
Click the top“Beginner Learning Vision” to select “Star” or “Top”
Heavyweight content delivered at the first time
Today our goal is to build a classifier that classifies images as “cactus” or “non-cactus”.


This classification problem is one of the Kaggle challenges. The goal is to build a classifier that classifies images as “cactus” or “non-cactus”. The training set contains 17,500 images, while the validation set contains 4,000 images. Images with signs of cacti are located in a folder named cactus, and vice versa. Here are examples from the training dataset.

Cactus

Non-Cactus
When we plot some of the images using the pyplot library, we can observe that they have different sizes, which is detrimental to the training process later. Also, note that we have labeled all images with 1 and 0 indicating cactus and non-cactus respectively.

Therefore, we need to normalize all images to the same size. Based on our experiments, the best strategy is to crop these images to a size of 48 x 48 pixels. Below are some cropped images. The first row shows the original images, and the second row shows the modified images.

The advantage of this method is that it preserves all the details of the image, but sometimes it may lose the edges of the image. If the image is too small, we need to use a black background to extend the image to match the size of the image. Losing edges can be a significant problem because we may cut off the cactus from the original image.
The convolutional neural network consists of 3 convolutional layers and 2 fully connected layers. Each convolutional layer has a 3 x 3 filter with a stride of 2, outputting 64 nodes. After that, the data passes through a max pooling layer to prevent overfitting and extract useful information.
model = Sequential()
model.add(Conv2D(64, (3,3), input_shape = X_train.shape[1:]))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3,3)))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3,3)))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Dense(1))
model.add(Activation(‘sigmoid’))
model.compile(loss="binary_crossentropy",optimizer="adam",metrics=[‘accuracy’])
history = model.fit(X_train, Y_train, batch_size=32, epochs=10, validation_split=0.1, use_multiprocessing=True)
model.save(‘model_48_crop’)Below is an overview of the model structure.

Model Summary
We trained the model for 10 epochs, and the results showed amazing effects. In the code snippet below, the first accuracy is the training accuracy, and the second accuracy is the validation accuracy. Note that before the final prediction, we used a portion of the training set (10%) as the validation set.
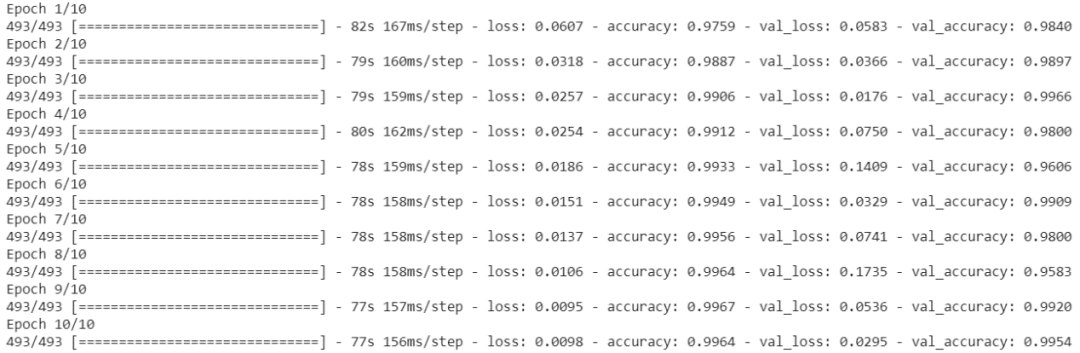
Now, we use the validation_set provided by Kaggle as the test set to make the final predictions for our trained model.
testdata = pd.read_pickle(“pickled_data_validation/crop_images(48, 48).pkl”)
test_images = testdata.loc[:, data.columns != ‘class’]
test_images = test_images.to_numpy()
test_images = test_images.reshape((len(test_images),48, 48, 3))
test_images = test_images/255.0
print(test_images.shape)
test_labels = testdata[‘class’]
test_labels = test_labels.to_numpy()
type(test_labels)
test_labels = test_labels.reshape((len(test_labels),1))
loss, acc = new_model.evaluate(test_images, test_labels, verbose=2)
print(‘Restored model, accuracy: {:5.2f}%’.format(100*acc))Here are the results. It achieved nearly 99% accuracy, which is amazing.

The main purpose of this article is to share the structure of convolutional networks and address binary classification problems like cat and dog image classification.
Discussion Group
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions (will gradually be subdivided later), please scan the WeChat number below to join the group, and note: “nickname + school/company + research direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format, otherwise you will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise you will be removed from the group. Thank you for your understanding~

