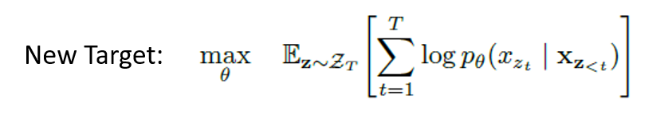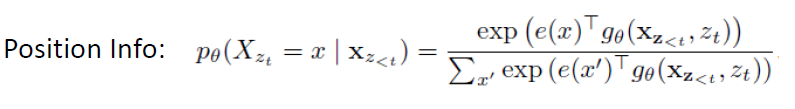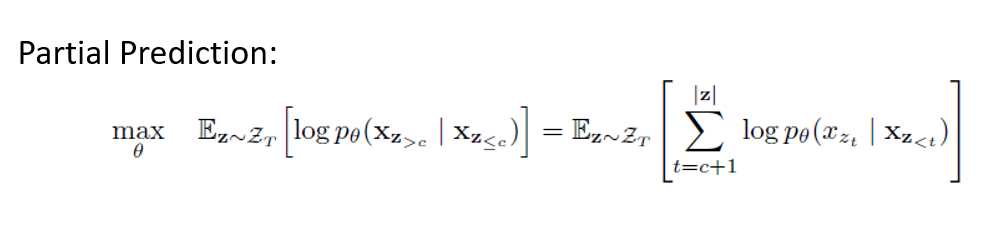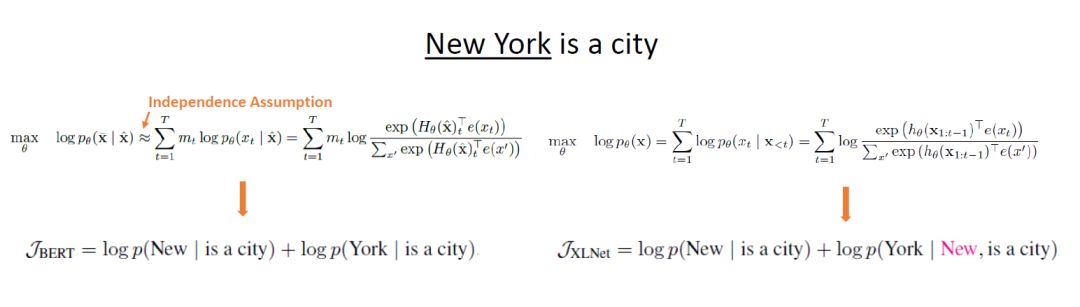Authorized Reprint from Microsoft Research AI Headlines
Since BERT was published on arXiv, it has gained significant success and attention, opening the Pandora’s box of 2-Stage in NLP. Subsequently, a large number of pre-trained models similar to “BERT” have emerged, including the generalized autoregressive model XLNet that introduces bidirectional context information from BERT, as well as RoBERTa and SpanBERT which improve BERT’s training methods and objectives, and MT-DNN which enhances BERT through multi-task learning and knowledge distillation. In addition, researchers have attempted to explore the principles of BERT and the true reasons for its outstanding performance on certain tasks.
All of the above has been humorously referred to as BERTology. In this article, Chen Yongqiang, an intern at the Knowledge Computing Group at Microsoft Research Asia, attempts to summarize the above content as a starting point for discussion.
Recent Overview of BERT-Related Models
-
XLNet and Its Comparison with BERT
-
-
-
MT-DNN and Knowledge Distillation
In-Depth Analysis of BERT’s Performance on Certain NLP Tasks
-
BERT’s Performance on Argument Reasoning Comprehension Tasks
-
BERT’s Performance on Natural Language Inference Tasks
Recent Overview of BERT-Related Models
1. XLNet and Its Comparison with BERT
Our discussion begins with a blog post from the XLNet team, who aimed to demonstrate the superiority of the latest pre-trained model XLNet through a fair comparison. But what is XLNet?
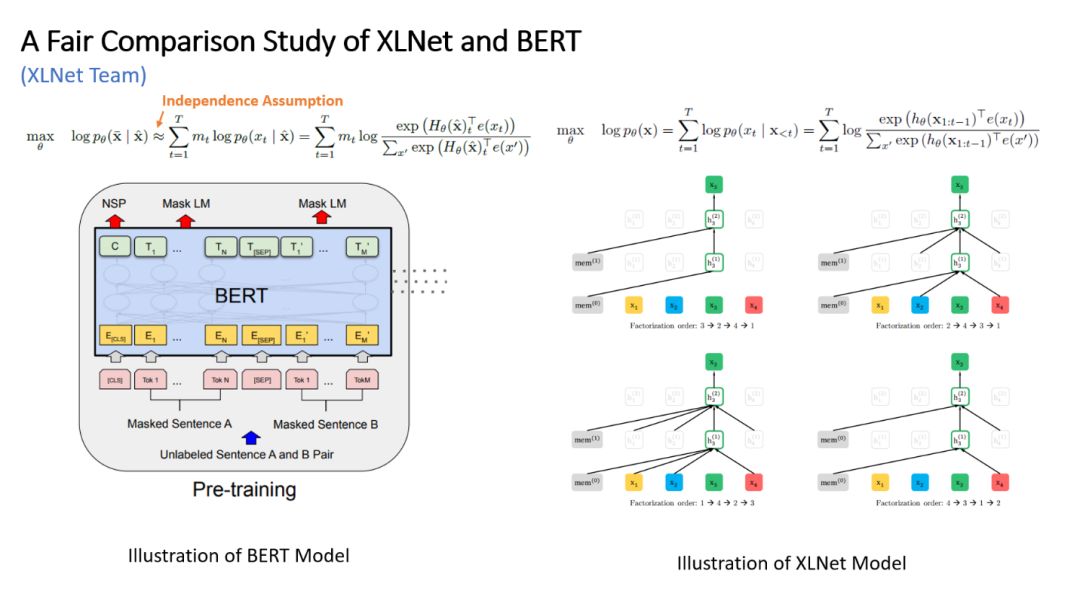
Figure 1: Comparison between XLNet and BERT
We know that BERT is a typical autoencoder model designed to reconstruct original data from noise-injected data. The pre-training process of BERT adopts the idea of denoising autoencoders, specifically the MLM (Masked Language Model) mechanism, which is different from autoregressive models. Its biggest contribution is that it allows the model to obtain bidirectional context information, but it also has some issues:
-
Pretrain-finetune Discrepancy: The [MASK] tokens used during pre-training do not appear during fine-tuning, leading to inconsistency between the two processes, which is detrimental to learning.
-
Independence Assumption: The prediction of each token is assumed to be independent. However, entities like “New York” have interdependencies between “New” and “York”, which this assumption ignores.
Autoregressive models do not face the second problem, but traditional autoregressive models are unidirectional. The XLNet team aimed to enable autoregressive models to also obtain bidirectional context information while avoiding the first issue.
They mainly used the following three mechanisms:
-
Permutation Language Model
-
Two-Stream Self-Attention
-
Next, we will introduce these three mechanisms in detail.
Permutation Language Model
Figure 2: XLNet Model Framework
When predicting a certain token, XLNet uses the input permutation to obtain bidirectional context information while maintaining the original unidirectional form of the autoregressive model. The advantage of this approach is that it does not require changing the input order, only internal processing is needed.
It is implemented in a clever way: by calculating context information based on the position of the token in the permutation. For instance, if we have a permutation of 2->4->3->1, we take token_2 and token_4 as inputs to predict token_3. It is easy to understand that when all permutations are exhausted, we can obtain all context information.
This leads us to our target formula:
However, in the original formula, we only used h_θ (x_(Z<t)) to represent the hidden representation of the “context” for the current token, which means that regardless of which token position the model is predicting, if the “context” is consistent, the output will also be consistent. Therefore, the new formula has been modified to include the positional information of the token to be predicted.
In addition, to reduce the difficulty of optimizing the model, XLNet uses Partial Prediction, predicting only the tokens after the current permutation position c, with the final optimization objective shown as follows:
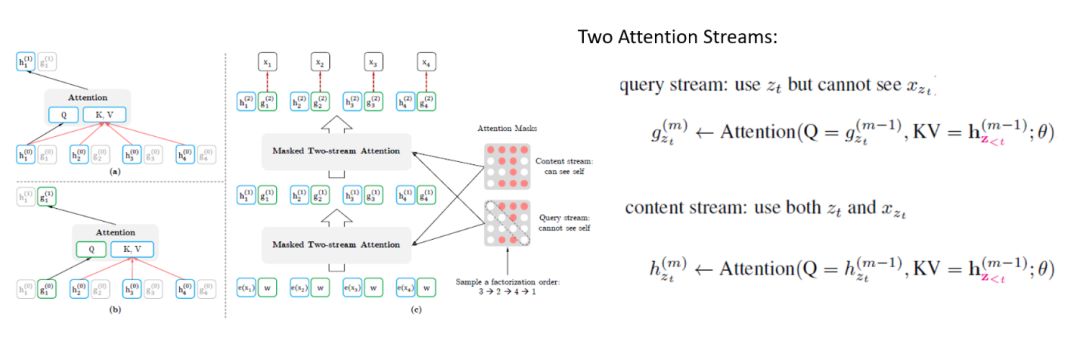
Two-Stream Self-Attention
Figure 3: Two-Stream Self-Attention Mechanism
This mechanism addresses the issue that after obtaining g_θ (x_{Z<t},z_t), we only have the positional information and “context” information, which is insufficient to predict the tokens that follow at that position; while the original h_θ (x_{Z<t}) lacks positional information, making it still insufficient for prediction. Therefore, XLNet introduces the Two-Stream Self-Attention mechanism to combine the two.
Figure 4: Recurrence Mechanism
This mechanism comes from Transformer-XL, which combines the hidden representation of the previous segment when processing the next segment, allowing the model to obtain longer-range context information. In XLNet, although relative positional encoding is used at the front end, the processing involved in representing h_θ (x_{Z<t}) is independent of the permutation, allowing this mechanism to be reused. This mechanism gives XLNet a significant advantage when dealing with long documents.
Example of the Difference Between XLNet and BERT
Figure 5: Example of the Difference Between XLNet and BERT
To illustrate the difference between XLNet and BERT, the author provides an example of processing “New York is a city.” This can be directly derived from the formulas of both models. Suppose we want to process the word New York, BERT will mask both tokens directly, using “is a city” as the context for prediction, which ignores the relationship between New and York; whereas XLNet, through permutation, can allow the model to obtain more information such as York | New, is a city.
Fair Comparison of XLNet and BERT
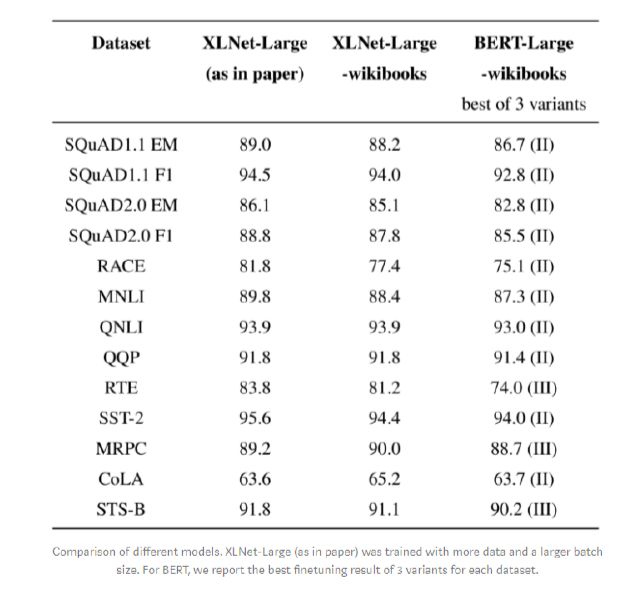
To better illustrate the superiority of XLNet, the XLNet team published the aforementioned blog post “A Fair Comparison Study of XLNet and BERT.”
In this blog post, the XLNet team controlled XLNet’s training data, hyperparameters, and grid search space to match those of BERT, and provided three versions of BERT for comparison. The BERT side then used the best-performing model among the following three models.
The experimental results are as follows:
Table 1: Comparison of Experimental Results Between XLNet and BERT
From this, it can be seen that under the same settings, XLNet far surpasses BERT. Interestingly:
-
XLNet achieved performance on the MRPC (Microsoft Research Paraphrase Corpus: A sentence pair from comments on the same news, determining whether the two sentences are semantically identical) and QQP (Quora Question Pairs: A binary classification dataset. The goal is to determine whether two questions from Quora are semantically equivalent) tasks that is not inferior to the original XLNet when using the Wikibooks dataset;
-
The BERT-WWM model generally outperforms the original BERT;
-
Removing NSP (Next Sentence Prediction) from BERT leads to better performance on certain tasks;
Besides XLNet, there are other models proposing improvements based on BERT to unlock its full potential.
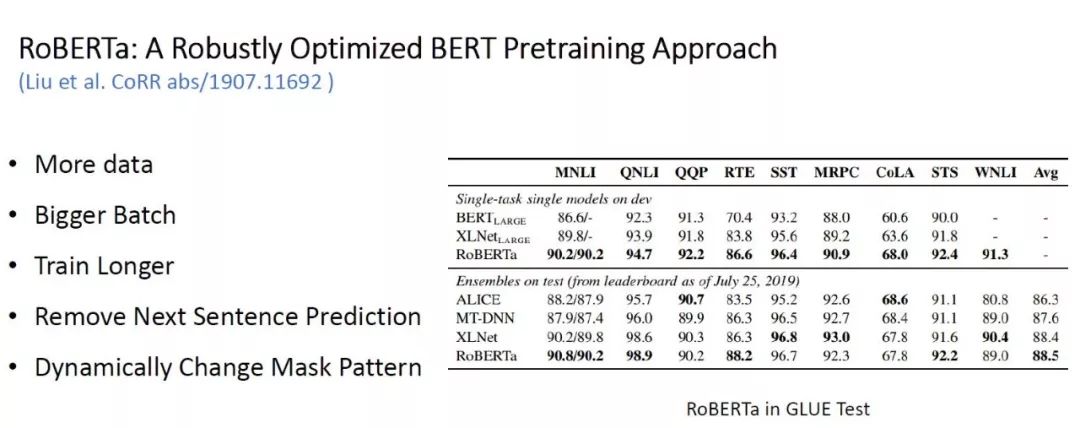
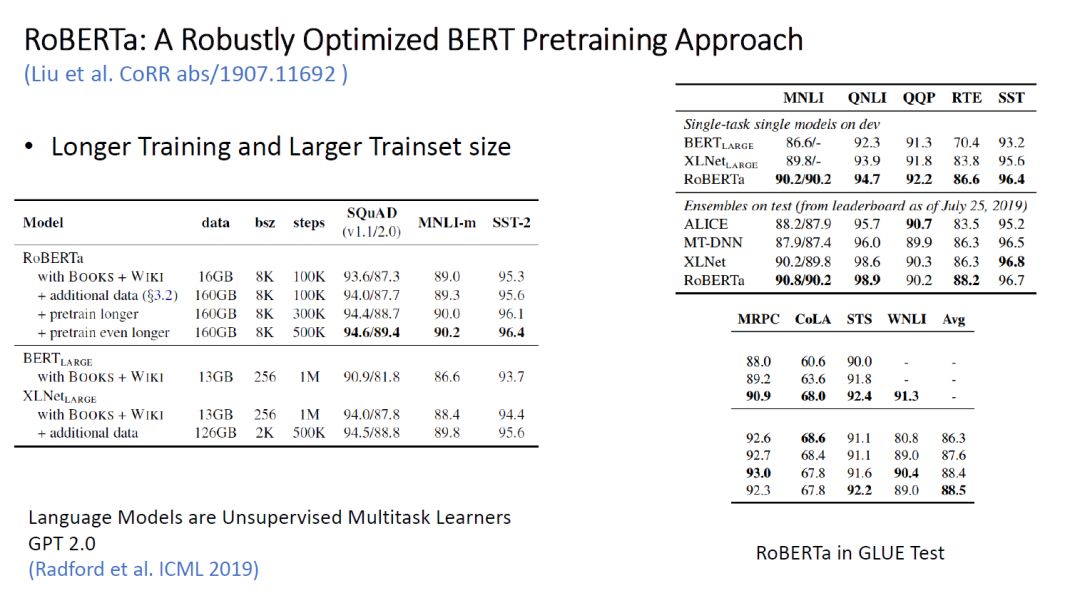
2. RoBERTa: A Robustly Optimized BERT Pretraining Approach
Table 2: RoBERTa’s Experimental Results in GLUE
RoBERTa is a BERT pre-training model recently released by Facebook AI in collaboration with UW, with improvements mainly shown in the following points; in addition to parameter tuning, it also introduces Dynamically Change Mask Pattern and removes Next Sentence Prediction, leading the model to rank first in the GLUE Benchmark. The authors’ viewpoint is: BERT is significantly undertrained.
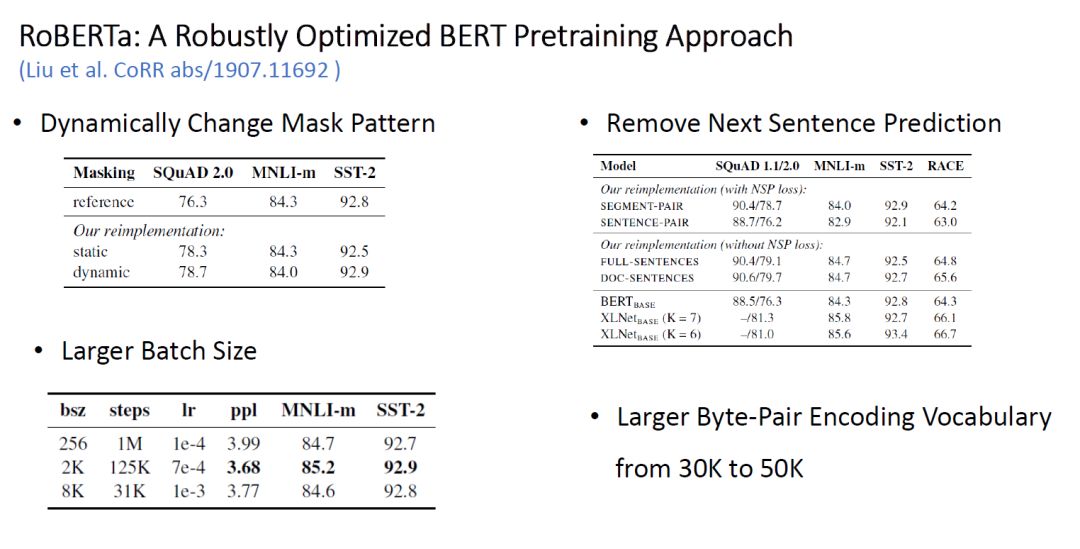 Table 3: Experimental Comparison of RoBERTa’s Various Mechanisms
Table 3: Experimental Comparison of RoBERTa’s Various Mechanisms
Unlike the original BERT’s MLM mechanism, the authors used 10 different Mask Patterns over a total of 40 epochs, training each Mask Pattern for 4 generations as a static strategy; they also introduced dynamic masking strategy, generating a mask pattern for each input sequence. Ultimately, they found that the new strategies were better than the original BERT, with dynamic overall performing better than static strategies, and could be used to train larger datasets and longer training steps, leading to the final choice of dynamic masking pattern.
The authors also replaced the NSP task during pre-training. Although BERT had already attempted to compare the results after removing NSP, with performance declining in many tasks, experiments conducted by the XLNet team have called this conclusion into question.
The newly adopted strategies include:
-
Sentence-Pair + NSP Loss: Same as original BERT;
-
Segment-Pair + NSP Loss: Input a complete pair of segments containing multiple sentences, which can come from the same document or different documents;
-
Full-Sentences: Input is a series of complete sentences, which can be from the same document or different documents;
-
Doc-Sentences: Input is a series of complete sentences from the same document;
Results showed that complete sentences performed better, and those from the same document were better than those from different documents, leading to the final choice of Doc-Sentences strategy.
Table 4: RoBERTa’s Experimental Results with More Training Data and Longer Training Time
The authors also attempted more training data and longer training times, finding that both improved model performance.
This approach is somewhat similar to OpenAI’s recent data expansion method for GPT2.0, but requires a lot of computational resources.
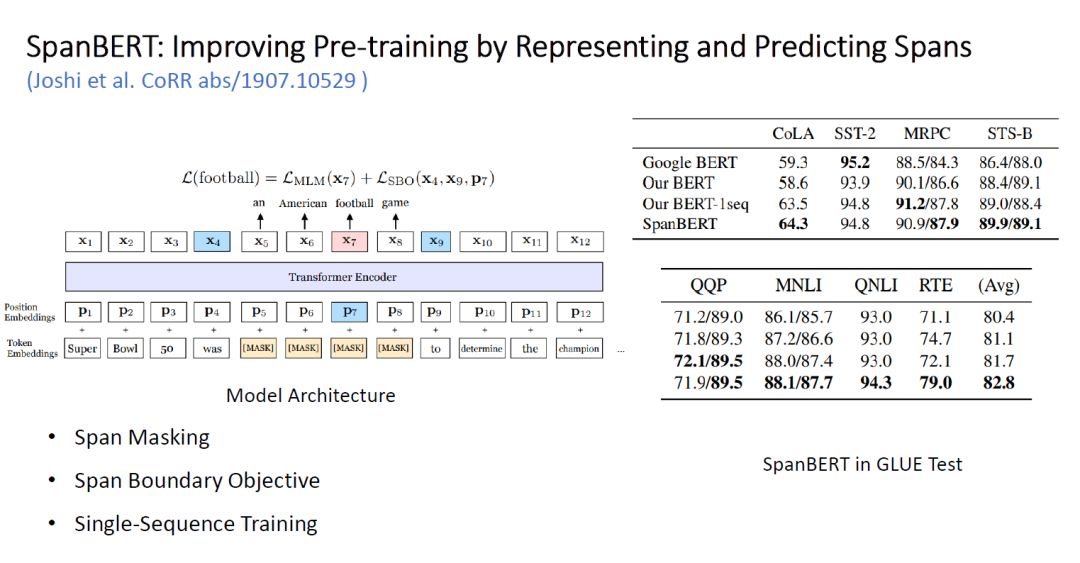
3. SpanBERT: Improving Pre-training by Representing and Predicting Spans
Figure 6: SpanBERT Model Framework and Its Experimental Results in GLUE
Unlike RoBERTa, SpanBERT achieves better performance by modifying the pre-training tasks and objectives of the model. Its modifications mainly focus on three aspects:
-
Span Masking: This method is similar to the WWM (Whole Word Masking) released by the BERT team, where entire word tokens are masked rather than individual tokens. Each time before masking, the length of the span to be masked is sampled from a geometric distribution, and spans of that length in the input are masked until 15% of the input is masked.
-
Span Boundary Object: Using the preceding token and the following token of the span, along with a fixed representation of the token’s position to represent a token within the span. This is used to predict that token, and cross-entropy is employed as a new loss added to the final loss function. This mechanism allows the model to achieve better performance in Span-Level tasks.
-
Single-Sequence Training: Directly inputting a continuous sequence allows the model to obtain longer context information.
With these three mechanisms, SpanBERT was trained on the same corpus as BERT, ultimately achieving a performance of 82.8 in GLUE, surpassing the original Google BERT by 2.4% and outperforming their tuned BERT by 1%, while also improving the best results in Coreference Resolution by 6.6%.
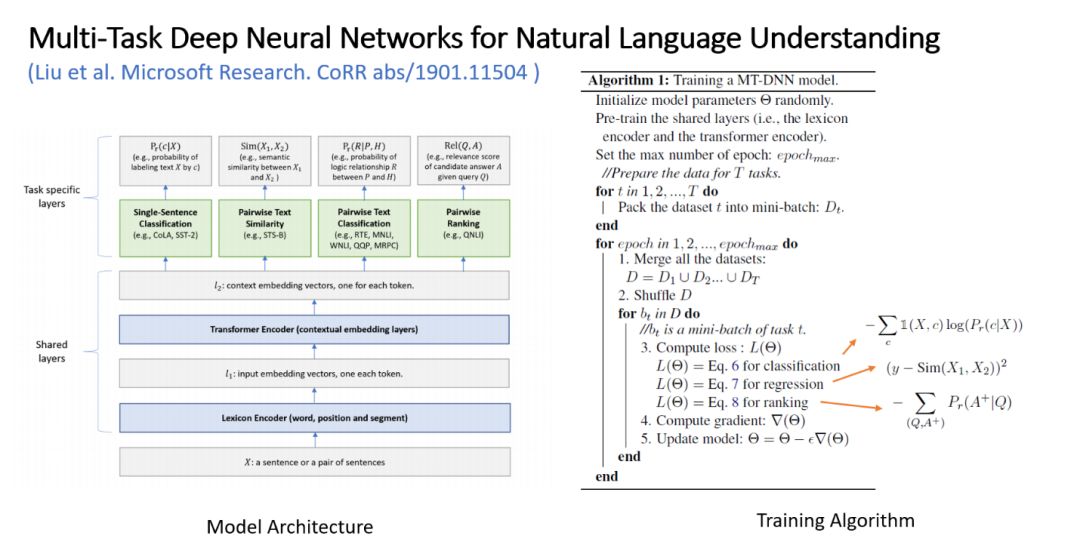
4. MT-DNN and Knowledge Distillation
Multi-Task Deep Neural Networks for Natural Language Understanding
This paper aims to combine Multi-Task learning with BERT, enabling the model to train on more data while also gaining better transfer ability.
Figure 7: MT-DNN Model Framework and Training Algorithm
The model architecture is as shown in the figure above, using the same mechanisms as BERT in the input and Transformer layers, but employing different task parameters and output representations with dot production for different task data processing, using different activation functions and loss functions for training.
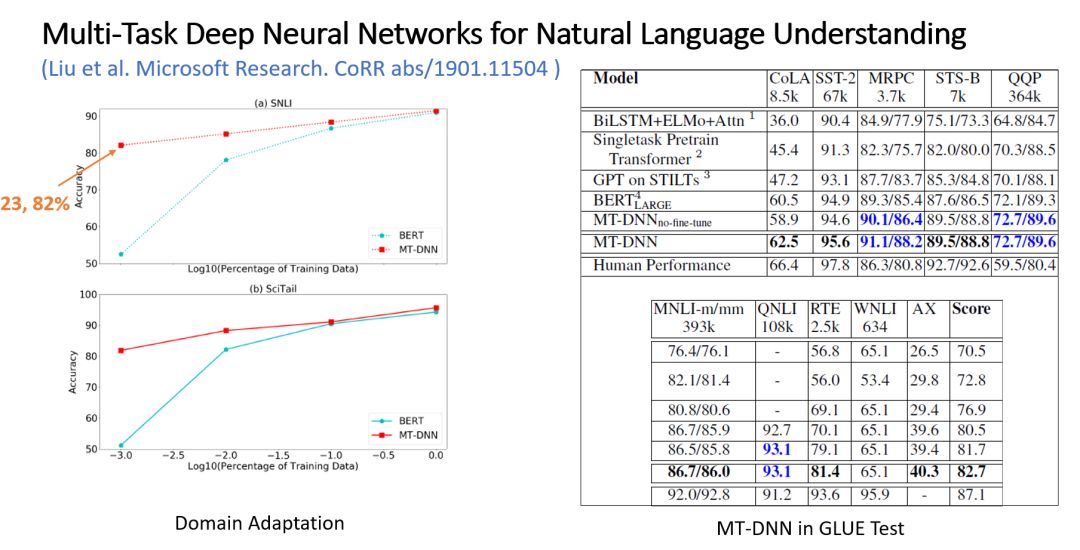
Figure 8: Transfer Ability of MT-DNN Across Different Tasks
MT-DNN exhibits a good transfer capability. As shown in the figure above, MT-DNN only requires 23 task samples to achieve 82% accuracy in SNLI! Especially, when BERT fine-tunes on small datasets, it may struggle to converge and perform poorly, whereas MT-DNN can effectively address this issue while saving costs on labeled data and long fine-tuning times for new tasks.
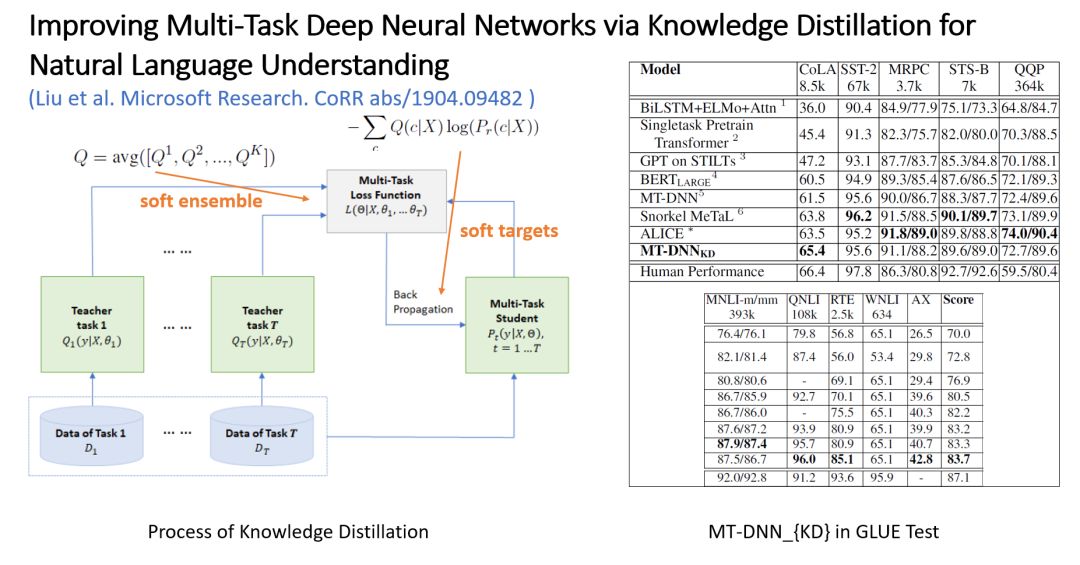
Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding
Figure 9: Optimizing MT-DNN Model Using Knowledge Distillation
Since MT-DNN can be seen as an ensemble process, it can be optimized using knowledge distillation, a method that can enhance the performance of many ensemble models; interested readers can explore related content.
The knowledge distillation process in this paper involves fine-tuning on corresponding datasets using the same structure for different tasks, which can be seen as each task’s Teacher, each excelling at solving corresponding problems.
The Student then fits the target Q and uses soft cross-entropy loss. Why use soft cross-entropy loss? Because some sentences may not have absolute meanings, for example, “I really enjoyed the conversation with Tom” may imply sarcasm with some probability rather than being 100% positive. This allows the Student to learn more information.
After adopting knowledge distillation, the model’s performance in GLUE increased by 1%, currently ranking in the top three. We can also expect the MT-DNN mechanism to perform well on other pre-trained models like XLNet.
In-Depth Analysis of BERT’s Performance on Certain NLP Tasks
The aforementioned BERT has achieved remarkable results in many NLP tasks, leading some to believe that BERT has nearly solved the problems in the NLP field, but the following two articles provide a sobering perspective.
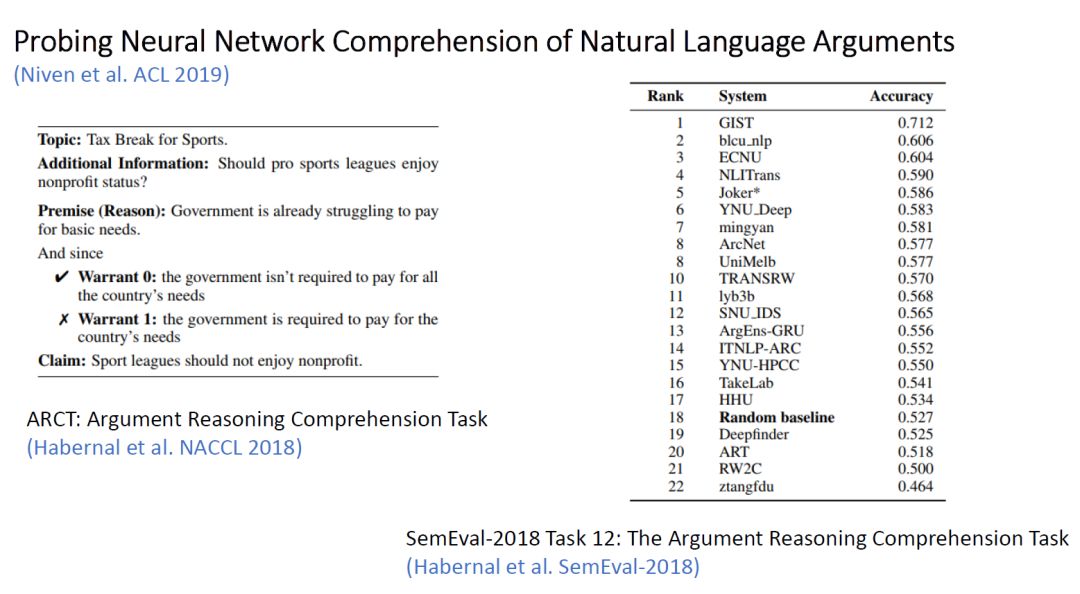
1. BERT’s Performance on Argument Reasoning Comprehension Tasks
Probing Neural Network Comprehension of Natural Language Arguments
Table 5: BERT’s Performance on Argument Reasoning Comprehension Tasks
This paper mainly explores the true reasons behind BERT’s impressive performance on the ARCT (Argument Reasoning Comprehension) task.
First, the ARCT task was proposed by Habernal et al. in NACCL 2018, which requires determining which of two opposing warrants (warrant0, warrant1) supports the premise (premise) for a given claim.
They also pointed out in SemEval-2018 that this task requires the model to understand the structure of reasoning and some external knowledge. In this case, that external knowledge could be that “Sport Leagues is an organization related to Sports.”
The best-performing model in this task is GIST, which will not be elaborated here; interested readers can follow that paper.
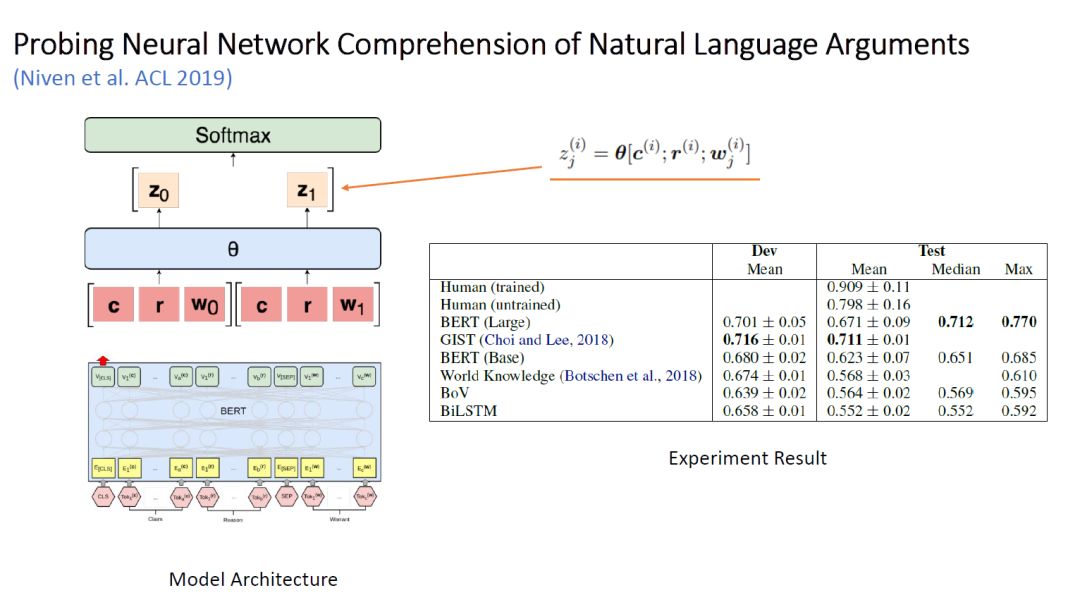
Figure 10: Model Framework and Experimental Results
The author attempted to use BERT to handle this task, adjusting the input to [CLS, Claim, Reason, SEP, Warrant], obtaining a logit (similar to logistic regression) through a shared linear layer, processing both warrant0 and warrant1 once, and normalizing into two probabilities through softmax, with the optimization objective being to maximize the probability corresponding to the answer.
Ultimately, the model achieved the highest accuracy of 77% on the test set. It should be noted that due to the small size of the ARCT dataset, with only 1210 training samples, BERT’s fine-tuning may lead to unstable performance. Therefore, the author conducted 20 experiments, excluding results that showed degeneration (i.e., very poor results on the training set) to obtain the statistics in the above table.
Table 6: Author’s Exploratory Experiments (Probing Experiments)
Although the experimental results are impressive, the author questions whether BERT has truly learned the necessary semantic information or merely over-utilized statistical information from the data, thus proposing some concepts regarding cues:
-
A Cue’s Applicability: The number of cues appearing in a warrant labeled j at a data point i that do not appear in another warrant.
-
A Cue’s Productivity: The proportion of cues appearing in a warrant labeled j at a data point i that do not appear in another warrant, and whose correct label is j. Intuitively, this indicates the value of the cue that the model can utilize; if this data is greater than 50%, we can consider the model’s use of this cue to be valuable.
-
A Cue’s Coverage: The number of times this cue appears across all data points.
There are many such cues, such as “not”, “are”, etc. As shown in the table above, the occurrence of “not” can be observed in 64% of the data points, and if the model selects warrants where “not” appears, the probability of correctness is 61%.
The author suspects that this is the information the model has learned. If this inference holds, the model should perform well with just the input of the warrant. Therefore, the author also conducted experiments as shown in the table above.
It can be seen that inputting just the warrant achieved peak performance of 71%, while inputting (R, W) increased it by 4%, and inputting (C, W) increased it by 2%, leading to a total of 71% + 4% + 2% = 77%, which is strong evidence.
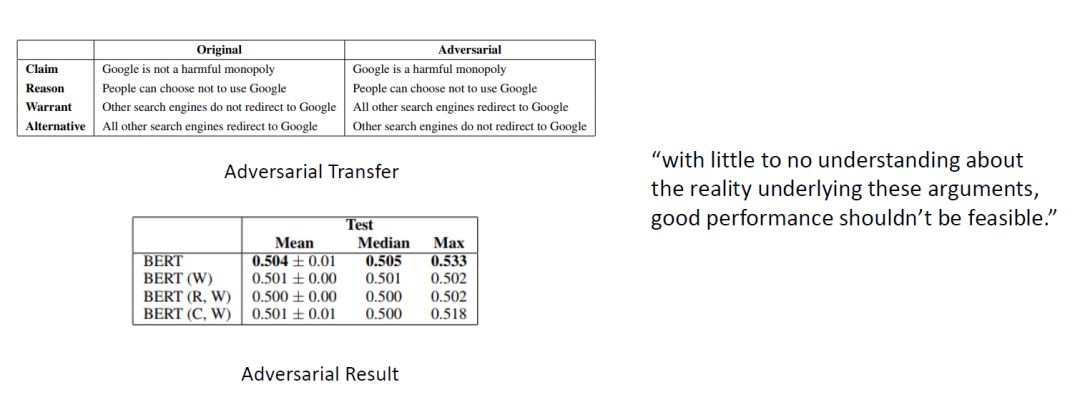
Figure 11: Adversarial Dataset and Experimental Results on the Adversarial Dataset
To fully demonstrate the correctness of the inference, the author constructed an adversarial dataset, as shown in the example above, transforming the original structure: R and W -> C into: R and !W -> !C (here, for convenience, “!” denotes negation).
Initially, the author fine-tuned the model on the original ARCT dataset and evaluated it on the adversarial dataset, resulting in performance worse than random. Later, the model was fine-tuned on the adversarial dataset and evaluated on it, yielding results as shown in the second table above.
From the experimental results, it can be seen that the adversarial dataset essentially eliminated the influence of cues, allowing BERT to truly demonstrate its capability on this task, consistent with the author’s conjecture.
Although the experiments are somewhat lacking (e.g., insufficient explanation of whether the model converged, how other models performed on the adversarial dataset, etc.), this paper provides a sobering perspective on the hype surrounding BERT, clearly indicating that BERT is not omnipotent, and we must calmly consider the true reasons behind BERT’s impressive performance.
2. BERT’s Performance on Natural Language Inference Tasks
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language
This is another exploration of the performance of BERT and other models on Natural Language Inference (NLI) tasks.
Figure 12: Heuristic Illustration in the NLI Task
The author first hypothesizes that models performing well in NLI may utilize three types of heuristics, where heuristics provide the model with some hints in the premise, as follows:
-
Lexical Overlap: The corresponding hypothesis is a subsequence of the premise.
-
Subsequence: The corresponding hypothesis is a substring of the premise.
-
Constituent: The syntax tree of the premise covers all hypotheses.
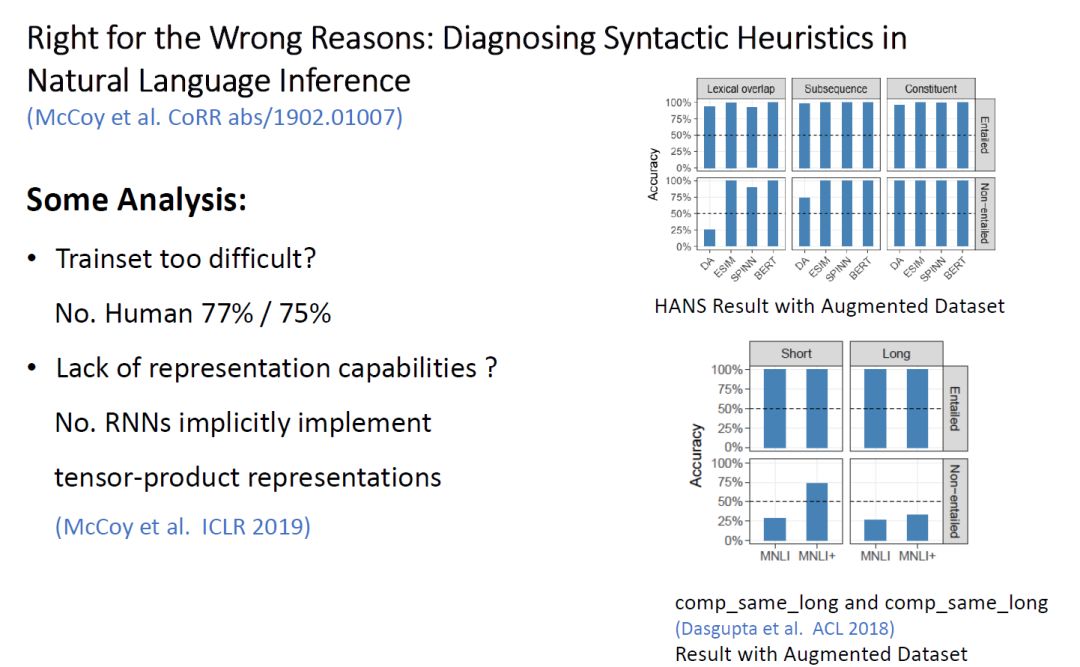
Based on this hypothesis, the author conducted experiments and observed that many data points in the MNLI training set exhibit such heuristics, with the correct option far outnumbering the incorrect ones. To address this situation, the author constructed the HANS dataset, balancing the distribution of both types of samples and marking whether the premise entails the aforementioned heuristics.
During the experiment, the model was fine-tuned on the MNLI dataset and evaluated on the HANS dataset, with results showing that the model performed well on entailment-type data points while performing poorly on non-entailment types, supporting the author’s hypothesis that the model overly relies on heuristic information.
Figure 13: Analysis of Model Results on the HANS Dataset
However, the author is not entirely sure what caused this experimental result and proposes the following conjectures:
-
Is the HANS dataset too difficult? No. The author had humans test it and found that humans achieved accuracy rates of 77% and 75% on the two types of data, far exceeding the model.
-
Is the model lacking sufficient representational power? No. The ICLR 2019 paper “RNNs implicitly implement tensor-product representations” provides some evidence that RNNs have learned certain structural information in the SNLI task.
-
Is it that the MNLI dataset is not good enough, lacking sufficient signals for the model to learn NLI? Yes.
Thus, the author added some HANS data to the training set, constructing the MNL+ dataset, allowing the model to fine-tune on this dataset, ultimately achieving the results shown in the figure above. To demonstrate the contribution of HANS to the model’s learning of NLI, the author also evaluated the model fine-tuned on MNL+ on another dataset, with improvements noted.
This article summarizes some of the latest developments since BERT was proposed.
BERT is an excellent pre-trained model, and its pre-training ideas can be used to improve other models. BERT can be better; we can set new training methods and objectives to unlock its greater potential.
However, BERT is not as good as imagined; we must calmly consider the reasons behind BERT’s good performance on certain tasks—whether it is because BERT has genuinely learned the corresponding semantic information or because the imbalance in the dataset has led BERT to over-utilize such signals.
[1] XLNet: Generalized Autoregressive Pretraining for Language Understanding. Yang et al. CoRR abs/1906.08237.
[2] A Fair Comparison Study of XLNet and BERT. XLNet Team.
https://medium.com/@xlnet.team/a-fair-comparison-study-of-xlnet-and-bert-with-large-models-5a4257f59dc0
[3] Probing Neural Network Comprehension of Natural Language Arguments. Niven et al. ACL2019.
[4] Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. McCoy et al. Corr abs/1902.01007.
[5] RoBERTa: A Robustly Optimized BERT Pretraining Approach. Liu et al. CoRR abs/190.11692.
[6] SpanBERT: Improving Pre-training by Representing and Predicting Spans. Joshi et al. CoRR abs/1907.10529.
[7] Multi-Task Deep Neural Networks for Natural Language Understanding. Liu et al. CoRR abs/1901.11504.
[8] Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding. Liu et al. CoRR abs/1904.09482.
Intern/Full-Time Editor Recruitment
Join us to personally experience every detail of writing for a professional tech media, growing alongside a group of the best talents in the most promising industry. Located at Tsinghua East Gate in Beijing, reply “Recruitment” on the Big Data Digest homepage chat page to learn more. Please send your resume directly to [email protected]
People who click “See” all become more attractive!