In daily life, humans utilize various senses such as vision and hearing to understand the surrounding environment. By integrating multiple perceptual modalities, a holistic understanding of events is formed. To enable machines to better mimic human cognitive abilities, multimodal cognitive computing simulates human “synaesthesia”, exploring efficient perception and comprehensive understanding methods for multimodal inputs such as images, videos, text, and speech. This area is an important research topic in artificial intelligence and is also one of the keys to achieving “general artificial intelligence.” In recent years, with the massive explosion of multimodal spatiotemporal data and the rapid enhancement of computational capabilities, scholars both domestically and internationally have proposed numerous methods to meet the increasingly diverse demands. However, current multimodal cognitive computing is still limited to the imitation of human apparent abilities and lacks theoretical support at the cognitive level. This article establishes an information transmission model of the cognitive process from the perspective of information theory, proposing the viewpoint that multimodal cognitive computing can enhance the machine’s information extraction capabilities, theoretically unifying various tasks of multimodal cognitive computing. Furthermore, based on the cognitive patterns of machines regarding multimodal information, this paper systematically analyzes and summarizes existing methods from three aspects: multimodal association, cross-modal generation, and multimodal collaboration, analyzing key issues and solutions involved. Finally, in light of the current characteristics of artificial intelligence development, this paper emphasizes the difficulties and challenges faced in the field of multimodal cognitive computing and provides an in-depth analysis and outlook on future development trends.
https://www.sciengine.com/SSI/doi/10.1360/SSI-2022-0226
1. Introduction
Enabling machines to perceive their surroundings intelligently like humans and make decisions is one of the goals of artificial intelligence. There is a significant difference between how humans and machines process information. To build intelligent systems that simulate human cognitive patterns, researchers at Ulster University in the UK introduced the concept of “Cognitive Computing” into the information field in 2003, focusing on the mechanisms and connections between cognitive science and traditional audio-visual, image, and text processing, and established corresponding teaching courses. In the early 2000s, X. Li founded the IEEE-SMC Cognitive Computing Technical Committee, which aimed to: “Cognitive Computing breaks the traditional boundary between neuroscience and computer science, and paves the way for machines that will have reasoning abilities analogous to a human brain. It’s an interdisciplinary research and application field, and uses methods from psychology, biology, signal processing, physics, information theory, mathematics, and statistics. The development of Cognitive Computing will cross-fertilize these other research areas with which it interacts. There are many open problems to be addressed and to be defined. This technical committee tackles these problems in both academia and industry, and focuses on new foundations/technologies that are intrinsic to Cognitive Computing.” Over the past few decades, cognitive computing has gradually attracted attention from scholars in various fields.
In real life, humans perceive the world through various senses such as vision, hearing, and touch, with different sensory stimuli merging to form a unified multi-sensory experience. This multi-sensory collaboration is referred to as “multimodal” for machines. Research in cognitive neuroscience indicates that a type of sensory stimulus may act on other sensory channels, a phenomenon known as “synaesthesia.” In 2008, Li et al. first introduced synaesthesia into the information field in the paper “Visual Music and Musical Vision,” and attempted to explore the theory and application of multimodal cognitive computing from the perspective of information measurement. With the deepening influence of the third wave of artificial intelligence development, multimodal cognitive computing has encountered new development opportunities, becoming a research topic of common concern in significant fields such as aerospace, intelligent manufacturing, and healthcare, which is of great significance for promoting the strategic development of artificial intelligence in our country. Domestically, corresponding research and exploration also have a long history and accumulation, with many top research teams. In 2008, the National Natural Science Foundation of China established a major research program on “Cognitive Computing of Audiovisual Information,” which has achieved fruitful results since its implementation. In 2017, the State Council issued the “New Generation Artificial Intelligence Development Plan,” clearly proposing to “establish new models of large-scale brain-like intelligent computing and brain-inspired cognitive computing models, and study cognitive computing theories and methods centered on natural language understanding and image graphics.” Currently, research on multimodal cognitive computing has transformed from being academically driven to being demand-driven. Supported by vast multimodal data of images, videos, text, speech, and powerful computing capabilities, major well-known companies and research institutions worldwide have joined this research. However, behind the booming development, the theoretical mechanisms of multimodal cognitive computing remain unclear. Cognitive neuroscientists have proposed numerous theories and hypotheses to characterize the cognitive processes of humans regarding multiple perceptual modalities. In the field of information, multimodal cognitive computing remains in the observational and imitative stage of human cognition, lacking mechanistic explanations and a unified theoretical framework for learning.
This paper attempts to clarify the theoretical significance of multimodal cognitive computing from the perspective of cognition. Cognition is the process by which humans extract and process information from the real world. External information is transmitted to the brain through various perceptual channels such as vision, hearing, smell, taste, and touch, stimulating the cerebral cortex. Relevant research in neuroscience indicates that the combined effects of multiple sensory stimuli can produce an effect where the whole is greater than the sum of its parts. For example, when watching a film or a drama, the simultaneous stimulation of visuals and sound provides a profound and comprehensive experience for humans and also helps them understand the film content more accurately. How does this phenomenon occur? Cognitive science research indicates that when humans receive external stimuli, they selectively focus on a portion of them. This “attention mechanism,” as a crucial component of human cognitive ability, effectively enhances the efficiency of information processing. When the visual image and sound of a film are synchronized, human attention is not distracted but rather focused on the events occurring in the film, allowing both visual and auditory senses to be engaged simultaneously. Based on the above observations, this paper proposes the following hypothesis: when the same event triggers simultaneous stimulation of multiple senses, different sensory channels share attention, allowing humans to perceive more information. From the perspective of cognitive computing, this paper utilizes information theory to model the above hypothesis. The founder of information theory, C. Shannon, introduced the concept of information entropy in his 1948 paper “A Mathematical Theory of Communication,” which represents the uncertainty level of a random variable, providing a solution for measuring the amount of information. According to the definition of information entropy, assuming the probability distribution of the event space X is known, the probability of event x is p(x), and the amount of information it brings is
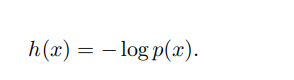
The smaller the probability of an event, the greater the amount of information it provides when it occurs. For example, a red sky has a lower probability of occurrence than a blue sky, and generally, its amount of information is relatively larger. At the same time, in different cognitive tasks, the occurrence probabilities of events vary, leading to differences in the amount of information provided. For a given cognitive task T, the amount of information provided by event x is
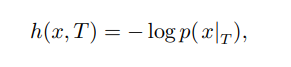

From formula (4), it can be seen that when attention is focused on spatiotemporal events dense in modalities, the amount of information obtained reaches its maximum. Therefore, individuals can utilize multimodal spatiotemporal data to acquire more information.
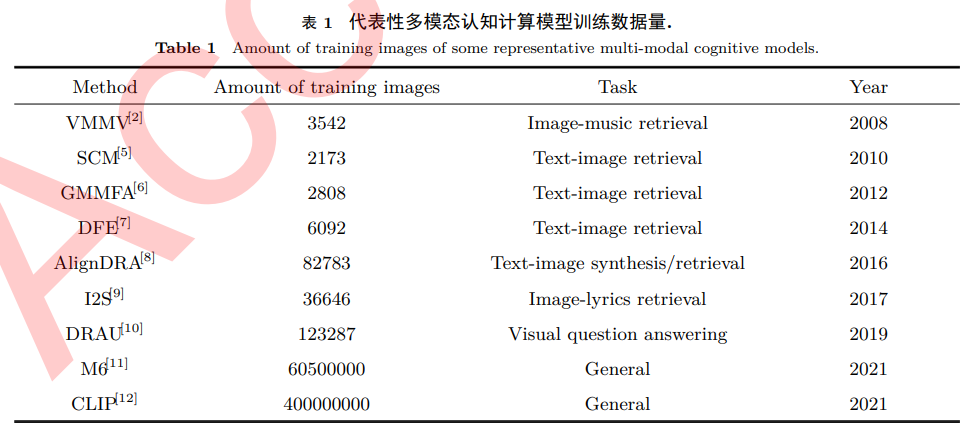
In recent years, the widespread application of attention mechanisms in fields such as computer vision and natural language processing has proven that focusing on specific events helps enhance a machine’s learning capabilities, while the success of multimodal learning also confirms the advantages of joint multimodal spatiotemporal data. Therefore, the model in formula (4) can attempt to explain the intrinsic mechanisms of multimodal cognitive computing, characterizing the process of machines extracting information from data. However, does obtaining more information bring machines closer to human cognitive levels? Currently, general multimodal learning models such as M6 and CLIP have achieved near-human effectiveness on specific tasks. As shown in Table 1, these models often require tens of millions of training data, and there remains a significant gap between them and human cognitive abilities. Defining the information provision capability of unit data as “Information Capacity,” the corresponding cognitive ability of machines is the ability to obtain the maximum amount of information from unit data:
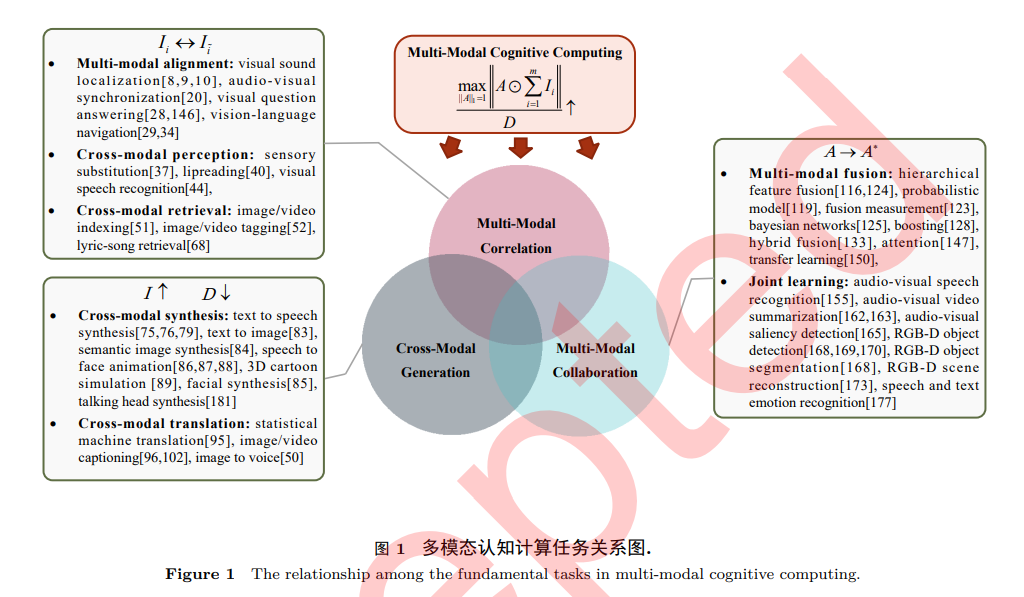
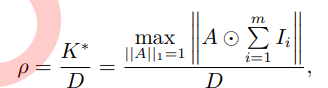
Where D is the amount of data in the event space X. Therefore, the cognitive ability of machines can be enhanced from three aspects:: (1) Optimize A, enabling machines to obtain greater amounts of information; (2) Increase I, utilizing data with larger amounts of information for a given task; (3) Reduce D, minimizing the amount of data. Maximizing the amount of information obtained using as little data as possible represents a stronger cognitive ability. Therefore, this paper focuses on the above three common key issues to enhance machine cognitive ability, systematically sorting through the three fundamental tasks of multimodal association, cross-modal generation, and multimodal collaboration, as shown in Figure 1. Specifically: (1) Multimodal association is the foundation for improving ρ. It achieves multimodal alignment, perception, and retrieval recognition by exploring the inherent consistency of different sub-modal events at spatial, event, and semantic levels, mapping sub-modal events to a unified information space. Through multimodal association, the corresponding relationships between different modalities can be mined to further enhance cognitive abilities. (2) Cross-modal generation enhances ρ by increasing I and reducing D. It transmits information using modalities as carriers, synthesizing and transforming known information across modalities by utilizing the differences among different modalities. In cross-modal synthesis, more intuitive and easily understandable modalities enrich and supplement information, increasing I. In cross-modal transformation, a more concise expression is sought, reducing D while retaining information, thereby enhancing information acquisition capabilities. (3) Multimodal collaboration maximizes information quantity K by optimizing A. It investigates effective and reasonable joint mechanisms between modalities by utilizing the associations and complementarities between different modalities. By learning the consistent representations of multimodal data represented by images, videos, texts, and speech, it achieves the fusion and enhancement of information to improve performance on task T.
In contrast to human cognition, cognitive enhancement is inseparable from associations, reasoning, induction, and deduction concerning the real world, corresponding to the associations, generation, and collaboration in multimodal cognitive computing. This paper unifies human and machine cognitive learning as a process of improving information utilization efficiency. With the deepening influence of artificial intelligence, research on multimodal cognitive computing is rapidly expanding in depth and breadth. As the three main lines of multimodal cognitive computing, multimodal association, cross-modal generation, and multimodal collaboration are effective ways to enhance machine cognitive abilities, they have become hot research topics closely watched by researchers both domestically and internationally. This paper conducts a detailed survey and introduction of related work, systematically sorting out the historical evolution and current development status of multimodal association, cross-modal generation, and multimodal collaboration, discussing the opportunities and challenges faced in the field of multimodal cognitive computing, and reflecting on and prospecting its future development directions and paths.
The organization framework of this paper is as follows:: Section 2 introduces the current development status of multimodal association tasks, divided into three parts: multimodal alignment, multimodal perception, and multimodal retrieval, along with analysis and discussion; Section 3 introduces methods for cross-modal synthesis and cross-modal transformation in cross-modal generation tasks, along with analysis and discussion; Section 4 introduces multimodal collaboration tasks from the aspects of modality fusion and joint learning, along with analysis and discussion; Section 5 discusses the challenges faced by multimodal learning and future development trends; Section 6 presents ideas around open issues in multimodal cognitive computing; Section 7 summarizes the entire paper.
2 Multimodal Association
Multimodal perception and learning are typically achieved by describing or delineating the same entity or spatiotemporal event across different modal spaces, thereby obtaining data from different modalities. For example, using an RGB-D camera to capture the same scene results in RGB color image descriptions and depth distance descriptions; using a camera to collect speech from a speaker obtains the speech content’s voice information and corresponding lip movement information. These multimodal descriptions can more comprehensively characterize the multidimensional information of the same objective entity, thereby enhancing the model’s understanding and cognitive capabilities. Since different modalities can acquire varying amounts of information when representing the same objective entity, for instance, in the aforementioned representation of speech information, the amount of information obtained from voice is generally higher than that from visual lip movement. Although the information obtained from different modalities differs, because they describe the same objective entity, the information obtained has a strong correlation. For example, different phonemes produce different visual lip movements. Therefore, to effectively characterize the associations between various modal information, it is necessary to analyze and align the amounts of information obtained from different modalities effectively, thus laying the foundation for subsequent multimodal perception and retrieval. That is, based on the joint perception summation of information obtained from different modalities, high-quality information association and alignment must be performed to lay the groundwork for subsequent multimodal perception and retrieval. For modalities i and ˜i, based on the amounts of information obtained from different modalities, the association is achieved through a specific function f(·), namely
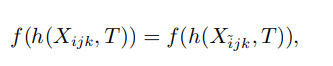
By optimizing the association objective f(·) between the amounts of information obtained from different modalities, the relationships of association between different modalities can be acquired. This section elucidates the relevant work on multimodal association from three aspects: multimodal alignment, multimodal association, and multimodal retrieval. Among them, multimodal alignment is a foundational requirement, such as the semantic alignment of image region content and text vocabulary, and the temporal alignment between visual lip movement and speech phonemes. Based on alignment, maximizing the association between modalities meets the practical task requirements of multimodal perception and retrieval.
3. Cross-Modal Generation
Under normal circumstances, human multi-channel perception and central thinking systems endow them with a natural ability to reason and generate across channels. For instance, when reading a novel, corresponding images naturally arise in the mind. Referencing this phenomenon, this paper defines the goal of cross-modal generation tasks in multimodal cognitive computing as endowing machines with the ability to generate unknown modal entities. Traditional machine generation tasks are typically conducted in a single and fixed modality, such as generating subsequent plot points from a known dialogue or synthesizing a new image from an existing one. In contrast, cross-modal generation involves the generation process of entities utilizing information from various different modalities, leveraging the consistency and complementarity between multimodal information to generate new things in a new modality. From the perspective of information theory, cross-modal generation tasks prompt the flow of information between different modalities, enhancing the individual’s perceivable information within a given spatiotemporal context. Assuming that an entity is known with m modal information {X1, X2, · · · , Xm}, the cross-modal generation task can be summarized as

Where Xp is the missing modal entity to be restored. With the rapid development of technologies such as natural language processing, intelligent speech, and computer vision, cross-modal generation tasks based on text, speech, images, and videos have emerged in abundance, such as generating images from sentences and producing audio from scenes. The different modalities present varying capabilities for information transmission due to their distinct ways of expressing information. In most people’s cognitive worlds, the amount of information that can be conveyed by text, audio, images, and videos gradually increases under specific spatiotemporal and target conditions. Simply put, the sound of the same entity conveys more rich information than text, while images are more intuitive than sound. In most cases, broadcasts are more easily accepted by the majority than written text; when seeing a photo of a dog, one understands more than when hearing the dog’s bark; dynamic videos provide a deeper impression on humans. However, simultaneously, describing the same entity using modalities with rich information also occupies larger storage space, leading to burdens in information processing efficiency. Considering these two factors, this paper summarizes the essence of cross-modal generation tasks as an issue of enhancing machine cognitive abilities within multimodal information channels. Furthermore, this task can be categorized into two approaches: increasing information amount I and reducing data amount D, namely cross-modal synthesis and cross-modal transformation. The following sections detail these two types of cross-modal generation technologies.
4 Multimodal Collaboration
Induction and deduction are important functions of human cognition. Humans can easily integrate various multimodal perceptions such as sight, hearing, smell, taste, and touch, and perform joint deductions to make different decisions and actions. In multimodal cognitive computing, multimodal collaboration refers to coordinating two or more modal data to work together to complete multimodal tasks. To achieve more complex tasks and enhance precision and generalization capabilities, multimodal information must be integrated to achieve complementary information. Echoing the previous discussion, this essentially optimizes attention A:
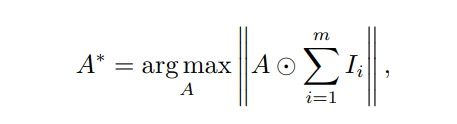
Furthermore, the fused multimodal information must undergo joint learning to achieve the surpassing of single-modality tasks by multimodal information, namely
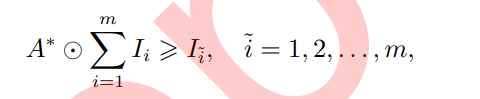
Increasing the amount of information can enhance the performance of single-modality tasks and also provide possibilities for developing innovative multimodal tasks. From a biological perspective, multimodal collaboration is similar to how humans respond by integrating various perceptions. In recent years, with the advancements in sensor technology, computer hardware, and deep learning techniques, the acquisition, computation, and application of multimodal data have changed rapidly. Simultaneously, significant progress has been made in multimodal collaboration research based on modalities such as vision, sound, and text. This section summarizes the modality fusion and joint learning methods in multimodal collaboration. Among them, modality fusion is divided into early, late, and mixed fusion strategies, as shown in Figure 6. Joint learning, based on its purpose, can be divided into enhancing single-modality task performance and addressing new challenging problems. The following sections will introduce each of these.
5 Challenges and Future Trends in Multimodal Cognitive Computing
In recent years, deep learning technologies have made significant progress in image processing, natural language processing, and other fields, driving multimodal cognitive computing to develop in depth in both theoretical research and engineering tasks. Against the backdrop of rapid data form iterations and diversified application demands, multimodal cognitive computing also faces new problems and challenges. From a macro perspective, all the aforementioned tasks revolve around the data (D), information amount (I), fusion mechanisms (A), and tasks (T) in formula (5) to enhance machine cognitive abilities (ρ). This section will analyze the current challenges of multimodal cognitive computing from the above four aspects and prospect future development trends.
6 Discussion of Open Issues
6.1 How Can Human Cognition and Artificial Intelligence Combine?
Currently, the development of multimodal cognitive computing is thriving. Most research focuses on the field of artificial intelligence, dedicated to analyzing multimodal data such as vision, hearing, smell, taste, and touch to accomplish various complex tasks. Over the past few decades, human “synaesthesia,” “perceptual reconfiguration,” and “multi-channel perception” have provided guiding principles for the association, generation, and fusion of multimodal data, initiating the research on multimodal cognitive computing. However, there are still many unknowns and uncertainties surrounding human cognition. How is human cognition formed? What are the underlying mechanisms? It is not fully understood at present. Lacking further cognitive guidance, multimodal cognitive computing is prone to fall into the trap of data fitting. The author of this paper has previously initiated related online (2020) and offline seminars (2022) as a co-organizer at the Visual and Learning Young Scholars Symposium (VALSE), focusing on these issues, emphasizing the exploration of the differences and connections between current multimodal research and human multi-sensory cognition. In the future, how will multimodal cognitive computing advance towards cognition? Humans possess highly reliable and robustly generalized multimodal perception capabilities, especially when certain sensory abilities are absent, they can compensate for the missing abilities through other senses. Cognitive neuroscientists believe that the potential physiological basis for this phenomenon may be a high-level semantic self-organizing associative network among different senses in information encoding, which is modality-independent but can directly relate to different modalities, thus achieving efficient multimodal perception. For multimodal cognitive computing, constructing an effective architecture is a key step to enhance multimodal perception capabilities. This paper proposes the construction of a modality interaction network centered on “meta-modalities,” learning intrinsic properties that are independent of specific modality types to maximize the association and alignment of different modal semantic contents. Meta-modalities point to a compact low-dimensional space that can project into different modality spaces, thus possessing more generalized representation capabilities.
6.2 What Do Multimodal Data Bring?
In recent years, artificial intelligence combined with multimodal data has indeed achieved better performance. This is evident, as under reasonable model optimization methods, increased input information often yields better results. However, upon deeper reflection, what additional information do multimodal data bring, and how do they enhance performance? In fact, while multimodal data bring information, they also introduce a significant amount of noise and redundancy, leading to a decrease in information capacity and increasing the learning pressure on the model. This can result in situations where multimodal data perform worse than single modalities. This paper attempts to explain the above issues from the perspective of information. Multimodal information possesses both similarity and complementarity. The similarity portion represents the intersection of information from various modalities, known as mutual information, which describes different aspects of the same scene from different modalities. The similarity portion provides a more comprehensive description of the scene, achieving the effect of “hearing all sides makes one wise,” enhancing the robustness of the model’s scene understanding. The complementarity portion represents the union of information from various modalities, referred to as joint entropy in information theory, which represents the differences between different modalities, including noise. The complementarity portion expands the perceptual capabilities of any single modality to achieve better scene understanding performance, reaching the ability to simulate human synaesthesia.
6.3 What Real Scenarios Does Multimodal Cognitive Computing Face?
Current research on multimodal cognitive computing mainly focuses on image and video data, emphasizing the analysis of auditory and visual modalities. This is primarily due to the rapid growth of image and video data resulting from the widespread use of smartphones and the rapid development of social networks, making data transmission increasingly convenient. However, the multimodal perception of the real world faces more complex situations, exemplified by robotics and vicinage earth security. Robotics will be a typical application of multimodal cognitive computing. The goal of robots is to perceive and think like humans. Suppose a robot is to perform multimodal perception in a real environment. In that case, it must first integrate visual, auditory, olfactory, gustatory, and tactile sensors, but current research on front-end sensors is noticeably insufficient. Next, perception must occur in three-dimensional space rather than just in video frames, requiring three-dimensional perception capabilities. Finally, perception occurs in dynamic environments, involving interactions between machines and the environment, various modalities and the environment, and among different modalities, which is also a key consideration for future research. Vicinage earth security also provides a broad application prospect for multimodal cognitive computing. With the gradual release of low-altitude airspace resources and the comprehensive enhancement of marine development capabilities, artificial intelligence is beginning to play a role in encompassing low-altitude, ground, and underwater vicinage spaces, involving various security issues such as search and rescue and inspection. For instance, in intelligent search and rescue, the collaboration and interaction between drones and ground unmanned devices require processing large amounts of data generated by different sensors, making multimodal cognitive computing one of the key core technologies to solve such tasks, which needs to be closely integrated with cross-domain intelligent interaction and water-light optics research topics. At the same time, the demand for real-time and efficiency in vicinage earth security presents new challenges for multimodal cognitive computing. In the future, vicinage earth security will become an important landing scenario for multimodal cognitive computing, transitioning from theory to application.
7 Conclusion
Research hotspots in the field of information often iterate in the process of acquisition—processing—feedback, especially in the first two aspects. Currently, the rapid development of processing methods such as deep learning suggests that the next hotspot may be data acquisition, which will usher multimodal computing into a new stage of development. This paper serves as a preliminary exploration, reviewing the development history of multimodal cognitive computing from three aspects: theory, methods, and trends. First, constructing an information transmission model characterizes the process of machines extracting information from event spaces, discussing the theoretical significance of multimodal cognitive computing. Then, it elucidates the theoretical connections among the three main tasks of multimodal association, cross-modal generation, and multimodal collaboration, unifying various tasks. Through analyzing and comparing existing methods, it comprehensively presents the current development status and key technologies of multimodal cognitive computing. Furthermore, in light of the current background of artificial intelligence development, it discusses the challenges faced by multimodal cognitive computing from aspects such as information measurement, fusion mechanisms, learning tasks, and data acquisition, and explores future research directions worth investigating. Finally, it presents some speculations on the open issues in multimodal cognitive computing. In reality, the modal information that humans can perceive is limited. Humans can only see a small portion of the visible light spectrum, from 400-700nm; they can only hear sound waves in the range of 20-20000Hz, which is also a small part of sound waves. Fortunately, with the aid of various advanced optoelectronic devices, we perceive more information beyond visible light and audible sound waves. In the future, as our perceptual capabilities further enhance, relying on human cognition to expand the boundaries of physical perception and achieve the unification of information domains and cognitive domains is an inevitable trend. It is hoped that this paper can provide references and inspiration for enhancing the perceptual capabilities of intelligent optoelectronic devices and promoting theoretical research in multimodal cognitive computing.
More Exciting:
Yan Shi│Thoughts and Suggestions on the “Difficulties” of Young Teachers in Universities
【Table of Contents】 “Computer Education” 2022 Issue 8
【Table of Contents】 “Computer Education” 2022 Issue 7
【Table of Contents】 “Computer Education” 2022 Issue 6
【Table of Contents】 “Computer Education” 2022 Issue 5
【Editorial Board Message】 Professor Li Xiaoming from Peking University: Reflections from the “Classroom Teaching Improvement Year”…
Professor Chen Daoxu from Nanjing University: Teaching students to ask questions and teaching students to answer questions, which is more important?
【Yan Shi Series】: Trends in Computer Science Development and Their Impact on Computer Education
Professor Li Xiaoming from Peking University: From Interesting Mathematics to Interesting Algorithms to Interesting Programming—A Path for Non-Majors to Experience Computational Thinking?
Reflections on Several Issues in Building a First-Class Computer Science Discipline
New Engineering and Big Data Major Construction
Lessons from Other Countries Can Be Applied to Our Own—Compilation of Research Articles on Computer Education