

1. Introduction to LlamaIndex
LlamaIndex is a Python library created by Jerry Liu that enables efficient text search and summarization of large document collections using language models.Developers can quickly add private/custom data to enhance existing LLMs with LlamaIndex. It provides personalized and data-driven responses without the need for retraining large models.

Due to the limited context of large models, processing ultra-large documents is costly, and the efficiency of keyword searches on raw text is very low. To overcome these challenges, LlamaIndex employs two key strategies. First, it chunks documents into smaller contexts, such as sentences or paragraphs, referred to as nodes. Language models can effectively handle these nodes. Second, LlamaIndex uses vector embeddings to index these nodes, enabling fast and semantic searches.
Function Examples:
-
Summarize a 1GB dataset through query summaries. LlamaIndex retrieves relevant nodes and synthesizes summaries;
-
Find documents mentioning a person by embedding names and retrieving similar nodes;
-
Extract entities from the dataset by querying similar locations;
-
Record QA by querying answers to questions;
-
Enhance data chatbots by querying responses to user messages;
-
LlamaIndex enables knowledge agents to autonomously retrieve and make informed decisions using efficient semantic searches over large document collections;
-
Conduct structured analysis by querying structured data such as tables, CSV files, databases, etc.
2. How to Use LlamaIndex?
LlamaIndex achieves scalable text search and summarization by chunking documents into smaller nodes, indexing them for efficient retrieval, and generating responses using language models.
The general steps to use LlamaIndex are as follows:

The key steps are to load data as documents, parse them into nodes, build an index on the documents/nodes, query the index to retrieve relevant nodes, and then parse the response object. The index can also be persisted and reloaded from disk.
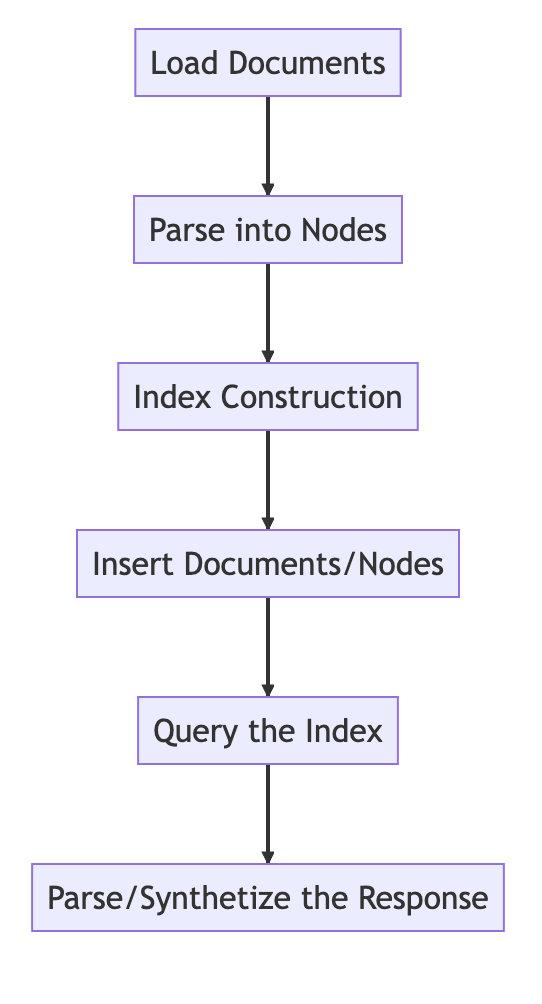
Example code is as follows:
pip install llama-index"""This module provides an example of using the llama_index library to load and query documents."""from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects, either manually or through a data loader
documents = SimpleDirectoryReader('data').load_data()
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
person = query_engine.query( "Extract all the person in the content, format as JSON with a lastname" " and first_name property")
print(person)
location = query_engine.query( "Extract all the location in the content, format as JSON with a name" " and the country")
print(location)PS: Data from: https://github.com/raphaelmansuy/digital_palace/blob/main/01-articles/llama_index/data/paul_graham_essay.txt
Output:
The context does not provide any information about what the author did growing up.
What is the data about: The text is about the author's experiences and reflections during their time at art school and their decision to pursue a career in painting.
{"persons": [ {"last_name": "Graham", "first_name": "Paul"}, {"last_name": "McCarthy", "first_name": "John"}]}{"locations": [ {"name": "New York City", "country": "United States"}, {"name": "Upper East Side", "country": "United States"}, {"name": "Yorkville", "country": "United States"}, {"name": "Cambridge", "country": "United States"}, {"name": "England", "country": "United Kingdom"}, {"name": "Florence", "country": "Italy"}, {"name": "Piazza San Felice", "country": "Italy"}, {"name": "Pitti", "country": "Italy"}, {"name": "Orsanmichele", "country": "Italy"}, {"name": "Duomo", "country": "Italy"}, {"name": "Baptistery", "country": "Italy"}, {"name": "Via Ricasoli", "country": "Italy"}, {"name": "Piazza San Marco", "country": "Italy"}]}"3. Basic Principles of LlamaIndex
3.1 Chunking Process
LlamaIndex breaks input documents into smaller chunks of nodes. This chunking is done by NodeParser. By default, SimpleNodeParser is used, which chunks documents into sentences.
Chunking process is as follows:
-
NodeParser receives a list of Document objects;
-
Uses spaCy’s sentence segmentation to split the text of each document into sentences;
-
Each sentence is wrapped in a TextNode object, representing a node;
-
TextNode contains the sentence text and metadata, such as document ID, position in the document, etc.;
-
Returns a list of TextNode objects.
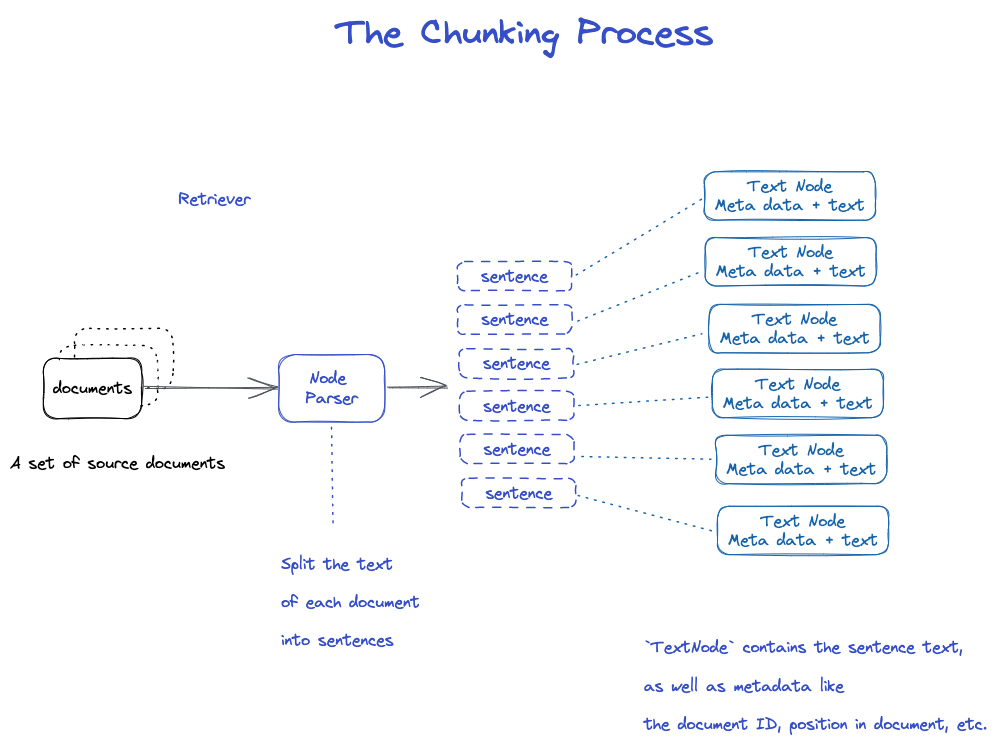
3.2 Converting Chunks to Embeddings and Nodes
Then the list of TextNode objects is passed to the index for embedding.
-
For each TextNode, a sentence transformer model like all-mpnet-base-v2 is used to encode the text into embeddings;
-
Store this embedding in the TextNode object;
-
The TextNode and its embedding and metadata can be indexed in the Node object.
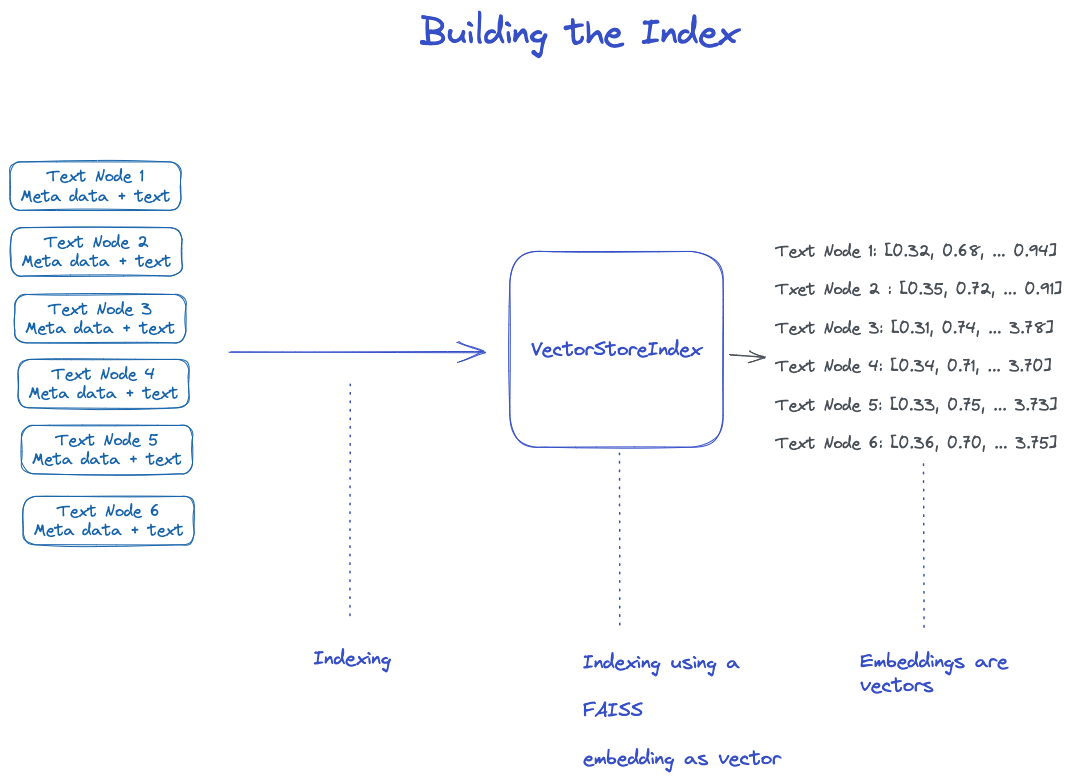
3.3 Building the Index
Build the index on the list of Node objects.
-
For VectorStoreIndex, the text embeddings on nodes are stored in a FAISS index, allowing for fast similarity searches on nodes;
-
The index also stores metadata for each node, such as document ID, position, etc.;
-
Nodes can retrieve content from a specific document or retrieve specific documents.
FAISS (Facebook AI Similarity Search) is a library developed by Facebook AI for efficient similarity search and dense vector clustering. The algorithms it contains can search any size set of vectors, up to billions of vectors. FAISS is built around an index type that stores a set of vectors and provides a function for searching through them by L2 (Euclidean) and/or dot product vector comparisons.
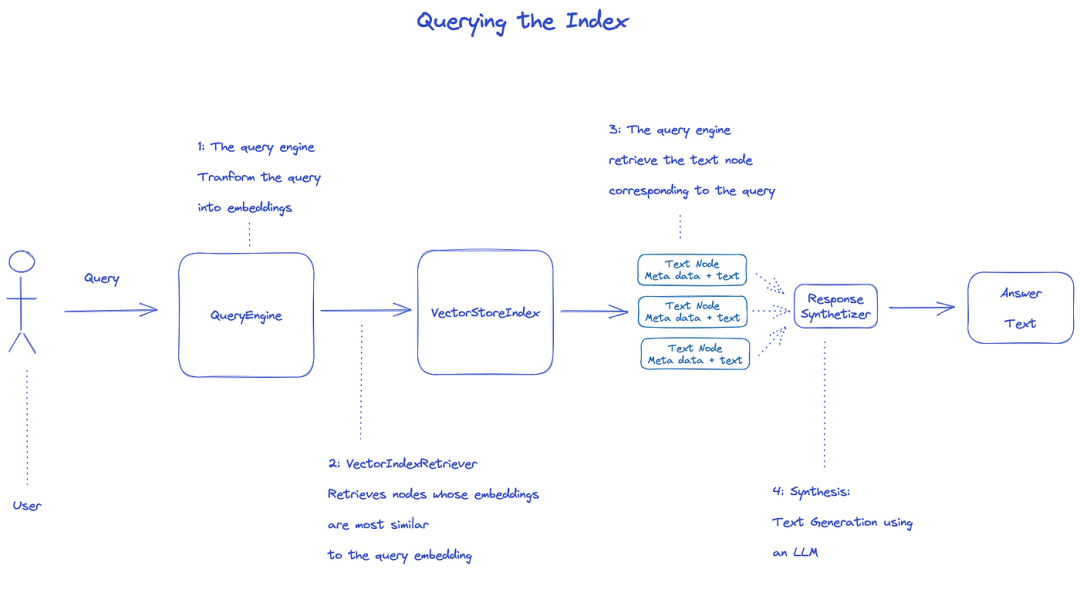
3.4 Querying the Index
To query the index, the QueryEngine will be used.
-
Retriever retrieves relevant nodes from the queried index. For example, VectorIndexRetriever retrieves nodes whose embeddings are most similar to the query embedding;
-
The retrieved list of nodes is passed to the ResponseSynthesizer to generate the final output;
-
By default, the ResponseSynthesizer processes each node sequentially, calling the LLM API for each node once;
-
LLM inputs the query and node text to get the final output;
-
The responses from each node are aggregated into the final output string.
In summary, the index allows for rapid retrieval of relevant nodes using embedding, followed by the use of LLM to synthesize the final output. This architecture allows customization of each component, such as chunking, embedding, retrieval, and synthesis.
References:
[1] https://medium.com/@raphael.mansuy/llamaindex-chunk-index-query-how-llamaindex-unlocks-custom-llms-329d543a06b7
To join the technical group, please add AINLP assistant WeChat (id: ainlp2)
Please note the specific direction + related technical points used.
About AINLP
AINLP is an interesting AI natural language processing community focusing on sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include LLM, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, job experience sharing, etc. Everyone is welcome to follow! To join the technical group, please add AINLP assistant WeChat (id: ainlp2), noting your work/research direction + purpose of joining the group.