This article summarizes the main content from the TPAMI review literature, and the author adds the latest papers and analyses related to this field. Paper: Multimodal Machine Learning: A Survey and TaxonomyHumans interact with the world through various sensory organs, such as eyes, ears, and touch. Multimodal Machine Learning (MML) studies machine learning problems that involve data from different modalities. Common modalities include: vision, text, and sound. They often come from different sensors, and the way data is formed and its internal structure can vary greatly; for example, images exist in continuous space, while text is organized in discrete space based on human knowledge and grammatical rules. The heterogeneity of multimodal data poses challenges for learning the relationships and complementarities between these modalities.This article categorizes common multimodal research into five types, which will be introduced one by one:1. Representation. How to mine the complementarity or independence between modalities to represent multimodal data.2. Translation. Learning a mapping from one modality to another. For example: image captioning.3. Alignment. Aligning sub-elements of multimodal data. For example, the phrase grounding task: aligning multiple objects in an image with phrases (or words) in a sentence. Implicit alignment may also be learned during representation or translation learning.4. Fusion. Fusing data from two modalities for making predictions. For example: Visual Question Answering requires fusing images and questions to predict answers; Audio-visual speech recognition requires fusing sound and video information for recognizing spoken content.5. Co-learning. Knowledge transfer between modalities. Networks trained using auxiliary modalities can assist in the learning of the primary modality, especially when the data amount of that modality is small.
0. Applications
One of the early applications of multimodality is audio-visual speech recognition proposed in the 1950s. This research was influenced by the McGurk Effect, where if a person is shown a video of someone saying /ga-ga/, but the audio is replaced with /ba-ba/, the subject will perceive that they heard /da-da/. Visual and auditory inputs can influence each other, and this psychological finding inspired researchers to explore how to use visual cues to assist in speech recognition.Around 2000, the rise of the internet promoted the application of cross-modal retrieval. Early search engines allowed people to search for images and videos using text (keywords), and in recent years, reverse image and video searches have emerged. Subsequently, understanding human social behaviors based on multimodal data was proposed. By analyzing conference recordings (language and visual information), emotional recognition can be performed. After 2015, tasks that combine vision and language emerged in large numbers and gradually became a hot topic. A representative task is image captioning, which involves generating a sentence that describes the main content of an image. Of course, generation tasks such as text-to-image, video-to-text, and text-to-video have also been proposed. The author summarizes common multimodal tasks as follows (additional contributions are welcome):Cross-modal pre-training
Image/Video and Language Pre-training.
Cross-task Pre-training
Language-Audio
Text-to-Speech Synthesis: Given text, generate a corresponding audio.
Audio Captioning: Given an audio segment, generate a sentence summarizing and describing the main content. (Not speech recognition)
Vision-Audio
Audio-Visual Speech Recognition: Given a person’s video and audio, perform speech recognition.
Video Sound Separation: Given video and sound signals (containing multiple sound sources), perform sound source localization and separation.
Image Generation from Audio: Given sound, generate an associated image.
Speech-conditioned Face Generation: Given a sentence, generate a video of the speaker.
Audio-Driven 3D Facial Animation: Given a sentence and a 3D facial template, generate a 3D animation of the speaker’s face.
Vision-Language
Image/Video-Text Retrieval: Mutual retrieval between images/videos and text.
Image/Video Captioning: Given an image/video, generate text describing its main content.
Visual Question Answering: Given an image/video and a question, predict the answer.
Image/Video Generation from Text: Given text, generate the corresponding image or video.
Multimodal Machine Translation: Given text in one language and the corresponding image, translate it into another language.
Vision-and-Language Navigation: Given natural language guidance, navigate an agent to a specific target based on visual sensors.
Multimodal Dialog: Given an image, historical dialogue, and a question related to the image, predict the answer to that question.
Location-related tasks
Visual Grounding: Given an image and a piece of text, locate the object described by the text.
Temporal Language Localization: Given a video and a piece of text, locate the action described by the text (predict start and end times).
Video Summarization from Text Query: Given a query and a video, summarize the video based on the query’s content and predict key frames (or key segments) to create a short summary video.
Video Segmentation from Natural Language Query: Given a query and a video, segment the object indicated by the query.
Video-Language Inference: Given a video (including some subtitle information) and a text hypothesis, determine whether there is semantic entailment between the two (binary classification), i.e., whether the video’s content contains the semantics of the text.
Object Tracking from Natural Language Query: Given a video and some text, perform tracking.
Language-guided Image/Video Editing: Automatically edit images based on a sentence. Given a command (text), automatically perform image/video editing.
More modalities
Affect Computing: Using modalities such as voice, vision (facial expressions), text information, ECG, EEG, etc., for emotional recognition.
Medical Images: Different medical image modalities such as CT, MRI, PET.
RGB-D Modality: RGB images and depth maps.
1. Multimodal Representation
Representation learning is the foundation of multimodal tasks, and it contains some open questions, such as: how to combine heterogeneous data from different sources, how to handle varying noise levels across different modalities, and what to do when a certain modality is missing in test samples. Existing multimodal representation learning can be divided into two categories: Joint (single-tower structure) and Coordinated (dual-tower structure).
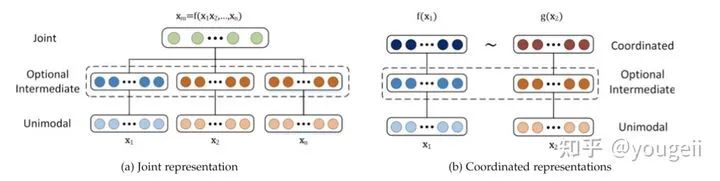
Joint Structure focuses on capturing the complementarity of multimodal data, fusing multiple input modalities x1, x2 to obtain multimodal representation xm = f(x1,……xn), and then using xm to complete a certain prediction task. The network optimization goal is the performance of a specific prediction task.
Coordinated Structure does not seek fusion but models the correlations between various modal data, mapping multiple (usually two) modalities into a collaborative space, represented as: f(x1) – g(x2), where ~ indicates a cooperative relationship. The optimization goal of the network is this cooperative relationship (usually similarity, i.e., minimizing cosine distance and other metrics).
Figure 1. Joint representation (single-tower) vs. Coordinated representation (dual-tower)During the testing phase, since the Coordinated structure retains the representation space of both modalities, it is suitable for applications that only have one modality as input, such as cross-modal retrieval, translation, grounding, and zero-shot learning. However, the xm learned from the Joint structure is only applicable when multimodal data is used as input, such as audio-visual speech recognition, VQA, emotional recognition, etc.Discussion: Compared to multimodal representation learning, single-modal representation learning has been widely and deeply researched. Before the emergence of Transformers, the best representation learning models suitable for different modalities varied; for example, CNNs were widely used in the CV field, while LSTMs dominated the NLP field. Many multimodal works still rely on using N heterogeneous networks to extract features from N modalities separately, and then training using Joint or Coordinated structures. However, this approach is rapidly changing as more and more works confirm that Transformers can achieve excellent performance across CV, NLP, and Speech fields, making it possible to unify multiple modalities and even multiple cross-modal tasks using only Transformers. Transformer-based multimodal pre-training models have surged since 2019, such as LXMERT[1], Oscar[2], and UNITER[3] belonging to the Joint structure, and CLIP[4], BriVL[5] belonging to the Coordinated structure.
2. Cross-modal Translation
The goal of cross-modal translation is to learn how to map the source modality to the target modality. For example: input an image, we want to generate a sentence describing it, or input a sentence, we generate an image that matches it. Mainstream methods can be divided into two categories:
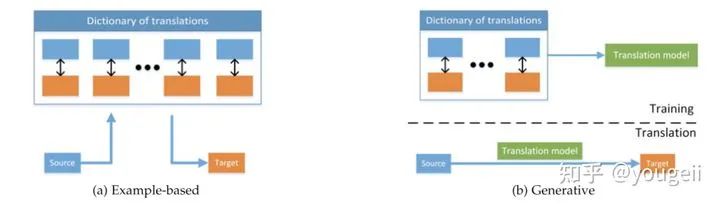
Example-based. The template method is characterized by using a dictionary for translation, which generally refers to data pairs in the training set {(x1,y1)},……{(xn,yn)}. Given a test sample x^, the template method directly retrieves the most matching translation result yi from the dictionary and uses it as the final output. The retrieval here can be divided into single-modal retrieval or cross-modal retrieval. Single-modal retrieval first finds the xi most similar to x^, and then obtains the corresponding yi. In contrast, multimodal retrieval directly retrieves the yi most similar to x^ from the {y1,……yn} set, and its performance is usually better than single-modal retrieval. To further improve the accuracy of the retrieval results, the top-K retrieval results {yi1, yi2……yik} can be selected, and then K results can be fused as the final output.
Generative Model. This method discards the dictionary and directly generates data for the target modality. It can be divided into three subcategories:
Grammar Template-based, which involves manually setting multiple grammatical templates for the target modality, inserting the model’s predictions into the template as the translation result. For example, in image description, the template is defined as who did what to whom in a place, with four slots to be replaced. Specific words for who, what, whom, and place can be obtained through different types of target/attribute/scenario detectors, thus completing the translation.
Encoder-Decoder. First, the source modality data is encoded into latent features , which the decoder uses to generate the target modality. For image captioning, the encoder (usually CNN + spatial pooling) encodes the image into one or more feature vectors, which are then input into an RNN to autoregressively generate a sequence of words.
Continuous Generation. This method targets tasks where both the source and target modalities are stream data that are strictly aligned in time. For example, text-to-speech synthesis differs from image description in that speech data and text data are strictly aligned in time. WaveNet[6] uses CNN parallel prediction + CTC loss to solve such problems. Of course, the encoder-decoder can theoretically also accomplish this task, but it requires addressing the data alignment issue.
Figure 2 Example-based method (left) vs. Generative model (right) for cross-modal translationDiscussion: The example-based method faces two issues: one is the need to maintain a large dictionary, and each translation requires global retrieval, making the model large and slow in inference (hashing can alleviate this issue). The second is that such methods are somewhat mechanical, merely copying (or slightly modifying) the data from the training set, and cannot generate accurate and novel translation results. Generative methods can produce more flexible, relevant, and higher-performing translation results. Among them, the grammar template-based approach is limited by the diversity of templates, resulting in limited diversity in generated sentences, and it is not end-to-end trained. Currently, encoder-decoder and continuous generation are mainstream solutions, typically based on deep networks and end-to-end training.3. The Evaluation Dilemma of Cross-modal Translation: Evaluating the performance of speech recognition models is straightforward because there is only one correct output. However, for most translation tasks (visual <–> text, text –> speech, etc.), the mapping between modalities is one-to-many, and outputs can have multiple correct results. For example, in image captioning, different people may use different phrases to describe the same image, making model evaluation often subjective. Human evaluation is the ideal assessment, but it is time-consuming and costly, requiring a diverse scoring population to avoid bias. Automated metrics are commonly used alternatives in the visual description field, including BLEU, Meteor, CIDEr, ROUGE, etc., but they have been shown to correlate weakly with human evaluations. Retrieval-based evaluation and weakening tasks (e.g., simplifying the one-to-many mapping in image captioning to a one-to-one mapping in VQA) are also means to address the evaluation dilemma.
3. Cross-modal Alignment
The goal of cross-modal alignment is to mine the relationships between sub-elements of multimodal data, such as the visual grounding task. Alignment is widely applied in multimodal tasks, with specific application methods including explicit alignment and implicit alignment.
Explicit Alignment. If the optimization goal of a model is to maximize the degree of alignment between sub-elements of multimodal data, it is called explicit alignment. This includes unsupervised and supervised methods. Unsupervised alignment: Given two modalities of data as input, the model aims to achieve alignment of sub-elements, but the training data lacks labeled “alignment results”; the model needs to learn both similarity metrics and alignment methods simultaneously. Supervised methods have labels available, allowing the model to learn similarity metrics. Visual grounding is a task of supervised alignment, while weakly-supervised visual grounding is a task of unsupervised alignment.
Implicit Alignment. If the model’s ultimate optimization goal is not the alignment task, and the alignment process is merely an intermediate (or implicit) step, it is called implicit alignment. Early methods based on probabilistic graphical models (such as HMM) were applied in text translation and phoneme recognition, aligning words or sound signals from the source language to the target language. However, they required manually constructing mappings between modalities. The most popular method is attention-based alignment, where we compute the attention weight matrix between the sub-elements of the two modalities, which can be seen as implicitly measuring the degree of association between cross-modal sub-elements. In image description, this attention is used to determine which areas of the image to focus on when generating a certain word. In visual question answering, attention weights are used to locate the areas of the image referenced by the question. Many deep learning-based cross-modal tasks can find traces of cross-modal attention.
Discussion: Alignment can serve as a standalone task or as an implicit feature enhancement for other tasks. Multimodal alignment can mine fine-grained interactions between sub-elements and is interpretable, making it widely applicable. However, multimodal alignment faces the following challenges: only a few datasets contain explicit alignment annotations; designing cross-modal metrics is difficult; there may be multiple alignments, and some elements may not be found in other modalities.
4. Multimodal Fusion
If the input data in the test scenario contains multiple modalities, one must face the challenge of multimodal feature fusion. Multimodal fusion is one of the original topics in multimodal machine learning.Model-independent fusion strategies:Early fusion: refers to concatenating features from multiple modalities at the shallow (or input) layer of the model. Late fusion: independently training multiple models and performing fusion at the prediction layer (the last layer). Mixed fusion: combining both early and late fusion, as well as conducting feature interaction in the middle layers of the model.Model-based fusion strategies:Multiple Kernel Learning is an extension of SVM. SVM uses kernel functions to map input features into high-dimensional space, making linearly inseparable problems separable in high-dimensional space. When handling multiple inputs, multiple kernels process features from multiple modalities, allowing each modality to find its optimal kernel function; Probabilistic graphical models utilize hidden Markov models or Bayesian networks to model the joint probability distribution (generative) or conditional probability (discriminative) of the data. Neural network-based fusion. Using LSTM, convolutional layers, attention layers, gating mechanisms, bilinear fusion, etc., to design complex interactions for sequential data or image data.Discussion: Multimodal fusion is dependent on the task and data; existing works often stack various fusion methods without a truly unified theoretical support. For the selection problem of fusion strategies caused by tasks/data, Neural Architecture Search is very suitable for efficiently and automatically searching. Of course, challenges still exist in multimodal fusion: the sequential information of different modalities may not be aligned; the associations between signals may only be supplementary (increasing robustness without increasing information) rather than complementary; different data may have different levels of noise.*Article Author: yougeii (HKU CV) *Source: WeChat Account 【Artificial Intelligence and Algorithm Learning】
 , which the decoder uses to generate the target modality. For image captioning, the encoder (usually CNN + spatial pooling) encodes the image into one or more feature vectors, which are then input into an RNN to autoregressively generate a sequence of words.
, which the decoder uses to generate the target modality. For image captioning, the encoder (usually CNN + spatial pooling) encodes the image into one or more feature vectors, which are then input into an RNN to autoregressively generate a sequence of words.