

BERT is a bidirectional transformer designed to leverage a large amount of unlabeled text data for pre-training, thereby learning and mastering a certain linguistic expression. More importantly, this expression can be further fine-tuned for specific machine learning tasks. Although BERT has brought practical performance that surpasses past state-of-the-art NLP technologies in multiple tasks, its performance enhancement is mainly attributed to the bidirectional transformer, masked language model, and next structure prediction, along with Google’s powerful data resources and computing capabilities.
Recently, various new methods aimed at improving BERT’s predictive metrics or computational speed have emerged in the NLP industry, but it has always been challenging to achieve both improvements simultaneously. Among them, XLNet and RoBERTa have pushed performance to new heights, while DistilBERT has improved inference speed. The table below compares the characteristics of various methods:
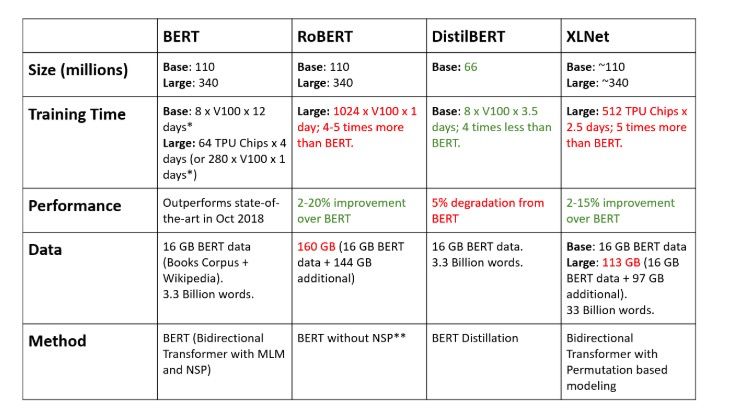
Comparison of improvement effects of BERT and recent related methods: * GPU time is an estimate (initial training for 4 days using 4 TPU Pods); ** Using a large number of small batch data, the learning speed, step size, and masking process of each method vary during the longer training period; *** Unless otherwise specified, relevant data comes from the original papers.
XLNet is a large bidirectional transformer that employs an improved training method. This training method allows it to leverage larger datasets and more powerful computing capabilities to achieve better predictive metrics than BERT across 20 language tasks.
To improve the training method, XLNet introduces permutation language modeling, where all tokens are predicted in a random order. This sharply contrasts with BERT’s masked language model. Specifically, BERT only predicts the masked portions of the text (which account for only 15%). This approach also disrupts the convention in traditional language models where all tokens are predicted in sequence. The new method helps the model grasp bidirectional relationships, thereby better handling the associations and connections between words. Additionally, this method uses Transformer XL as the underlying architecture to provide good performance even in non-sequential training scenarios.
XLNet has utilized over 130 GB of text data combined with 512 TPU chips for two and a half days of training, both metrics exceeding those of BERT.
RoBERTa is a robustly optimized BERT variant launched by Facebook. Essentially, RoBERTa retrains on top of BERT, enhancing training methods while increasing the total amount of data and computing resources by 10 times.
To optimize the training process, RoBERTa removes the next sentence prediction (NSP) task from BERT’s pre-training, opting for dynamic masking to change masked tokens during training iterations. Furthermore, Facebook has confirmed that a larger approved training scale indeed enhances model performance.
More importantly, RoBERTa pre-trains using 160 GB of text, including 16 GB of text corpus and the English Wikipedia used by BERT. The remaining portion includes the CommonCrawl News dataset (containing 63 million articles, totaling 76 GB), web text corpus (38 GB), and story material from Common Crawl (31 GB). This combination of materials was run for an entire day on 1024 V100 Tesla units, providing a solid pre-training foundation for RoBERTa.
As a result, RoBERTa achieves performance results superior to both BERT and XLNet on the GLUE benchmark test:
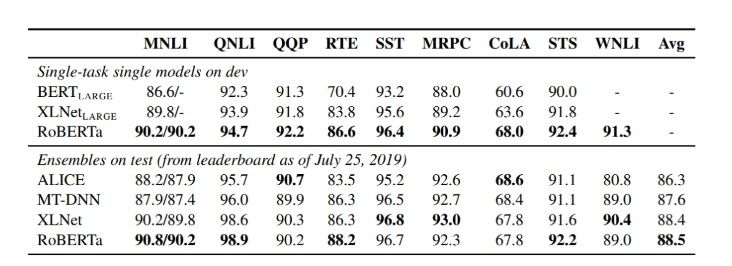
Performance comparison results of RoBERTa.
On the other hand, to shorten the computation (training, prediction) time of BERT and related models, a logical attempt is to choose a smaller network scale to achieve similar performance. Current pruning, distillation, and quantization methods can achieve this effect, but they may reduce predictive performance to some extent.
DistilBERT learns a distilled (approximate) version of BERT, achieving about 95% of BERT’s performance while using only half of the total parameters. Specifically, DistilBERT discards some token types and pooling layers, resulting in a total layer count that is only half that of Google’s BERT. DistilBERT employs a distillation technique, which utilizes several smaller neural networks to form a large neural network. The principle is that if one aims to train a large neural network, it might be beneficial to first use smaller neural networks to estimate its complete output distribution. This approach is somewhat similar to posterior approximation. Due to this similarity, DistilBERT also employs one of the key optimization functions used in Bayesian statistics for posterior approximation—the Kullback-Leibler divergence.
Note: In Bayesian statistics, what we approach is the true posterior value (from data); but in distillation, we can only approach the posterior value learned by the large network.
If you wish to achieve faster inference speed and can accept a slight compromise in predictive accuracy, then DistilBERT should be the most suitable option. However, if you are highly concerned about predictive performance, then Facebook’s RoBERTa is undoubtedly the ideal solution.
From a theoretical perspective, XLNet’s permutation-based training method should better handle dependencies and is expected to deliver better performance over the long run.
However, Google’s BERT already possesses quite strong benchmark performance, so if you do not have special requirements, continuing to use the original BERT model is also a good idea.
As we can see, most performance enhancement methods (including BERT itself) focus on increasing data volume, computational power, or training processes. While these methods are valuable, they often require us to make trade-offs between computation and predictive performance. Currently, what we really need to explore is how to leverage less data and computational resources to help models achieve performance improvements.
Original link:
https://towardsdatascience.com/bert-roberta-distilbert-xlnet-which-one-to-use-3d5ab82ba5f8

Are you also “watching”? 👇