The 2023 Zhejiang Programmer Festival is in full swing, and the knowledge sharing activities, as one of the series of events, will successively launch the 【Artificial Intelligence Special】 knowledge sharing, including the development of AI large models, cutting-edge technologies, learning resources, etc. Welcome to follow! This issue’s content: Building your own AIGC application using LangChain and OpenAI API


Introduction
Generative artificial intelligence is leading the latest technological wave in the industry. Generative AI applications, such as image generation, text generation, summarization, and Q&A bots, are thriving. With OpenAI recently leading the large language model wave, many startups have developed tools and frameworks that allow developers to build innovative applications using these LLMs. One such tool is LangChain, a framework for developing applications powered by LLMs, known for its composability and reliability. LangChain has become the preferred tool for AI developers worldwide to build generative AI applications. LangChain also allows for the connection of external data sources and integration with many LLMs available on the market. Additionally, LLM-driven applications require a vector storage database to store the data they will retrieve later. In this blog, we will explore LangChain and its capabilities by building an application pipeline using the OpenAI API and ChromaDB.



Overview of LangChain
LangChain has recently become a popular framework for large language model applications. LangChain provides a complex framework for interacting with LLMs, external data sources, prompts, and user interfaces.
The value proposition of LangChain
The main value propositions of LangChain are:
-
Components: These are the abstractions needed to work with language models. Components are modular and easy to use for many LLM use cases.
-
Ready-made Chains: Structured combinations of various components and modules to accomplish specific tasks, such as summarization, Q&A, etc.
Project Details
LangChain is an open-source project that has gained over 54K+ stars on GitHub since its launch, indicating the project’s popularity and acceptance.
The project documentation describes the framework as follows:
Large language models (LLMs) are becoming a transformative technology that enables developers to build applications that were previously impossible. However, using these LLMs alone is often insufficient to create a truly powerful application—the real power emerges when they are combined with other computational or knowledge sources.
Clearly, it defines the purpose of the framework, which is designed to assist in developing applications that leverage user knowledge.
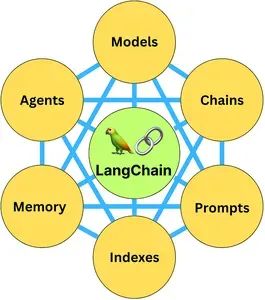
LangChain Components (Source: ByteByteGo)
LangChain has six main components for building LLM applications: model I/O, data connections, chains, memory, agents, and callbacks. The framework also allows for integration with many toolsets to develop full-stack applications, such as OpenAI, Huggingface Transformers, and vector stores like Pinecone and ChromaDB.
A comprehensive description of the components:
-
Model I/O: An interface with the language model. It consists of prompts, models, and output parsers.
-
Data Connections: Interacting with application-specific data sources using data converters, text splitters, vector storage, and retrievers.
-
Chains: Constructing a series of calls using other components of the AI application. Examples of chains include sequential chains, summarization chains, and retrieval Q&A chains.
-
Agents: LangChain provides agents that allow applications to leverage dynamic calling chains to various tools (including LLMs) based on user input.
-
Memory: Maintaining application state between chain runs.
-
Callbacks: Recording and streaming the steps of sequential chains for efficient execution and monitoring of resource consumption.
Now let’s look at some use cases of LangChain.
-
Q&A or chat based on specific documents.
-
Chatbots.
-
Summarization.
-
Agents.
-
Interacting with APIs.
These are just a small fraction of the numerous use cases. We will learn and develop a semantic search application for Q&A on specific documents using the OpenAI API and the open-source vector database ChromaDB.


Setting Up the Environment and Loading Documents
Now, we will set up an environment using OpenAI’s LLM API for our semantic search application to answer user questions about a set of documents. We will use sample documents in this article, but you can use documents to generate Q&A applications. First, we need to install the following libraries:
Installing Project Dependencies
# install openai, langchain, sentence transformers and other dependencies
!pip install openai langchain sentence_transformers -q
!pip install unstructured -q
# install the environment dependencies
!pip install pydantic==1.10.8
!pip install typing-inspect==0.8.0 typing_extensions==4.5.
!pip install chromadb==0.3.26LangChain requires some environment dependencies with specific versions, such as pydantic, typing extensions, and ChromaDB. Once installed, you can run the following code in Colab or any other notebook environment.
LangChain Document Loader
LangChain provides a document loader class for loading documents from user input or databases. It supports various file formats, such as HTML, JSON, CSV, etc.
# import langchain dir loader from document loaders
from langchain.document_loaders import DirectoryLoader
# directory path
directory = '/content/pets'
# function to load the text docs
def load_docs(directory):
loader = DirectoryLoader(directory)
documents = loader.load()
return documents
documents = load_docs(directory)
len(documents)
---------------------------[Output]----------------------------------------
[nltk_data] Downloading package punkt to /root/nltk_data/...
[nltk_data] Unzipping tokenizers/punkt.zip.
[nltk_data] Downloading package averaged_perceptron_tagger to[nltk_data] /root/nltk_data/...
[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.5After loading the data, we will use a text splitter to break the text documents into fixed-size chunks to store them in the vector database. LangChain provides various text splitters, such as splitting by characters or by code.
# use text splitter to split text in chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split the docs into chunks using recursive character splitter
def split_docs(documents, chunk_size=1000, chunk_overlap=20):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents)
return docs
# store the split documents in docs variable
docs = split_docs(documents)After converting the documents into chunks, we will use an open-source embedding model to embed them into vectors in the next section.


Using LangChain and Open Source Models for Text Embedding
Embedding text is one of the most crucial concepts in the pipeline of LLM application development. All text documents need to be vectorized before they can be used for semantic search, summarization, and other tasks. We will use the open-source sentence transformer model “all-MiniLM-L6-v2” for text embedding. After embedding the documents, we can store them in the open-source vector database ChromaDB for semantic search. Let’s look at a hands-on code example.
# embeddings using langchain
from langchain.embeddings import SentenceTransformerEmbeddings
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# using chromadb as a vector store and storing the docs in it
from langchain.vectorstores import Chroma
db = Chroma.from_documents(docs, embeddings)
# Doing similarity search using query
query = "What are the different kinds of pets people commonly own?"
matching_docs = db.similarity_search(query)
matching_docs[0]
--------------------------[output]----------------------------------------
Document(page_content='Pet animals come in all shapes and sizes, each suited to different lifestyles and home environments. Dogs and cats are the most common, known for their companionship and unique personalities. Small mammals like hamsters, guinea pigs, and rabbits are often chosen for their low maintenance needs. Birds offer beauty and song, and reptiles like turtles and lizards can make intriguing pets. Even fish, with their calming presence, can be wonderful pets.', metadata={'source': '/content/pets/Different Types of Pet Animals.txt'})In the code above, we use embeddings to store in ChromaDB, which supports memory storage. Thus, we can query the database to get answers from the text documents. We asked about the different kinds of pets people usually own, and provided the correct answer along with the source of the answer.
Generative AI Application Using OpenAI API, ChromaDB, and LangChain

Semantic Search Q&A Using LangChain and OpenAI API
This pipeline requires interpreting the intent and context of the search terms and documents to generate more accurate search results. It can enhance search accuracy by understanding user intent, examining the relationships between words and concepts, and utilizing attention mechanisms in natural language processing (NLP) to generate context-aware search results.
LangChain provides an OpenAI chat interface for calling model APIs into your application and creating a Q&A pipeline that answers user queries based on given context or input documents. It essentially performs vectorized searches to find the most similar answers to the questions. (See the flowchart below)
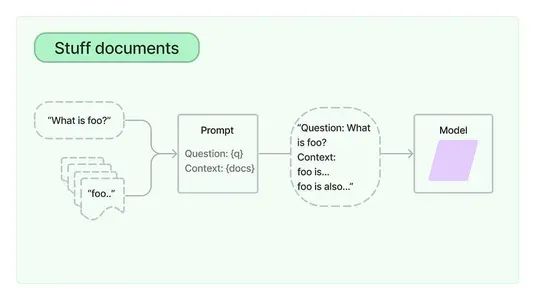
Context-Based Search Pipeline (Source: LangChain Docs)
# insert an openai key below parameter
import os
os.environ["OPENAI_API_KEY"] = "YOUR-OPENAI-KEY"
# load the LLM model
from langchain.chat_models import ChatOpenAI
model_name = "gpt-3.5-turbo"
llm = ChatOpenAI(model_name=model_name)
# Using q&a chain to get the answer for our query
from langchain.chains.question_answering import load_qa_chain
chain = load_qa_chain(llm, chain_type="stuff", verbose=True)
# write your query and perform similarity search to generate an answer
query = "What are the emotional benefits of owning a pet?"
matching_docs = db.similarity_search(query)
answer = chain.run(input_documents=matching_docs, question=query)
answer
-----------------------------------[Results]---------------------------------
'Owning a pet can provide numerous emotional benefits. Pets offer companionship and can help reduce feelings of loneliness and isolation. They provide unconditional love and support, which can boost mood and overall well-being. Interacting with pets, such as petting or with them, has been shown to decrease levels of stress hormones and increase the release of oxytocin, a hormone associated with bonding and relaxation. Pets also offer a sense of purpose and responsibility, as taking care of them can give a sense of fulfillment and provide a distraction from daily stressors. Additionally, the bond between pets and their owners can provide a sense of stability and consistency during times of personal or societal stress.'The code above uses LangChain’s ChatOpenAI() function to call the “gpt-3.5-turbo” model API and creates a Q&A chain to answer our query.
Generating Company Names Using LLM Chain
Another use case of large language models is generating company names using LLMChain, OpenAI LLM, and LangChain’s PromptTemplate based on a given description as a prompt. Please refer to the following code:
# import necessary components from langchain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# LLM by OpenAI
llm = OpenAI(temperature=0.9)
# Write a prompt using PromptTemplate
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?")
# create chain using LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
Output>>> Colorful Toes Co.Summarizing Text Documents Using LangChain
The chain also allows the development of text summarization applications, which help the legal industry to summarize large amounts of legal documents to expedite judicial processes. Refer to the example code using LangChain functions below:
# from langChain import load_summarize_chain function and OpenAI llm
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
# LLM by OpenAI
llm = OpenAI(temperature=0.9)
# create a chain instance with OpenAI LLM with map_reduce chain type
chain = load_summarize_chain(llm, chain_type="map_reduce")
chain.run(docs)LangChain’s easy-to-use interface unlocks many different applications and solves numerous problems for end users. As you can see, with just a few lines of code, we can harness the power of LLMs to summarize any data from any source on the web.


Conclusion
In conclusion, this blog post explores the exciting field of building generative AI applications using LangChain and the OpenAI API. We saw an overview of LangChain, its various components, and use cases for LLM applications. Generative AI is revolutionizing various fields, enabling us to generate realistic text, images, videos, and more. Semantic search is an application used to build Q&A applications using OpenAI LLMs, such as GPT-3.5 and GPT-4. Let’s review the key points of this blog:
-
We gained a brief overview of LangChain—an open-source framework for building LLM-driven applications.
-
We learned to use LangChain and ChromaDB—a vector database to store embeddings for similarity search applications.
-
Finally, we learned about OpenAI LLM APIs and how to build generative AI applications using LangChain.


Frequently Asked Questions
Question 1. What is generative AI?
Answer: Generative artificial intelligence is a machine learning technique that learns from large amounts of unstructured data to generate new text, images, music, or even videos.
Question 2. What is semantic search?
Answer: Semantic search applications require interpreting the intent and context of search terms and documents to generate precise search results for specific queries from users.
Question 3. What is LangChain, and what are its main features?
Answer: LangChain is a popular framework in the development of large language model applications. LangChain provides a framework for interacting with LLMs, external data sources, prompts, and user interfaces.
Question 4. What are the benefits of LangChain?
Answer: LangChain supports connections with various external data sources. It also integrates LLMs into various use cases, such as chatbots, summarization, and code generation.
Question 5. What databases does LangChain support?
Answer: LangChain supports vector databases like ChromaDB and Pinecone, as well as structured databases like MS SQL, MySQL, MariaDB, PostgreSQL, Oracle SQL, etc.
To learn more about large model artificial intelligence-related knowledge structures, please visit momodel.cn, where the Zhejiang Software Industry Association and Zhejiang University Ministry of Education Artificial Intelligence Innovation Collaborative Center will provide more support.
The Mo platform will regularly update books, videos, and other learning resources. These books and materials can also be obtained for free by following the WeChat public account MomodelAI, and everyone is welcome to use the “Mo AI Programming” WeChat mini-program.