian Zhang
The championship throne of XLNet has not yet warmed up, and the plot has once again taken a turn.
Last month, XLNet comprehensively surpassed BERT on 20 tasks, creating a new record for NLP pre-training models and enjoyed a moment of glory. However, now, just a month after XLNet dominated the rankings, the plot has taken another turn: Facebook researchers stated that if BERT is trained a bit longer and with more data, it can return to SOTA.
They named the improved version of BERT RoBERTa, which is currently at the top of the GLUE leaderboard.
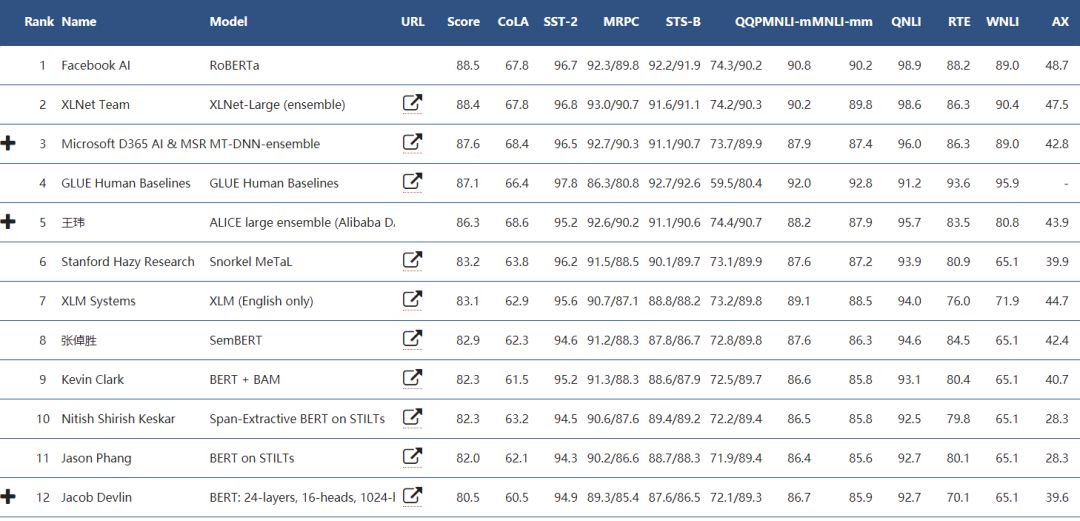
Facebook AI stated: “RoBERTa stands for Robustly Optimized BERT Pretraining Approach. We used BERT-Large and enhanced the pre-training process through more data and longer training, with the final results obtained through model ensemble.“
We calculated that XLNet used 126GB of plain text, with TPU costs amounting to $61,400. If RoBERTa requires even more training resources, how much would that be?
From BERT to XLNet
In 2018, Google released BERT, a large-scale pre-training language model based on bidirectional Transformers, which refreshed the optimal performance records of 11 NLP tasks, bringing great surprises to the NLP field. Soon, BERT became widely adopted in the community, leading to many new works related to it.
From the GLUE benchmark leaderboard, BERT is currently ranked 12th, but a closer look at the leaderboard reveals that many of the top models are improvements based on BERT, such as SemBERT at 8th, BERT+BAM at 9th, and BERT on STILTs at 11th.
However, some researchers have taken alternative paths, attempting to build pre-training models that can surpass BERT using other methods, such as the recently dominating XLNet. XLNet was proposed by researchers from Carnegie Mellon University and Google Brain, comprehensively surpassing BERT on 20 tasks including SQuAD, GLUE, and RACE, achieving state-of-the-art results on 18 tasks, including machine question answering, natural language inference, sentiment analysis, and document ranking.
XLNet is a generalized autoregressive pre-training model. Researchers indicated that this model overcomes some shortcomings of BERT: 1) By permuting the language model, it removes BERT’s independence assumption on masks; 2) It does not use masks in pre-training, addressing the issue of downstream NLP tasks lacking mask labels. These two major improvements make XLNet more suitable as a pre-training language model compared to BERT.
Researchers indicated in XLNet that if XLNet-Base has the same parameter count and data volume as BERT-Base, then XLNet’s performance would still be slightly better. This indicates that XLNet itself has significant advantages in terms of task and architecture improvements.
Data and Computing Power Are the Keys to the GLUE Benchmark
A few hours ago, Facebook AI tweeted that as long as the data is large enough and the computing power is sufficient, BERT still has significant room for improvement. Even compared to the improved XLNet in terms of tasks and architecture, RoBERTa shows more improvements in 6 NLP tasks.
First, regarding data, XLNet not only uses the two standard datasets (BooksCorpus and Wikipedia, totaling 13GB) used by the original BERT, but also additionally uses three large text datasets (Giga5, ClueWeb 2012-B, and Common Crawl, totaling 113GB), making its data volume extremely vast. So how large would RoBERTa’s data need to be to surpass XLNet?
Secondly, regarding computing power, XLNet’s first author, Yang Zhiling, indicated to Machine Heart that they used Google’s internal TPU computing power, so they did not feel much of the cost. However, based on XLNet’s large model training for 2.5 days on 128 Cloud TPU v3, this cost is generally unaffordable for academic research institutions. Only tech giants like Facebook can afford “larger” computing power.
Finally, the reason it is said that BERT is reclaiming SOTA is that Facebook AI indicated they used the original implementation of BERT-Large. Although the official paper or blog has not yet been released, we know that its core is BERT, possibly with some modifications for more robust training.
Looking at it this way, both the recently significantly improved XLNet and the later RoBERTa that caught up have greatly enhanced data volume and computing power. Perhaps it is under the influence of both that the GLUE benchmark keeps updating.
This article is reported by Machine Heart, please contact this public account for authorization.
✄————————————————
Join Machine Heart (Full-time reporter / Intern): [email protected]
Submissions or seeking reports: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]