Abstract
Large language models (LLMs) have demonstrated impressive capabilities. However, this does not mean they are error-free; anyone who has experienced ChatGPT’s “hallucinations” can attest to that. Retrieval Augmented Generation (RAG) is a framework designed to make LLMs more reliable by extracting relevant, up-to-date data directly related to user queries. In this article, I analyze the symptoms that lead to hallucinations, explain what RAG is, and discuss various methods of using it to address the limitations of language models.
Introduction
Imagine you ask an AI-based chat application a relatively simple, straightforward question. Suppose the application is ChatGPT, and we pose the question, “What is LlamaIndex?”

In fact, if you ask ChatGPT (or any other application powered by another LLM) any question about recent events, you are likely to receive a response like, “As of my last knowledge update…”
While many language models are trained on vast datasets, data is still data, and it can become outdated. Another fact is that the “intelligence” of a language model depends on the data used to train it. There are many techniques to improve the performance of language models, but what if the language model could access facts and data from the real world outside its training set without extensive retraining? In other words, what if we could supplement the model’s existing training with accurate, timely data?
This is precisely what Retrieval Augmented Generation (RAG) does, and its concept is simple: allow the language model to access relevant knowledge. This could include recent news, research, new statistics, or any new data. With RAG, LLMs can retrieve “up-to-date” information to provide higher quality responses and reduce hallucinations.
But what exactly does RAG provide? Where does it fit into the language chain? We will explore this and more in this article.
What is Semantic Search?
Unlike keyword search, which relies on precise literal matches, semantic search interprets the “real meaning” and intent of the query—it’s not just about matching keywords, but producing more relevant results related to the original query.
For example, a semantic search for the query “best budget laptop” would understand that the user is looking for “affordable” laptops without having to query that exact term. The search identifies contextual relationships between words.
This is because text embeddings, or the mathematical representation of semantics, can capture nuances. It’s an interesting process where embedded models provide the query, which is then transformed into a set of numerical vectors for matching and association.
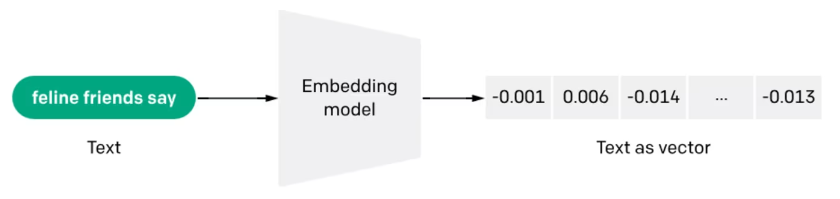
Text embeddings are a technique for representing text data in numerical form.
Vectors represent meanings, and the resulting benefit is that semantic search can perform many useful functions, such as eliminating irrelevant words from queries, indexing information for efficiency, and ranking results based on relevance and other factors.
When using language models, specialized databases optimized for speed and scale are absolutely necessary, as you may be searching through billions of documents. By implementing semantic search with text embeddings, the efficiency of storing and querying high-dimensional embedding data is significantly higher, allowing for rapid and effective evaluation of document vectors across large datasets.
This is the background we need to begin discussing and delving into RAG.
RAG
Retrieval Augmented Generation (RAG) is based on research from the Meta team, aimed at enhancing the natural language processing capabilities of LLMs. Meta’s research suggests combining the retriever and generator components to make language models smarter and more accurate in generating text in a human-like manner, which is often referred to as Natural Language Processing (NLP).
The core of RAG is the seamless integration of retrieval-based models for acquiring external information and the generative model skills for producing natural language. RAG models outperform standard language models on knowledge-intensive tasks, such as enhancing LLMs to answer questions using retrieved information; this also helps make more informed responses.
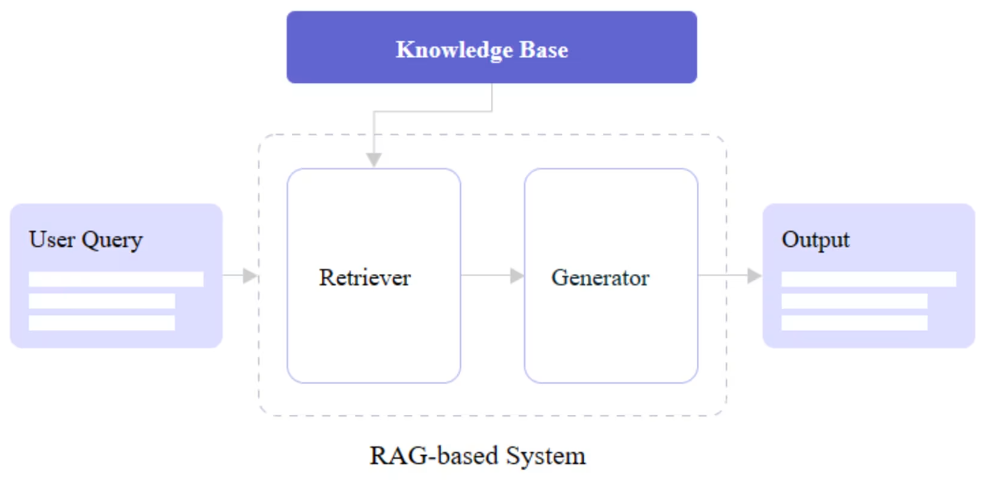
You may notice two core components of RAG in the image above: the retriever and the generator. Let’s take a closer look at how each contributes to the RAG architecture.
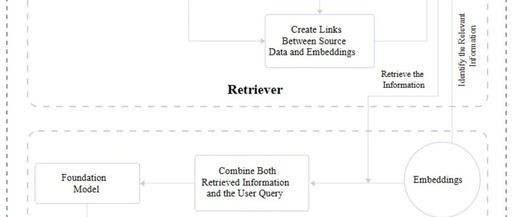
Retriever
The retriever module is responsible for finding the most relevant information from the dataset to respond to the user query through vectors generated by text embeddings. In short, it receives the query and retrieves the most accurate information based on semantic search from the vector database.
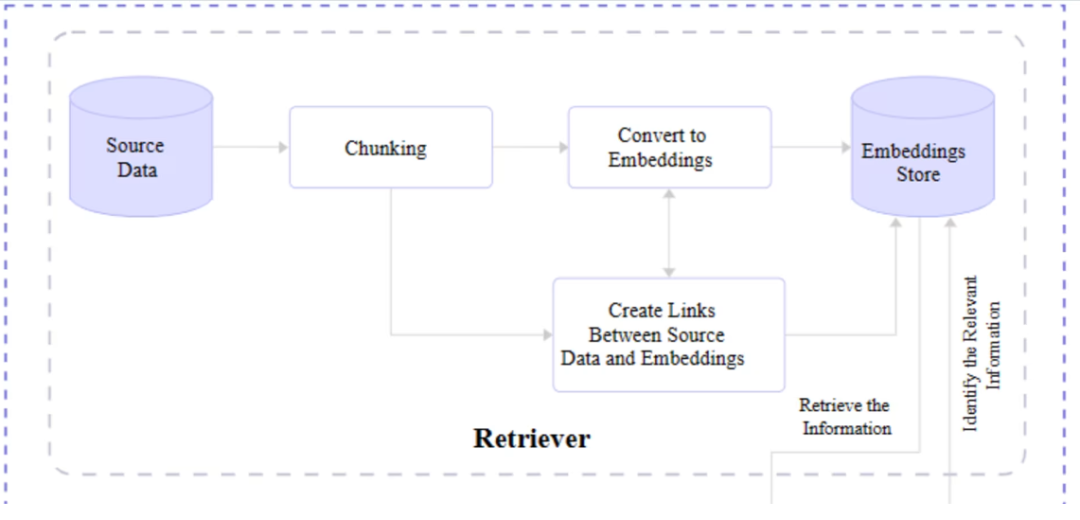
The retriever is itself a model. However, unlike language models, the retriever does not engage in “training” or machine learning tasks. They are more of an enhancement or add-on component, providing additional context understanding and effective information retrieval capabilities.
OpenAI, Cohere, and others offer a variety of retrievers, and we can also find many open-source retrievers in the Hugging Face community.
Generator
Once the retriever finds relevant information, it needs to send it back to the application to be displayed to the user. Alternatively, we need a generator that can convert the retrieved data into human-readable content.
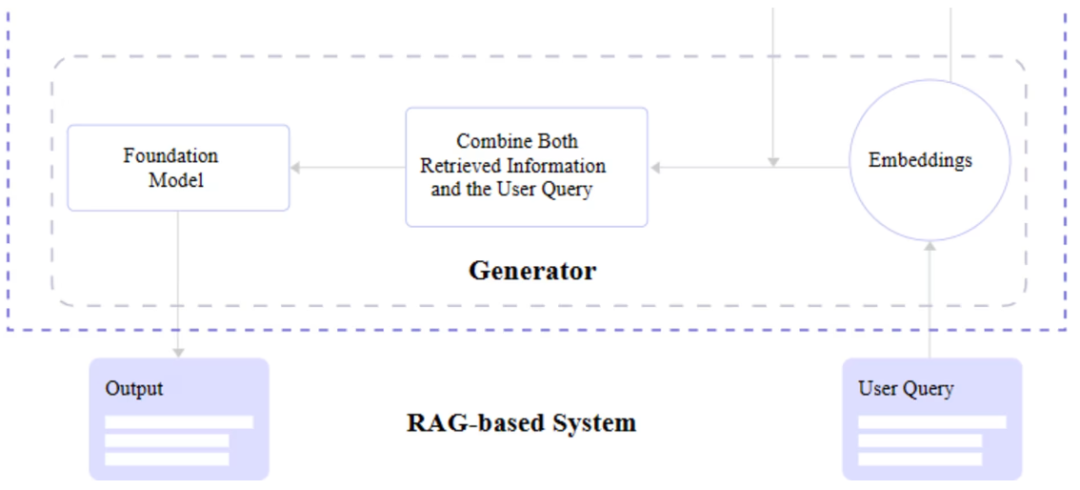
What happens behind the scenes is that the generator takes the text embedding vectors received from the retriever, mixes them with the original query, and generates text through a trained language model during the NLP steps.
Complete RAG Process
Putting everything together, the complete RAG process is as follows:
-
Make a query.
-
The query is passed to the RAG system.
-
The RAG system encodes the query as a text embedding and compares it with the information dataset.
-
The RAG retriever uses its semantic search capabilities to determine the most relevant information and converts it into vector embeddings.
-
The RAG retriever sends the parsed embeddings to the generator.
-
The generator receives the embeddings and combines them with the original query.
-
The generator passes its work to the language model to produce content that appears natural to the user.
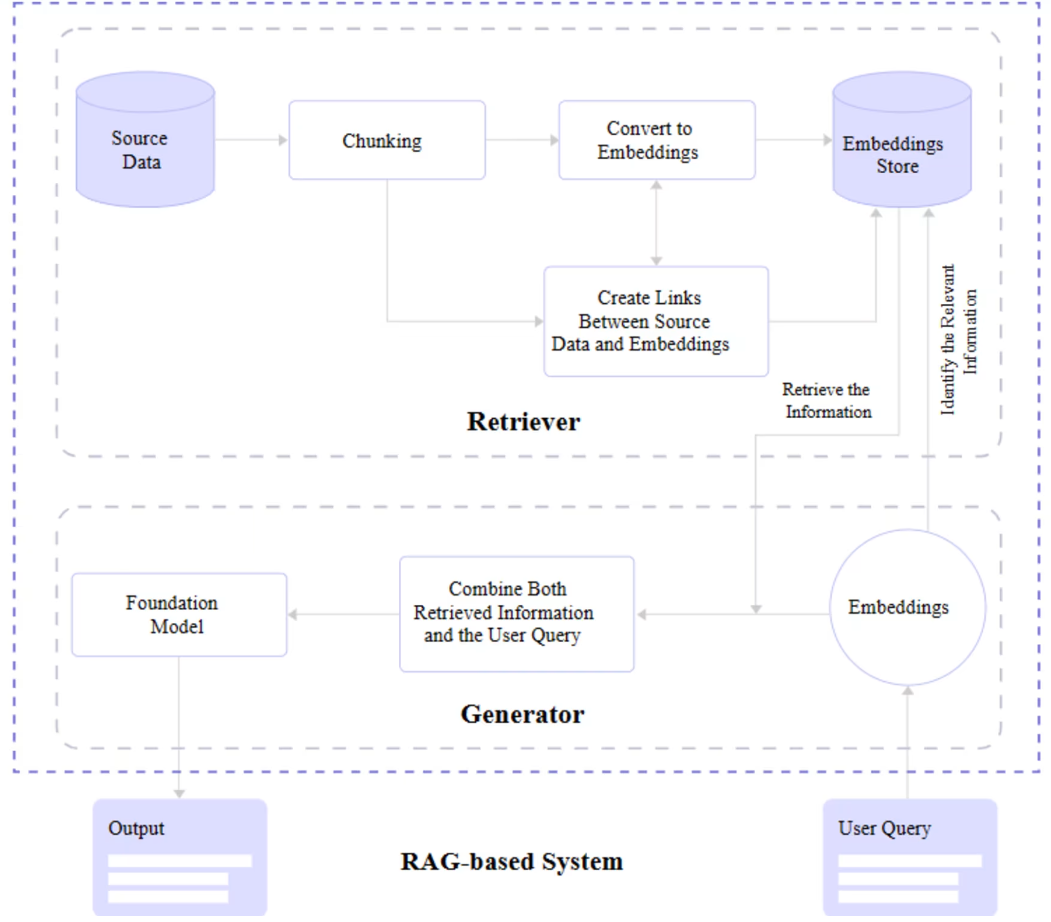
Complete RAG architecture: integrating retriever and generator components to enhance language model performance.
LLM Hallucinations and Knowledge Limitations
We start this article by describing the “hallucinations” in LLM erroneous answers or similar phrases like “I don’t know, but here’s what I know.” LLMs “make things up” because they simply do not have updated information to respond.
Let’s revisit the first query used at the beginning of this article—”What is LlamaIndex?”—and compare the responses of GPT-3.5 and the locally running LLama2-13B language model:

GPT-3.5
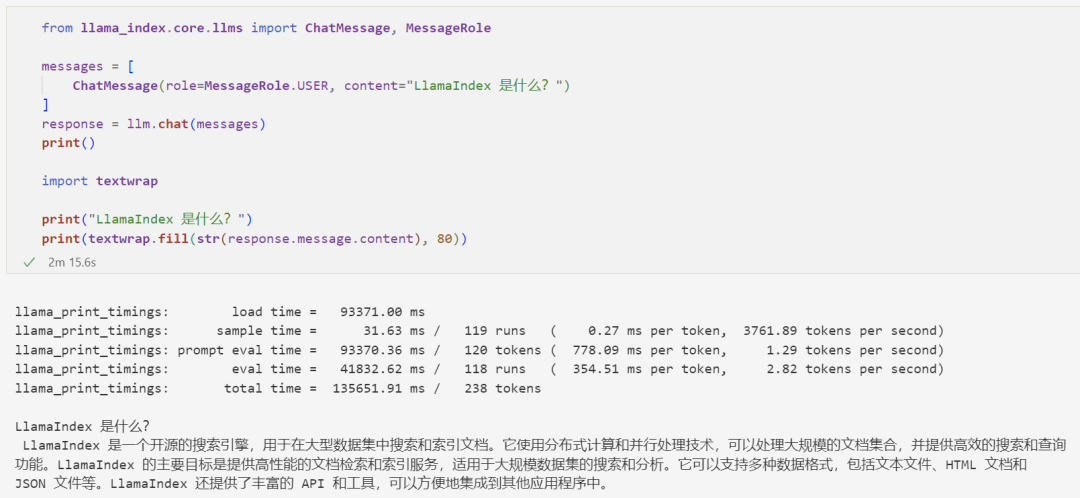
LLama2-13B
From the response of the LLama2-13B model above, this is a good example of how LLMs can give seemingly credible but actually incorrect answers.LLMs are designed to predict the next “reasonable” token in a sequence, regardless of whether these tokens are words, subwords, or characters. They do not fundamentally understand the full meaning of the text. Even the most advanced models (including GPT-4) struggle to avoid giving false responses, especially on topics they lack understanding of.
There are many reasons for LLMs to produce hallucinations and various types of hallucinations:

Integrating RAG with Language Models
Alright, we know that LLMs sometimes produce hallucinated answers. We know that hallucinations are often the result of outdated information. We also know there is something called RAG that can supplement LLMs with updated information.
But how do we connect RAG and LLM?
Introduction from the LlamaIndex official website:

First, I will translate the introduction of the LlamaIndex official website into Chinese and save it to a local file data/LlamaIndex.txt:
LlamaIndex is a data framework for applications based on LLMs that benefits from context enhancement. This LLM system is called a RAG system, which stands for “Retrieval Augmented Generation.” LlamaIndex provides the necessary abstractions to ingest, build, and access private or domain-specific data more easily, allowing this data to be securely injected into LLMs for more accurate text generation. It can be used in Python (these documents) and Typescript.
Then, I will load the Llama2-13B model locally:
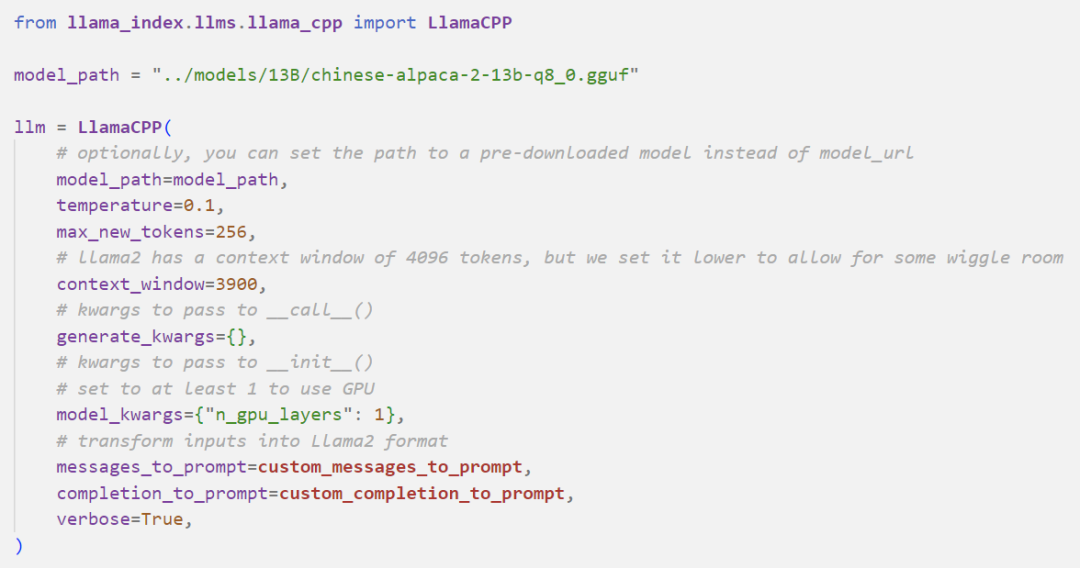
Next, use Hugging Face to load the text embedding model:

Finally, build the index according to the documents and construct the query engine:

Now, let’s query again, “What is LlamaIndex?”:

At this point, the LLM can correctly answer the question based on our enhanced contextual knowledge.
We provide the model with content it can use when receiving queries on specific topics by giving it a simple text file. Of course, this is a rather simple and artificial example.
Ultimately, the responses of language models depend on the data provided to them, as we have seen, even the most widely used models contain outdated information. Language models do not acknowledge failure but instead provide confident guesses that may be misinterpreted as accurate information.