MLNLP community is a renowned machine learning and natural language processing community both domestically and internationally, covering NLP graduate students, university professors, and corporate researchers.
The Vision of the Community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners.
Reprinted from | ZHUAN ZHI
During the training and inference of multimodal models, data samples may miss certain modalities due to sensor limitations, cost constraints, privacy issues, data loss, and temporal and spatial factors, leading to a decline in model performance. This review outlines the latest advancements in the field of Multimodal Learning with Missing Modalities (MLMM), focusing on deep learning techniques. This is the first comprehensive review covering the historical context of MLMM and how it differs from standard multimodal learning settings, followed by a detailed analysis of current MLMM methods, applications, and datasets, and a discussion of the challenges faced in this field and potential future directions.
1 Introduction
Multimodal learning has become a key area in the field of artificial intelligence (AI), focusing on integrating and analyzing various types of data, including visual, textual, auditory, and sensor information (Figure 1a). This approach reflects the human ability to better understand and interact with the environment by combining multiple senses. Modern multimodal models leverage the powerful generalization capabilities of deep learning to reveal complex patterns and relationships that unimodal systems may not detect. This capability has driven progress in several fields, including computer vision. Recent surveys in these areas show a significant impact of multimodal methods, demonstrating their ability to enhance performance and enable more complex AI applications【7,224】.
However, multimodal systems often face the problem of missing or incomplete data in practical applications. This can occur due to various factors such as sensor failures, hardware limitations, privacy issues, environmental interference, and data transmission problems. As shown in Figure 1b, in the case of tri-modal data, data samples can be categorized as full-modal (containing information from all three modalities) or missing-modal (completely lacking one or more modalities). These issues can arise at any stage from data collection to deployment, significantly affecting model performance. Such problems are widespread in the real world across multiple fields. In the field of affective computing, researchers【31,150】 have found that due to camera occlusions or excessive microphone noise, samples may only contain available images or audio. Similarly, in space exploration, NASA’s “Ingenuity” Mars helicopter【36】 faced challenges with missing modalities due to extreme temperature cycles on Mars causing its inclinometer to fail. To address this issue, NASA applied a software patch that modified the initialization of the navigation algorithm【169】. In the field of medical AI, certain modalities may be unavailable in some data samples due to privacy concerns, leading to inherent modality missing in multimodal datasets【222】. The unpredictability of real-world scenarios and the diversity of data sources further exacerbate this challenge. Therefore, developing multimodal systems that can effectively operate in the presence of missing modalities has become a key research direction in this field.
In this review, we refer to the challenges of handling missing modalities as the “missing modality problem.” The methods we address for solving this problem are termed “Multimodal Learning with Missing Modalities” (MLMM). This approach contrasts with traditional full-modal multimodal learning (MLFM). Specifically, in MLFM tasks, given a dataset containing HH modalities, it is typically required that the trained model be capable of processing and integrating information from all HH modalities for prediction. During training and testing, complete information samples from all HH modalities are used. In contrast, in MLMM tasks, due to data collection restrictions or constraints in the deployment environment, fewer than HH modalities are used during training or testing. The main challenge of MLMM lies in dynamically and robustly handling and integrating any number of available modality information during training and testing while maintaining performance comparable to full-modal samples.
This review covers the latest advancements in MLMM and its applications in various fields such as information retrieval, remote sensing, and robotic vision. We provide a detailed categorization of MLMM methodologies, application scenarios, and related datasets. Our work expands existing reviews focused on specific fields (such as medical diagnosis【5,151,235】, sentiment analysis【179】, and multi-view clustering【17】). By providing a comprehensive overview of current research and identifying promising directions for future work, this review aims to contribute to the development of more robust and adaptive multimodal learning systems. These advancements are crucial for deploying intelligent systems in dynamic and unpredictable environments, ranging from harsh conditions in planetary exploration to everyday life.
The main contributions of this review are threefold:
-
A comprehensive review of MLMM applications across various fields, collecting a wealth of relevant datasets, highlighting the versatility of MLMM in addressing real-world challenges.
-
Proposing a novel and detailed classification system for MLMM methodologies, based on recovery strategies, integration phases, parameter-efficient methods, and attention mechanisms.
-
In-depth analysis of current MLMM methods, their challenges, and future research directions within the proposed classification framework.
2 Methodology
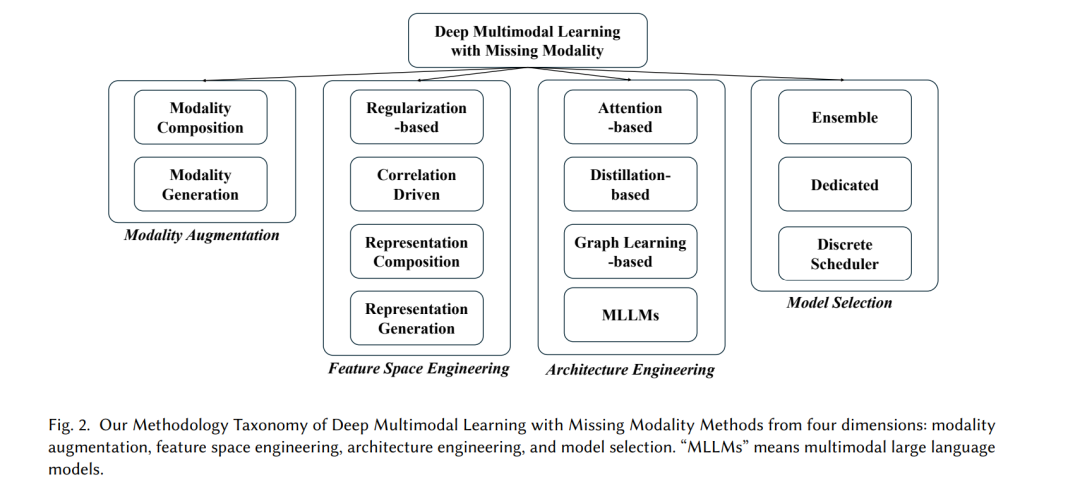
We classify and discuss existing deep Multimodal Learning with Missing Modalities (MLMM) methods based on a classification framework across four main dimensions: modality enhancement, feature space engineering, architecture engineering, and model selection.
2.1 Modality Enhancement
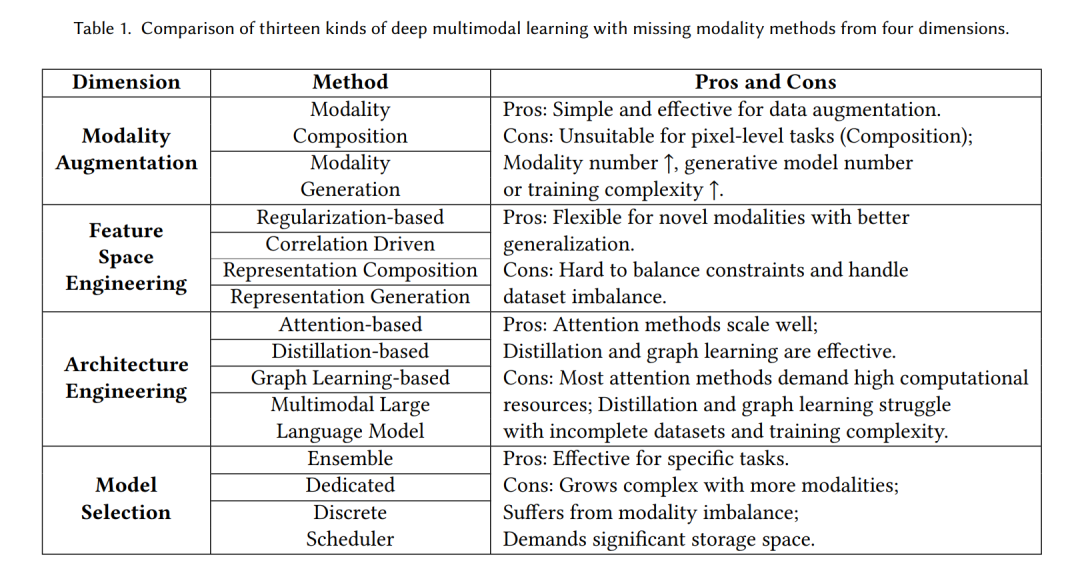
We categorize the modality enhancement methods addressing the missing modality problem into two classes, targeting the raw data at the modality level. The first class is modality composition methods, which use zero/random values, data copied directly from similar instances, or matching samples obtained through retrieval algorithms to combine with missing modality samples to form full-modal samples. The second class is modality generation methods, which use generative models (such as Autoencoders (AEs) [55], Generative Adversarial Networks (GANs) [42], or diffusion models [56]) to generate raw data for the missing modalities.
2.1.1 Modality Composition Methods
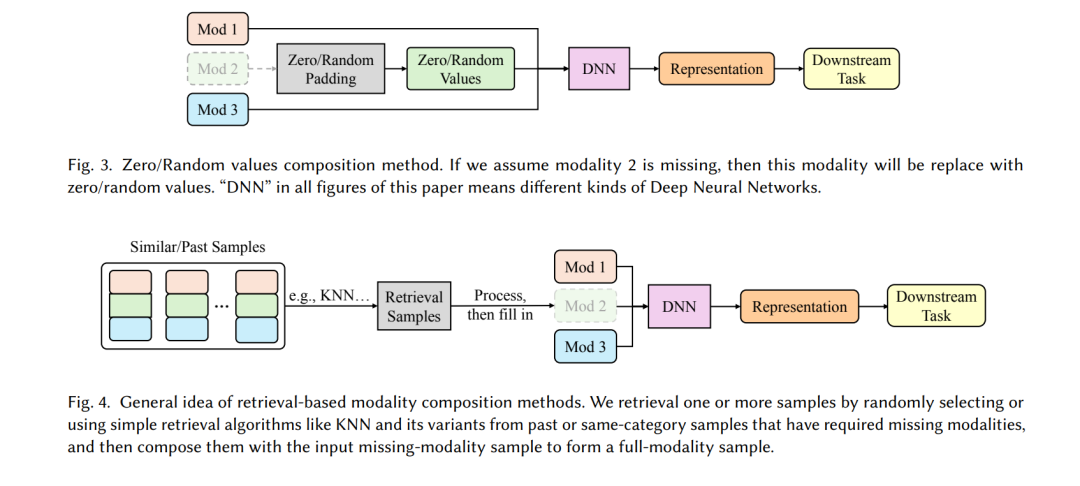
When there are few missing modality samples in a dataset, deleting these samples is a common preprocessing method in multimodal datasets. However, this approach reduces the size of the dataset and can lead to the disappearance of some rare samples when many samples in the dataset are missing modalities. Modality composition methods are widely used for their simplicity and effectiveness, and they can maintain the size of the dataset. One typical method is the zero/random value composition method, which replaces missing modality data with zero/random values, as shown in Figure 3. In recent studies [28, 102, 114, 163], these methods are often compared as baselines with proposed methods. For missing sequential data problems, such as missing frames in videos, similar frame-zero methods [135] have been proposed, which replace missing frames with zero frames and combine them with available frames. These methods are very common in typical multimodal learning training processes. Through these methods, multimodal models can balance and integrate information from different modalities during prediction, thereby avoiding excessive reliance on one or a few modalities, enhancing their robustness. However, when most samples in the dataset are missing modality samples, these methods struggle to generalize well. Another composition method is based on retrieval algorithms (Figure 3), which fills in missing modality data by copying/averaging original data from retrieved samples with the same modality and category. Some simple methods randomly select a sample with the same category and required modality and combine it with the input missing modality to form a full-modal sample for training. For example, researchers [204] proposed Modal-mixup, which randomly supplements missing modality samples to complete the training dataset. However, such methods cannot solve the missing modality problem during the testing phase. For missing frames in streaming data like videos, researchers have proposed using frame repetition methods [135], which utilize past frames to supplement missing frames. Some works [14, 41, 204] attempt to use K-nearest neighbors (KNN) or its variants to retrieve the best matching samples for combination. Experiments show that KNN-based methods perform better than random selection methods when dealing with missing modality problems during the testing phase. However, simple clustering methods often suffer from high computational complexity, sensitivity to imbalanced data, and high memory overhead. Moreover, retrieval-based modality composition methods are not suitable for pixel-level tasks (such as segmentation) and are only applicable to simpler tasks (such as classification), as they may lead to model confusion. Additionally, while all the aforementioned methods can complete missing modality datasets, they reduce the diversity of the dataset. This is particularly problematic for datasets with high modality missing rates (where most samples are missing modality samples), as it increases the risk of overfitting to certain classes of a few full-modal samples.
2.1.2 Modality Generation Methods
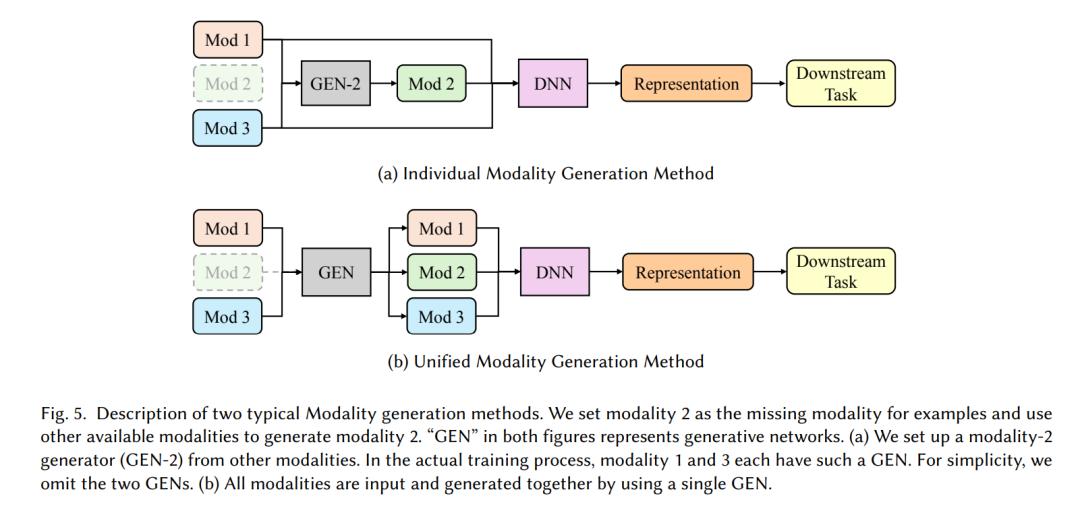
In missing data research, various matrix imputation methods [41] have been proposed, leveraging the latent correlations between matrix elements. However, in multimodal datasets, missing data often occurs in large chunks, making traditional methods inefficient for large-scale processing and high-dimensional computations. With the development of deep learning, generating missing modalities has become more efficient. Current methods for generating raw data for missing modalities can be categorized into unimodal generation methods and unified modal generation methods. Unimodal generation methods train separate generative models for each modality to handle any missing modality situation, as shown in Figure 5a. Early works utilized Gaussian processes [117] or Boltzmann machines [159] to generate missing modality data from available inputs. With the advancement of deep learning, methods such as AEs and U-Net [147] have been used to generate raw modal data. Li et al. [87] generated Positron Emission Tomography (PET) data from Magnetic Resonance Imaging (MRI) data using 3D-CNN. Chen et al. [24] generated two other modalities from MRI data through training a U-Net model to address the missing modality problem in MRI segmentation. Recent works [113] have used AEs as one of the baseline methods, completing datasets by training an AE for each modality. In domain adaptation, Zhang et al. [220] proposed a multimodal data generation module that generates each missing modality through domain adversarial learning, learning domain-invariant features. GANs have significantly improved the quality of image generation by using generators to create realistic data and allowing discriminators to distinguish it from real data. Researchers have begun to use GANs instead of AEs and U-Nets to generate missing modalities. For instance, GANs generate raw data for missing modalities based on the latent representations of existing modalities and have been applied in breast cancer prediction [3], while WGANs have been used in sentiment analysis [184]. In the field of remote sensing, Bischke et al. [8] used GANs to generate depth data, improving the segmentation performance of RGB models. GANs have also been used to generate RGB and depth images in robotic recognition [45]. Recent research [113] indicates that GANs outperform AEs in generating more realistic missing modalities and can yield better downstream task model performance. The recent introduction of diffusion models has further improved image generation quality. Wang et al. proposed the IMDer method [190], utilizing available modalities as conditions to assist diffusion models in generating missing modalities. Experiments show that diffusion models reduce semantic ambiguity between recovered and missing modalities and outperform previous methods in terms of generalization performance. However, training a separate generator for each modality is inefficient and fails to capture the latent correlations between modalities. Researchers have developed another generation method, the unified modal generation method, which trains a unified model that can generate all modalities simultaneously (Figure 5b). One representative model is Cascade AE [174], which captures the differences between missing modalities and existing modalities by stacking AEs to generate all missing modalities. Recent researchers, such as Zhang et al. [221], have attempted to integrate the features of existing modalities using attention mechanisms and max-pooling layers, allowing modality-specific decoders to generate each missing modality. Experiments show that this method is more effective than simply using max-pooling [19] to integrate features from multiple modalities to generate missing modalities. Although the aforementioned methods can alleviate performance degradation to some extent, training generators capable of producing high-quality, real-world distribution-like missing modalities remains challenging, especially when the training dataset contains few full-modal samples. Furthermore, modality generation models significantly increase storage requirements. As the number of modalities increases, the complexity of these generative models also increases, further complicating the training process and resource demands.
2.2 Feature Space Engineering
The following introduces methods for addressing missing modality problems at the feature space level. First, we introduce two constraint-based methods that enhance more discriminative and robust representation learning (Figure 6) by imposing specific constraints. One method improves the effectiveness and generalization ability of learned representations through regularization. Another method focuses on maximizing correlations using specific metrics to strengthen relationships between features. Next, representation composition methods can draw from the solutions discussed in section 2.1.1, operating at the feature level of modalities or using arithmetic operations to handle dynamic numbers of modalities. Finally, we introduce representation generation methods that can generate feature representations for missing modalities.
2.3 Architecture Engineering
Unlike the aforementioned methods that generate modalities or modality representations, some researchers adjust the model architecture to accommodate missing modalities. Based on their core contributions in handling missing modalities, we categorize them into four types: attention-based methods, distillation-based methods, graph learning-based methods, and multimodal large language models (MLLMs).
2.4 Model Selection
Model selection methods aim to use one or more selected models for downstream tasks while enhancing their robustness and performance. These methods can be divided into ensemble methods, specialized methods, and discrete scheduling methods. Ensemble methods combine the predictions of multiple selected models through voting, weighted averaging, etc., to improve the accuracy and stability of final decisions. Specialized methods assign dedicated individual models for different subtasks (such as varying missing modality situations), focusing on specific subtasks or sub-datasets. In discrete scheduling methods, users can use natural language instructions to allow large language models (LLMs) to autonomously select appropriate models based on modality types and downstream tasks.
3 Applications and Datasets
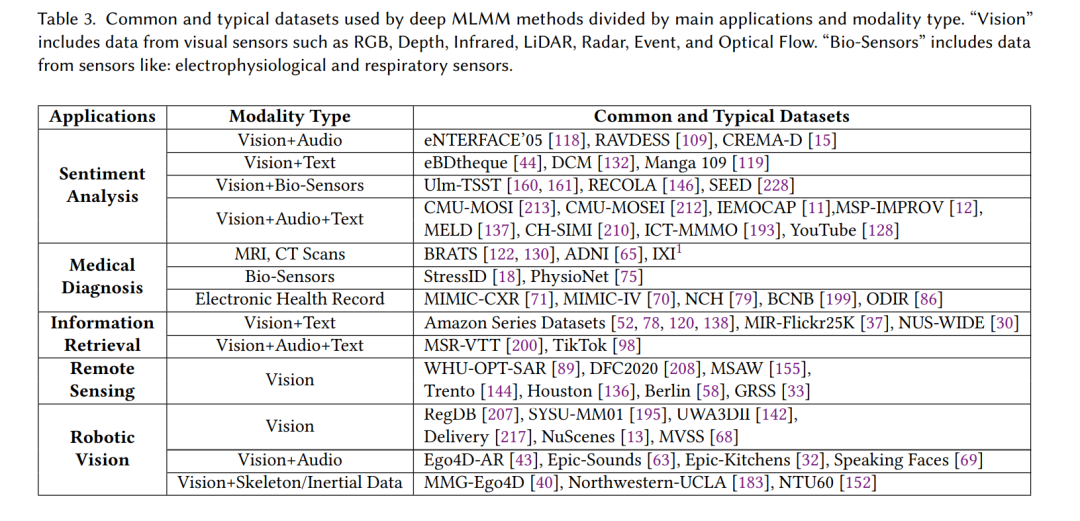
In the past decade, deep learning-based multimodal learning has experienced explosive growth, gaining widespread applications in academia and industry. Accompanying these applications is the emergence of various forms of multimodal datasets. However, the collection of such datasets often requires significant manpower and costs. In certain specific application directions, factors such as user privacy issues and sensor failures in data collection devices may lead to missing modalities within datasets. In severe cases, up to 90% of samples may have missing modality issues, making it difficult for traditional full-modal multimodal learning (MLFM) to achieve good performance during model training. This has given rise to the task of Multimodal Learning with Missing Modalities (MLMM). Since the factors leading to incomplete datasets often stem from different application directions, we introduce corresponding datasets based on these application directions: sentiment analysis, medical diagnosis, retrieval/description, remote sensing, robotic vision, etc. We also classify these datasets in Table 3 based on applications and data types.
Conclusion
In this review, we provide a comprehensive overview of deep multimodal learning with missing modalities for the first time. We briefly introduce the historical development of the missing modality problem and its importance in the real world. Subsequently, we detail the current advancements in the field from two perspectives: methodology, applications, and datasets. Finally, we discuss the existing challenges in this field and potential future directions. Despite the increasing number of researchers engaging in the study of missing modality issues, we also recognize some urgent problems that need to be addressed, such as unified testing benchmarks (like multimodal large language models) and broader application demands (like natural sciences). Through our comprehensive and detailed review, we hope to inspire more researchers to explore deep multimodal learning techniques for missing modalities, ultimately contributing to the development of robust and high-performance AI systems.
Invitation to Technical Exchange Group

△ Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction
(e.g., Xiaozhang-Harbin Institute of Technology-Dialogue Systems)
to apply to join technical exchange groups such as Natural Language Processing/PyTorch
About Us
MLNLP Community is a grassroots academic community jointly established by machine learning and natural language processing scholars from both domestic and international backgrounds. It has developed into a well-known machine learning and natural language processing community, aimed at promoting progress among the academic and industrial sectors of machine learning and natural language processing.
The community can provide an open platform for communication regarding the further education, employment, and research of relevant practitioners. We welcome everyone to follow and join us.