
Machine Heart Editorial Team
Is a more complex deep learning model architecture always better?
Over the past few decades, artificial neural networks have made significant progress, thanks to the idea that increasing the complexity of the network can enhance performance. Since AlexNet sparked the deep learning craze in computer vision, researchers have meticulously designed a variety of modules to improve the performance of deep networks, including residuals in ResNet and attention mechanisms in ViT. However, while deep complex neural networks can achieve impressive performance, their inference speed in practical applications is often slowed down by these complex operations.
Researchers from Huawei Noah and the University of Sydney have proposed a minimalist neural network model called VanillaNet, which adheres to the design philosophy of minimalism. The network contains only the simplest convolutional computations, removing residual and attention modules, and has achieved remarkable results across various tasks in computer vision. The 13-layer VanillaNet model can reach 83% accuracy on ImageNet, challenging the necessity of complex designs in deep learning models.

-
Paper link: https://arxiv.org/abs/2305.12972
-
Code link: https://github.com/huawei-noah/VanillaNet
Architecture Design of the Minimalist Network
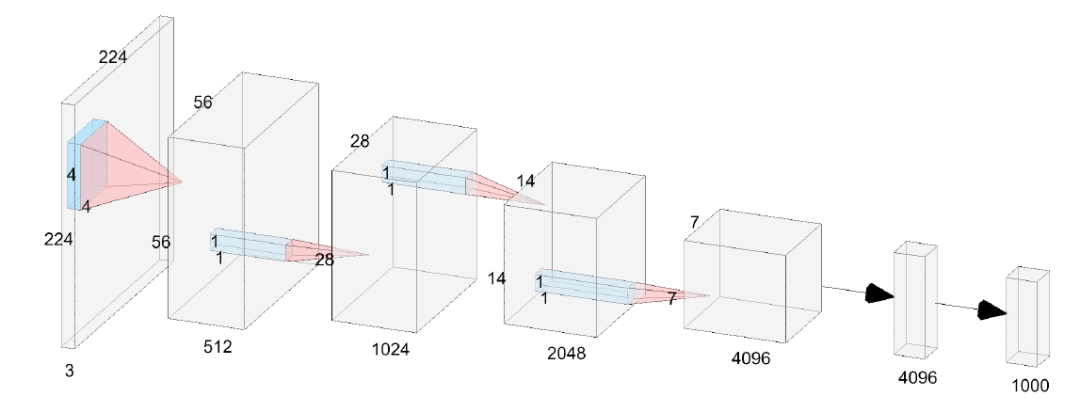
Figure 1. Diagram of the 6-layer VanillaNet structure
Figure 1 shows the structure of the 6-layer VanillaNet, which is very simple, consisting of 5 convolutional layers, 5 pooling layers, one fully connected layer, and 5 activation functions. The design structure follows common schemes of traditional deep networks like AlexNet and VGG: the resolution gradually decreases while the number of channels gradually increases, without including residuals or self-attention computations.
However, can such a simple neural network structure really achieve SOTA accuracy? From past experience, networks like AlexNet and VGG have been abandoned due to their difficulty in training and low accuracy. How to improve the accuracy of such networks is a challenge that needs to be solved.
Training Strategy for the Minimalist Network
The authors believe that the bottleneck of VanillaNet mainly arises from the non-linearity issues caused by its fewer layers. Based on this perspective, the authors first proposed a deep training strategy to address this problem.
For a convolutional layer in VanillaNet, the deep training strategy suggests splitting it into two convolutional layers to increase its non-linearity. However, splitting one layer into two will significantly increase the computational load and complexity of the network. Therefore, the authors propose to only increase the number of layers during training, and then merge them during inference. Specifically, the split convolutional layers will use the following activation function:
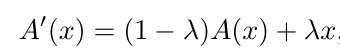
Which is obtained by weighting a traditional non-linear activation function (such as ReLU) and an identity mapping. In the initial stages of network training, the non-linear activation function dominates, allowing the network to have high non-linearity at the start of training. Throughout the training process, the weight of the identity mapping gradually increases, and at this point, the activation function gradually becomes a linear identity mapping, derived through the following formula:
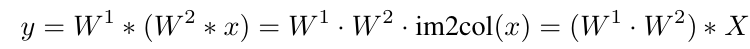
Two convolutional layers without non-linear activation can be merged into one layer, thus achieving the effect of ‘deep training, shallow inference’.
Additionally, the authors proposed a series-inspired activation function to further increase network non-linearity. Specifically, assuming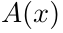 is any existing non-linear activation function, the series activation function is obtained by biasing and weighting the activation function, resulting in multiple activation functions being combined, thus enabling a single activation function to exhibit stronger non-linearity:
is any existing non-linear activation function, the series activation function is obtained by biasing and weighting the activation function, resulting in multiple activation functions being combined, thus enabling a single activation function to exhibit stronger non-linearity:
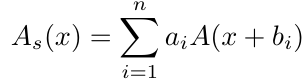
The authors further refined this form so that the activation function can learn global information rather than just information from individual input points:
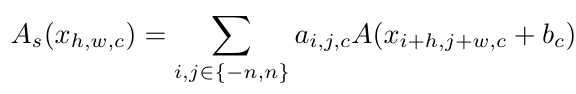
The authors believe that by proposing these two improvements, the non-linearity of the network can be increased, allowing the minimalist network to achieve performance comparable to or even surpassing that of complex networks.
The Power of the Minimalist Network
To prove the effectiveness of VanillaNet, the authors conducted experiments on three major mainstream tasks in computer vision: image classification, detection, and segmentation.
The authors first validated the effectiveness of the proposed deep training strategy and series activation function:
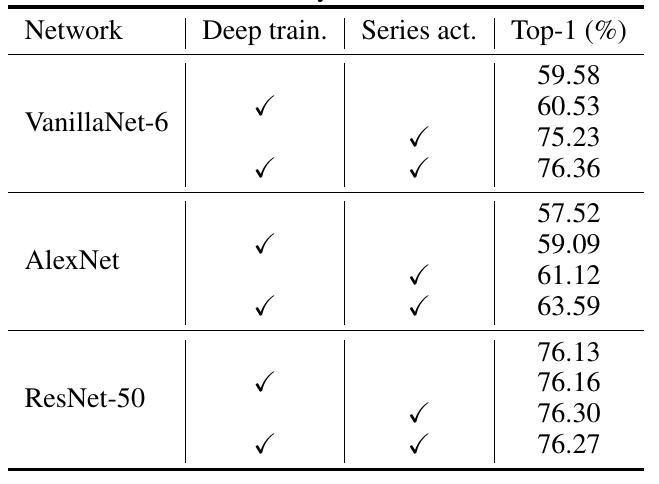
Table 1 Performance of the Minimalist Network in Image Classification
From the table above, it can be seen that the two proposed schemes can significantly enhance the accuracy of VanillaNet, achieving dozens of points of improvement on ImageNet. Additionally, the authors also conducted experiments on traditional networks like AlexNet, and the performance improvement was still remarkable, proving that as long as simple network designs are carefully crafted and trained, they can still possess powerful capabilities. For complex networks like ResNet50, the design proposals presented in this paper yield minimal results, indicating that such proposals are more effective for simpler networks.
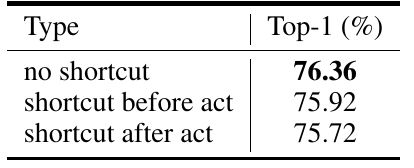
Table 2 Performance of the Minimalist Network in Image Classification
Do residual modules still work in a simple network like VanillaNet? The authors also experimented with this question, and the results showed that neither the original ResNet residual scheme nor the improved PreAct-ResNet residual scheme improved VanillaNet’s performance. Does this suggest that residual networks are not the only choice in deep learning? This is worth considering for future researchers. The authors explain that due to VanillaNet’s fewer layers, its main bottleneck lies in non-linearity rather than residuals, and that residuals may even harm the network’s non-linearity.
Next, the authors compared VanillaNet with various complexly designed networks in terms of accuracy on the ImageNet classification task.
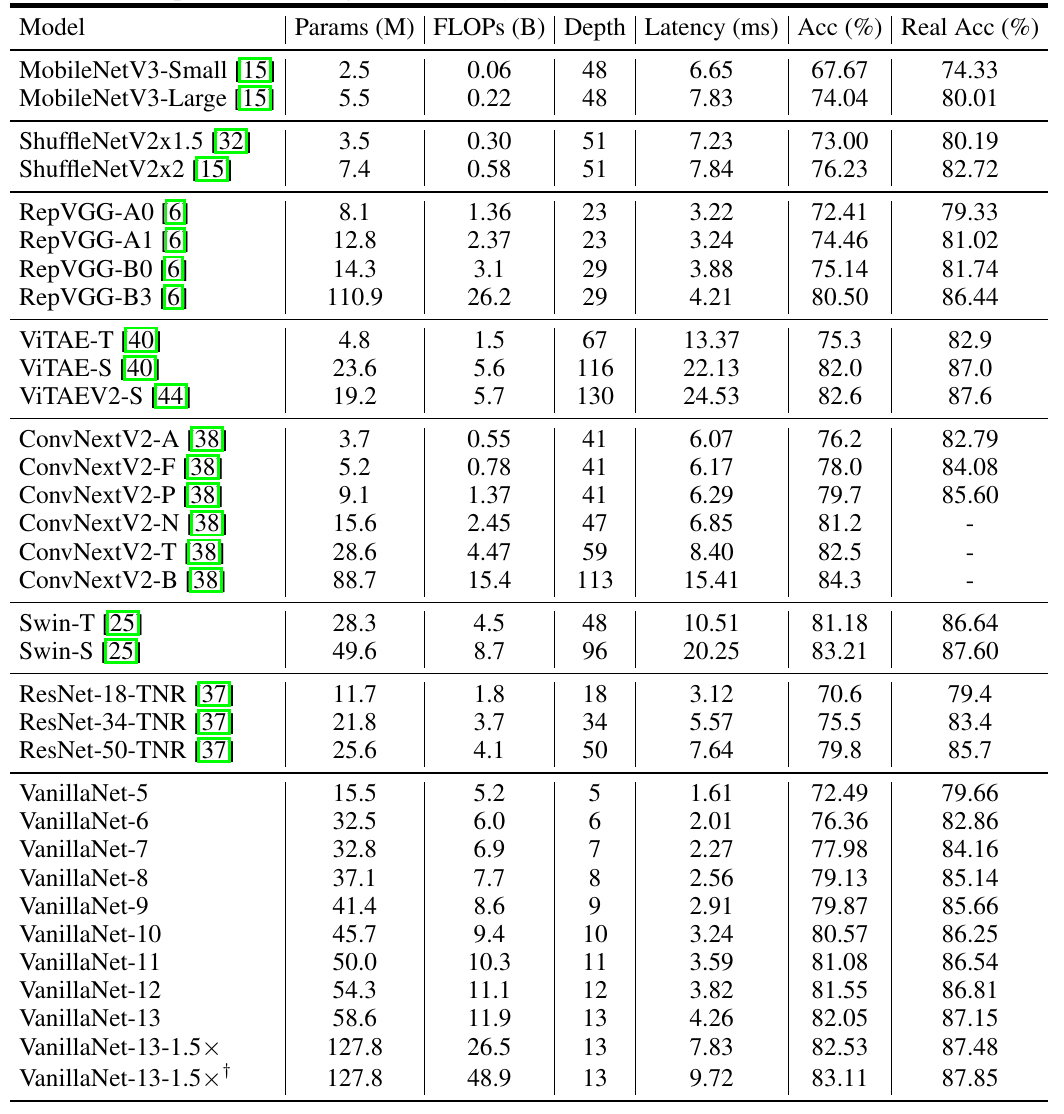
Table 3 Performance of the Minimalist Network in Image Classification
It can be seen that the proposed VanillaNet has impressive speed and accuracy metrics. For instance, VanillaNet-9, using only 9 layers, achieves nearly 80% accuracy on ImageNet, and compared to ResNet-50 with the same accuracy, it boasts over double the speed (2.91ms vs. 7.64ms), while the 13-layer VanillaNet can achieve 83% Top-1 accuracy, being over twice as fast as the Swin-S network with the same accuracy. Despite VanillaNet having a much higher number of parameters and computational load than complex networks, its speed is faster due to its minimalist design advantages.
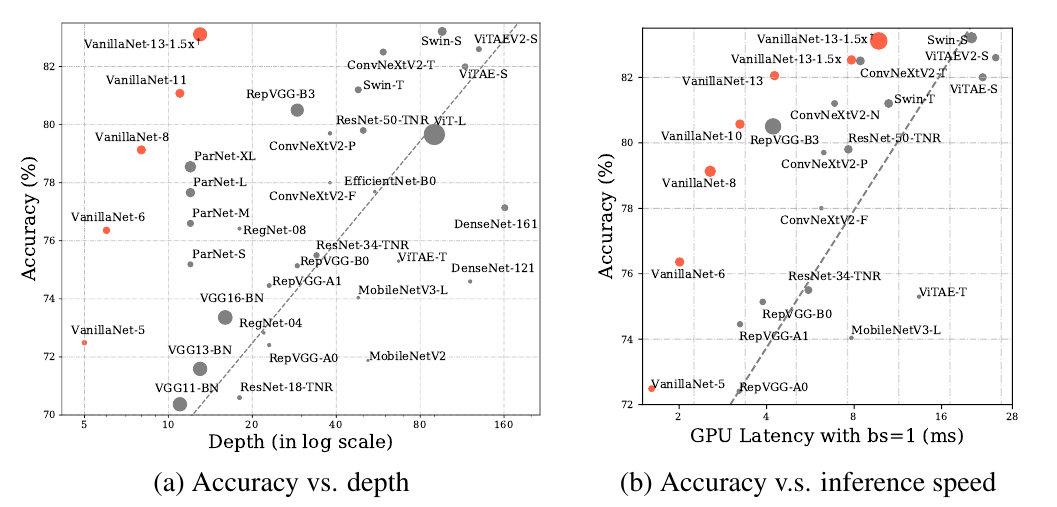
Figure 2 Performance of the Minimalist Network in Image Classification
Figure 2 visually demonstrates the power of VanillaNet. By using a minimal number of layers and setting the batch size to 1, VanillaNet achieves SOTA accuracy and speed curves.
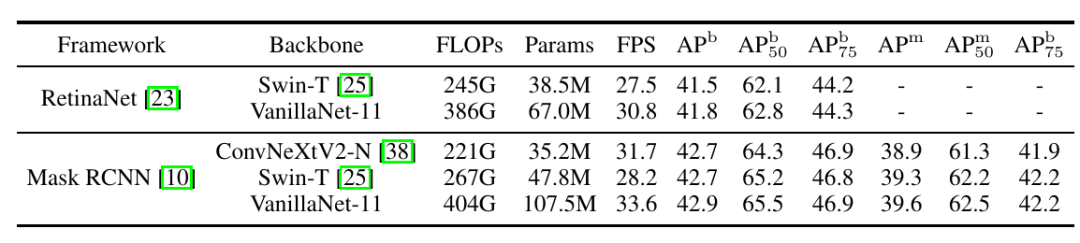
Table 4 Performance of the Minimalist Network in Detection and Segmentation Tasks
To further demonstrate VanillaNet’s capabilities across different tasks, the authors also conducted experiments on detection and segmentation models. The experiments indicated that VanillaNet can also achieve better FPS on downstream tasks with the same accuracy, proving its potential in computer vision.
In summary, VanillaNet is a very simple yet powerful computer vision network architecture that achieves SOTA performance using a straightforward convolutional structure. Since the introduction of Transformers into the visual domain, attention mechanisms have been considered essential and effective structural designs. However, ConvNeXt has restored confidence in convolutional networks through better performance. So, can VanillaNet spark a ‘Renaissance’ of designs such as no-residual networks and shallow networks? Let us wait and see.

© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]