Source: DeepHub IMBA
This article is approximately 4200 words long and is suggested to be read in 5 minutes.
This article reveals the main reasons for the failure of ordinary RAGs and provides specific strategies and methods to bring your RAG closer to production stage.
Countless companies are attempting to use Retrieval-Augmented Generation (RAG), but they are generally disappointed when it comes to producing these systems at production quality. This is because their RAGs not only perform poorly but also leave them confused about how to improve and what follow-up work to undertake.
One key factor hindering RAG systems is semantic incoherence, which arises from inconsistencies between the expected meanings of tasks, the understanding of RAG, and the underlying stored knowledge. Because the underlying technology of vector embeddings is magical (volatile and highly opaque), it is difficult to diagnose this incoherence, making it a significant barrier to production.
In this article, we will:
-
Differentiate the ideal prospects of RAG from the reality of ordinary RAG.
-
Explain how semantic incoherence arises.
-
Introduce how to diagnose and mitigate semantic incoherence.
-
Summarize some additional high ROI strategies to bring RAG closer to production quality.
Note: To simplify the problem, we will focus on text examples based on Q&A, but the core ideas can be generalized to other use cases.
Why Choose RAG?
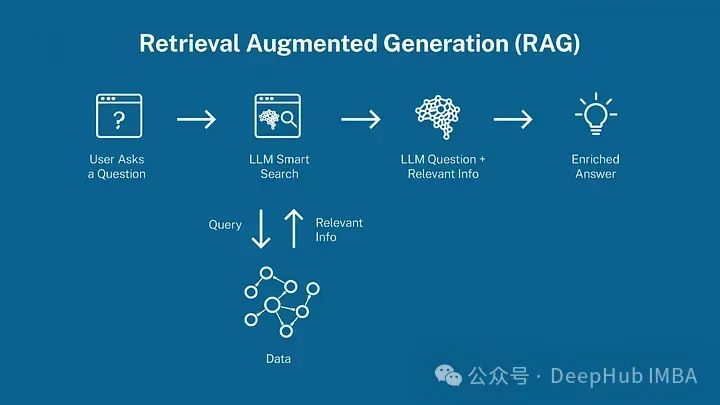
RAG (Retrieval-Augmented Generation) is a paradigm currently experiencing a hype cycle. It sounds appealing; essentially, it is a search engine for AI.
Shortly after GPT-3 became popular, RAG started to gain traction. A direct problem faced by companies building LLM-driven AI is that models like GPT have not been trained on their specific data and domains. So LLM practitioners quickly discovered that when providing business-specific context (such as support documents) directly in the prompt, GPT performs surprisingly well. This provides companies with an alternative to fine-tuning models.
For RAG, give it a question, possibly with user-specific information, and it will return the most relevant context to GPT. While this sounds great in theory, there are significant challenges in implementing production-grade RAG, which we will explore in the following sections.
RAG Has Potential, Ordinary RAG Is Just the Beginning
RAG is merely a framework; a perfectly functioning RAG, regardless of its backend, will bring immense value to countless use cases. If you are familiar with RAG, you can skip this section.
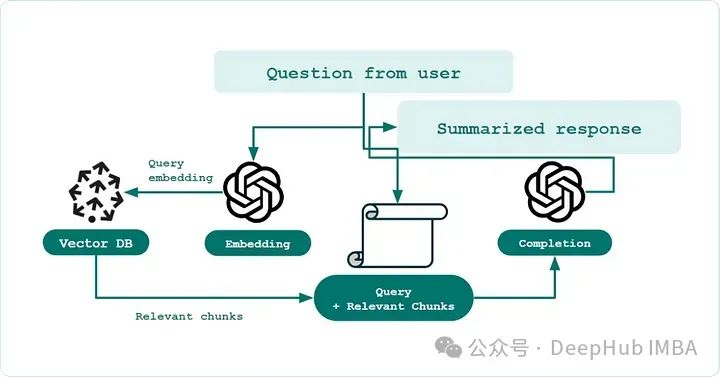
Traditional RAG (definition): A single-step semantic search engine that stores business knowledge (such as support documents) in a vector database like Pinecone, using off-the-shelf embedding models. It then ranks the k most relevant documents by creating vector embeddings of the question text and using comparison metrics (such as cosine similarity).
A vector embedding model receives any string and returns a fixed-dimensional mathematical vector. Popular embedding models include OpenAI’s text-embedding-ada-002 and its latest model text-embedding-3-small. These models convert text blocks into approximately 1500-dimensional vectors with almost no human-understandable interpretability.
Vectors are very common and useful tools because they can break down non-quantitative things into rich arrays of dimensions and allow for quantitative comparisons. Some examples include:
-
The (red, green, blue) color palette is a vector, with each value ranging from 0-255.
-
Stocks can be represented as vectors using industry standards like Barra, quantifying their sensitivity to economic factors (like broad growth, interest rate changes, etc.).
-
Platforms like Netflix can break down user preferences into a vector, where the components can represent genres and other features.
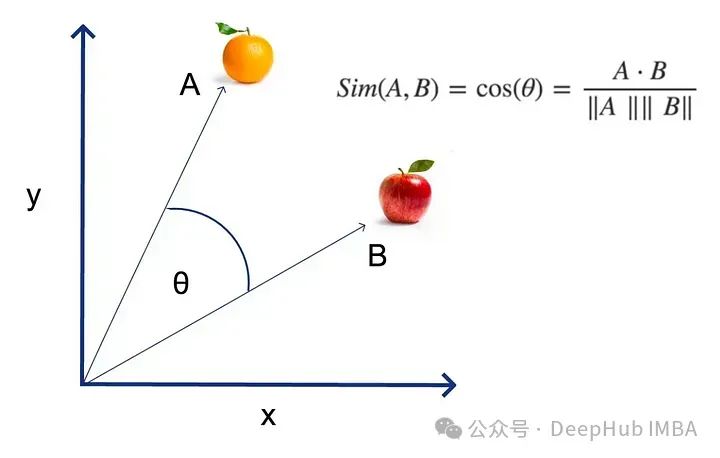
Cosine similarity can be considered the default metric for comparing vectors in semantic search; it works by applying the cosine to the angle of the dot product between two vectors. The closer the cosine is to 1, the more similar the vectors are.
There are other methods for measuring semantic similarity, but this is not usually the crux of the problem; we will use cosine similarity throughout this article.
However, it must be emphasized that vector comparison metrics like cosine similarity are difficult to handle because they lack absolute meaning—these values depend entirely on the embedding model and the context of the text involved. Suppose you match a question with an answer and get a cosine similarity of 0.73. Is this a good match?
We pose a question, “What is rain?” and compare it with three texts of varying relevance. In the table below, you can see that the range and interpretation of cosine similarities using two different OpenAI models vary significantly.For the first model, 0.73 indicates a completely irrelevant match, whereas for the second model, 0.73 indicates a highly relevant match. This indicates that any well-functioning RAG system needs to calibrate its understanding of these scores.
Text1 (definition): “Rain is the precipitation of water droplets from clouds, falling to the ground when they become too heavy to stay suspended in air.”
Text2 (mentions rain): “The winds blowing moisture over the mountains are responsible for rain in Seattle.”
Text3 (irrelevant info): “Stripe is a payments infrastructure business.”
Semantic Incoherence Causes Problems
Several challenges of traditional RAG can be attributed to semantic incoherence and poor interpretability of embeddings. Semantic incoherence is the inconsistency between the expected meanings of tasks, the understanding of RAG, and the underlying stored knowledge.
It can be roughly stated as “the questions are semantically different from their answers,” so directly comparing the questions with your original knowledge base will yield limited results.
Imagine a lawyer needing to sift through thousands of documents to find evidence of investment fraud. He then poses the question, “What evidence is there that Bob committed financial fraud?” The statement “Bob purchased XYZ stock on March 14” (where it is implied that XYZ is a competitor and March 14 is the week before the earnings report) has virtually no semantic overlap, yet causally, the two are related.
Vector embeddings and cosine similarity are fuzzy because vectors have inherent imperfections in fully capturing the semantic content of any given statement. Cosine similarity does not necessarily lead to precise rankings because it implicitly assumes that every dimension has equal importance.
Using cosine similarity for semantic search tends to be directionally correct but inherently fuzzy. It can estimate the top 20 results well, but relying solely on it to reliably rank the best answers is demanding.
Embedding models trained on the internet do not understand your business and domain, especially in an era where neologisms abound; words like Connect, Radar, and Link can have vastly different meanings when discussing different products. The sources of semantic incoherence are multiple and lead to unreliable rankings.
Diagnosing and Mitigating Semantic Incoherence
This example will illustrate how to diagnose complete semantic incoherence in RAG. We will also discuss early signs of performance improvement through added structure.
This example comes from a real-life use case.
1. Assume an e-commerce startup is building an internal RAG that finds the best SQL tables for given business problems. Below is the setup of the example, where we:
events.purchase_flow: Detailed raw user events in the product flow.
aggregates.purchases: A summarized table containing aggregated analysis.
2. Then, we created some hypothetical questions for evaluation.
What impact do IP addresses have on the types of products viewed and purchased? What is the overall trend of shoe sales this quarter? Are there unusual behaviors within seconds of each hour? How does user engagement change around significant events like New Year?
3. Generated additional metadata.
A brief description of each table, along with example questions that each table uniquely answers.
4. Checked noisy cosine similarity scores by comparing our input text with “garbage.”
5. Compared four different retrieval strategies to see which types of texts are “most semantically similar” to our input.
Strategy 1: Only table structure.
Strategy 2: Table structure + brief description.
Strategy 3: Table structure + brief description + example questions.
Strategy 4: Only example questions.
We compared random text fragments with each question and the original table text for cosine similarity (the following figure is an example). We found that the cosine similarity for garbage input ranged from 0.04 to 0.23, which helped establish a baseline indicating weak to no semantic overlap.
Comparison of Four Strategies
From the results below, it can be seen that Strategy 4 compares the questions with example questions, showing the highest semantic overlap and best ranking. Strategies 1 and 2 performed similarly, consistent with noise—indicating that there is weak or no semantic overlap between business questions and SQL table statements.
This may differ from our cognition because, in the general understanding, Strategy 1 seems sufficient, and LLM can handle everything. However, professionals understand that Strategy 3 should be better because it mixes everything together, yet it performed worse than Strategy 4.
-
Noise (random, irrelevant text): Cosine similarity ranges from 0.04 to 0.23.
-
Strategy 1 (only table structure): Values range from 0.17 to 0.25 (consistent with noise).
-
Strategy 2 (table structure + description): Values range from 0.14 to 0.25 (still consistent with noise).
-
Strategy 3 (table structure + description + example questions): Values range from 0.23 to 0.30. A significant improvement, and we begin to see signals from the noise.
-
Strategy 4 (only example questions): Values range from 0.30 to 0.52. Clearly the best-performing strategy and completely surpassed the noise range, leading to the greatest separation in cosine similarity between the correct and incorrect tables, thus generating a stronger signal.
Strategies to Further Improve Your RAG
If you are encountering the problems we are currently describing, then first of all, congratulations, you are a practitioner who has genuinely used or wants to use RAG. However, the above issues only scratch the surface; more complex problems are beyond the scope of this article, which we will discuss in future writings. For now, we need to focus on solving the problems described in this article, and here are some worthwhile methods for incremental improvements.
You can improve RAG by adding structure, which first links questions to existing question libraries, subsequently guiding you to find the correct answers. This is in contrast to directly linking questions to the correct text in a single step.
For Q&A systems built on support documents, comparing questions to questions will substantially improve performance, rather than comparing questions to support documents. In practice, the simplest method is to ask your large model (like ChatGPT) to generate example questions for each document and have human experts curate them. Essentially, this establishes our own knowledge base.
Can this method be further developed?
-
For each document, have ChatGPT generate a list of 100 questions it can answer.
-
These questions will not be perfect, so for each question you generate, calculate its cosine similarity with every other document.
-
Filter out those questions that will rank the correct document above all other documents.
-
Identify the highest quality questions by sorting those with the greatest differences in cosine similarity between the correct document and the second-best document.
-
Send for further human judgment (this step incurs human costs).
Semantic + Relevance Ranking
Almost every major search engine uses this method, so it may be one of the greater benefits we can achieve. Because cosine similarity is suitable for initial assessments, but ultimately cannot achieve higher precision ranking.
If your business may have more information to help AI make better decisions, for example: metrics such as page views and likes, possibly having these metrics by persona characteristics. Then you can create a relevance score that includes a wide range of user/task characteristics to fine-tune rankings, making RAG work better. For example, you can make your ranking a linear combination,
Ranking = (Cosine Similarity) + (Weight) x (Relevance Score)
Using AI as a Tool, Not a Complete Solution
For decades, software engineering practices have evolved to favor designing many small components with strict, explicit guarantees. The frenzy around chat interfaces has completely upended this paradigm, and five years from now, this approach may be seen as misguided.
ChatGPT and most emerging ecosystems encourage the paradigm of “give me any text, and I will give you any text.” These AIs do not provide guarantees of efficacy, cost, or latency, but rather a vague commitment of “I might be right to some extent at some point.” In fact, companies should build more robust AIs by providing interfaces that are more scoped and subjective.
This is also why what is said about super alignment for OpenAI is very important but not necessary.
Conclusion
We are witnessing the arrival of a new era in AI. The novelty of this era lies not in the emergence of NLP and language models, but in how off-the-shelf technology has lowered the barriers for companies to leverage natural language technology for their specific use cases. However, we must also recognize that this technology is still in its early development stages. When building RAG for your AI, you are essentially constructing a complex search engine; it is feasible, but recognizing the complexities and challenges here and addressing these issues is crucial for taking the first step towards success.
Proofreader: Lin Yilin