In this blog post, we introduce a brand new data structure in LlamaIndex: the Document Summary Index. We describe how it helps provide better retrieval performance compared to traditional semantic search, along with an example.

Background
One of the core scenarios for large language models (LLM) is question answering on user data. To achieve this, we pair the LLM with a “retrieval” model that can perform information retrieval on a knowledge corpus and use the LLM to synthesize responses from the retrieved text. This overall framework is called retrieval-augmented generation.
Most users building LLM-supported QA systems today tend to perform some form of the following operations:
-
Obtain source documents and split each document into text blocks -
Store text blocks in a vector database -
During queries, retrieve text blocks through embedding similarity and/or keyword filters. -
Execute responses and summarize answers
For various reasons, this approach provides limited retrieval performance.
Limitations of Existing Methods
Using text blocks for embedding retrieval has some limitations.
-
Text blocks lack global context. Often, the context needed for a question exceeds the content indexed in a specific block. -
Carefully tuning top-k/similarity score thresholds. If the assumed value is too small, you miss context. If the assumed value is too large, the cost/delay may increase with more irrelevant context, adding noise. -
Embeddings do not always select the most relevant context for the question. Embeddings are determined separately for text and context.
Adding keyword filters is one way to enhance retrieval results. But this also brings a series of challenges. We need to manually or through NLP keyword extraction/topic tagging models sufficiently determine appropriate keywords for each document. Additionally, we need to sufficiently infer the correct keywords from the queries.
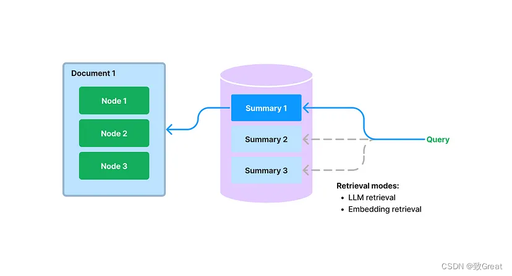
Document Summary Index
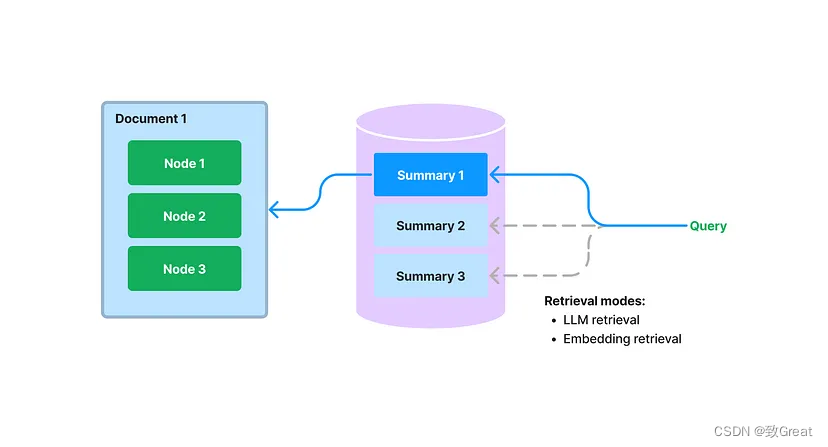 A new index is proposed in LlamaIndex that extracts/indexes unstructured text summaries for each document. This index helps improve retrieval performance, surpassing existing retrieval methods. It helps index more information than a single text block and has more semantics than keyword tags. It also allows for more flexible forms of retrieval: we can perform both LLM retrieval and embedding-based retrieval simultaneously.
A new index is proposed in LlamaIndex that extracts/indexes unstructured text summaries for each document. This index helps improve retrieval performance, surpassing existing retrieval methods. It helps index more information than a single text block and has more semantics than keyword tags. It also allows for more flexible forms of retrieval: we can perform both LLM retrieval and embedding-based retrieval simultaneously.
How It Works
During the build phase, we extract each document and use the LLM to extract summaries from each document. We also split the documents into text blocks (nodes). Both summaries and nodes are stored in our document storage abstraction. We maintain a mapping from summaries to source documents/nodes.
During queries, we use the following methods to retrieve relevant documents based on summaries for the query:
-
LLM-based retrieval: We provide the LLM with a set of document summaries and ask the LLM to determine which documents are relevant and their relevance scores. -
Embedding-based retrieval: We retrieve relevant documents based on summary embedding similarity (using a top-k cutoff).
Note that this method of retrieving document summaries (even using embedding-based methods) is different from embedding-based text block retrieval. The retrieval class of document summary index retrieves all nodes of any selected document, rather than returning relevant blocks at the node level.
Storing document summaries also enables LLM-based retrieval. We can first let the LLM check concise document summaries to see if they are relevant to the query, rather than providing the entire document to the LLM from the start. This leverages the reasoning capabilities of the LLM, which are more advanced than embedding-based lookups, while avoiding the cost/delay of providing the entire document to the LLM.
Concept
Retrieving documents with summaries can be seen as an “in-between” of semantic search and powerful summaries of all documents. We look for documents based on the relevance of summaries to a given query, and then return all nodes corresponding to the retrieved documents.
Why do we do this? By retrieving context at the document level, this retrieval method provides users with more context than top-k on text blocks. However, it is also a more flexible/automated method than topic modeling; no more worrying about whether your text has the right keyword tags!
Example
Let’s look at an example demonstrating the document summary index, which includes Wikipedia articles about different cities.
The rest of this guide showcases relevant code snippets. You can find the complete walkthrough here (this is the notebook link).
We can build a GPTDocumentSummaryIndex from a set of documents and pass in a ResponseSynthesizer object to synthesize the summaries of the documents.
from llama_index import (
SimpleDirectoryReader,
LLMPredictor,
ServiceContext,
ResponseSynthesizer
)
from llama_index.indices.document_summary import GPTDocumentSummaryIndex
from langchain.chat_models import ChatOpenAI
# load docs, define service context
...
# build the index
response_synthesizer = ResponseSynthesizer.from_args(response_mode="tree_summarize", use_async=True)
doc_summary_index = GPTDocumentSummaryIndex.from_documents(
city_docs,
service_context=service_context,
response_synthesizer=response_synthesizer
)
After building the index, we can obtain a summary of any given document:
summary = doc_summary_index.get_document_summary("Boston")
Next, let’s look at an example of LLM-based index retrieval.
from llama_index.indices.document_summary import DocumentSummaryIndexRetriever
retriever = DocumentSummaryIndexRetriever(
doc_summary_index,
# choice_select_prompt=choice_select_prompt,
# choice_batch_size=choice_batch_size,
# format_node_batch_fn=format_node_batch_fn,
# parse_choice_select_answer_fn=parse_choice_select_answer_fn,
# service_context=service_context
)
retrieved_nodes = retriever.retrieve("What are the sports teams in Toronto?")
print(retrieved_nodes[0].score)
print(retrieved_nodes[0].node.get_text())The retriever will retrieve a set of relevant nodes for a given index.
Note that in addition to the document text, the LLM also returns relevance scores:
8.0
Toronto ( (listen) tə-RON-toh; locally [təˈɹɒɾ̃ə] or [ˈtɹɒɾ̃ə]) is the capital city of the Canadian province of Ontario. With a recorded population of 2,794,356 in 2021, it is the most populous city in Canada...
Advanced API
query_engine = doc_summary_index.as_query_engine(
response_mode="tree_summarize", use_async=True
)
response = query_engine.query("What are the sports teams in Toronto?")
print(response)
Underlying API
# use retriever as part of a query engine
from llama_index.query_engine import RetrieverQueryEngine
# configure response synthesizer
response_synthesizer = ResponseSynthesizer.from_args()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
# query
response = query_engine.query("What are the sports teams in Toronto?")
print(response)