Skip to content
With the rapid evolution of generative artificial intelligence, multimodal large models are increasingly demonstrating their advantages in multimodal content understanding and generation. The multimodal large model (hereinafter referred to as “large model”) refers to artificial intelligence models capable of processing and understanding various modal data inputs such as text, images, audio, and video. Artificial intelligence models represented by GPT-4 belong to multimodal large models. Large models typically have extremely large-scale parameters and support reasoning and decision-making through prompt engineering and fine-tuning, showing excellent performance in multiple tasks such as natural language processing and audio-visual analysis. To further unleash the application potential of large models, researchers in the field of artificial intelligence have begun to attempt to construct intelligent agents based on large models. Intelligent agents, also known as autonomous agents, refer to adaptive systems that can perceive their environment and react to it to achieve their own goals. Since the 20th century, the design and implementation of intelligent agents have become one of the main objectives of research in the field of artificial intelligence. However, this research has long been limited by the intelligence level of core models. The emergence of large models provides a feasible technical path for constructing and realizing intelligent agents, and the interaction ability of agents with the external environment can also facilitate the adaptation of large models to downstream tasks. Therefore, the construction of intelligent agents based on large models is increasingly valued in the field of artificial intelligence and various vertical fields, but there is a lack of systematic design and comprehensive discussion in the field of education.
In the field of education, research on intelligent agents is still in its infancy. Early studies focused on constructing intelligent agents aimed at optimizing knowledge sharing and organizational management models, and some studies attempted to design educational intelligent agents that can interact with learners to achieve student-centered personalized online learning. In recent years, researchers have conducted studies on intelligent agents from perspectives such as the mechanisms of cognitive learning and the design of social cues, emphasizing the high-level significance processing and interactive innovation of learning subjects. As generative artificial intelligence technologies such as large models mature, researchers are attempting to construct general intelligent agents based on large language models (LLMs) to utilize them as user interaction assistants for mathematical formula formatting. Additionally, researchers have attempted to use multiple general intelligent agents to simulate classroom interactions between teachers and students, and experimental results indicate a high similarity to real classroom environments in dimensions such as teaching methods, curricula, and student performance.
Currently, most research in the field of education remains at the stage of attempting educational applications of general intelligent agents, lacking clear definitions and systematic architecture design. Therefore, this study proposes the concept of “teaching intelligent agents,” aiming to fully utilize the autonomous adaptation capabilities of generative artificial intelligence in environmental perception, reasoning and planning, learning improvement, and action decision-making, to provide intelligent services for teaching and learning for various stakeholders in multiple educational scenarios, including classroom teaching, after-school tutoring, teacher training, and home-school cooperation. This study will conduct research on the design and implementation paths of teaching intelligent agents based on the latest technological advances in the field of generative artificial intelligence, combined with the actual needs of the current education sector.
2. Intelligent Agents Based on Large Models
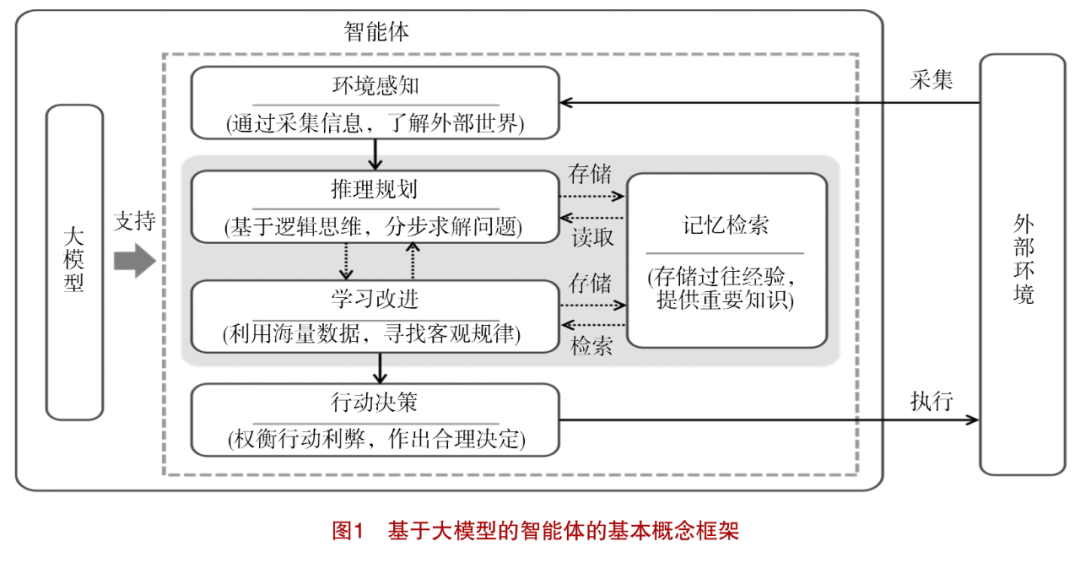
In the field of artificial intelligence, intelligent agents need to perceive their external environment and take actions to influence it. Typically, the perception and action between intelligent agents and the external environment continuously cycle, forming close interactions to complete specific task objectives. Figure 1 shows the basic framework of intelligent agents based on large models, where the large model serves as the foundational support and core of the agent. For a given task, the agent first collects information through its environmental perception capabilities to understand the dynamically changing external environment. Subsequently, the agent can solve specific problems in the given task step by step based on logical reasoning. During this process, a memory retrieval mechanism supports the storage and retrieval of past experiences, helping to improve the quality of reasoning and planning. At the same time, the agent can also utilize vast amounts of data to discover objective laws for learning improvements, thereby enhancing its own performance and storing it in memory. Based on this, the agent weighs the pros and cons of actions in reasoning and planning, makes reasonable decisions, and selects execution tools, transforming decisions into actual effects and impacts on the external environment to achieve task objectives. Compared with traditional intelligent agents in the field of artificial intelligence, intelligent agents based on large models possess several core capabilities.
 1. Multimodal Perception and Generation
Multimodal perception and generation integrate various data channels such as vision, speech, and text to achieve external information acquisition in a standalone or combined manner, thereby endowing intelligent agents with the ability to understand and analyze their surrounding environment. Relying on the understanding and generation capabilities of vision and language, agents can perform various image-text perception and generation tasks, such as Visual Question Answering (VQA) and Text-to-Image Generation. For example, the visual question-answering task requires the agent to answer questions related to scene understanding, such as “counting,” “attribute recognition,” and “object detection” based on image information. Building on this, the external knowledge-based visual question-answering task requires the agent to answer questions that cannot be understood solely through image information, encouraging it to generate answers by retrieving from external knowledge bases combined with image understanding. Currently, the multimodal perception and generation capabilities of agents have expanded into the video domain, supporting the interpretation and construction of continuous image frames to accurately answer questions related to video content or generate logically coherent high-quality videos. Furthermore, for embodied operational entities such as physical robots or virtual environment characters, multimodal perception can support real-time information updates for environmental interactions, assisting agents in completing complex tasks such as task planning, path planning, reasoning, and decision-making.
2. Retrieval-Augmented Generation
To mitigate issues such as the “hallucination” of large models that generates information contrary to facts and the untimely updating of data, retrieval-augmented generation (RAG) technology has begun to be widely adopted. Retrieval-augmented generation technology can provide large models with reliable external knowledge related to the problems to be solved based on knowledge base retrievers. This technology mainly includes three basic steps: index establishment, question retrieval, and content generation. The index establishment step requires constructing a knowledge base based on specified task information, which can cover various types of knowledge resources, including documents, web pages, knowledge graphs, etc., and utilizes methods such as word embeddings of language models to extract the semantic features of the resources, which are then stored in the knowledge base online or offline. The question retrieval step takes the user’s question content as a retrieval request, extracts its textual semantic features, and retrieves matching data content from the knowledge base as auxiliary information for the question. In the content generation step, the large model generates answers to the question based on the user’s inquiry information and the retrieved auxiliary information through methods such as data augmentation or constructing attention mechanisms. The team from Carnegie Mellon University provided an interface document query function for intelligent agents based on the concept of retrieval-augmented generation. By querying the interface documentation of liquid processors, the intelligent agent can achieve precise control over the liquid processor using ultraviolet-visible spectral measurement tools and Python computational tools based on user text commands, which can be used for the automatic design, planning, and execution of scientific experiments.
3. Reasoning and Planning
The task planning of intelligent agents aims to decompose complex tasks into multiple executable subtasks, mainly relying on the reasoning capabilities of large models. By constructing prompt information that can stimulate the reasoning capabilities of large models, agents can autonomously complete multi-step reasoning and decompose complex tasks into multiple executable subtasks, thus autonomously planning specific behavior sequences to achieve task objectives. There are already various proven effective methods for constructing prompt information, including typical methods based on single-path reasoning such as Chain of Thought (CoT), multi-path reasoning based methods like Self-consistency (CoT-SC), Tree of Thought (TOT), and planning methods that integrate behavior reflection like ReAct.
The Chain of Thought, as one of the earliest proposed reasoning methods, aims to stimulate large models to use multi-step thinking during reasoning, thereby guiding the model to execute specific tasks along a single path. Building on this, the self-consistency chain of thought considers the randomness of content generated by large models, constructing multiple parallel chains of thought by repeatedly executing the single-path reasoning chain, ultimately selecting the result with the highest consistency as the answer. The Tree of Thought further refines the reasoning process and integrates the advantages of the above two, constructing a tree-structured problem-solving solution. Each path in the tree structure represents a solution, and each node represents an intermediate step. The Tree of Thought decomposes the intermediate steps of task reasoning according to different problem attributes, striving for each step to be executed in relatively reliable small steps, thereby generating possible solutions for the next step at the current node. The Tree of Thought provides heuristic path selection for subsequent search algorithms by setting independent quality assessment mechanisms for each node or voting mechanisms among multiple nodes. Ultimately, based on different tree structures, breadth-first or depth-first search algorithms are used to select the best problem-solving path. The ReAct planning method further integrates feedback information from task execution during the reasoning process, enabling agents to achieve autonomous interaction with external resources, task planning updates, and anomaly handling. In specific task planning processes, the ReAct planning method consists of three basic actions: Thought, Action, and Observation of Action Results. By repeatedly executing this combination of actions, a final solution containing multiple rounds of reasoning steps is generated. The ReAct method has shown good performance in various language and decision-making tasks such as question answering, fact verification, text games, and web navigation, with the generated task trajectories being interpretable and credible.
4. Interaction and Evolution
Agents can collaborate and complete complex tasks through interactions with external environments, humans, and other agents, thereby achieving autonomous evolution. In interactions with external environments, agents can autonomously set tasks and explore the external world based on their data, available tools, inventory resources, and environmental descriptions. During the exploration process, agents can construct skill libraries to accumulate skills based on a self-check mechanism of machine language, achieving complex and meaningful autonomous evolutionary behaviors. For instance, the Voyager, as a large model-driven agent, has achieved autonomous world exploration and skill evolution in sandbox survival games.
In interactions with humans, agents support users in customizing the integration of various large language models and tools, conducting autonomous planning and human-machine collaboration, thereby effectively solving tasks across various fields and types, such as programming, mathematics, experimental operations, online decision-making, and Q&A. For example, agents can solve complex number theory problems through automated problem-solving, and when a problem is answered incorrectly, they can obtain human feedback through human-machine collaboration to improve and correct errors in automated answers. Agents can complete tasks such as organic synthesis, drug discovery, and materials design based on user input instructions, achieving the automatic synthesis of a mosquito repellent and three organic catalysts in tests, guiding humans to discover new chromophores through human-machine collaboration.
Different agents can also interact and collaborate to advance the resolution of complex tasks and self-evolution. For example, by constructing a “Plan, Execute, Inspect, and Learn” (PEIL) guiding mechanism, multi-agent task planning and tool execution, visual perception and memory management, proactive learning and scheme optimization can be realized, demonstrating excellent performance in tasks like visual question answering and reasoning questions. At the same time, debate-style interactions among multiple agents can enhance their ability to solve complex reasoning problems and have shown effectiveness in tasks such as commonsense machine translation and counterintuitive arithmetic reasoning. Moreover, agents can simulate and realize specific business processes and task objectives through role division and collaboration among multiple agents. For instance, the MetaGPT multi-agent collaboration framework can assign roles (such as product manager and software development engineer) to multiple agents and set workflows, achieving automated software development processes through the introduction of human job mechanisms.
Furthermore, the memory mechanism of agents plays an important role in interaction and evolution, supporting agents’ review of interaction history, knowledge acquisition, experience reflection, skill accumulation, and self-evolution. The generative agents proposed by Stanford University constructed a virtual town scene in a sandbox game engine, enabling dynamic behavior planning of virtual individuals and simulating credible human behavior. This generative agent established a memory flow mechanism to store perceived virtual environment information and individual experiences in the memory flow. Agents can make behavioral decisions based on individual memories and can also form long-term behavioral planning and high-level reflection, providing memory reserves for subsequent behavioral decisions. For example, in the behavioral decision of “whether to attend a party,” an agent first retrieves relevant memory records from the memory flow, calculating a comprehensive score for each memory based on the timeliness, relevance, and importance of each record to the decision task. The highest-ranking memories will serve as decision-making references and be included in the prompt information to assist in behavioral decisions.
(3) Implementation Methods
Agents use large models as core controllers, emphasizing the dynamic interaction between agents and information, the integration of reasoning and planning capabilities, the establishment of memory and reflection mechanisms, the realization of tool usage and task execution capabilities, and the continuous evolution of capabilities during interactions with external environments. These characteristics collectively endow agents with high-level information understanding and processing capabilities, bringing their decision-making approaches closer to those of humans and demonstrating the ability to understand and handle complex situations. To support the practical implementation of large model-based agents, several engineering frameworks have been developed and open-sourced, such as LangChain, which supports single-agent implementations, and Auto-GPT, as well as AutoGen, BabyAGI, and CAMEL, which support multi-agent collaboration. These frameworks provide important resources for researchers and developers, facilitating the development and testing of agents’ multi-scenario applications.
In the aforementioned implementation frameworks, LangChain and AutoGen are respectively the most widely used single-agent and multi-agent frameworks. LangChain provides a structured application process for large models, facilitating the engineering implementation of agents. Its technical component modules include model I/O, retrieval, agents, chains, and memory. LangChain supports a rich array of tool and toolkit calls and can realize multiple core capabilities of agents, such as retrieval-augmented generation and ReAct planning. AutoGen allows users to flexibly define interaction modes and human-machine collaboration modes among multiple agents according to their needs, such as a dynamic group discussion mode led by one agent with human participation or a collaborative coding mode where two agents are responsible for coding and debugging respectively. AutoGen supports the interactive memory read/write of multiple agents and can use third-party Python toolkits to realize tool usage (such as calling the Matplotlib plotting library for mathematical plotting) while supporting the transformation of tasks into machine language solutions, executing tasks step by step with code, and ensuring the successful operation of programs through code execution and debugging among agents.
Both LangChain and AutoGen provide feasible solutions for agent implementation, and their combined use can leverage their respective advantages. For example, AutoGen can flexibly construct and realize the interaction framework of agents and machine language-based task execution, while LangChain can assist in connecting a rich external tool library (such as ArXiv, Office365, Wolfram Alpha, etc.) and custom tools (by providing tool function descriptions, method implementation codes, input/output formats, etc.), thereby expanding the capability boundaries of agents.
3. Construction of Teaching Intelligent Agents Based on Large Models
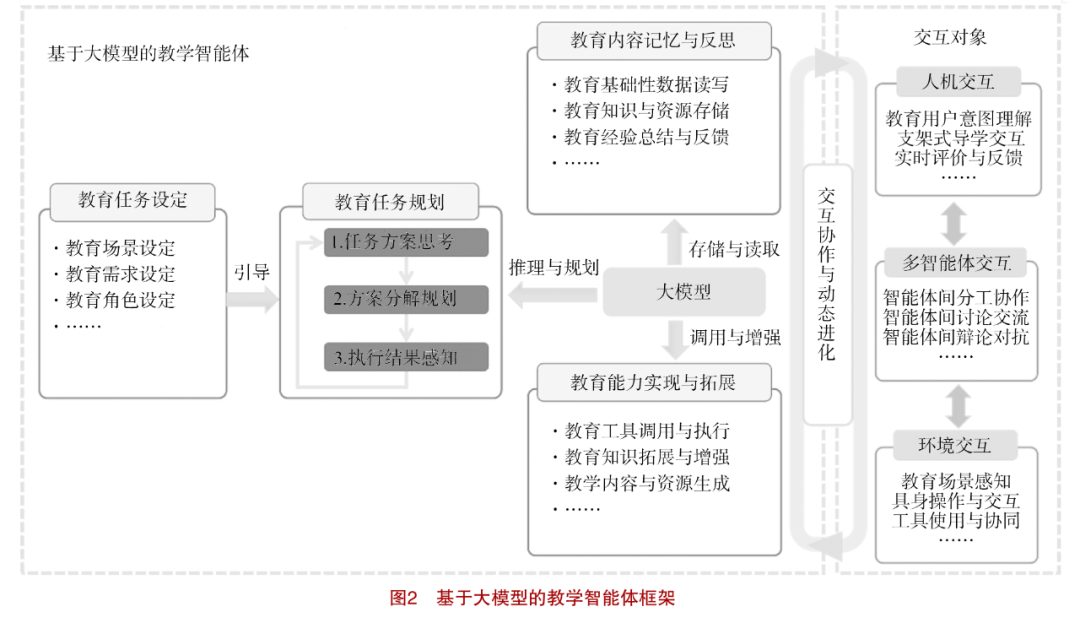
Based on the rapid evolution and development of large models in the current education sector, this study proposes the construction of teaching intelligent agents based on large models. As shown in Figure 2, teaching intelligent agents center around the “large model,” and their main functional modules include “educational task setting,” “educational task planning,” “educational capability realization and expansion,” and “educational content memory and reflection.” At the same time, teaching intelligent agents support interactions with multiple types of objects and achieve dynamic evolution, covering human-machine interaction, multi-agent interaction, and environmental interaction.
(1) Educational Task Setting
The “educational task setting” module encompasses the provision of key information such as educational scenario setting, educational demand setting, and educational role setting. Among them, the setting of educational scenarios provides background information for the agent’s educational tasks, such as project-based learning scenarios centered on students, online self-learning scenarios, traditional classroom teaching scenarios, etc.; educational demand setting provides specific goal descriptions for educational tasks, such as providing strategic scaffolding for project-based learning, evaluating learners’ problem-solving abilities, and coordinating group collaborative learning; educational role setting assigns specific role information that the agent needs to play in educational tasks, such as teaching assistants, student partners, training assistants, and family assistants. The setting of educational roles helps agents interact more effectively with educational users, providing personalized interaction experiences and improving assistance effectiveness. Multiple teaching intelligent agents can also meet key educational needs in specific educational scenarios through role division, collaborative debate, and human-machine collaboration.
(2) Educational Task Planning
Based on the established educational task information, teaching intelligent agents can achieve autonomous task planning, with basic steps and sequences including “task scheme thinking,” “scheme decomposition planning,” and “execution result perception.” First, the “task scheme thinking” step combines key information such as established educational scenarios, demands, and roles with relevant educational standards or frameworks, educational resources, and auxiliary tools to reason and generate an overall scheme; the “scheme decomposition planning” step decomposes the generated overall scheme into multiple executable and manageable subtasks, including planning specific teaching activities, teaching resources, teaching tools, and educational evaluation methods. Teaching intelligent agents can also adjust each subtask in real-time based on feedback from teachers or learners, ensuring the adaptability and effectiveness of educational task planning. After the planned subtasks are executed, the “execution result perception” step is responsible for obtaining execution results and multi-dimensional interaction information. By introducing an evaluation feedback mechanism, based on task execution results, agents can autonomously reason or manually evaluate the quality of subtask completion. If problems are found or planning goals are not met, the agent will restart the “task scheme thinking” step until the goals are achieved before exiting the loop. Through the above educational task planning process, agents can iteratively optimize the execution process and strategies of educational tasks to meet efficient personalized educational needs.
(3) Educational Capability Realization and Expansion
Teaching intelligent agents can realize and expand multiple basic capabilities to execute the specific educational tasks they have planned. First, teaching intelligent agents can call external professional teaching tools and their operating environments, including but not limited to mathematical calculation tools, educational software, and collaborative learning tools. For example, teaching intelligent agents can call the mathematical calculation tool Wolfram Alpha to answer precise calculation problems required across multiple disciplines through interactions based on natural language or mathematical formulas. These external tools can provide professional capabilities that large models do not possess, thereby assisting agents in solving professional problems within the planned educational tasks.
Teaching intelligent agents can also expand their knowledge and capability boundaries through retrieval-augmented generation and other methods to avoid outputting erroneous educational information. Providing educational services typically requires high accuracy and interpretability, thus necessitating real-time updating and reliable information sources for agents. For example, agents can obtain and integrate the latest educational resources and real-time educational data from national educational resource public service platforms, professional educational academic journals, and educational news websites, achieving retrieval-augmented generation of educational content and clearly explaining the basis for the content provided, ensuring the timeliness and accuracy of the educational services offered.
Moreover, after perceiving and understanding the elements of educational scenarios, teaching intelligent agents can automatically generate educational content and products in various forms, including teaching text dialogues and audio-visual teaching resources, to provide full-process support for established educational roles. For example, when the execution of educational tasks involves programming and logical reasoning, agents can leverage the code generation and debugging capabilities of large models to translate tasks into machine languages such as Python and assist learners in completing programming tasks. For educational tasks requiring embodied operations, teaching intelligent agents can automatically generate operational processes based on physical environmental perception capabilities and complete real-time control of hardware and software according to educational user instructions.
(4) Educational Content Memory and Reflection
The educational content memory of teaching intelligent agents is primarily used to store and retrieve important data during the planning and execution processes of educational tasks, supporting the agents’ self-reflection. Specifically, educational content memory can store foundational data for all steps of educational task planning and execution, such as educational task solution data, interaction Q&A data between agents and learners, the process and result data of external tool calls, and hardware and software control and operation data. Based on the stored foundational data, agents can reflect on and process educational knowledge and experiences through self-questioning or summarization methods using large models. For example, teaching intelligent agents can reflect on personalized characteristics of the learners they serve and the effectiveness of their teaching interactions. Combined with mechanisms of trial and error or interactive feedback, teaching intelligent agents can summarize failed or inefficient teaching experiences, serving as references for autonomously optimizing and improving teaching strategies when encountering similar educational tasks again. Additionally, the rich educational memories and reflections stored by agents can serve as important reference knowledge and resources supporting the expansion of their teaching capabilities.
Based on permission dimensions, educational content memory can be divided into public memory and private memory. Public memory refers to the educational knowledge and teaching resources accumulated by teaching intelligent agents, including subject knowledge graphs, teaching method knowledge, curriculum standards, teaching materials, and auxiliary materials; private memory refers to individual information closely related to educational users and their roles, such as individual learners’ historical interaction and learning evaluation data, individual teachers’ teaching videos, teaching plans, and evaluation data. Teaching intelligent agents need to reasonably use memory data with different permissions, respect the privacy of educational users, and establish corresponding educational data usage norms.
(5) Interaction Collaboration and Dynamic Evolution
Teaching intelligent agents can achieve collaborative planning and execution of educational tasks through interactions with different roles of educational users, other agents, and educational environments, promoting their dynamic evolution. In interactions with educational users, teaching intelligent agents can fully understand the intentions of different roles of educational users, thereby providing various forms and modalities of human-machine interaction services. For example, in online self-learning scenarios for learners, providing multi-type scaffolded intelligent guidance interaction services supports recommending multi-modal teaching content, including text, video, and audio teaching resources, while providing real-time progress evaluation and feedback information. In interactions with other agents, agents can achieve supervisory guidance, discussion, collaboration, and even orderly debate modes based on the role-playing of different agents and educational tasks. For instance, engaging in debate-style interactions among multiple agents can achieve scientific decomposition and reasonable planning of complex educational tasks. Additionally, educational subjects can be introduced into the multi-agent interaction process, achieving educational goal attainment in a human-machine collaborative mode. For example, during collaborative exam paper compilation, based on the subject, knowledge points, and discrimination requirements provided by teachers, different agents can serve as question setters, test-takers, and graders to complete the exam paper compilation, which is ultimately reviewed by teachers for quality assurance. In interactions with educational environments, agents can fully utilize external hardware and software tools and their human-machine interaction capabilities to achieve embodied operations and human-machine collaboration, such as completing complex experimental operations in subjects like physics and chemistry or scientific inquiry processes through real-time perception of experimental instrument statuses and precise control of robotic arms.
In interactions with educational users, other agents, and educational environments, teaching intelligent agents can gradually form educational experiences and reflective knowledge through continuous collection and analysis of process and outcome data and feedback information. These experiences and knowledge can be stored and retrieved by agents’ memories, used for planning future educational tasks and executing educational capabilities, thus achieving dynamic enhancement and evolution of their problem-solving capabilities. For example, by reflecting on human-machine interaction process information and summarizing scientific instrument control processes, teaching intelligent agents can more efficiently plan scientific experiment steps and provide real-time scaffolding for experimental operations and collaborative services for scientific inquiry.
4. Applications of Teaching Intelligent Agents Based on Large Models
Based on the framework proposed above, this study illustrates the application of teaching intelligent agents using project-based learning scenarios as an example. Project-based learning is an effective teaching model for cultivating students’ core competencies and higher-order abilities. In typical project-based learning processes, learners usually require continuous support from teachers and peers to complete project outputs. Teaching intelligent agents can conduct specific task planning for the completion of project outputs through project-based learning task settings, support memory and reflection related to project-based learning content, and provide multi-modal project resource generation, retrieval-augmented generative learning scaffolding, high-quality code generation and feedback, among other capabilities, while supporting human-machine interaction and multi-agent interaction modes. As shown in Figure 3, teaching intelligent agents can assume two educational roles: “teaching assistant agent” and “peer agent,” having different task settings, expansion capabilities, and individual memories in different project stages, thus exhibiting capability and functional differences to provide various interactive support for learners. Taking the common interdisciplinary theme of “garbage classification” in information technology or artificial intelligence courses as an example, we illustrate the role of teaching intelligent agents in various stages of project-based learning.
1. Multimodal Perception and Generation
Multimodal perception and generation integrate various data channels such as vision, speech, and text to achieve external information acquisition in a standalone or combined manner, thereby endowing intelligent agents with the ability to understand and analyze their surrounding environment. Relying on the understanding and generation capabilities of vision and language, agents can perform various image-text perception and generation tasks, such as Visual Question Answering (VQA) and Text-to-Image Generation. For example, the visual question-answering task requires the agent to answer questions related to scene understanding, such as “counting,” “attribute recognition,” and “object detection” based on image information. Building on this, the external knowledge-based visual question-answering task requires the agent to answer questions that cannot be understood solely through image information, encouraging it to generate answers by retrieving from external knowledge bases combined with image understanding. Currently, the multimodal perception and generation capabilities of agents have expanded into the video domain, supporting the interpretation and construction of continuous image frames to accurately answer questions related to video content or generate logically coherent high-quality videos. Furthermore, for embodied operational entities such as physical robots or virtual environment characters, multimodal perception can support real-time information updates for environmental interactions, assisting agents in completing complex tasks such as task planning, path planning, reasoning, and decision-making.
2. Retrieval-Augmented Generation
To mitigate issues such as the “hallucination” of large models that generates information contrary to facts and the untimely updating of data, retrieval-augmented generation (RAG) technology has begun to be widely adopted. Retrieval-augmented generation technology can provide large models with reliable external knowledge related to the problems to be solved based on knowledge base retrievers. This technology mainly includes three basic steps: index establishment, question retrieval, and content generation. The index establishment step requires constructing a knowledge base based on specified task information, which can cover various types of knowledge resources, including documents, web pages, knowledge graphs, etc., and utilizes methods such as word embeddings of language models to extract the semantic features of the resources, which are then stored in the knowledge base online or offline. The question retrieval step takes the user’s question content as a retrieval request, extracts its textual semantic features, and retrieves matching data content from the knowledge base as auxiliary information for the question. In the content generation step, the large model generates answers to the question based on the user’s inquiry information and the retrieved auxiliary information through methods such as data augmentation or constructing attention mechanisms. The team from Carnegie Mellon University provided an interface document query function for intelligent agents based on the concept of retrieval-augmented generation. By querying the interface documentation of liquid processors, the intelligent agent can achieve precise control over the liquid processor using ultraviolet-visible spectral measurement tools and Python computational tools based on user text commands, which can be used for the automatic design, planning, and execution of scientific experiments.
3. Reasoning and Planning
The task planning of intelligent agents aims to decompose complex tasks into multiple executable subtasks, mainly relying on the reasoning capabilities of large models. By constructing prompt information that can stimulate the reasoning capabilities of large models, agents can autonomously complete multi-step reasoning and decompose complex tasks into multiple executable subtasks, thus autonomously planning specific behavior sequences to achieve task objectives. There are already various proven effective methods for constructing prompt information, including typical methods based on single-path reasoning such as Chain of Thought (CoT), multi-path reasoning based methods like Self-consistency (CoT-SC), Tree of Thought (TOT), and planning methods that integrate behavior reflection like ReAct.
The Chain of Thought, as one of the earliest proposed reasoning methods, aims to stimulate large models to use multi-step thinking during reasoning, thereby guiding the model to execute specific tasks along a single path. Building on this, the self-consistency chain of thought considers the randomness of content generated by large models, constructing multiple parallel chains of thought by repeatedly executing the single-path reasoning chain, ultimately selecting the result with the highest consistency as the answer. The Tree of Thought further refines the reasoning process and integrates the advantages of the above two, constructing a tree-structured problem-solving solution. Each path in the tree structure represents a solution, and each node represents an intermediate step. The Tree of Thought decomposes the intermediate steps of task reasoning according to different problem attributes, striving for each step to be executed in relatively reliable small steps, thereby generating possible solutions for the next step at the current node. The Tree of Thought provides heuristic path selection for subsequent search algorithms by setting independent quality assessment mechanisms for each node or voting mechanisms among multiple nodes. Ultimately, based on different tree structures, breadth-first or depth-first search algorithms are used to select the best problem-solving path. The ReAct planning method further integrates feedback information from task execution during the reasoning process, enabling agents to achieve autonomous interaction with external resources, task planning updates, and anomaly handling. In specific task planning processes, the ReAct planning method consists of three basic actions: Thought, Action, and Observation of Action Results. By repeatedly executing this combination of actions, a final solution containing multiple rounds of reasoning steps is generated. The ReAct method has shown good performance in various language and decision-making tasks such as question answering, fact verification, text games, and web navigation, with the generated task trajectories being interpretable and credible.
4. Interaction and Evolution
Agents can collaborate and complete complex tasks through interactions with external environments, humans, and other agents, thereby achieving autonomous evolution. In interactions with external environments, agents can autonomously set tasks and explore the external world based on their data, available tools, inventory resources, and environmental descriptions. During the exploration process, agents can construct skill libraries to accumulate skills based on a self-check mechanism of machine language, achieving complex and meaningful autonomous evolutionary behaviors. For instance, the Voyager, as a large model-driven agent, has achieved autonomous world exploration and skill evolution in sandbox survival games.
In interactions with humans, agents support users in customizing the integration of various large language models and tools, conducting autonomous planning and human-machine collaboration, thereby effectively solving tasks across various fields and types, such as programming, mathematics, experimental operations, online decision-making, and Q&A. For example, agents can solve complex number theory problems through automated problem-solving, and when a problem is answered incorrectly, they can obtain human feedback through human-machine collaboration to improve and correct errors in automated answers. Agents can complete tasks such as organic synthesis, drug discovery, and materials design based on user input instructions, achieving the automatic synthesis of a mosquito repellent and three organic catalysts in tests, guiding humans to discover new chromophores through human-machine collaboration.
Different agents can also interact and collaborate to advance the resolution of complex tasks and self-evolution. For example, by constructing a “Plan, Execute, Inspect, and Learn” (PEIL) guiding mechanism, multi-agent task planning and tool execution, visual perception and memory management, proactive learning and scheme optimization can be realized, demonstrating excellent performance in tasks like visual question answering and reasoning questions. At the same time, debate-style interactions among multiple agents can enhance their ability to solve complex reasoning problems and have shown effectiveness in tasks such as commonsense machine translation and counterintuitive arithmetic reasoning. Moreover, agents can simulate and realize specific business processes and task objectives through role division and collaboration among multiple agents. For instance, the MetaGPT multi-agent collaboration framework can assign roles (such as product manager and software development engineer) to multiple agents and set workflows, achieving automated software development processes through the introduction of human job mechanisms.
Furthermore, the memory mechanism of agents plays an important role in interaction and evolution, supporting agents’ review of interaction history, knowledge acquisition, experience reflection, skill accumulation, and self-evolution. The generative agents proposed by Stanford University constructed a virtual town scene in a sandbox game engine, enabling dynamic behavior planning of virtual individuals and simulating credible human behavior. This generative agent established a memory flow mechanism to store perceived virtual environment information and individual experiences in the memory flow. Agents can make behavioral decisions based on individual memories and can also form long-term behavioral planning and high-level reflection, providing memory reserves for subsequent behavioral decisions. For example, in the behavioral decision of “whether to attend a party,” an agent first retrieves relevant memory records from the memory flow, calculating a comprehensive score for each memory based on the timeliness, relevance, and importance of each record to the decision task. The highest-ranking memories will serve as decision-making references and be included in the prompt information to assist in behavioral decisions.
(3) Implementation Methods
Agents use large models as core controllers, emphasizing the dynamic interaction between agents and information, the integration of reasoning and planning capabilities, the establishment of memory and reflection mechanisms, the realization of tool usage and task execution capabilities, and the continuous evolution of capabilities during interactions with external environments. These characteristics collectively endow agents with high-level information understanding and processing capabilities, bringing their decision-making approaches closer to those of humans and demonstrating the ability to understand and handle complex situations. To support the practical implementation of large model-based agents, several engineering frameworks have been developed and open-sourced, such as LangChain, which supports single-agent implementations, and Auto-GPT, as well as AutoGen, BabyAGI, and CAMEL, which support multi-agent collaboration. These frameworks provide important resources for researchers and developers, facilitating the development and testing of agents’ multi-scenario applications.
In the aforementioned implementation frameworks, LangChain and AutoGen are respectively the most widely used single-agent and multi-agent frameworks. LangChain provides a structured application process for large models, facilitating the engineering implementation of agents. Its technical component modules include model I/O, retrieval, agents, chains, and memory. LangChain supports a rich array of tool and toolkit calls and can realize multiple core capabilities of agents, such as retrieval-augmented generation and ReAct planning. AutoGen allows users to flexibly define interaction modes and human-machine collaboration modes among multiple agents according to their needs, such as a dynamic group discussion mode led by one agent with human participation or a collaborative coding mode where two agents are responsible for coding and debugging respectively. AutoGen supports the interactive memory read/write of multiple agents and can use third-party Python toolkits to realize tool usage (such as calling the Matplotlib plotting library for mathematical plotting) while supporting the transformation of tasks into machine language solutions, executing tasks step by step with code, and ensuring the successful operation of programs through code execution and debugging among agents.
Both LangChain and AutoGen provide feasible solutions for agent implementation, and their combined use can leverage their respective advantages. For example, AutoGen can flexibly construct and realize the interaction framework of agents and machine language-based task execution, while LangChain can assist in connecting a rich external tool library (such as ArXiv, Office365, Wolfram Alpha, etc.) and custom tools (by providing tool function descriptions, method implementation codes, input/output formats, etc.), thereby expanding the capability boundaries of agents.
3. Construction of Teaching Intelligent Agents Based on Large Models
Based on the rapid evolution and development of large models in the current education sector, this study proposes the construction of teaching intelligent agents based on large models. As shown in Figure 2, teaching intelligent agents center around the “large model,” and their main functional modules include “educational task setting,” “educational task planning,” “educational capability realization and expansion,” and “educational content memory and reflection.” At the same time, teaching intelligent agents support interactions with multiple types of objects and achieve dynamic evolution, covering human-machine interaction, multi-agent interaction, and environmental interaction.
(1) Educational Task Setting
The “educational task setting” module encompasses the provision of key information such as educational scenario setting, educational demand setting, and educational role setting. Among them, the setting of educational scenarios provides background information for the agent’s educational tasks, such as project-based learning scenarios centered on students, online self-learning scenarios, traditional classroom teaching scenarios, etc.; educational demand setting provides specific goal descriptions for educational tasks, such as providing strategic scaffolding for project-based learning, evaluating learners’ problem-solving abilities, and coordinating group collaborative learning; educational role setting assigns specific role information that the agent needs to play in educational tasks, such as teaching assistants, student partners, training assistants, and family assistants. The setting of educational roles helps agents interact more effectively with educational users, providing personalized interaction experiences and improving assistance effectiveness. Multiple teaching intelligent agents can also meet key educational needs in specific educational scenarios through role division, collaborative debate, and human-machine collaboration.
(2) Educational Task Planning
Based on the established educational task information, teaching intelligent agents can achieve autonomous task planning, with basic steps and sequences including “task scheme thinking,” “scheme decomposition planning,” and “execution result perception.” First, the “task scheme thinking” step combines key information such as established educational scenarios, demands, and roles with relevant educational standards or frameworks, educational resources, and auxiliary tools to reason and generate an overall scheme; the “scheme decomposition planning” step decomposes the generated overall scheme into multiple executable and manageable subtasks, including planning specific teaching activities, teaching resources, teaching tools, and educational evaluation methods. Teaching intelligent agents can also adjust each subtask in real-time based on feedback from teachers or learners, ensuring the adaptability and effectiveness of educational task planning. After the planned subtasks are executed, the “execution result perception” step is responsible for obtaining execution results and multi-dimensional interaction information. By introducing an evaluation feedback mechanism, based on task execution results, agents can autonomously reason or manually evaluate the quality of subtask completion. If problems are found or planning goals are not met, the agent will restart the “task scheme thinking” step until the goals are achieved before exiting the loop. Through the above educational task planning process, agents can iteratively optimize the execution process and strategies of educational tasks to meet efficient personalized educational needs.
(3) Educational Capability Realization and Expansion
Teaching intelligent agents can realize and expand multiple basic capabilities to execute the specific educational tasks they have planned. First, teaching intelligent agents can call external professional teaching tools and their operating environments, including but not limited to mathematical calculation tools, educational software, and collaborative learning tools. For example, teaching intelligent agents can call the mathematical calculation tool Wolfram Alpha to answer precise calculation problems required across multiple disciplines through interactions based on natural language or mathematical formulas. These external tools can provide professional capabilities that large models do not possess, thereby assisting agents in solving professional problems within the planned educational tasks.
Teaching intelligent agents can also expand their knowledge and capability boundaries through retrieval-augmented generation and other methods to avoid outputting erroneous educational information. Providing educational services typically requires high accuracy and interpretability, thus necessitating real-time updating and reliable information sources for agents. For example, agents can obtain and integrate the latest educational resources and real-time educational data from national educational resource public service platforms, professional educational academic journals, and educational news websites, achieving retrieval-augmented generation of educational content and clearly explaining the basis for the content provided, ensuring the timeliness and accuracy of the educational services offered.
Moreover, after perceiving and understanding the elements of educational scenarios, teaching intelligent agents can automatically generate educational content and products in various forms, including teaching text dialogues and audio-visual teaching resources, to provide full-process support for established educational roles. For example, when the execution of educational tasks involves programming and logical reasoning, agents can leverage the code generation and debugging capabilities of large models to translate tasks into machine languages such as Python and assist learners in completing programming tasks. For educational tasks requiring embodied operations, teaching intelligent agents can automatically generate operational processes based on physical environmental perception capabilities and complete real-time control of hardware and software according to educational user instructions.
(4) Educational Content Memory and Reflection
The educational content memory of teaching intelligent agents is primarily used to store and retrieve important data during the planning and execution processes of educational tasks, supporting the agents’ self-reflection. Specifically, educational content memory can store foundational data for all steps of educational task planning and execution, such as educational task solution data, interaction Q&A data between agents and learners, the process and result data of external tool calls, and hardware and software control and operation data. Based on the stored foundational data, agents can reflect on and process educational knowledge and experiences through self-questioning or summarization methods using large models. For example, teaching intelligent agents can reflect on personalized characteristics of the learners they serve and the effectiveness of their teaching interactions. Combined with mechanisms of trial and error or interactive feedback, teaching intelligent agents can summarize failed or inefficient teaching experiences, serving as references for autonomously optimizing and improving teaching strategies when encountering similar educational tasks again. Additionally, the rich educational memories and reflections stored by agents can serve as important reference knowledge and resources supporting the expansion of their teaching capabilities.
Based on permission dimensions, educational content memory can be divided into public memory and private memory. Public memory refers to the educational knowledge and teaching resources accumulated by teaching intelligent agents, including subject knowledge graphs, teaching method knowledge, curriculum standards, teaching materials, and auxiliary materials; private memory refers to individual information closely related to educational users and their roles, such as individual learners’ historical interaction and learning evaluation data, individual teachers’ teaching videos, teaching plans, and evaluation data. Teaching intelligent agents need to reasonably use memory data with different permissions, respect the privacy of educational users, and establish corresponding educational data usage norms.
(5) Interaction Collaboration and Dynamic Evolution
Teaching intelligent agents can achieve collaborative planning and execution of educational tasks through interactions with different roles of educational users, other agents, and educational environments, promoting their dynamic evolution. In interactions with educational users, teaching intelligent agents can fully understand the intentions of different roles of educational users, thereby providing various forms and modalities of human-machine interaction services. For example, in online self-learning scenarios for learners, providing multi-type scaffolded intelligent guidance interaction services supports recommending multi-modal teaching content, including text, video, and audio teaching resources, while providing real-time progress evaluation and feedback information. In interactions with other agents, agents can achieve supervisory guidance, discussion, collaboration, and even orderly debate modes based on the role-playing of different agents and educational tasks. For instance, engaging in debate-style interactions among multiple agents can achieve scientific decomposition and reasonable planning of complex educational tasks. Additionally, educational subjects can be introduced into the multi-agent interaction process, achieving educational goal attainment in a human-machine collaborative mode. For example, during collaborative exam paper compilation, based on the subject, knowledge points, and discrimination requirements provided by teachers, different agents can serve as question setters, test-takers, and graders to complete the exam paper compilation, which is ultimately reviewed by teachers for quality assurance. In interactions with educational environments, agents can fully utilize external hardware and software tools and their human-machine interaction capabilities to achieve embodied operations and human-machine collaboration, such as completing complex experimental operations in subjects like physics and chemistry or scientific inquiry processes through real-time perception of experimental instrument statuses and precise control of robotic arms.
In interactions with educational users, other agents, and educational environments, teaching intelligent agents can gradually form educational experiences and reflective knowledge through continuous collection and analysis of process and outcome data and feedback information. These experiences and knowledge can be stored and retrieved by agents’ memories, used for planning future educational tasks and executing educational capabilities, thus achieving dynamic enhancement and evolution of their problem-solving capabilities. For example, by reflecting on human-machine interaction process information and summarizing scientific instrument control processes, teaching intelligent agents can more efficiently plan scientific experiment steps and provide real-time scaffolding for experimental operations and collaborative services for scientific inquiry.
4. Applications of Teaching Intelligent Agents Based on Large Models
Based on the framework proposed above, this study illustrates the application of teaching intelligent agents using project-based learning scenarios as an example. Project-based learning is an effective teaching model for cultivating students’ core competencies and higher-order abilities. In typical project-based learning processes, learners usually require continuous support from teachers and peers to complete project outputs. Teaching intelligent agents can conduct specific task planning for the completion of project outputs through project-based learning task settings, support memory and reflection related to project-based learning content, and provide multi-modal project resource generation, retrieval-augmented generative learning scaffolding, high-quality code generation and feedback, among other capabilities, while supporting human-machine interaction and multi-agent interaction modes. As shown in Figure 3, teaching intelligent agents can assume two educational roles: “teaching assistant agent” and “peer agent,” having different task settings, expansion capabilities, and individual memories in different project stages, thus exhibiting capability and functional differences to provide various interactive support for learners. Taking the common interdisciplinary theme of “garbage classification” in information technology or artificial intelligence courses as an example, we illustrate the role of teaching intelligent agents in various stages of project-based learning.
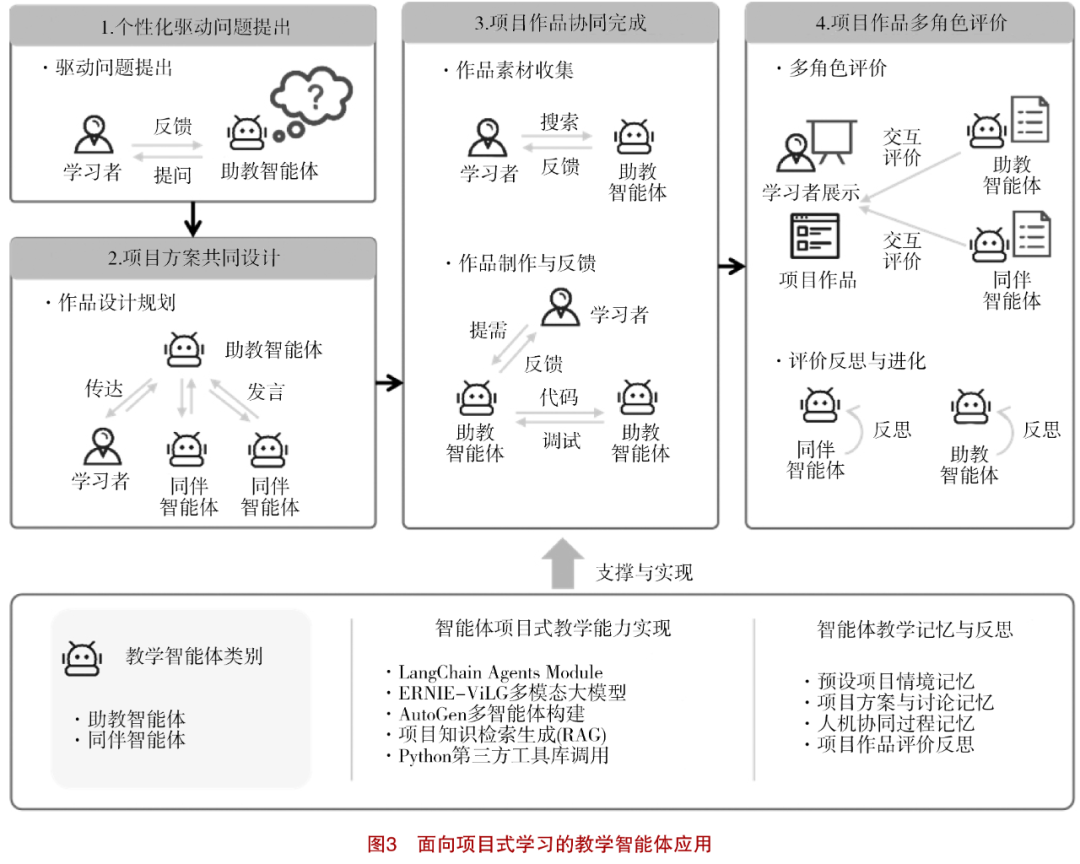 (1) Personalized Driven Problem Proposal
Project-based learning requires proposing driving problems based on real situations, allowing learners to genuinely feel the urgency and feasibility of solving these problems, thereby stimulating their intrinsic motivation to engage in deep exploration and complete projects. Therefore, in the driving problem proposal stage, the “teaching assistant agent” can first establish a driving problem guidance framework based on the preset learning context. Building on this, the “teaching assistant agent” can engage in multi-modal online discussions with learners and, according to the characteristics and learning intentions of the learners, adopt personalized dialogue paths and interaction strategies, ultimately guiding learners to autonomously propose the driving problems for the projects. The “teaching assistant agent” can utilize the intelligent agent module (Agents Module) in the previously mentioned open-source LangChain technology framework to realize this primary function by setting the preset guidance framework as the target question for each round of dialogue and including the learner as a necessary consulting tool in each round of task planning, actively asking questions to learners and engaging in discussions.
For example, regarding the environmental theme of “garbage classification,” the “teaching assistant agent” can create real scenarios for learners by calling the image generation capabilities of the external ERNIE-ViLG multimodal large model to illustrate scenes such as “ocean garbage vortex” and “non-degradable plastic waste.” Simultaneously, the “teaching assistant agent” can engage in online discussions with learners about the urgency of garbage management based on the large model’s dialogue capabilities. Combining the specific feedback from learners, the “teaching assistant agent” can continue to propose possible necessary steps and methods for garbage management, thereby guiding students to autonomously think and clarify specific project activities to undertake, such as “how to promote the environmental concept of garbage classification” or “how to create a smart garbage bin for garbage classification.”
(2) Collaborative Design of Project Schemes
To solve the personalized driving problems proposed by learners, teaching intelligent agents can build dynamic discussion groups between learners and agents, helping learners determine specific solutions and decompose plans based on their educational task planning capabilities. Group discussions can be conducted in two modes: “agent-led” or “learner-led,” depending on project goals and learner styles. In the “agent-led” mode, teaching intelligent agents can utilize the previously mentioned open-source AutoGen technology framework to construct multiple “peer agents” that simulate and play different roles of human group members during the project-based learning process, engaging in multi-role interactions between human learners and multiple “peer agents.” In this process, the “teaching assistant agent” is mainly responsible for selecting the speaker for each round (human learner or “peer agent”) based on the historical content of group dialogue and project goals, broadcasting the spoken content to all group members, thus achieving collaborative design of the project implementation plan through multiple rounds of speaking and information transmission. In the “learner-led” mode, learners can directly choose to engage in dialogue with different “peer agents.”
Specifically, in the “agent-led” mode, to solve the driving problem of “how to promote the environmental concept of garbage classification,” teaching intelligent agents can first utilize their task planning capabilities to decompose the solution to the driving problem into multiple executable subtasks, such as “understanding garbage classification rules,” “collecting examples of various typical garbage,” and “creating promotional materials and carriers.” Based on the planned subtasks, teaching intelligent agents can construct multiple “peer agents” to engage in discussions with learners regarding specific project schemes, providing strategic scaffolding and real-time understanding and timely feedback on learners’ opinions, gradually guiding learners to collaboratively complete the design of project schemes. For example, regarding the subtask of “creating promotional materials and carriers,” multiple “peer agents” in group discussions can propose different solution options for promotional forms such as posters, web pages, or WeChat mini-programs. If learners propose a web-based solution based on their interests and expertise, the “teaching assistant agent” will select a “peer agent” with relevant capabilities to speak, engaging in scheme design and discussion based on creating a “garbage classification promotional website.” Subsequently, the “teaching assistant agent” can broadcast the obtained schemes within the group and select other “peer agents” to refine suggestions, such as first clarifying the rules of “garbage classification” and displaying them prominently on the website.
(3) Collaborative Completion of Project Outputs
Based on the designed project scheme, teaching intelligent agents can construct corresponding “peer agents” to collaboratively complete the production of project outputs with learners. The production of project outputs first requires the collection of relevant materials and information. For example, in the subtask of “understanding garbage classification rules,” learners need to gather the latest garbage classification standards from their locality. Since garbage classification standards vary and change worldwide, the “teaching assistant agent” can provide accurate content generation for learners using the RAG method. As illustrated in Figure 4, “peer agents” can utilize various function shortcuts provided by the LangChain framework to implement the RAG process. First, in the “index establishment” step, agents automatically crawl or manually filter resources from official government environmental department websites on the internet, using the Document Loaders method in LangChain to collect reliable information, and utilizing the Text Splitter method to segment long texts into semantically related short sentences. Based on this, in the “question retrieval” step, the large model extracts textual feature vectors from the text and stores them in the Chroma vector database, constructing a feature retrieval knowledge base for “garbage classification standards.” Subsequently, in the “content generation” step, the retrieval-based question-answering method extracts the textual features of user inquiries and retrieves the information most relevant to the inquiry from the vector database based on feature similarity. Finally, the retrieved information and user inquiry information are input into the prompt template to construct complete prompt information, allowing the large model to generate the latest and correct garbage classification rules.
(1) Personalized Driven Problem Proposal
Project-based learning requires proposing driving problems based on real situations, allowing learners to genuinely feel the urgency and feasibility of solving these problems, thereby stimulating their intrinsic motivation to engage in deep exploration and complete projects. Therefore, in the driving problem proposal stage, the “teaching assistant agent” can first establish a driving problem guidance framework based on the preset learning context. Building on this, the “teaching assistant agent” can engage in multi-modal online discussions with learners and, according to the characteristics and learning intentions of the learners, adopt personalized dialogue paths and interaction strategies, ultimately guiding learners to autonomously propose the driving problems for the projects. The “teaching assistant agent” can utilize the intelligent agent module (Agents Module) in the previously mentioned open-source LangChain technology framework to realize this primary function by setting the preset guidance framework as the target question for each round of dialogue and including the learner as a necessary consulting tool in each round of task planning, actively asking questions to learners and engaging in discussions.
For example, regarding the environmental theme of “garbage classification,” the “teaching assistant agent” can create real scenarios for learners by calling the image generation capabilities of the external ERNIE-ViLG multimodal large model to illustrate scenes such as “ocean garbage vortex” and “non-degradable plastic waste.” Simultaneously, the “teaching assistant agent” can engage in online discussions with learners about the urgency of garbage management based on the large model’s dialogue capabilities. Combining the specific feedback from learners, the “teaching assistant agent” can continue to propose possible necessary steps and methods for garbage management, thereby guiding students to autonomously think and clarify specific project activities to undertake, such as “how to promote the environmental concept of garbage classification” or “how to create a smart garbage bin for garbage classification.”
(2) Collaborative Design of Project Schemes
To solve the personalized driving problems proposed by learners, teaching intelligent agents can build dynamic discussion groups between learners and agents, helping learners determine specific solutions and decompose plans based on their educational task planning capabilities. Group discussions can be conducted in two modes: “agent-led” or “learner-led,” depending on project goals and learner styles. In the “agent-led” mode, teaching intelligent agents can utilize the previously mentioned open-source AutoGen technology framework to construct multiple “peer agents” that simulate and play different roles of human group members during the project-based learning process, engaging in multi-role interactions between human learners and multiple “peer agents.” In this process, the “teaching assistant agent” is mainly responsible for selecting the speaker for each round (human learner or “peer agent”) based on the historical content of group dialogue and project goals, broadcasting the spoken content to all group members, thus achieving collaborative design of the project implementation plan through multiple rounds of speaking and information transmission. In the “learner-led” mode, learners can directly choose to engage in dialogue with different “peer agents.”
Specifically, in the “agent-led” mode, to solve the driving problem of “how to promote the environmental concept of garbage classification,” teaching intelligent agents can first utilize their task planning capabilities to decompose the solution to the driving problem into multiple executable subtasks, such as “understanding garbage classification rules,” “collecting examples of various typical garbage,” and “creating promotional materials and carriers.” Based on the planned subtasks, teaching intelligent agents can construct multiple “peer agents” to engage in discussions with learners regarding specific project schemes, providing strategic scaffolding and real-time understanding and timely feedback on learners’ opinions, gradually guiding learners to collaboratively complete the design of project schemes. For example, regarding the subtask of “creating promotional materials and carriers,” multiple “peer agents” in group discussions can propose different solution options for promotional forms such as posters, web pages, or WeChat mini-programs. If learners propose a web-based solution based on their interests and expertise, the “teaching assistant agent” will select a “peer agent” with relevant capabilities to speak, engaging in scheme design and discussion based on creating a “garbage classification promotional website.” Subsequently, the “teaching assistant agent” can broadcast the obtained schemes within the group and select other “peer agents” to refine suggestions, such as first clarifying the rules of “garbage classification” and displaying them prominently on the website.
(3) Collaborative Completion of Project Outputs
Based on the designed project scheme, teaching intelligent agents can construct corresponding “peer agents” to collaboratively complete the production of project outputs with learners. The production of project outputs first requires the collection of relevant materials and information. For example, in the subtask of “understanding garbage classification rules,” learners need to gather the latest garbage classification standards from their locality. Since garbage classification standards vary and change worldwide, the “teaching assistant agent” can provide accurate content generation for learners using the RAG method. As illustrated in Figure 4, “peer agents” can utilize various function shortcuts provided by the LangChain framework to implement the RAG process. First, in the “index establishment” step, agents automatically crawl or manually filter resources from official government environmental department websites on the internet, using the Document Loaders method in LangChain to collect reliable information, and utilizing the Text Splitter method to segment long texts into semantically related short sentences. Based on this, in the “question retrieval” step, the large model extracts textual feature vectors from the text and stores them in the Chroma vector database, constructing a feature retrieval knowledge base for “garbage classification standards.” Subsequently, in the “content generation” step, the retrieval-based question-answering method extracts the textual features of user inquiries and retrieves the information most relevant to the inquiry from the vector database based on feature similarity. Finally, the retrieved information and user inquiry information are input into the prompt template to construct complete prompt information, allowing the large model to generate the latest and correct garbage classification rules.
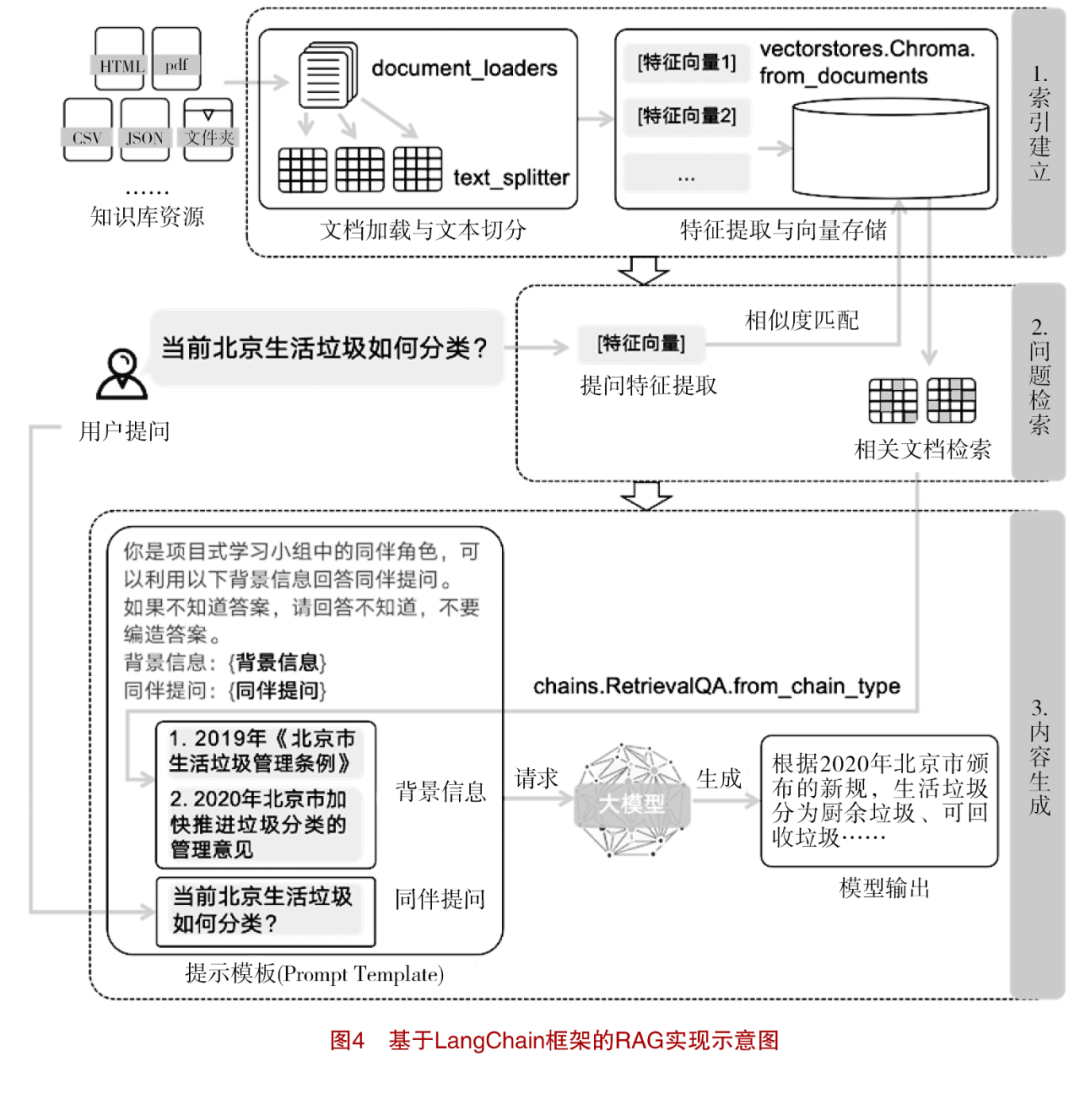 Once the relevant materials are collected, the “teaching assistant agent” can further assist learners in creating the “garbage classification promotional website.” In this process, learners can communicate with the agent in multiple modalities, presenting hand-drawn design drafts of the website front end or discussing backend design concepts using text. The “teaching assistant agent” can call various external web design scripting language libraries to automatically generate the corresponding website code. At the same time, teaching intelligent agents can utilize the embedded machine language execution environment within the AutoGen framework to directly execute the generated code and provide feedback on execution results and error prompts to the “teaching assistant agent,” guiding further automatic modifications and improvements to the code. Learners can also provide feedback on modifications based on the generated pages through page screenshots or natural language, allowing the “teaching assistant agent” to further adjust and optimize the website based on the feedback content.
(4) Multi-Role Evaluation of Project Outputs
During the project outputs presentation and evaluation stage, both the “teaching assistant agent” and “peer agents” can conduct evaluations of project outputs from their respective perspectives, providing teacher evaluations and peer evaluations. Agents can pre-generate corresponding process and outcome evaluation rubrics based on personalized driving problems and project schemes. During the learners’ presentations of the collaboratively produced project outputs, the “teaching assistant agent” and “peer agents” can evaluate the presentation content based on their stored different process information and corresponding evaluation rubrics from the perspectives of teachers and external peers. For example, regarding the “garbage classification promotional website” project outputs, agents can provide objective evaluations based on learners’ contributions during group discussions and the website production process. Simultaneously, agents can utilize their environmental interaction capabilities to click on and access the webpage, conducting interactive testing and quantitative statistics on the website’s design, such as the number of elements on the webpage, color choices, and multimedia usage, obtaining outcome evaluations for the project outputs. Furthermore, agents can input the learners’ presentation content in video form based on their multimodal perception capabilities, evaluating aspects such as language fluency, content logic, and completeness of the presentation.
Based on the evaluation information from this round of project outputs, both the “teaching assistant agent” and “peer agents” can reflect and question from the perspectives of learners’ knowledge mastery, skill acquisition, and interaction effectiveness, promoting simultaneous enhancement of their educational task planning, teaching, and interaction capabilities. Thus, in the next round of project-based learning, agents can more effectively carry out project-based learning under the same theme for new groups of learners, achieving the evolution of agents’ educational capabilities.
5. Conclusion and Outlook
Teaching intelligent agents based on large models represent one of the important future research directions and application forms of generative artificial intelligence in the field of education, as well as a core technical path for solving human-machine collaborative models in the educational sector. The teaching intelligent agent architecture proposed in this study centers around large models and their various capabilities, combined with the multi-scenario demands and multi-role service characteristics in the field of education, aiming to inspire and assist in the design and realization of future highly intelligent education systems. Based on this, this study elaborates on the roles, functions, and collaborative practice paths of teaching intelligent agents in project-based learning scenarios. The research on teaching intelligent agents is still in its infancy. This paper proposes the following research outlook for their future development:
1. The design and development of teaching intelligent agents urgently need to be emphasized to ensure that the education sector can fully leverage cutting-edge technologies such as generative artificial intelligence to rapidly enhance the intelligence and interactivity of various educational products and services. The application of multi-agent technology needs to be emphasized, utilizing agents to simulate and play different key educational roles, achieving efficient teaching interaction processes through various modes such as “discussion-practice-reflection.” At the same time, it is essential to fully utilize the respective advantages of human and agent intelligence to achieve a more reasonable and effective human-machine collaborative education model.
2. Compared to general or other vertical domain intelligent agents, the construction of educational domain agents has unique special requirements and characteristics, necessitating full consideration of the complexity of educational scenarios and teaching subjects, and designing proprietary educational large models and their core educational capabilities. Educational large models need to deeply understand educational resources, teaching subjects, and teaching processes, supported by relevant educational theories and learning sciences.
3. The design of teaching intelligent agents needs to fully consider their impact on learners’ values and ethical concepts, ensuring that the agents’ behaviors align with social moral standards and educational objectives. During the execution of educational tasks, teaching intelligent agents need to possess the capability for continuous learning and self-optimization, continually accumulating experiences through interactions with educational stakeholders, enhancing the reliability and credibility of their educational services, providing inclusive educational resources and teaching strategies, and avoiding bias and discrimination.
[1] Franklin S,Graesser A.Is it an Agent,or just a Program?:A Taxonomy for Autonomous Agents [A].International Workshop on Agent Theories, Architectures, and Languages [C].Berlin,Heidelberg:Springer Berlin Heidelberg,1996.21-35.
[2] Xi Z Chen W,Guo X,et al.The Rise and Potential of Large Language Model Based Agents:A Survey [DB/OL].https://arxiv.org/abs/2309.07864,2023-09-19.
[3] Soller A,Busetta P.An Intelligent Agent Architecture for Facilitating Knowledge Sharing Communication [A].Rosenschein S J,Wooldridge M.Proceedings of the Workshop on Humans and Multi-Agent Systems at the 2nd International Joint Conference on Autonomous Agents and Multi-Agent System [C].New York:Association for Computing Machinery,2003.94-100.
[4] Woolf B P.Building Intelligent Interactive Tutors: Student-centered Strategies for Revolutionizing e-Learning [M].Burlington:Morgan Kaufmann,2010.
[5] Liu Qingtang, Ba Shen et al. A Review of the Mechanisms of Educational Agents on Cognitive Learning [J]. Distance Education Journal, 2019, 37(5):35-44.
[6] Liu Qingtang, Ba Shen et al. Research on the Design of Social Cues for Educational Agents in Video Courses [J]. Research on Educational Technology, 2020, 41(9):55-60.
[7] Liu Sannv Ya, Peng Zhan et al. Intelligent Education from the Perspective of New Data Elements: Models, Paths, and Challenges [J]. Research on Educational Technology, 2021, 42(9):5-11+19.
[8] Swan, M., Kido, T., Roland, E., Santos, R.P.D.Math Agents: Computation Infrastructure, Mathematical Embedding, and Genomics [DB/OL].https://arxiv.org/abs/2307.02502,2023-07-04.
[9] Jinxin S, Jiabao Z, et al. CGMI: Configurable General Multi-agent Interaction Framework [DB/OL].https://arxiv.org/abs/2308.12503,2023-08-28.
[10] Durante Z, Huang Q, et al. Agent AI: Surveying the Horizons of Multimodal Interaction [DB/OL].https://arxiv.org/abs/2401.03568,2024-01-25.
[11] Marino K, Rastegari M, et al. Ok-vqa: A Visual Question Answering Benchmark Requiring External Knowledge [A]. Robert S.and Florian K..Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition [C]. Piscataway:IEEE Computer Society,2019.3195-3204.
[12] Gao Y, Xiong Y, et al. Retrieval-augmented Generation for Large Language Models: A Survey [DB/OL].https://arxiv.org/abs/2312.10997,2024-01-05.
[13] Li H, Su Y, et al. A Survey on Retrieval-augmented Text Generation [DB/OL].https://arxiv.org/abs/2202.01110,2022-02-13.
[14] Boiko D A, MacKnight R, Gomes G. Emergent Autonomous Scientific Research Capabilities of Large Language Models [DB/OL].https://arxiv.org/abs/2304.05332,2023-04-11.
[15] Wei J, Wang X, et al. Chain-of-thought Prompting Elicits Reasoning in Large Language Models [J]. Advances in Neural Information Processing Systems,2022,35:24824-24837.
[16] Wang X, Wei J, et al. Self-consistency Improves Chain of Thought Reasoning in Language Models [DB/OL].https://arxiv.org/abs/2203.11171,2023-03-07.
[17] Yao S, Yu D, et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models [J]. Advances in Neural Information Processing Systems,2024,36:1-11.
[18] Yao S, Zhao J, et al. ReAct: Synergizing Reasoning and Acting in Language Models [DB/OL].https://arxiv.org/abs/2210.03629,2023-03-10.
[19] Wang G, Xie Y, et al. Voyager: An Open-Ended Embodied Agent with Large Language Models [A]. Colas C, Teodorescu L, Ady N, Sancaktar C, Chu J. Intrinsically-Motivated and Open-Ended Learning Workshop@ NeurIPS2023 [C]. Cambridge, MA:MIT Press,2023.
[20] Wu Q, Bansal G, et al. Autogen: Enabling Next-gen LLM Applications via Multi-agent Conversation Framework [DB/OL].https://arxiv.org/abs/2308.08155,2023-10-03.
[21] Bran A M, Cox S, et al. ChemCrow: Augmenting Large-language Models with Chemistry Tools [DB/OL].https://arxiv.org/abs/2304.05376,2023-10-02.
[22] Gao D, Ji L, et al. AssistGPT: A General Multi-modal Assistant that Can Plan, Execute, Inspect, and Learn [DB/OL].https://arxiv.org/abs/2306.08640,2023-06-28.
[23] Liang T, He Z, et al. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate [DB/OL].https://arxiv.org/abs/2305.19118,2023-05-30.
[24] Hong S, Zheng X, et al. Metagpt: Meta Programming for Multi-agent Collaborative Framework [DB/OL].https://arxiv.org/abs/2308.00352,2023-11-06.
[25] Park J S, O’Brien J, et al. Generative Agents: Interactive Simulacra of Human Behavior [A]. Follmer S, Han J, Steimle J, Riche N H. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology [C]. New York:Association for Computing Machinery,2023.1-22.
[26] Wang L, Ma C, et al. A Survey on Large Language Model Based Autonomous Agents [J]. Frontiers of Computer Science,2024,18(6):1-26.
[27] LangChain. LangChain [EB/OL].https://python.langchain.com/docs/get_started/introduction,2023-11-12.
[28] Auto-GPT. Auto-GPT [EB/OL].https://docs.agpt.co/,2023-12-29.
[29] AutoGen. AutoGen [EB/OL].https://microsoft.github.io/autogen/,2023-12-28.
[30] BabyAGI. BabyAGI [DB/OL].https://github.com/yoheinakajima/babyagi,2023-12-28.
[31] Li G, Hammoud H, et al. Camel: Communicative Agents for “mind” Exploration of Large Language Model Society [J]. Advances in Neural Information Processing Systems,2024,36:1-34.
[32] Lu Yu, Yu Jinglei et al. Research and Outlook on the Educational Applications of Multimodal Large Models [J]. Research on Educational Technology, 2023, 44(6):38-44.
[33] Wolfram. WolframAlpha [EB/OL].https://www.wolframalpha.com/,2023-11-11.
[34] Ma Ning, Guo Jiahui et al. Evidence-based Project-based Learning Model and System under Big Data Background [J]. China Educational Technology, 2022,(2):75-82.
[35] Zhang Z, Han X, et al. ERNIE: Enhanced Language Representation with Informative Entities [A]. Korhonen A, Traum D, Màrquez L. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics [C]. Stroudsburg:Association for Computational Linguistics,2019.1441-1451.
Lu Yu: Associate Professor, PhD Supervisor, research direction in artificial intelligence and its educational applications.
Yu Jinglei: PhD candidate, research direction in artificial intelligence and its educational applications.
Chen Penghe: Lecturer, PhD, research direction in artificial intelligence and its educational applications.
Once the relevant materials are collected, the “teaching assistant agent” can further assist learners in creating the “garbage classification promotional website.” In this process, learners can communicate with the agent in multiple modalities, presenting hand-drawn design drafts of the website front end or discussing backend design concepts using text. The “teaching assistant agent” can call various external web design scripting language libraries to automatically generate the corresponding website code. At the same time, teaching intelligent agents can utilize the embedded machine language execution environment within the AutoGen framework to directly execute the generated code and provide feedback on execution results and error prompts to the “teaching assistant agent,” guiding further automatic modifications and improvements to the code. Learners can also provide feedback on modifications based on the generated pages through page screenshots or natural language, allowing the “teaching assistant agent” to further adjust and optimize the website based on the feedback content.
(4) Multi-Role Evaluation of Project Outputs
During the project outputs presentation and evaluation stage, both the “teaching assistant agent” and “peer agents” can conduct evaluations of project outputs from their respective perspectives, providing teacher evaluations and peer evaluations. Agents can pre-generate corresponding process and outcome evaluation rubrics based on personalized driving problems and project schemes. During the learners’ presentations of the collaboratively produced project outputs, the “teaching assistant agent” and “peer agents” can evaluate the presentation content based on their stored different process information and corresponding evaluation rubrics from the perspectives of teachers and external peers. For example, regarding the “garbage classification promotional website” project outputs, agents can provide objective evaluations based on learners’ contributions during group discussions and the website production process. Simultaneously, agents can utilize their environmental interaction capabilities to click on and access the webpage, conducting interactive testing and quantitative statistics on the website’s design, such as the number of elements on the webpage, color choices, and multimedia usage, obtaining outcome evaluations for the project outputs. Furthermore, agents can input the learners’ presentation content in video form based on their multimodal perception capabilities, evaluating aspects such as language fluency, content logic, and completeness of the presentation.
Based on the evaluation information from this round of project outputs, both the “teaching assistant agent” and “peer agents” can reflect and question from the perspectives of learners’ knowledge mastery, skill acquisition, and interaction effectiveness, promoting simultaneous enhancement of their educational task planning, teaching, and interaction capabilities. Thus, in the next round of project-based learning, agents can more effectively carry out project-based learning under the same theme for new groups of learners, achieving the evolution of agents’ educational capabilities.
5. Conclusion and Outlook
Teaching intelligent agents based on large models represent one of the important future research directions and application forms of generative artificial intelligence in the field of education, as well as a core technical path for solving human-machine collaborative models in the educational sector. The teaching intelligent agent architecture proposed in this study centers around large models and their various capabilities, combined with the multi-scenario demands and multi-role service characteristics in the field of education, aiming to inspire and assist in the design and realization of future highly intelligent education systems. Based on this, this study elaborates on the roles, functions, and collaborative practice paths of teaching intelligent agents in project-based learning scenarios. The research on teaching intelligent agents is still in its infancy. This paper proposes the following research outlook for their future development:
1. The design and development of teaching intelligent agents urgently need to be emphasized to ensure that the education sector can fully leverage cutting-edge technologies such as generative artificial intelligence to rapidly enhance the intelligence and interactivity of various educational products and services. The application of multi-agent technology needs to be emphasized, utilizing agents to simulate and play different key educational roles, achieving efficient teaching interaction processes through various modes such as “discussion-practice-reflection.” At the same time, it is essential to fully utilize the respective advantages of human and agent intelligence to achieve a more reasonable and effective human-machine collaborative education model.
2. Compared to general or other vertical domain intelligent agents, the construction of educational domain agents has unique special requirements and characteristics, necessitating full consideration of the complexity of educational scenarios and teaching subjects, and designing proprietary educational large models and their core educational capabilities. Educational large models need to deeply understand educational resources, teaching subjects, and teaching processes, supported by relevant educational theories and learning sciences.
3. The design of teaching intelligent agents needs to fully consider their impact on learners’ values and ethical concepts, ensuring that the agents’ behaviors align with social moral standards and educational objectives. During the execution of educational tasks, teaching intelligent agents need to possess the capability for continuous learning and self-optimization, continually accumulating experiences through interactions with educational stakeholders, enhancing the reliability and credibility of their educational services, providing inclusive educational resources and teaching strategies, and avoiding bias and discrimination.
[1] Franklin S,Graesser A.Is it an Agent,or just a Program?:A Taxonomy for Autonomous Agents [A].International Workshop on Agent Theories, Architectures, and Languages [C].Berlin,Heidelberg:Springer Berlin Heidelberg,1996.21-35.
[2] Xi Z Chen W,Guo X,et al.The Rise and Potential of Large Language Model Based Agents:A Survey [DB/OL].https://arxiv.org/abs/2309.07864,2023-09-19.
[3] Soller A,Busetta P.An Intelligent Agent Architecture for Facilitating Knowledge Sharing Communication [A].Rosenschein S J,Wooldridge M.Proceedings of the Workshop on Humans and Multi-Agent Systems at the 2nd International Joint Conference on Autonomous Agents and Multi-Agent System [C].New York:Association for Computing Machinery,2003.94-100.
[4] Woolf B P.Building Intelligent Interactive Tutors: Student-centered Strategies for Revolutionizing e-Learning [M].Burlington:Morgan Kaufmann,2010.
[5] Liu Qingtang, Ba Shen et al. A Review of the Mechanisms of Educational Agents on Cognitive Learning [J]. Distance Education Journal, 2019, 37(5):35-44.
[6] Liu Qingtang, Ba Shen et al. Research on the Design of Social Cues for Educational Agents in Video Courses [J]. Research on Educational Technology, 2020, 41(9):55-60.
[7] Liu Sannv Ya, Peng Zhan et al. Intelligent Education from the Perspective of New Data Elements: Models, Paths, and Challenges [J]. Research on Educational Technology, 2021, 42(9):5-11+19.
[8] Swan, M., Kido, T., Roland, E., Santos, R.P.D.Math Agents: Computation Infrastructure, Mathematical Embedding, and Genomics [DB/OL].https://arxiv.org/abs/2307.02502,2023-07-04.
[9] Jinxin S, Jiabao Z, et al. CGMI: Configurable General Multi-agent Interaction Framework [DB/OL].https://arxiv.org/abs/2308.12503,2023-08-28.
[10] Durante Z, Huang Q, et al. Agent AI: Surveying the Horizons of Multimodal Interaction [DB/OL].https://arxiv.org/abs/2401.03568,2024-01-25.
[11] Marino K, Rastegari M, et al. Ok-vqa: A Visual Question Answering Benchmark Requiring External Knowledge [A]. Robert S.and Florian K..Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition [C]. Piscataway:IEEE Computer Society,2019.3195-3204.
[12] Gao Y, Xiong Y, et al. Retrieval-augmented Generation for Large Language Models: A Survey [DB/OL].https://arxiv.org/abs/2312.10997,2024-01-05.
[13] Li H, Su Y, et al. A Survey on Retrieval-augmented Text Generation [DB/OL].https://arxiv.org/abs/2202.01110,2022-02-13.
[14] Boiko D A, MacKnight R, Gomes G. Emergent Autonomous Scientific Research Capabilities of Large Language Models [DB/OL].https://arxiv.org/abs/2304.05332,2023-04-11.
[15] Wei J, Wang X, et al. Chain-of-thought Prompting Elicits Reasoning in Large Language Models [J]. Advances in Neural Information Processing Systems,2022,35:24824-24837.
[16] Wang X, Wei J, et al. Self-consistency Improves Chain of Thought Reasoning in Language Models [DB/OL].https://arxiv.org/abs/2203.11171,2023-03-07.
[17] Yao S, Yu D, et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models [J]. Advances in Neural Information Processing Systems,2024,36:1-11.
[18] Yao S, Zhao J, et al. ReAct: Synergizing Reasoning and Acting in Language Models [DB/OL].https://arxiv.org/abs/2210.03629,2023-03-10.
[19] Wang G, Xie Y, et al. Voyager: An Open-Ended Embodied Agent with Large Language Models [A]. Colas C, Teodorescu L, Ady N, Sancaktar C, Chu J. Intrinsically-Motivated and Open-Ended Learning Workshop@ NeurIPS2023 [C]. Cambridge, MA:MIT Press,2023.
[20] Wu Q, Bansal G, et al. Autogen: Enabling Next-gen LLM Applications via Multi-agent Conversation Framework [DB/OL].https://arxiv.org/abs/2308.08155,2023-10-03.
[21] Bran A M, Cox S, et al. ChemCrow: Augmenting Large-language Models with Chemistry Tools [DB/OL].https://arxiv.org/abs/2304.05376,2023-10-02.
[22] Gao D, Ji L, et al. AssistGPT: A General Multi-modal Assistant that Can Plan, Execute, Inspect, and Learn [DB/OL].https://arxiv.org/abs/2306.08640,2023-06-28.
[23] Liang T, He Z, et al. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate [DB/OL].https://arxiv.org/abs/2305.19118,2023-05-30.
[24] Hong S, Zheng X, et al. Metagpt: Meta Programming for Multi-agent Collaborative Framework [DB/OL].https://arxiv.org/abs/2308.00352,2023-11-06.
[25] Park J S, O’Brien J, et al. Generative Agents: Interactive Simulacra of Human Behavior [A]. Follmer S, Han J, Steimle J, Riche N H. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology [C]. New York:Association for Computing Machinery,2023.1-22.
[26] Wang L, Ma C, et al. A Survey on Large Language Model Based Autonomous Agents [J]. Frontiers of Computer Science,2024,18(6):1-26.
[27] LangChain. LangChain [EB/OL].https://python.langchain.com/docs/get_started/introduction,2023-11-12.
[28] Auto-GPT. Auto-GPT [EB/OL].https://docs.agpt.co/,2023-12-29.
[29] AutoGen. AutoGen [EB/OL].https://microsoft.github.io/autogen/,2023-12-28.
[30] BabyAGI. BabyAGI [DB/OL].https://github.com/yoheinakajima/babyagi,2023-12-28.
[31] Li G, Hammoud H, et al. Camel: Communicative Agents for “mind” Exploration of Large Language Model Society [J]. Advances in Neural Information Processing Systems,2024,36:1-34.
[32] Lu Yu, Yu Jinglei et al. Research and Outlook on the Educational Applications of Multimodal Large Models [J]. Research on Educational Technology, 2023, 44(6):38-44.
[33] Wolfram. WolframAlpha [EB/OL].https://www.wolframalpha.com/,2023-11-11.
[34] Ma Ning, Guo Jiahui et al. Evidence-based Project-based Learning Model and System under Big Data Background [J]. China Educational Technology, 2022,(2):75-82.
[35] Zhang Z, Han X, et al. ERNIE: Enhanced Language Representation with Informative Entities [A]. Korhonen A, Traum D, Màrquez L. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics [C]. Stroudsburg:Association for Computational Linguistics,2019.1441-1451.
Lu Yu: Associate Professor, PhD Supervisor, research direction in artificial intelligence and its educational applications.
Yu Jinglei: PhD candidate, research direction in artificial intelligence and its educational applications.
Chen Penghe: Lecturer, PhD, research direction in artificial intelligence and its educational applications.

Reviewed by: Song Lingqing