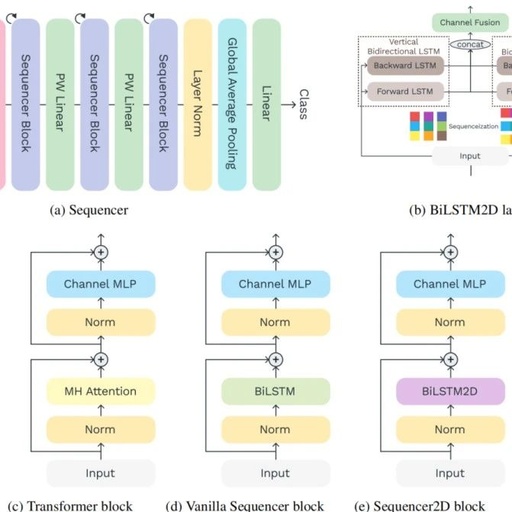
Applications of ResNet in Computer Vision

Click the above “Beginner Learning Vision“, select to add “Star” or “Top“ Essential knowledge delivered promptly 1. IntroductionDeep Convolutional Neural Networks have greatly changed the research landscape of image classification [1]. As more layers are added, the model’s expressive power increases; it can learn more complex representations. To some extent, there seems to be a … Read more