
Click the above“Beginner’s Visual Learning” to selectStar or “Top”
Heavyweight content delivered promptly
The KNN algorithm, or K-Nearest Neighbors algorithm, is a type of supervised learning algorithm that essentially finds the K instances closest to a given test sample A among the provided training samples, and then counts the most frequent class among these K instances to determine the class of A. From this sentence, it is clear that the principle of KNN is very straightforward and it is an “online” learning method, meaning that each classification requires traversing all training samples. Additionally, the KNN algorithm has several elements: K, distance, and classification decision rules.
Elements
For KNN, there are three elements:
The value of K is one of the few hyperparameters in the KNN algorithm, and the choice of K directly affects the model’s performance. If we set a relatively small K value, it means we expect a more complex and precise model, which is also more prone to overfitting; conversely, if K is larger, the model becomes simpler. An extreme example is if we set K equal to the number of training samples, i.e., K=N, then regardless of the class of the test sample, the final test result will always be the most frequent class among the training samples.
Distance measurement describes the proximity of the test sample to the training samples, which serves as the basis for selecting the K samples. In the KNN algorithm, if the features are continuous, the distance function is generally the Manhattan distance (L1 distance) or the Euclidean distance (L2 distance). If the features are discrete, Hamming distance is usually chosen. The Manhattan distance in KNN is the sum of the differences of each dimension of sample features: 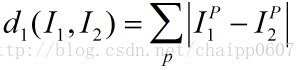 The Euclidean distance in KNN is the square root of the sum of the squares of the differences of each dimension of sample features:
The Euclidean distance in KNN is the square root of the sum of the squares of the differences of each dimension of sample features: 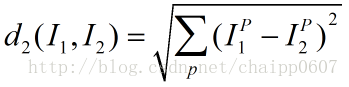 Hamming distance:
Hamming distance: 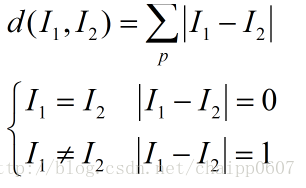
With the concepts of K and distance mentioned above, we can select the K training samples closest to the test sample. How to decide the class of the test sample based on these K samples is the classification decision rule of KNN. The most commonly used rule in KNN is the majority voting rule. However, this rule heavily relies on the number of training samples, which we will discuss later.
Image Classification Problem
So how does the KNN algorithm apply to the image classification problem? The problem essentially boils down to how to evaluate the distance between an image A to P training sample images. The key issue is the selection of image features. Broadly speaking, the significant difference between traditional machine learning and deep learning for images is that the latter automates feature extraction. Therefore, the advent of deep learning has changed the focus of image processing problems from feature description to network structure. Thus, we can loosely categorize the approaches into two types: directly using images and using a method for image feature extraction.
1. Direct Classification Direct classification essentially uses the pixel values of each pixel in the image as features. In this case, the distance between the two images (assuming L1 is used) is the sum of the absolute differences of pixel values at corresponding positions. 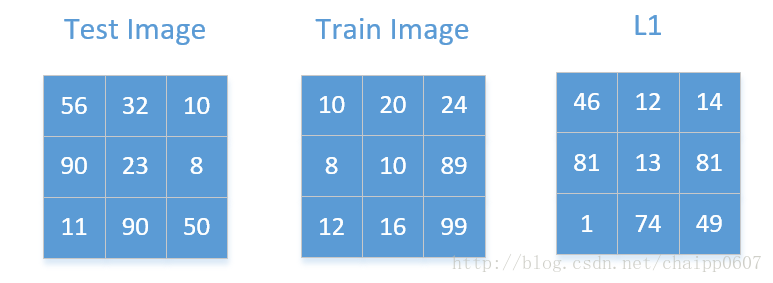 The L1 distance between the two images is 371.
The L1 distance between the two images is 371.
2. Feature-Based Classification Many times, we do not directly use pixel values as features because they do not fundamentally reflect human perception of the image. For instance, if we slightly shift an image in one direction, they should be perceived as the same class by the human eye, but if we compute the distance using pixel values, the distance may be quite large. Therefore, more often, the objects whose distances we calculate are features generated by some descriptors. For example, the HOG+SVM method performs well in pedestrian detection, where SVM acts as a classifier. If we replace it with KNN, it is also feasible (feasible in principle, but the actual effectiveness has not been verified). Thus, in this case, the KNN computes based on the descriptors generated by HOG rather than the pixel values of the images.
Unfortunately, KNN is rarely used in image problems. This viewpoint is derived from Stanford’s CS231n, which states that K-Nearest Neighbor on images is never used.
There are two reasons: 1. Very poor testing efficiency; 2. The distance measurement at the image level may be very counterintuitive. While the second reason can be addressed with some feature descriptors, the first issue is a fundamental flaw of the KNN algorithm. In machine learning, we generally tolerate significantly more time during the testing phase than during training since the final model needs to solve problems quickly. CNNs typically work this way. However, this issue becomes infinitely exposed in KNN; the “online” learning method means that as the sample size increases, the classification process becomes slower.
Conclusion
1. For the problem of imbalanced samples, KNN has a lower tolerance compared to other supervised learning algorithms. 2. The computation and storage requirements of KNN are quite large. 3. However, the concept of KNN is simple, and in some cases, it can achieve high accuracy, such as in the classic handwritten digit recognition problem, where KNN’s accuracy ranks second. 4. KNN is an online learning method that is inefficient, and the larger the sample size, the lower the efficiency.
In response to these issues, various improved algorithms mainly focus on two directions to enhance KNN: the first is how to address the sample imbalance problem, and the second is how to improve classification efficiency.
Source: https://zhangxu.blog.csdn.net/article/details/77915298
Discussion Group
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, three-dimensional vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions (which will gradually be subdivided). Please scan the WeChat ID below to join the group, with the note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Visual SLAM”. Please follow the format for notes, otherwise, you will not be approved. After successfully adding, you will be invited into the relevant WeChat group based on your research direction. Please do not send advertisements in the group, or you will be removed, thank you for your understanding~

