An Overview of Knowledge Graph Technology and Its Applications
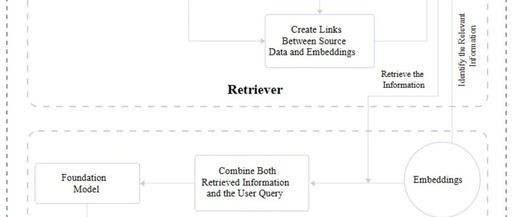
1 Overview The concept of knowledge graphs was first proposed by Google on May 17, 2012, aiming to describe concepts, entities, events, and their relationships in the objective world, serving as a core foundation for building the next generation of intelligent search engines. In simple terms, a knowledge graph is a network of relationships formed … Read more