Click on the above“Beginner Learning Vision”, select to addStar or “Top”
Heavy content delivered immediately
Introduction
1. Introduction
Since 2010, deep learning methods have brought tremendous changes to the fields of speech recognition, image recognition, and natural language processing. Tasks in these fields only involved unimodal inputs, but recently more applications require the wisdom of multiple modalities. Multimodal deep learning mainly includes three aspects: multimodal learning representation, multimodal signal fusion, and multimodal applications, while this article mainly focuses on related fusion methods in computer vision and natural language processing, including network structure design and fusion methods (for specific tasks).
2. Multimodal Fusion Methods
Multimodal fusion is a very critical research point in multimodal studies, integrating information extracted from different modalities into a stable multimodal representation. Multimodal fusion and representation are closely related; if a process focuses on using a certain architecture to integrate different unimodal representations, it is classified as fusion. Fusion methods can also be categorized into late and early fusion based on their occurrence. Since early and late fusion suppresses intra- or inter-modal interactions, current research mainly focuses on intermediate fusion methods, allowing these fusion operations to be placed within multiple layers of deep learning models. The methods for fusing text and images mainly include three: operation-based, attention-based, and tensor-based methods.
a) Operation-based Fusion Methods
Feature vectors from different modalities can be integrated through simple operations, such as concatenation and weighted summation. Such simple operations have almost no connection between parameters, but subsequent network layers will automatically adapt to these operations.
l Concatenation can be used to combine low-level input features [1][2][3] or high-level features (features extracted from pre-trained models) [3][4][5].
l Weighted sum for scalar-weighted summation methods requires the vectors generated by pre-trained models to have a defined dimension, arranged in a specific order suitable for element-wise addition [6]. To meet this requirement, fully connected layers can be used to control dimensions and reorder each dimension.
A recent study [7] adopted progressive exploration neural architecture search [8][9][10] to find suitable settings for fusion. Each fusion function is configured based on the layers to be fused and whether to use concatenation or weighted sum as the fusion operation.
b) Attention-based Fusion Methods
Many attention mechanisms have been applied to fusion operations. The attention mechanism typically refers to a set of scalar weight vectors dynamically generated at each time step by a group of “attention” models [11][12]. Multiple outputs of these attention heads can dynamically produce weights used during summation, thus preserving additional weight information during concatenation. When applying the attention mechanism to images, different weights are assigned to different regions of the image feature vectors to obtain a final overall image vector.
Graph Attention Mechanism
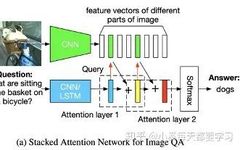
This extends the LSTM model used for text processing by incorporating an image attention model based on previous LSTM hidden states, with inputs being the concatenation of the current embedded word and the participating image features [13]. The final LSTM hidden state is used for a multimodal fusion representation, applied to VQA tasks. This RNN-based encoder-decoder model is used to assign weights to image features for the image captioning task [14]. Additionally, for visual question answering (VQA) tasks, the attention model can locate the corresponding position of the image through a text query [15]. Similarly, Stacked Attention Networks (SANs) have been proposed to use multi-layer attention models to query the image multiple times, gradually inferring answers, simulating a multi-step reasoning process [16]. Through multiple iterations, attention is allocated to the relevant regions of the image. First, a feature attention distribution is generated based on image features and text features, and from this distribution, the weight and Vi of each image region are obtained, resulting in a refined query vector via u=Vi+Vq. This process
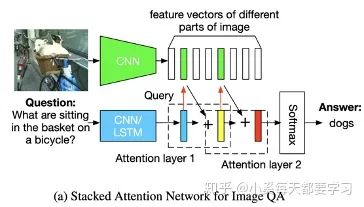
Multiple iterations ultimately focus on the relevant areas of the problem. Of course, similar to SAN, there is also [17].
A dynamic memory network has also been upgraded and used to encode questions and images separately. This network uses attention-based GRUs to update contextual memory and retrieve necessary information [18].
The bottom-up and top-down attention methods (Up-Down), as the name suggests, simulate the human visual system by combining two visual attention mechanisms [19]. The bottom-up attention mechanism first selects a series of candidate regions in the image using object detection algorithms (such as Faster R-CNN), while the top-down attention mechanism combines visual information and semantic features to generate an attention-aware image feature vector, ultimately serving image description and VQA tasks. At the same time, the attention-aware image feature vector can also be dot-multiplied with the text vector. Complementary image features from different models (ResNet and Faster R-CNN) can also be used for various image attention mechanisms [20]. Furthermore, the reverse application of the image attention mechanism can generate text features from the input image + text, and can also be used for text-to-image generation tasks [21].
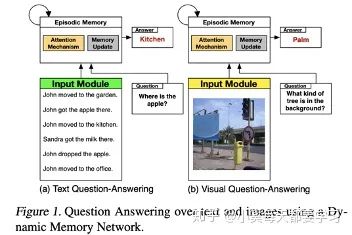
Symmetric Attention Mechanism for Graph and Text
Unlike the aforementioned image attention mechanism, co-attention mechanisms use symmetric attention structures to generate attended image feature vectors and attended language vectors [22]. Parallel co-attention mechanisms simulate the attention distribution of images and languages using joint representation methods. Alternating co-attention mechanisms have a cascading structure, first generating an attention-aware image vector using language features, then generating an attention-aware language vector using the attention-aware image vector.
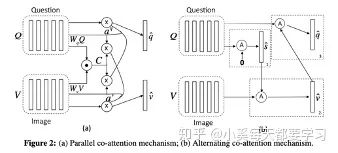
Similar to the parallel co-attention mechanism, the Dual Attention Network (DAN) simultaneously estimates the attention distributions of images and texts to obtain the final attention feature vector [23]. This attention model conditions on features and memory vectors related to the patterns. This is a key difference from co-attention, as the memory vector can be iteratively updated at each inference step using the repeated DAN structure.
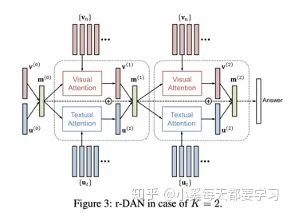
Stacked Latent Attention (SLA) improves SAN by connecting the raw features of the image with shallow network vectors to preserve latent information during intermediate reasoning stages [24]. Of course, there is also a similar dual-stream parallel co-attention structure used for simultaneous attention to image and language features, facilitating iterative reasoning using multiple SLA layers. Dual Recursive Attention Units utilize LSTM models for text and images to achieve a parallel co-attention structure, assigning attention weights for each input position in the representations obtained from stacking CNN layers of convolutional image features [25]. To simulate high-order interactions between two data modalities, the high-order correlations between the two data modalities can be computed as the inner product of two feature vectors, resulting in attention feature vectors for interactions between the two modalities [26].
Bilinear Pooling Fusion Methods
Bilinear pooling is mainly used to fuse visual feature vectors and text feature vectors to obtain a joint representation space by calculating their outer product. This method can utilize all interactions of the elements of these two vectors, also known as second-order pooling [30]. Unlike simple vector combination operations (assuming each modality’s feature vector has n elements), simple operations (such as weighted summation, bitwise operations, concatenation) generate an n or 2n-dimensional representation vector, while bilinear pooling produces an n squared dimensional representation. By linearizing the matrix generated by the outer product into a vector representation, this means that this method is more expressive. Bilinear representation methods are often transformed into corresponding output vectors through a two-dimensional weight matrix, equivalent to using a three-dimensional tensor to fuse two input vectors. When calculating the outer product, each feature vector can add a 1 to maintain unimodal input features in the bilinear representation [32]. However, due to its high dimensionality (typically on the order of hundreds of thousands to millions of dimensions), bilinear pooling often requires decomposing the weight tensor for appropriate and effective training of the relevant models.
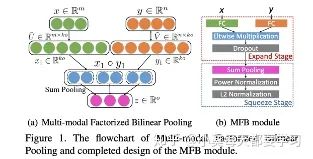
Factorization of Bilinear Pooling
Since the representation obtained from bilinear pooling is closely related to polynomial kernels, various low-dimensional approximations can be used to obtain compact bilinear representations [32]. Count sketch and convolution can be used to approximate polynomial kernels [33][34], leading to the emergence of Multimodal Compact Bilinear Pooling (MCB) [35]. Alternatively, by applying low-rank control to the weight tensor, Multimodal Low-rank Bilinear Pooling (MLB) decomposes the three-dimensional weight tensor of bilinear pooling into three two-dimensional weight matrices [36]. Specifically, visual and textual feature vectors are linearly projected onto low-dimensional matrices through two input factor matrices. Then, element-wise multiplication is used to fuse these factors, followed by linear projection of the output factors using a third matrix. Multimodal Factorized Bilinear Pooling (MFB) modifies MLB by summing the results of element-wise multiplication within each non-overlapping one-dimensional window, aggregating the results [37]. Multiple MFB models can be cascaded to model high-order interactions between input features, known as Multimodal Factorized High-order Pooling (MFH) [38].
MUTAN is a Tucker decomposition method based on multimodal tensors that uses Tucker decomposition [39] to decompose the original three-dimensional weight tensor operator into low-dimensional core tensors and three two-dimensional weight matrices used by MLB [40]. The core tensor models different forms of interactions. MCB can be seen as a MUTAN with fixed diagonal input factor matrices and sparse fixed kernel tensors, while MLB can be seen as a MUTAN with a unit tensor as its kernel tensor.
The latest AAAI 2019 proposed BLOCK, a block-based hyper-diagonal fusion framework [41], aimed at the dissolution and synthesis of block items [42]. BLOCK generalizes MUTAN to the sum of multiple MUTAN models, providing richer modeling for interactions between modalities. Furthermore, bilinear pooling can be generalized to more than two modalities, for example, using outer products to model interactions between video, audio, and language representations [43].
Bilinear Pooling and Attention Mechanisms
Bilinear pooling and attention mechanisms can also be combined. The bilinear representations of MCB/MLB can be used as input features for attention models to obtain attention-aware image feature vectors, which can then be fused with text feature vectors using MCB/MLB, forming the final joint representation [44][45]. MFB/MFH can be used for alternating co-attention learning joint representations [46][47].
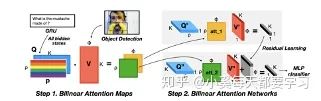
Bilinear Attention Networks (BAN) utilize MLB to fuse images and texts, generating bilinear attention maps that represent attention distribution, which are then used as weight tensors for bilinear pooling, further fusing image and text features [48].
3. Conclusion
In recent years, the main multimodal fusion methods are attention-based and bilinear pooling-based methods. Among them, there is still significant room for improvement in the mathematical effectiveness of bilinear pooling.
Zhang, C., Yang, Z., He, X., & Deng, L. (2020). Multimodal intelligence: Representation learning, information fusion, and applications. IEEE Journal of Selected Topics in Signal Processing.
References:
Good news!
Beginner Learning Vision Knowledge Group
Now open to the public 👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of "Beginner Learning Vision" WeChat public account to download the first Chinese version of the OpenCV extension module tutorial online, covering more than twenty chapters including extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of "Beginner Learning Vision" WeChat public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of "Beginner Learning Vision" WeChat public account to download 20 practical projects based on OpenCV to advance OpenCV learning.
Group Chat
Welcome to join the WeChat group of public account readers to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes, otherwise, it will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed. Thank you for understanding~